Post Syndicated from Netflix Technology Blog original https://medium.com/netflix-techblog/vmaf-v1-good-is-not-good-enough-60d7e4244ea8
By Christos G. Bampis, Zhi Li, Kyle Swanson, Nil Fons Miret and Pavan Madhusudanarao
Will this encode look good to Netflix members? Does switching to a new codec improve quality at the same bitrate and by how much? What is the best way to encode a movie title given a target bitrate budget? For years, VMAF has reliably helped us answer those questions and deliver an optimized quality of experience to our members.
But good is not good enough. If VMAF misjudges quality, that may lead to loss of detail for a suspenseful close-up or banding for a stunning wide-angle sky shot. That’s a lot of trust to put in one number, so we strive to make sure it earns it. Over time, we collected feedback from VMAF users, both internally and externally. A few years ago, we embarked on a journey to develop a new version of VMAF to address some of its known limitations. Today, we are happy to announce that we are open-sourcing a new version of VMAF, with version number v1. By using VMAF v1 we can more accurately assess visual quality and hence efficiently deliver higher quality for Netflix members worldwide. In this post we share how v1 addresses the previous version’s (called VMAF v0) limitations and some of the challenges we faced along the way.
What is VMAF and why improve it?
VMAF (Video Multimethod Assessment Fusion) is a video quality metric that Netflix developed with university partners and open-sourced on GitHub. It has become a de facto standard for encoding evaluation and optimization for the video industry. VMAF combines elementary quality-aware features and fuses them with a support-vector regressor (SVR) trained on subjective data. For background, see our first, second and third VMAF tech blogs.
Despite its accuracy and wide adoption, we have identified room to improve the core of the algorithm. That’s central to our mission of delivering the best possible visual quality to our members no matter where and how they watch Netflix. As new codecs, like AV2, are developed and use cases like live streaming and cloud gaming emerge, we strive to continue to improve VMAF to serve these business needs. We describe each key improvement below.
Improving sensitivity to compression artifacts
As discussed in our first VMAF tech blog [1], a typical encoding pipeline introduces both compression and scaling artifacts. Intuitively, when more bits are available, higher resolutions are preferable. VMAF quantifies the tradeoff between compression and scaling and determines the optimal resolution to use given a bitrate budget. This can be demonstrated by a VMAF vs. bitrate curve.
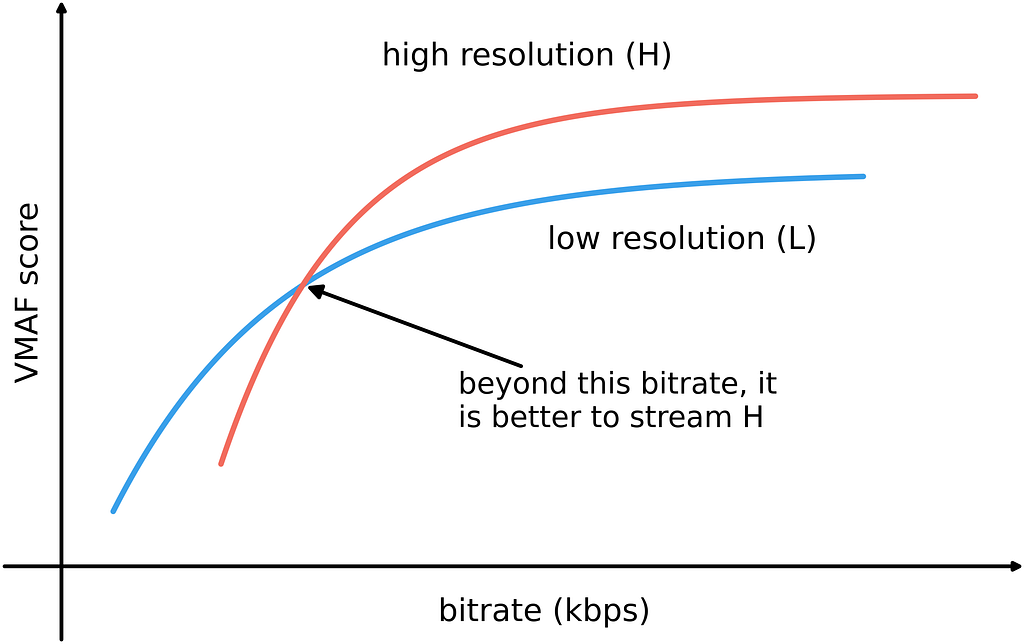
In practice, we observed that VMAF v0 tends to favor switching to a higher resolution at lower bitrates, preferring compression artifacts over scaling, which could be visually annoying. This can be partially attributed to the DLM (Detail Loss Metric) feature, which penalizes contrast/detail loss, but may be less sensitive to distracting artifacts, like blockiness [3]. In VMAF v1, to complement DLM, we added the AIM (additive impairments) component [3] from the original ADM formulation with minor modifications to improve accuracy. These two elementary metrics are linearly combined, similar to the original implementation in [3].
One VMAF model to rule them all
A first-order effect that influences quality perception is the visibility of artifacts and its relationship to viewing distance and canvas size. Put simply, the same encoded video looks better when displayed on a smaller canvas or viewed from further away.

The standard VMAF model assumes that viewers sit in front of a 1920×1080 display, in a living room-like environment, with a normalized viewing distance of approximately 3× the screen height (3H). This means that the standard 1080p@3H VMAF model corresponds to a viewing angle of approximately 60 pixels per degree.
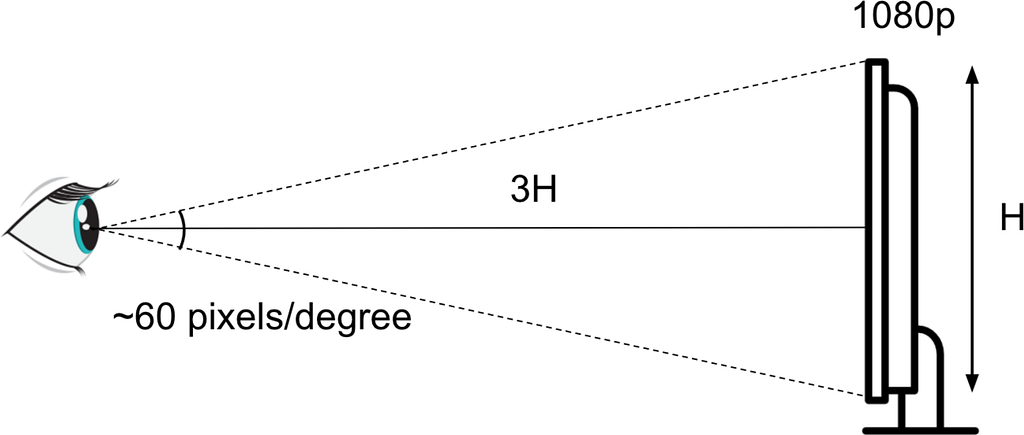
For phone viewing, given a smaller screen size and longer natural viewing distance (typical phone viewing can be approximated as 4 to 5H) relative to the screen height, we expect that artifacts become less visible. The phone model of VMAF v0 captures this by post-processing the standard (TV/laptop) VMAF score by a second-order polynomial mapping. This mapping was estimated using subjective data.
One drawback of the above mapping is that it is hard to generalize predictions for the myriad of viewing conditions that materially differ from the original subjective experiment. Further, in practice, we observed that the phone model can overpredict quality. In v1, instead of using a mapping function, we adjust the elementary feature values based on the normalized viewing distance. The same model can then be trained and reapplied for different use cases, e.g., phone viewing, 4K@3H, or a more discerning [email protected]. We found that this approach improves accuracy and helps generalize VMAF better.
To achieve this, we modulate the spatial contrast sensitivity function (CSF) used in DLM based on the normalized viewing distance. The CSF defines human sensitivity to contrast across spatial frequencies and is related to distortion perceptibility. The CSF can hence be used to estimate perceived distortion for different viewing distances, display sizes, and resolutions. An example CSF curve is shown below.
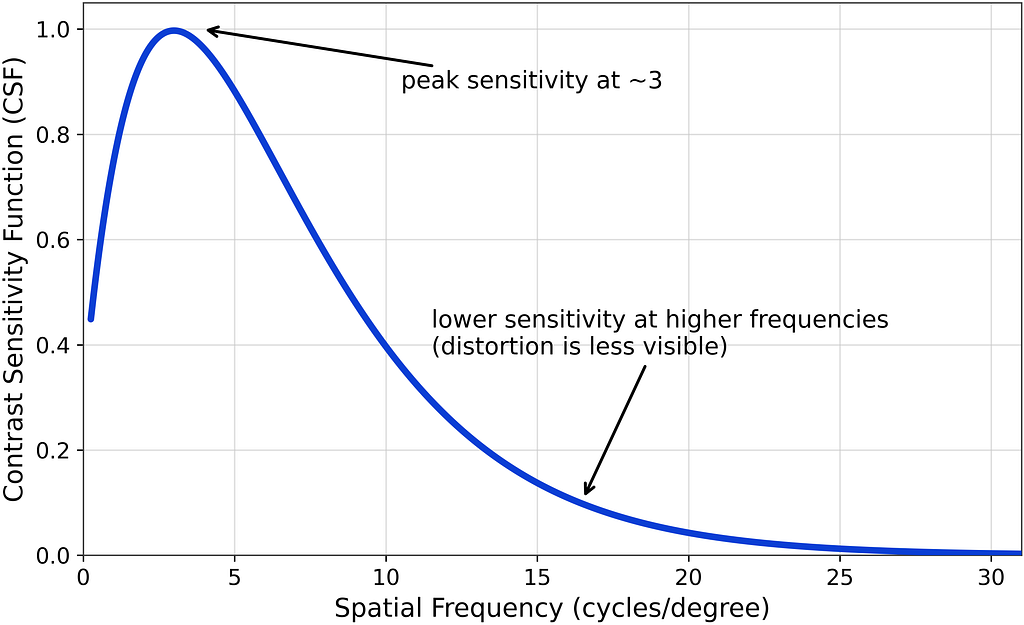
As the viewing distance increases, more pixels fit into a degree of visual angle, which lowers distortion visibility. In VMAF v1, we use an adapted version of Barten’s CSF model from [4].
Addressing banding artifacts
Banding shows up as staircase-like edges in parts of the image that should look smooth. It can have a negative visual impact for viewers, but this impact is not captured well by VMAF v0. VMAF v1 integrates the Contrast Aware Multiscale Banding Index (CAMBI) as one of the elementary features. You can read more about CAMBI in our previous tech blog or the technical paper.
Addressing chroma artifacts
VMAF v0 only extracts luma-based features, so it is unaware of chroma artifacts. In practice, encoding and scaling introduce chroma artifacts via quantization and subsampling. To capture such artifacts, we modified SpEED-QA and applied it to the chroma channels.
Leveraging the no-enhancement gain (NEG) mode
To reduce the effect of image enhancement operations, like sharpening, a standalone no-enhancement gain (NEG) mode was made available for VMAF v0. We have found that NEG serves as a conservative quality metric and helps preserve creative intent. We already use VMAF-NEG as one of the quality metrics during codec development, such as for AV2. Therefore, NEG is enabled by default for VMAF v1 without a need for a separate model.
Improving the motion feature
VMAF v0’s motion feature does not have an upper bound. Further, the training data used then did not have enough coverage for high-motion sequences. Consequently, we observed that VMAF v0 could overpredict quality for very high-motion scenes. On the flip side, since motion differencing in v0 was performed between consecutive frames, v0 would underpredict quality for sequences with frame rates higher than 24 or 30 fps, like 60 fps. In v1, we apply an empirically derived hard threshold to the motion feature. Further, we add an option to measure motion differences over a larger temporal window. Expanding the temporal window alone does not fully capture the perceptual impact of 60 fps, but it does reduce the underprediction evident in v0.
Overview of VMAF v1 models
VMAF v1 supports the following models:
- Standard 1080p Model: This model is calibrated for 1080p video viewed at a standard 3H distance. It uses an operating range of [0, 100].
- Phone Model: Derived by setting the normalized viewing distance to 5H (based on experimental data), this model adjusts the DLM, AIM, and chroma feature calculations to reflect reduced artifact visibility on smaller screens viewed from a greater relative distance. It retains the standard [0, 100] range.
- 4K Model: We release two v1 4K models: a 1.5H variant and a 3H variant. The 1.5H variant is based on a discerning [email protected] viewing condition. This variant is conceptually similar to its v0 4K counterpart and operates on a [0, 100] range. For most users, this variant is the default choice. The 3H variant is based on a consumer-like 4K@3H viewing condition. This variant operates on a [0, 110] range, which helps to quantify the additional perceptual benefit of 4K resolution over 1080p when both are viewed at 3H.
Interpreting the score
VMAF v1’s score and interpretation are largely consistent with v0’s. To achieve this, we calibrated the VMAF v1 scale to align with v0 via a score transform, so that the new algorithm preserves the meaning of the numbers while keeping its accuracy benefits.
Putting v1 to the test
We evaluate VMAF v1 across several subjective datasets. These datasets cover a variety of codecs, content types, and use cases. For simplicity, we report the Spearman’s rank correlation coefficient (SRCC) for VMAF v0 and v1. SRCC values closer to 1 show higher agreement with subjective data. Full results will be available in a future technical paper.
In the table below, if a dataset is marked as “4K” then we measure VMAF at 4K using the [email protected] model, otherwise we measure VMAF at 1080p, using the appropriate 1080p model. If a dataset is marked as “phone” the 1080p phone model is used, otherwise the standard 1080p@3H model is used.
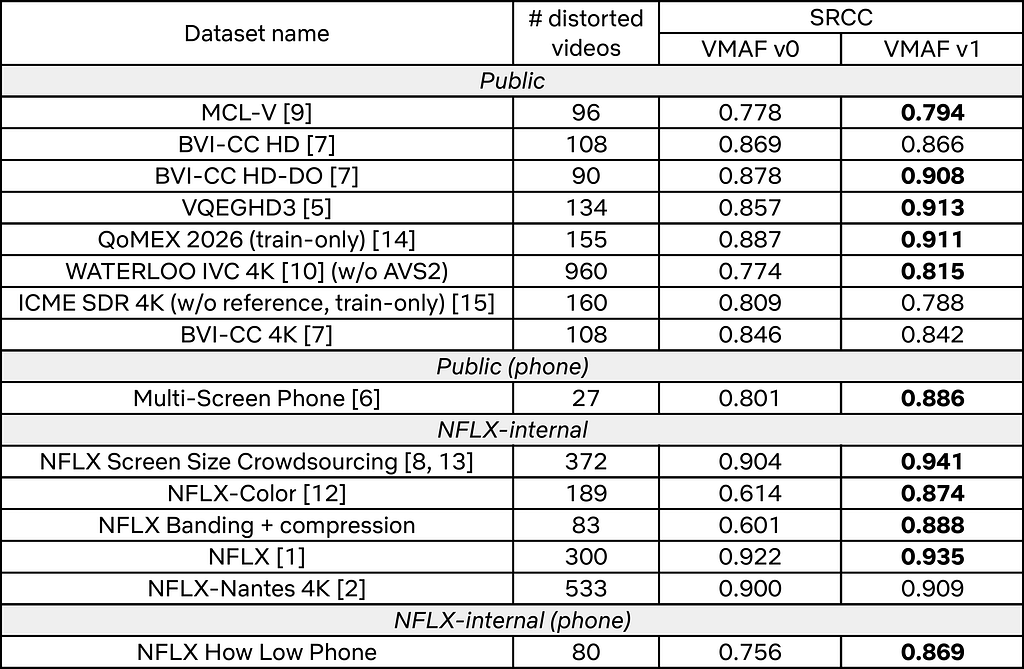
As seen above, VMAF v1 matches or outperforms v0 in most datasets. There are notable improvements on large datasets like WATERLOO IVC 4K and the Netflix Screen Size Crowdsourcing, on datasets with chroma and banding artifacts, and those that involve phone viewing. On a few datasets we observe minor regressions, which are small relative to the gains elsewhere.
Running v1
Even with the addition of new features, we wanted VMAF v1 to have a reduced computational complexity when compared with VMAF v0. To achieve this, we have:
- Removed VIF (Visual Information Fidelity) as a core VMAF feature. VIF is computationally complex and did not meaningfully improve accuracy after updating the other features.
- Introduced a few CAMBI-specific optimizations, both algorithmic and software.
- Measured the chroma feature at a lower scale, which does not hurt accuracy [11].
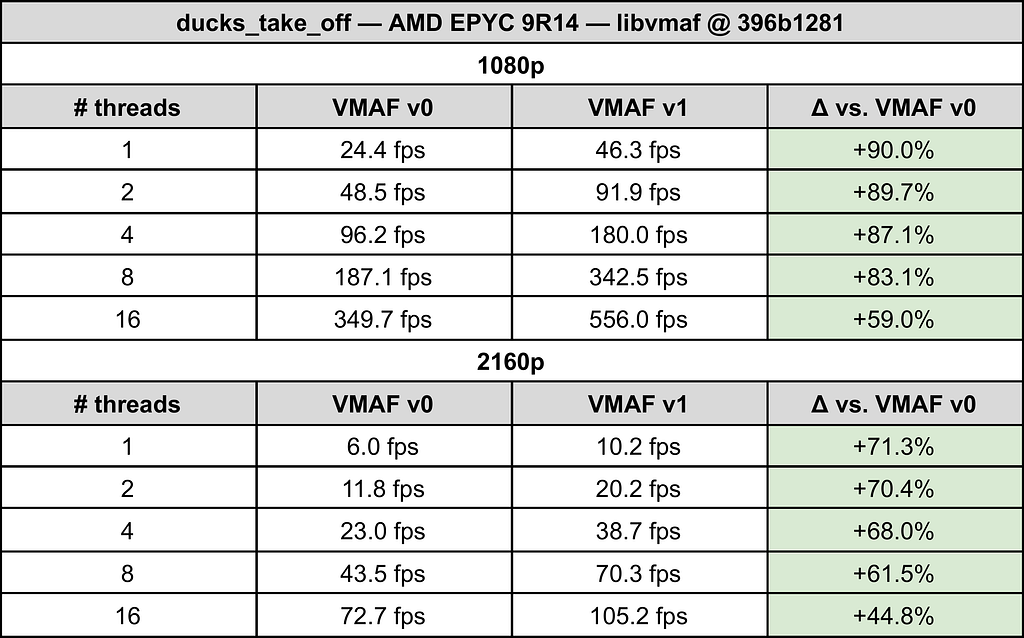
The result of this work is not only a more accurate VMAF, but also a much faster VMAF. The table below shows the processing speed and threading performance for each VMAF model at 1080p and 4K. Additionally, our newest libvmaf release has a much improved threading performance, which is of benefit to both v0 and v1. Note that for content with significant banding, computing CAMBI adds some overhead, which can reduce this speedup.
Keeping some old (and good) habits
While the core of the algorithm has changed, we still recommend:
- Computing VMAF at the right resolution by upsampling the distorted video to the source resolution, so that both compression and scaling artifacts are reflected. For example, bicubic upsampling can be used as a general approximation.
- Interpreting scores in context by using the right model (e.g. 1080p vs. 4K vs. phone) for your scenario by taking into account viewing distance assumptions.
This is not the end of the road
Just like any metric, VMAF v1 is not perfect. There is still room for improvement. Some areas that we are working on addressing in the future are: film-grain noise, improved handling for high frame rates, and perceptual codec optimizations such as adaptive quantization. We invite the community to try the latest VMAF models, report edge cases, contribute to the open-source code, and help improve VMAF. We plan to publish a detailed technical paper for VMAF v1. We also plan to release an HDR version enhanced by the v1 improvements, so stay tuned!
Acknowledgments
This was a collaborative effort propelled by our stunning colleagues. We want to thank the following individuals: Xiaoqing Zhu, Mariana Afonso, Anush Moorthy, Raymond Walsh, Omair Akhtar, Amelia Taylor, Ken Thomas, Zheng Lu, Chris Pham, Alex Chang, Prudhvi Chaganti, Ben Wallen, Craig Howland, Deepthi Arun, Andy Rhines and Lukáš Krasula.
References
[1] Z. Li et al., “Toward a practical perceptual video quality metric,” Netflix Technology Blog, 2016.
[2] Z. Li et al., “VMAF: The journey continues,” Netflix Technology Blog, 2018.
[3] S. Li, F. Zhang, L. Ma, and K. Ngan, “Image Quality Assessment by Separately Evaluating Detail Losses and Additive Impairments,” IEEE Transactions on Multimedia, 2011.
[4] P. G. J. Barten, Contrast Sensitivity of the Human Eye and Its Effects on Image Quality. SPIE Press, 1999.
[5] Video Quality Experts Group, “Report on the validation of video quality models for high definition video content,” 2010.
[6] N. Barman, Y. Reznik, and M. G. Martini, “A Subjective Dataset for Multi-Screen Video Streaming Applications,” International Conference on Quality of Multimedia Experience (QoMEX), Ghent, Belgium, 2023, pp. 270–275.
[7] A. Katsenou, F. Zhang, M. Afonso, G. Dimitrov, and D. R. Bull, “BVI-CC: A Dataset for Research on Video Compression and Quality Assessment,” Frontiers in Signal Processing, vol. 2, 2022.
[8] C. G. Bampis, L. Krasula, Z. Li, and O. Akhtar, “Measuring and Predicting Perceptions of Video Quality Across Screen Sizes with Crowdsourcing,” International Conference on Quality of Multimedia Experience (QoMEX), Ghent, Belgium, 2023, pp. 13–18.
[9] J. Y. Lin, R. Song, C.-H. Wu, T. J. Liu, H. Wang, and C.-C. J. Kuo, “MCL-V: A streaming video quality assessment database,” Journal of Visual Communication and Image Representation, vol. 30, pp. 1–9, Jul. 2015.
[10] Z. Li, Z. Duanmu, W. Liu, and Z. Wang, “AVC, HEVC, VP9, AVS2 or AV1? — A Comparative Study of State-of-the-Art Video Encoders on 4K Videos,” Int. Conf. Image Analysis and Recognition (ICIAR), 2019.
[11] C. G. Bampis, P. Gupta, R. Soundararajan, and A. C. Bovik, “SpEED-QA: Spatial Efficient Entropic Differencing for Image and Video Quality,” IEEE Signal Process. Lett., vol. 24, no. 9, pp. 1333–1337, Sep. 2017.
[12] L.-H. Chen, C. G. Bampis, Z. Li, J. Sole, and A. C. Bovik, “Perceptual video quality prediction emphasizing chroma distortions,” IEEE Trans. Image Process., vol. 30, pp. 1941–1954, 2021.
[13] C. G. Bampis et al., “NFLX Screen Size Crowdsourcing dataset,” 2023.
[14] H. Wei, P. Lebreton, Y. Chen, J. Zhu, and P. Le Callet, “Grand Challenge on Video Quality Assessment for Asymmetric Encoded Videos,” Int. Conf. Quality of Multimedia Experience (QoMEX), Cardiff, U.K., 2026.
[15] Y. Chen, B. Chen, H. Wei, A. C. Bovik et al., “ICME 2025 Generalizable HDR and SDR Video Quality Measurement Grand Challenge,” arXiv:2506.22790, 2025.
![]()
VMAF v1: Good Is Not Good Enough was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.