Post Syndicated from Ankur Bhanawat original https://aws.amazon.com/blogs/big-data/best-practices-for-migrating-teradata-bteq-scripts-to-amazon-redshift-rsql/
When migrating from Teradata BTEQ (Basic Teradata Query) to Amazon Redshift RSQL, following established best practices helps ensure maintainable, efficient, and reliable code. While the AWS Schema Conversion Tool (AWS SCT) automatically handles the basic conversion of BTEQ scripts to RSQL, it primarily focuses on SQL syntax translation and basic script conversion. However, to achieve optimal performance, better maintainability, and full compatibility with the architecture of Amazon Redshift, additional optimization and standardization are needed.
The best practices that we share in this post complement the automated conversion supplied by AWS SCT by addressing areas such as performance tuning, error handling improvements, script modularity, logging enhancements, and Amazon Redshift-specific optimizations that AWS SCT might not fully implement. These practices can help you transform automatically converted code into production-ready, efficient RSQL scripts that fully use the capabilities of Amazon Redshift.
BTEQ
BTEQ is Teradata’s legacy command-line SQL tool that has served as the primary interface for Teradata databases since the 1980s. It’s a powerful utility that combines SQL querying capabilities with scripting features; you can use it to perform various tasks from data extraction and reporting to complex database administration. BTEQ’s robustness lies in its ability to handle direct database interactions, manage sessions, process variables, and execute conditional logic while providing comprehensive error handling and report formatting capabilities.
RSQL is a modern command-line client tool provided by Amazon Redshift and is specifically designed to execute SQL commands and scripts in the AWS ecosystem. Similar to PostgreSQL’s psql but optimized for the unique architecture of Amazon Redshift, RSQL offers seamless SQL query execution, efficient script processing, and sophisticated result set handling. It stands out for its native integration with AWS services, making it a powerful tool for modern data warehousing operations.
The transition from BTEQ to RSQL has become increasingly relevant as organizations embrace cloud transformation. This migration is driven by several compelling factors. Businesses are moving from on-premises Teradata systems to Amazon Redshift to take advantage of cloud benefits. Cost optimization plays a crucial role in these moves, because Amazon Redshift typically offers more economical data warehousing solutions with its pay-as-you-go pricing model.
Furthermore, organizations want to modernize their data architecture to take advantage of enhanced security features, better scalability, and seamless integration with other AWS services. The migration also brings performance benefits through columnar storage, parallel processing capabilities, and optimized query performance offered by Amazon Redshift, making it an attractive destination for enterprises looking to modernize their data infrastructure.
Best practices for BTEQ to RSQL migration
Let’s explore key practices across code structure, performance optimization, error handling, and Redshift-specific considerations that will help you create robust and efficient RSQL scripts.
Parameter files
Parameters in RSQL function as variables that store and pass values to your scripts, similar to BTEQ’s .SET VARIABLE functionality. Instead of hardcoding schema names, table names, or configuration values directly in RSQL scripts, use dynamic parameters that can be modified for different environments (dev, test, prod). This approach reduces manual errors, simplifies maintenance, and supports better version control by keeping sensitive values separate from code.
Create a separate shell script containing environment variables:
```sh
# rsql_parameters.sh
VIEW_SCHEMA=<SAMPLE_VIEW_SCHEMA>;export VIEW_SCHEMA
STAGING_TABLE_SCHEMA=<SAMPLE_STAGING_TABLE_SCHEMA>;export STAGING_TABLE_SCHEMA
STORED_PROCEDURE_SCHEMA=<SAMPLE_STORED_PROCEDURE_SCHEMA>;export STORED_PROCEDURE_SCHEMA
QUERY_GROUP=<ETL_JOB_NAME>;export QUERY_GROUP
```
Then import these parameters into your RSQL scripts using:
. <file_path>/rsql_parameters.sh
# or
source <file_path>/rsql_parameters.sh
Secure credential management
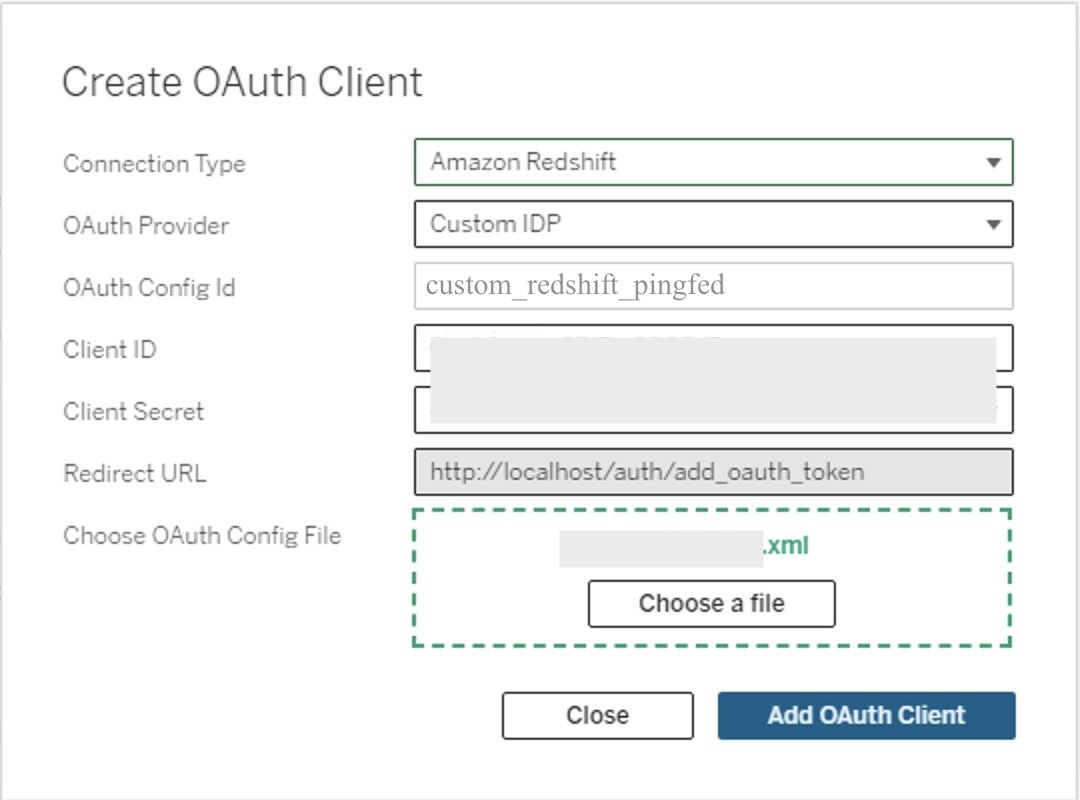
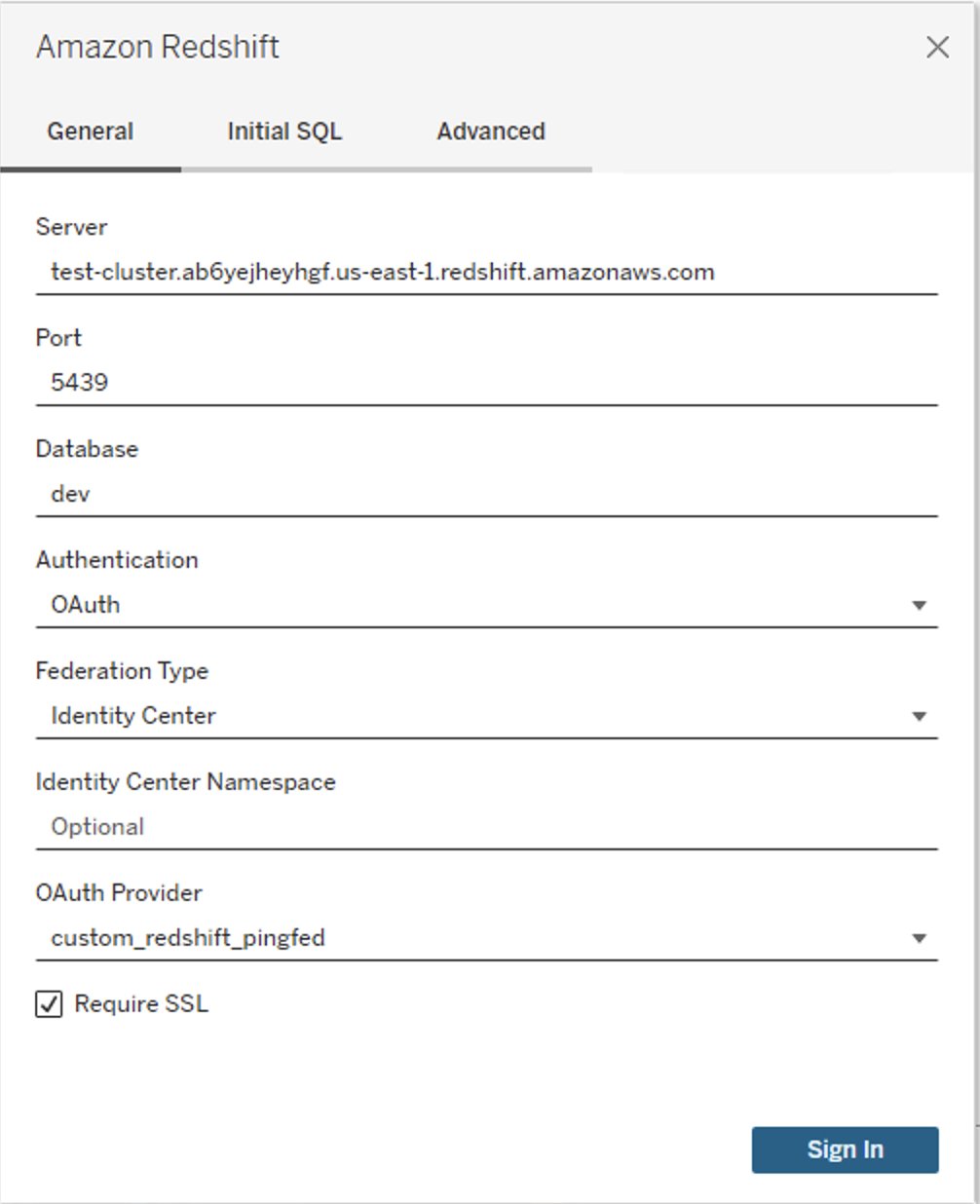
For better security and maintainability, use JDBC or ODBC temporary AWS Identity and Access Management (IAM) credentials for database authentication. For details, see Connect to a cluster with Amazon Redshift RSQL.
Query logging and debugging
Debugging and troubleshooting SQL scripts can be challenging, especially when dealing with complex queries or error scenarios. To simplify this process, it’s recommended to enable query logging in RSQL scripts.
RSQL provides the echo-queries option, which prints the executed SQL queries along with their execution status. By invoking the RSQL client with this option, you can track the progress of your script and identify potential issues.
rsql --echo-queries -D testiam
Here testiam represents a DSN connection configured in odbc.ini with an IAM profile.
You can store these logs by redirecting the output when executing your RSQL script:
```
sh <path to RSQL file>/<RSQL file name>.sh > <log file name>.log
```
With query logging is enabled, you can examine the output and identify the specific query that caused an error or unexpected behavior. This information can be invaluable when troubleshooting and optimizing your RSQL scripts.
Error handling with incremental exit codes
Implement robust error handling using incremental exit codes to identify specific failure points. Proper error handling is crucial in a scripting environment, and RSQL is no exception. In BTEQ scripts, errors were typically handled by checking the error code and taking appropriate actions. However, in RSQL, the approach is slightly different. To help ensure robust error handling and straightforward troubleshooting, it’s recommended that you implement incremental exit codes at the end of each SQL operation.The incremental exit code approach works as follows:
- After executing a SQL statement (such as
SELECT, INSERT, UPDATE, and so on.), check the value of the :ERROR variable.
- If the
:ERROR variable is non-zero, it indicates that an error occurred during the execution of the SQL statement.
- Print the error message, error code, and additional relevant information using RSQL commands such as
\echo, \remark, and so on.
- Exit the script with an appropriate exit code using the
\exit command, where the exit code represents the specific operation that failed.
By using incremental exit codes, you can identify the point of failure within the script. This approach not only aids in troubleshooting but also allows for better integration with continuous integration and deployment (CI/CD) pipelines, where specific exit codes can trigger appropriate actions.
Example:
SELECT * FROM $STAGING_TABLE_SCHEMA.SAMPLE_TABLE;
\if :ERROR <> 0
\echo 'Error occurred in executing the select operation on table $STAGING_TABLE_SCHEMA.SAMPLE_TABLE'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 1 -- Exit code 1 represents a failure in the SELECT operation
\else
\echo 'Select statement completed successfully'
INSERT INTO $STAGING_TABLE_SCHEMA.ANOTHER_SAMPLE_TABLE
SELECT * FROM $STAGING_TABLE_SCHEMA.SAMPLE_TABLE;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on table $STAGING_TABLE_SCHEMA.SAMPLE_TABLE'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 2 -- Exit code 2 represents a failure in the INSERT operation
\else
\echo 'Insert statement completed successfully'
In the preceding example, if the SELECT statement fails, the script will exit with an exit code of 1. If the INSERT statement fails, the script will exit with an exit code of 2. By using unique exit codes for different operations, you can quickly identify the point of failure and take appropriate actions.
Use query groups
When troubleshooting issues in your RSQL scripts, it can be helpful to identify the root cause by analyzing query logs. By using query groups, you can label a group of queries that are run during the same session, which can help pinpoint problematic queries in the logs.
To set a query group at the session level, you can use the following command:
set query_group to $QUERY_GROUP;
By setting a query group, queries executed within that session will be associated with the specified label. This technique can significantly aid in effective troubleshooting when you need to identify the root cause of an issue.
Use a search path
When creating an RSQL script that refers to tables from the same schema multiple times, you can simplify the script by setting a search path. By using a search path, you can directly reference table names without specifying the schema name in your queries (for example, SELECT, INSERT, and so on).
To set the search path at the session level, you can use the following command:
set search_path to $STAGING_TABLE_SCHEMA;
After setting the search path to $STAGING_TABLE_SCHEMA, you can refer to tables within that schema directly, without including the schema name.
For example:
SELECT * FROM STAGING_TABLE;
If you haven’t set a search path, you need to specify the schema name in the query, as shown in the following example:
SELECT * FROM $STAGING_TABLE_SCHEMA.STAGING_TABLE;
It’s recommended to use a fully qualified path for an object in an RSQL script, but adding the search path prevents abrupt execution failure because of not providing a fully qualified path.
Combine multiple UPDATE statements into a single INSERT
In BTEQ scripts, it might have multiple sequential UPDATE statements for the same table. However, this approach can be inefficient and lead to performance issues, especially when dealing with large datasets, because of I/O intensive operations.
To address this concern, it’s recommended to combine all or some of the UPDATE statements into a single INSERT statement. This can be achieved by creating a temporary table, converting the UPDATE statements into a LEFT JOIN with the staging table using a SELECT statement, and then inserting the temporary table data into the staging table.
Example:
The existing BTEQ SQLs in the following example first INSERT the data into staging_table from staging_table1 and then UPDATE the columns for inserted data if certain condition is satisfied:
Insert into SAMPLE_STAGING_TABLE_SCHEMA.staging_table select col1,col2,col3,col4,col5 from SAMPLE_STAGING_TABLE_SCHEMA.staging_table1 where col1=col2;
Update SAMPLE_STAGING_TABLE_SCHEMA.staging_table a from (select col1,col2 from SAMPLE_STAGING_TABLE_SCHEMA.staging_table2 where col1!=col2) b where a.col1=b.col1 set a.col2 =b.col2;
Update SAMPLE_STAGING_TABLE_SCHEMA.staging_table a from (select col3,col2 from SAMPLE_STAGING_TABLE_SCHEMA.staging_table2 where col3!=col1) c where a.col2=c.col2 set a.col3=c.col3;
Update SAMPLE_STAGING_TABLE_SCHEMA.staging_table where col4='no' set col4='yes';
Update SAMPLE_STAGING_TABLE_SCHEMA.staging_table where col1='zyx' set col1 ='nochange';
The following RSQL operation below achieves the same result by first loading the data into a staging table, then executing the UPDATE using a temporary table as an intermediate step and then completes UPDATE using a temporary table. After this, it will truncate staging_tables and insert temporary table staging_table_temp1 data into staging_table.
Insert into $STAGING_TABLE_SCHEMA.staging_table select col1,col2,col3,col4,col5 from $STAGING_TABLE_SCHEMA.staging_table1 where col1=col2;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on table staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 1
\else
\echo 'Insert statement completed successfully'
Create temporary table staging_table_temp1 (like $STAGING_TABLE_SCHEMA.staging_table including defaults);
\if :ERROR <> 0
\echo 'Error occurred in creating the temporary table staging_table_temp1'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 2
\else
\echo 'Temporary table created successfully'
Insert into staging_table_temp1
(
Col1,
Col2,
Col3,
Col4
)
select
case when col1='zyx' then 'nochange'
else a.col1
end as col1,
coalesce(b.col2,a.col2) as col2,
coalesce(c.col3,a.col3) as col3,
case when col4='no' then 'yes'
else a.col4
end as col4
from $STAGING_TABLE_SCHEMA.staging_table a
left join (select col1,col2 from $STAGING_TABLE_SCHEMA.staging_table2 where col1!=col2) b
on a.col1=b.col1
left join (select col3,col2 from $STAGING_TABLE_SCHEMA.staging_table2 where col3!=col1) c
on a.col2=c.col2;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on temporary table staging_table_temp1'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 3
\else
\echo 'Insert statement completed successfully'
--Truncate table staging_table;
$STORED_PROCEDURE_SCHEMA.sp_truncate_table(‘$STAGING_TABLE_SCHEMA’,’staging_table’)
\if :ERROR <> 0
\echo 'Error occurred in executing the Truncate operation on table $STAGING_TABLE_SCHEMA.staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 4
\else
\echo 'Truncate statement completed successfully'
Insert into $STAGING_TABLE_SCHEMA.staging_table(col1,col2,col3,col4) select col1,col2,col3,col4 from staging_table_temp1;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on table $STAGING_TABLE_SCHEMA.staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 5
\else
\echo 'Insert statement completed successfully'
The following is an overview of the preceding logic:
- Create a temporary table with the same structure as the staging table.
- Execute a single
INSERT statement that combines the logic of all the UPDATE statements from the BTEQ script. The INSERT statement uses a LEFT JOIN to merge data from the staging table and the staging_table2 table, applying the necessary transformations and conditions.
- After inserting the data into the temporary table, truncate the staging table and insert the data from the temporary table into the staging table.
By consolidating multiple UPDATE statements into a single INSERT operation, you can improve the overall performance and efficiency of the script, especially when dealing with large datasets. This approach also promotes better code readability and maintainability.
Execution logs
Troubleshooting and debugging scripts can be a challenging task, especially when dealing with complex logic or error scenarios. To aid in this process, it’s recommended to generate execution logs for RSQL scripts.
Execution logs capture the output and error messages produced during the script’s execution, providing valuable information for identifying and resolving issues. These logs can be especially helpful when running scripts on remote servers or in automated environments, where direct access to the console output might be limited.
To generate execution logs, you can execute the RSQL script from the Amazon Elastic Compute Cloud (Amazon EC2) machine and redirect the output to a log file using the following command:
sample_rsql_script.sh > sample_rsql_script_$(date "+%Y.%m.%d-%H.%M.%S").log
The preceding command executes the RSQL script and redirects the output, including error messages or debugging information to the specified log file. It’s recommended to add a time parameter in the log file name to have distinct files for each run of RSQL script.
By maintaining execution logs, you can review the script’s behavior, track down errors, and gather relevant information for troubleshooting purposes. Additionally, these logs can be shared with teammates or support teams for collaborative debugging efforts.
Capture an audit parameter in the script
Audit parameters such as start time, end time, and the exit code of an RSQL script are important for troubleshooting, monitoring, and performance analysis. You can capture the start time at the beginning of your script and the end time and exit code after the script completes.
Here’s an example of how you can implement this:
# Capture start time
start=$(date +%s)
echo date : $(date)
echo Start Time : $(date +"%T.%N")
. <file_path>/rsql_parameters.
-- Your RSQL script logic goes here
--End of the RSQL code
-- Capture exit code and end time
rsqlexitcode=$?
echo Exited with error code $rsqlexitcode
echo End Time : $(date +"%T.%N")
end=$(date +%s)
exec=$(($end - $start))
echo Total Time Taken : $exec seconds
The preceding example captures the start time in start= $(date +%s). After the RSQL code is complete, it captures the exit code in rsqlexitcode=$? and the end time in end=$(date +%s).
Sample structure of the script
The following is a sample RSQL script that follows the best practices outlined in the preceding sections:
#bin/bash
#capturing start time of script execution
start=$(date +%s)
#Executing and setting rsql parameters script variables
. /<parameter script path>/rsql_parameters.sh
echo date : $(date)
echo Start Time : $(date +"%T.%N")
#Logging into Redshift cluster. Here credentials are retrieved from ODBC based temporary
#IAM credentials which is discussed in Credentials Management section
rsql --echo-queries -D testiam < EOF
\timing true
\echo '\n-----MAIN EXECUTION LOG STARTING HERE-----'
\echo '\n--JOB ${0:2} STARTING--'
/* Setting query group. Here $QUERY_GROUP retrieved from RSQL parameters file*/
SET query_group to '$QUERY_GROUP';
\if :ERROR <> 0
\echo 'Setting Query Group to $QUERY_GROUP failed '
\echo 'Error Code -'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 1
\else
\remark '\n **** Setting Query Group to $QUERY_GROUP Successfully **** \n'
\endif
/*Setting search path to Staging table schema*/
SET SEARCH_PATH TO $STAGING_TABLE_SCHEMA, pg_catalog;
\if :ERROR <> 0
\echo 'SET SEARCH_PATH TO $STAGING_TABLE_SCHEMA, pg_catalog failed.'
\echo 'Error Code -'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 2
\else
\remark '\n **** SET SEARCH_PATH TO $STAGING_TABLE_SCHEMA, pg_catalog executed Successfully **** \n'
\endif
/* Inserting initial data from staging_table1 into staging_table */
Insert into staging_table select col1,col2,col3,col4,col5 from staging_table1 where col1=col2;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on table staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 3
\else
\echo 'Insert statement completed successfully'
/* Creating temporary table for handling multiple updates using select statement*/
Create temporary table staging_table_temp1 (like $STAGING_TABLE_SCHEMA.staging_table including defaults);
\if :ERROR <> 0
\echo 'Error occurred in creating the temporary table staging_table_temp1'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 4
\else
\echo 'Temporary table created successfully'
/* Updates handling using insert and select statement*/
Insert into staging_table_temp1(Col1,Col2,Col3,Col4)
select
case when col1='zyx' then 'nochange' else a.col1 end as col1,
coalesce(b.col2,a.col2) as col2,
coalesce(c.col3,a.col3) as col3,
case when col4='no' then 'yes' else a.col4 end as col4
from $STAGING_TABLE_SCHEMA.staging_table a
left join (select col1,col2 from $STAGING_TABLE_SCHEMA.staging_table2 where col1!=col2) b
on a.col1=b.col1
left join (select col3,col2 from $STAGING_TABLE_SCHEMA.staging_table2 where col3!=col1) c
on a.col2=c.col2;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on temporary table staging_table_temp1'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 5
\else
\echo 'Insert statement completed successfully'
/*In production, ETL user may not have truncate table permission therefore, to avoid permission issue we are using a stored procedure which can truncate required table by using provided schema name and table name.
Note: You can create a stored procedure for truncating the tables and refer in all ETL RSQL script */
$STORED_PROCEDURE_SCHEMA.sp_truncate_table(‘$STAGING_TABLE_SCHEMA’,’staging_table’)
\if :ERROR <> 0
\echo 'Error occurred in executing the Truncate operation on table $STAGING_TABLE_SCHEMA.staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 6
\else
\echo 'Truncate statement completed successfully'
/* Inserting data from temporary table into staging table staging_table */
Insert into $STAGING_TABLE_SCHEMA.staging_table(col1,col2,col3,col4) select col1,col2,col3,col4 from staging_table_temp1;
\if :ERROR <> 0
\echo 'Error occurred in executing the insert operation on table $STAGING_TABLE_SCHEMA.staging_table'
\echo :ERRORCODE
\remark :LAST_ERROR_MESSAGE
\exit 7
\else
\echo 'Insert statement completed successfully'
EOF
#Capture RSQL return code to exit the script with proper error code and message
rsqlexitcode=$?
echo Exited with error code $rsqlexitcode
echo End Time : $(date +"%T.%N")
end=$(date +%s)
exec=$(($end - $start))
echo Total Time Taken : $exec seconds
Conclusion
In this post, we’ve explored crucial best practices for migrating Teradata BTEQ scripts to Amazon Redshift RSQL. We’ve shown you essential techniques including parameter management, secure credential handling, comprehensive logging, and robust error handling with incremental exit codes. We’ve also discussed query optimization strategies and methods that you can use to improve data modification operations. By implementing these practices, you can create efficient, maintainable, and production-ready RSQL scripts that fully use the capabilities of Amazon Redshift. These approaches not only help ensure a successful migration, but also set the foundation for optimized performance and straightforward troubleshooting in your new Amazon Redshift environment.
To get started with your BTEQ to RSQL migration, explore these additional resources:
About the authors
 Ankur Bhanawat is a Consultant with the Professional Services team at AWS based out of Pune, India. He’s an AWS certified professional in three areas and specialized in databases and serverless technologies. He has experience in designing, migrating, deploying, and optimizing workloads on the AWS Cloud.
Ankur Bhanawat is a Consultant with the Professional Services team at AWS based out of Pune, India. He’s an AWS certified professional in three areas and specialized in databases and serverless technologies. He has experience in designing, migrating, deploying, and optimizing workloads on the AWS Cloud.
 Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernizing analytical solutions. His background is in data warehouse architecture, development, and administration. He has been in data and analytical field for over 14 years.
Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernizing analytical solutions. His background is in data warehouse architecture, development, and administration. He has been in data and analytical field for over 14 years.


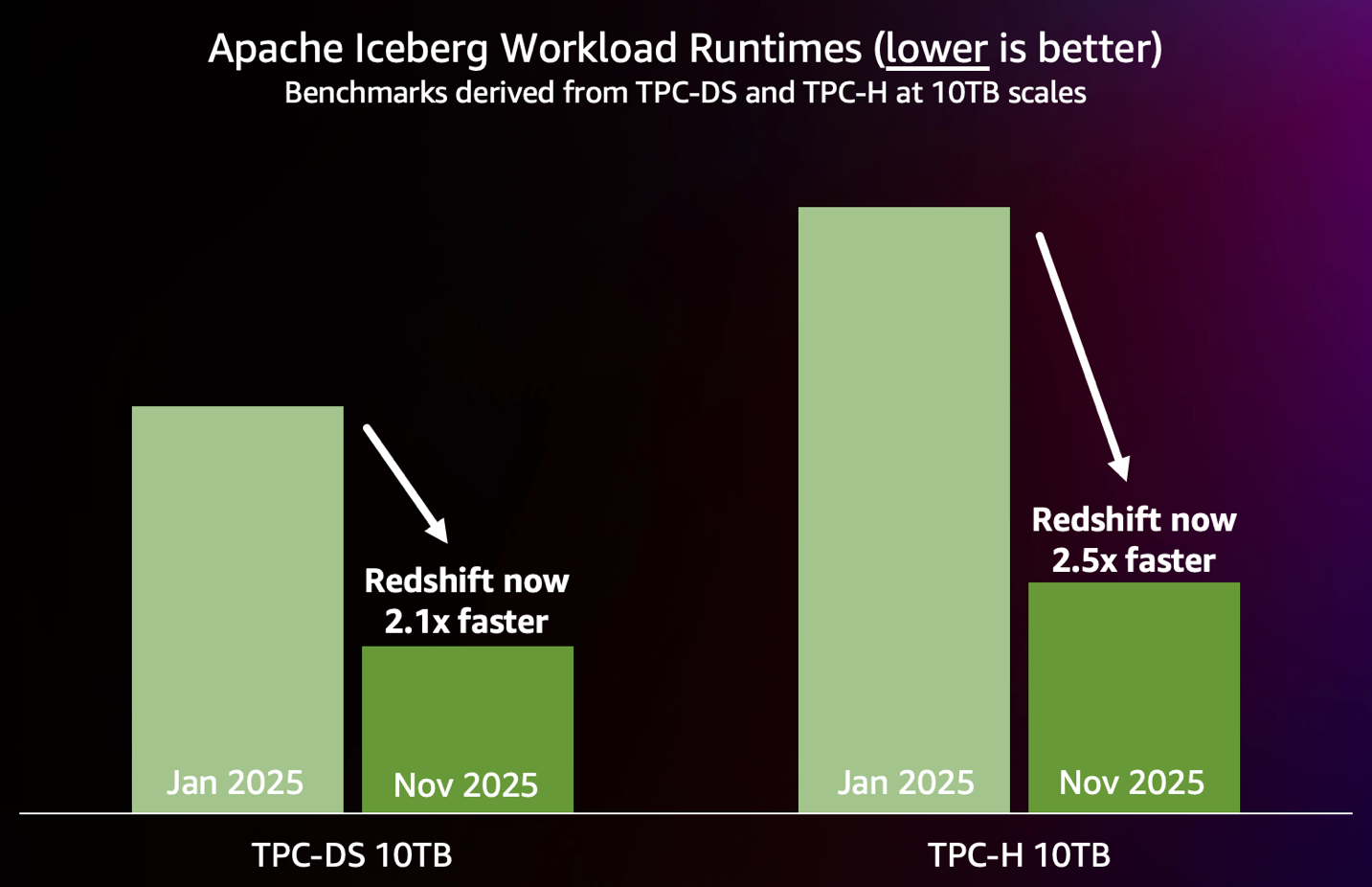
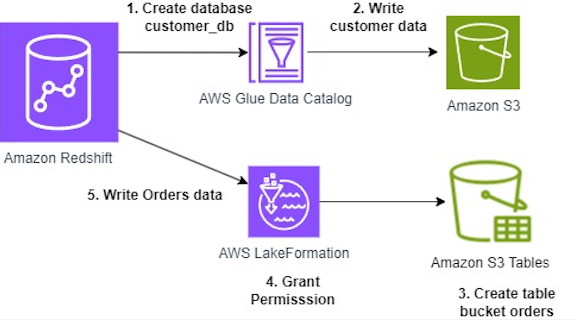
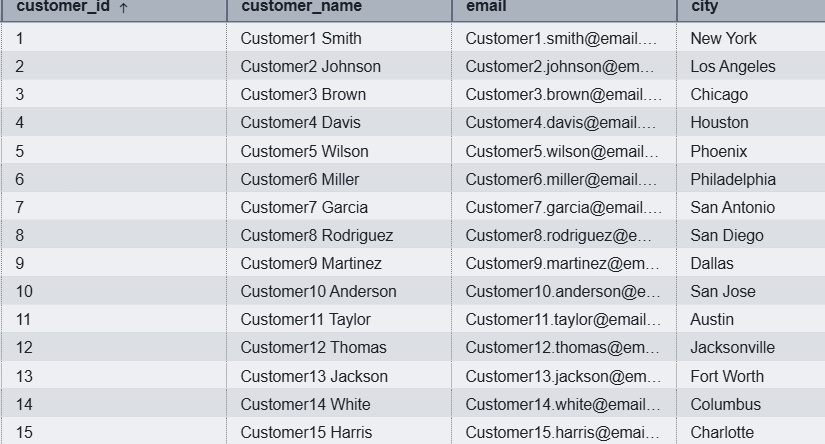 Figure 2: Result from demo_iceberg.customer
Figure 2: Result from demo_iceberg.customer










 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications. Ankur Bhanawat is a Consultant with the Professional Services team at AWS based out of Pune, India. He’s an AWS certified professional in three areas and specialized in databases and serverless technologies. He has experience in designing, migrating, deploying, and optimizing workloads on the AWS Cloud.
Ankur Bhanawat is a Consultant with the Professional Services team at AWS based out of Pune, India. He’s an AWS certified professional in three areas and specialized in databases and serverless technologies. He has experience in designing, migrating, deploying, and optimizing workloads on the AWS Cloud. Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernizing analytical solutions. His background is in data warehouse architecture, development, and administration. He has been in data and analytical field for over 14 years.
Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernizing analytical solutions. His background is in data warehouse architecture, development, and administration. He has been in data and analytical field for over 14 years.




 Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in data science and AI/ML. He has extensive experience in optimizing real-time decision-making in High-Frequency Trading (HFT) and applying machine learning to genomics research. Known for leveraging generative AI and advanced analytics, he delivers practical, impactful solutions across industries.
Konstantinos Tzouvanas is a Senior Enterprise Architect on AWS, specializing in data science and AI/ML. He has extensive experience in optimizing real-time decision-making in High-Frequency Trading (HFT) and applying machine learning to genomics research. Known for leveraging generative AI and advanced analytics, he delivers practical, impactful solutions across industries. Marios Parthenios is a Senior Solutions Architect working with Small and Medium Businesses across Central and Eastern Europe. He empowers organizations to build and scale their cloud solutions with a particular focus on Data Analytics and Generative AI workloads. He enables businesses to harness the power of data and artificial intelligence to drive innovation and digital transformation.
Marios Parthenios is a Senior Solutions Architect working with Small and Medium Businesses across Central and Eastern Europe. He empowers organizations to build and scale their cloud solutions with a particular focus on Data Analytics and Generative AI workloads. He enables businesses to harness the power of data and artificial intelligence to drive innovation and digital transformation. Pavlos Kaimakis is a Senior Solutions Architect at AWS who helps customers design and implement business-critical solutions. With extensive experience in product development and customer support, he focuses on delivering scalable architectures that drive business value. Outside of work, Pavlos is an avid traveler who enjoys exploring new destinations and cultures.
Pavlos Kaimakis is a Senior Solutions Architect at AWS who helps customers design and implement business-critical solutions. With extensive experience in product development and customer support, he focuses on delivering scalable architectures that drive business value. Outside of work, Pavlos is an avid traveler who enjoys exploring new destinations and cultures. John Mousa is a Senior Solutions Architect at AWS. He helps power and utilities and healthcare and life sciences customers as part of the regulated industries team in Germany. John has interest in the areas of service integration, microservices architectures, as well as analytics and data lakes. Outside of work, he loves to spend time with his family and play video games.
John Mousa is a Senior Solutions Architect at AWS. He helps power and utilities and healthcare and life sciences customers as part of the regulated industries team in Germany. John has interest in the areas of service integration, microservices architectures, as well as analytics and data lakes. Outside of work, he loves to spend time with his family and play video games. Martin Milenkoski is a Software Development Engineer on the Amazon Redshift team, currently focusing on data lake performance and query optimization. Martin holds an MSc in Computer Science from the École Polytechnique Fédérale de Lausanne.
Martin Milenkoski is a Software Development Engineer on the Amazon Redshift team, currently focusing on data lake performance and query optimization. Martin holds an MSc in Computer Science from the École Polytechnique Fédérale de Lausanne. Kalaiselvi Kamaraj is a Sr. Software Development Engineer on the Amazon Redshift team. She has worked on several projects within the Amazon Redshift Query processing team and currently focusing on performance related projects for Amazon Redshift DataLake and query optimizer.
Kalaiselvi Kamaraj is a Sr. Software Development Engineer on the Amazon Redshift team. She has worked on several projects within the Amazon Redshift Query processing team and currently focusing on performance related projects for Amazon Redshift DataLake and query optimizer. Jonathan Katz is a Principal Product Manager – Technical on the AWS Analytics team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor, including to the pgvector project.
Jonathan Katz is a Principal Product Manager – Technical on the AWS Analytics team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor, including to the pgvector project.
 Gregory Knowles is a data and AI specialist solution architect at AWS, focusing on the UK public sector. With extensive experience in cloud-based architectures, Greg guides public sector customers in implementing modern data solutions. His expertise spans governance, analytics, and AI/ML. Greg’s passion lies in accelerating transformation and innovation to improve productivity and outcomes. He has successfully led projects that moved data systems into the cloud, adopted new data architectures, and implemented AI at scale in production.
Gregory Knowles is a data and AI specialist solution architect at AWS, focusing on the UK public sector. With extensive experience in cloud-based architectures, Greg guides public sector customers in implementing modern data solutions. His expertise spans governance, analytics, and AI/ML. Greg’s passion lies in accelerating transformation and innovation to improve productivity and outcomes. He has successfully led projects that moved data systems into the cloud, adopted new data architectures, and implemented AI at scale in production. Abhinav Tripathy is a Software Engineer and Security Guardian at AWS, where he develops Amazon Q generative SQL by combining machine learning, databases, and web systems. Abhinav is passionate about building scalable web systems from scratch that solve real customer challenges. Outside of work, he enjoys traveling, watching soccer, and playing badminton.
Abhinav Tripathy is a Software Engineer and Security Guardian at AWS, where he develops Amazon Q generative SQL by combining machine learning, databases, and web systems. Abhinav is passionate about building scalable web systems from scratch that solve real customer challenges. Outside of work, he enjoys traveling, watching soccer, and playing badminton. Erol Murtezaoglu is a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems, in order to deliver solutions that exceed expectations.
Erol Murtezaoglu is a Technical Product Manager at AWS, is an inquisitive and enthusiastic thinker with a drive for self-improvement and learning. He has a strong and proven technical background in software development and architecture, balanced with a drive to deliver commercially successful products. Erol highly values the process of understanding customer needs and problems, in order to deliver solutions that exceed expectations.
 Saeed Barghi is a Sr. Specialist Solutions Architect at Amazon Web Services (AWS) specializing in architecting enterprise data platforms and AI solutions. Based in Melbourne, Australia, Saeed works with public sector customers in Australia and New Zealand and helps his customers build fit-for-purpose and future-proof data platforms and AI solutions.
Saeed Barghi is a Sr. Specialist Solutions Architect at Amazon Web Services (AWS) specializing in architecting enterprise data platforms and AI solutions. Based in Melbourne, Australia, Saeed works with public sector customers in Australia and New Zealand and helps his customers build fit-for-purpose and future-proof data platforms and AI solutions. Miroslaw (Mick) Mioduszewski is the Director of Analytics at Revenue NSW Department of Customer service in NSW. He held multiple C-level roles in private and public companies as well as government, e.g. COO and CIO, as well as serving as company director. Mick holds computer science and business degrees, is a fellow of the Australian Institute of Company Directors and an industry fellow at the University of technology, Sydney.
Miroslaw (Mick) Mioduszewski is the Director of Analytics at Revenue NSW Department of Customer service in NSW. He held multiple C-level roles in private and public companies as well as government, e.g. COO and CIO, as well as serving as company director. Mick holds computer science and business degrees, is a fellow of the Australian Institute of Company Directors and an industry fellow at the University of technology, Sydney. Moha Alsouli is a Public Sector Solutions Architect at Amazon Web Services (AWS) in Sydney. He is dedicated to supporting state and local government customers deliver citizen services, through solution design, reviews, optimisation, and architecture guidance. Moha is also specialising in generative artificial intelligence (AI) on AWS.
Moha Alsouli is a Public Sector Solutions Architect at Amazon Web Services (AWS) in Sydney. He is dedicated to supporting state and local government customers deliver citizen services, through solution design, reviews, optimisation, and architecture guidance. Moha is also specialising in generative artificial intelligence (AI) on AWS.





