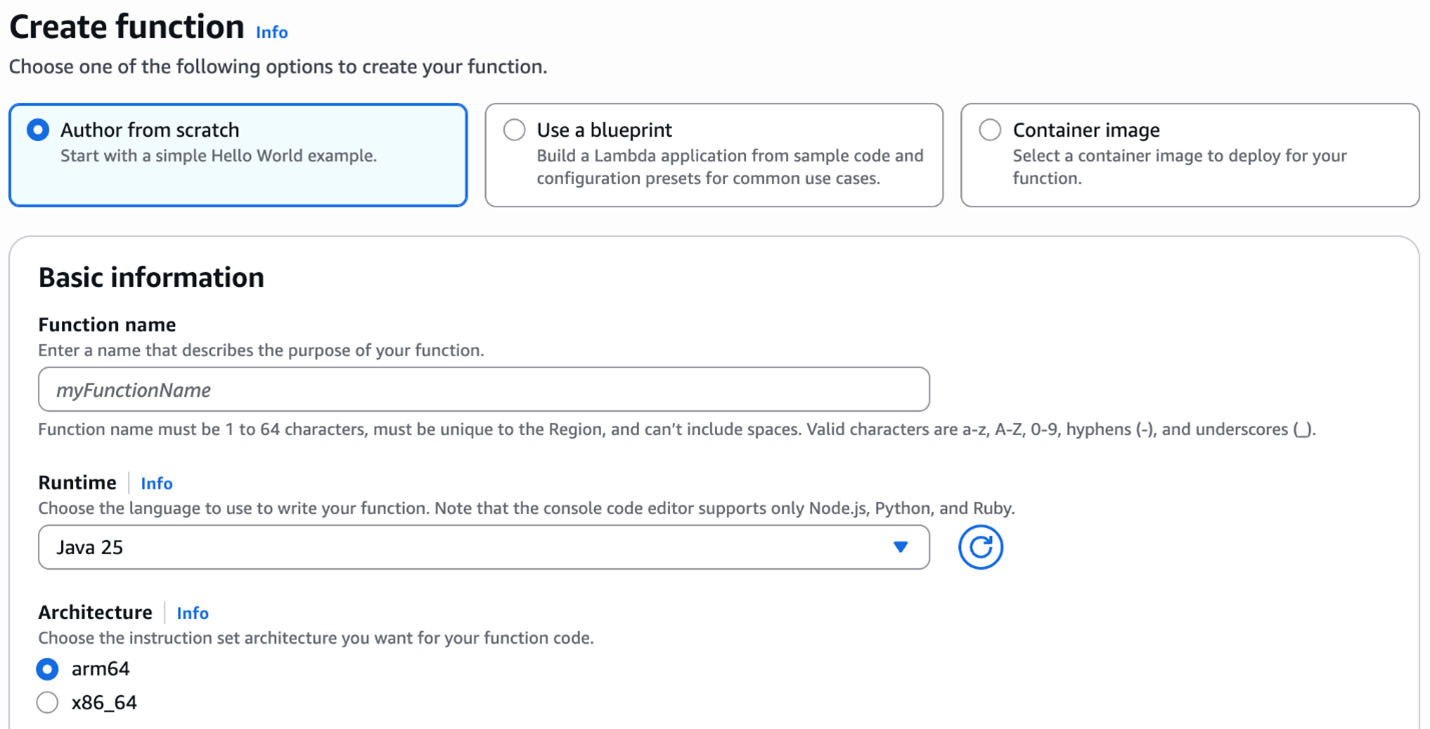
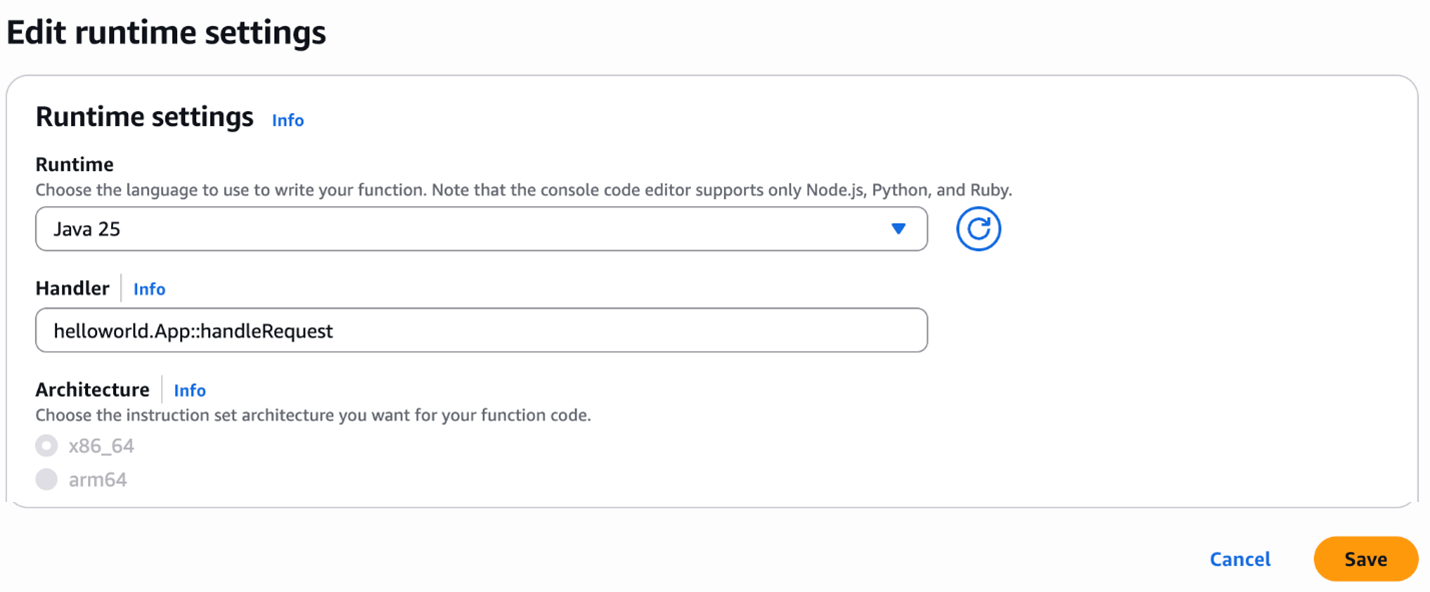
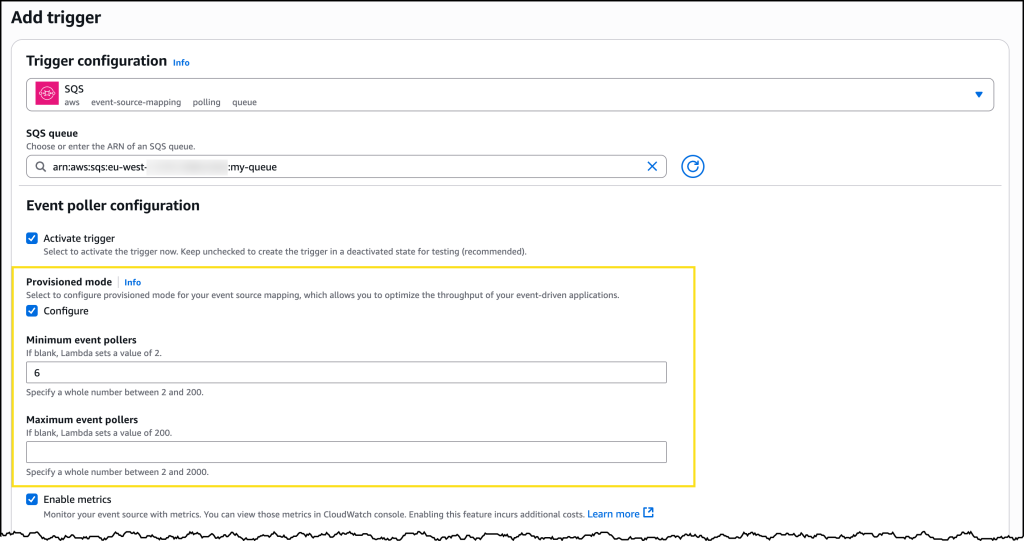
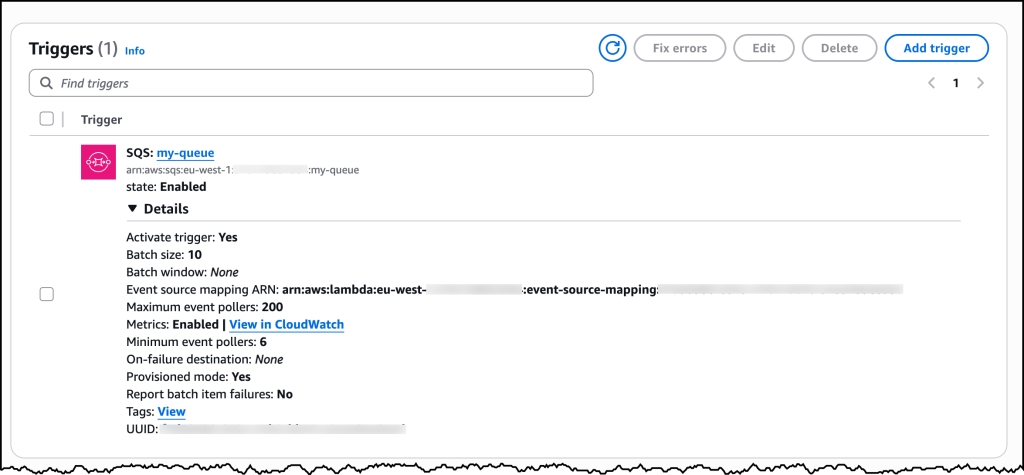
Post Syndicated from Philip Whiteside original https://aws.amazon.com/blogs/compute/handle-unpredictable-processing-times-with-operational-consistency-when-integrating-asynchronous-aws-services-with-an-aws-step-functions-state-machine/
Integrating asynchronous AWS services with an AWS Step Functions state machine, presents a challenge when building serverless applications on Amazon Web Services (AWS). Services such as Amazon Translate, Amazon Macie, and Amazon Bedrock Data Automation (BDA) excel at handling long-running operations that can take more than 10 minutes to complete because of their asynchronous nature. Asynchronous services return an immediate 200 OK response, indicating that the request has succeeded, upon job submission (see the API response syntax of StartTextTranslationJob in Amazon Translate, CreateClassificationJob in Macie, and InvokeDataAutomationAsync in BDA), rather than waiting for the actual task completion and results.
In this post, we explore using AWS Step Function state machine with asynchronous AWS services, look at some scenarios where the processing time can be unpredictable, explain when traditional solutions such as polling (periodically check) fall short, and demonstrate how to implement a generalized callback pattern to handle asynchronous operations into a more manageable synchronous flow. We cover the related architecture, technical implementation, and best practices, and we provide a real-world examples that uses the AWS Cloud Development Kit (AWS CDK). Services used in this generalized callback pattern include Amazon DynamoDB, Amazon EventBridge and AWS Step Functions.
Understanding the issue this solution addresses
Asynchronous operations are designed to handle long-running operations without blocking resources, a design followed by many AWS services. However, these services create challenges in Step Functions workflows by returning immediate 200 OK responses rather than confirming task completion. This breaks the Step Functions execution model, which expects each step to be complete before advancing. Developers often attempt to address this issue through polling loops to repeatedly check the status of operations, an approach that works for containerized applications and Amazon Elastic Compute Cloud (Amazon EC2). For these services, compute resources are already provisioned, but compute resources become problematic in serverless architectures when AWS Lambda functions have a 15-minute execution limit, making them unsuitable for long-running polls.
Step Functions supports Run a Job (.sync) to call a service and have Step Functions wait for a job to complete, but this works only for selected optimized integrations. However, this functionality is limited to specific AWS services such as AWS Glue. Amazon Translate, Macie, and other services are not optimized integrations. If your operation is not listed as working with .sync, it can benefit from the generalized callback pattern covered in this post.
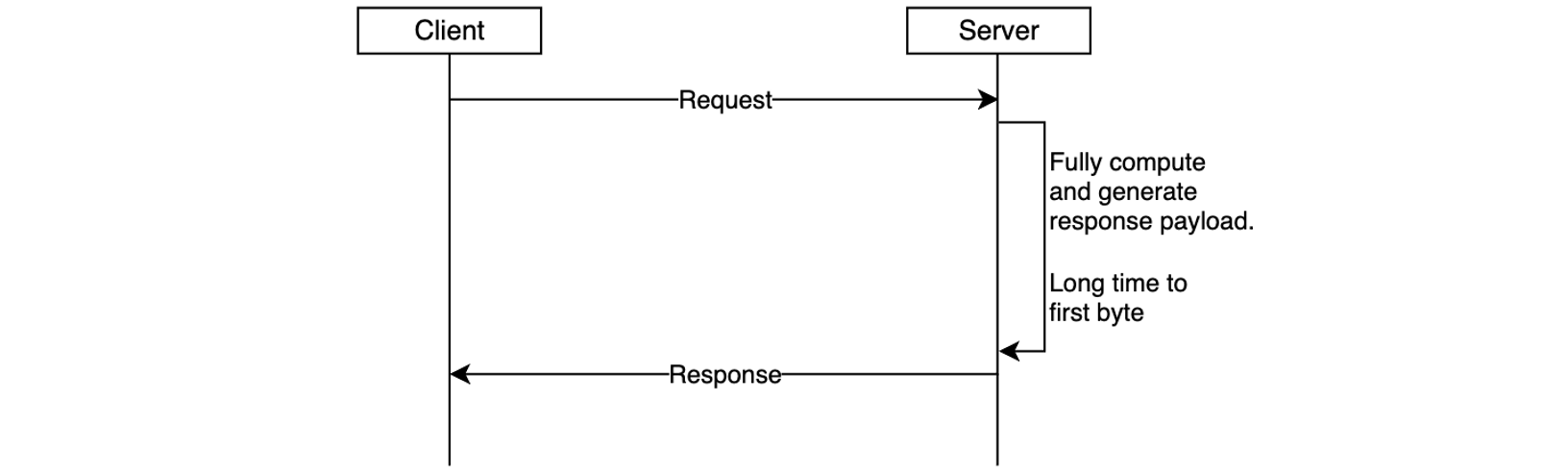
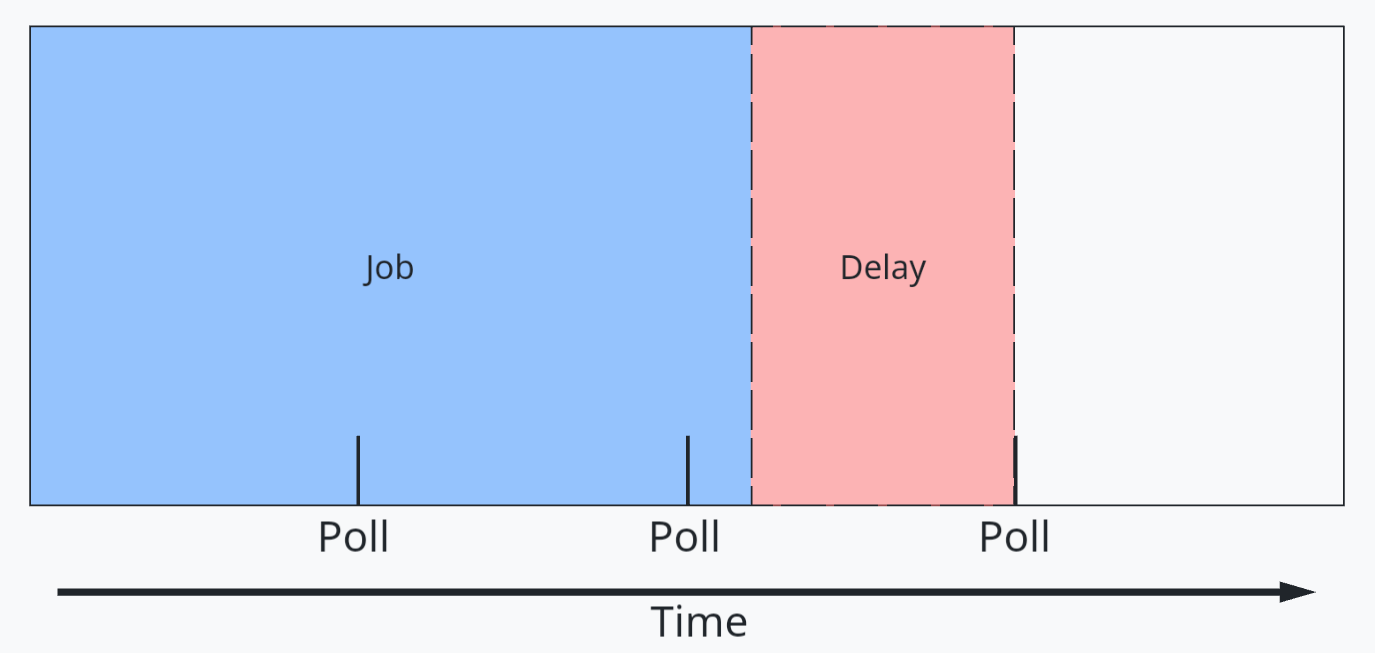
For these non-optimized integrations, an option is to use polling (periodically check). However, polling can lead to additional latency in response because polling times are unlikely to align with job completion. This is shown in the following figure.

Figure 1: A job processing and delay timeline diagram
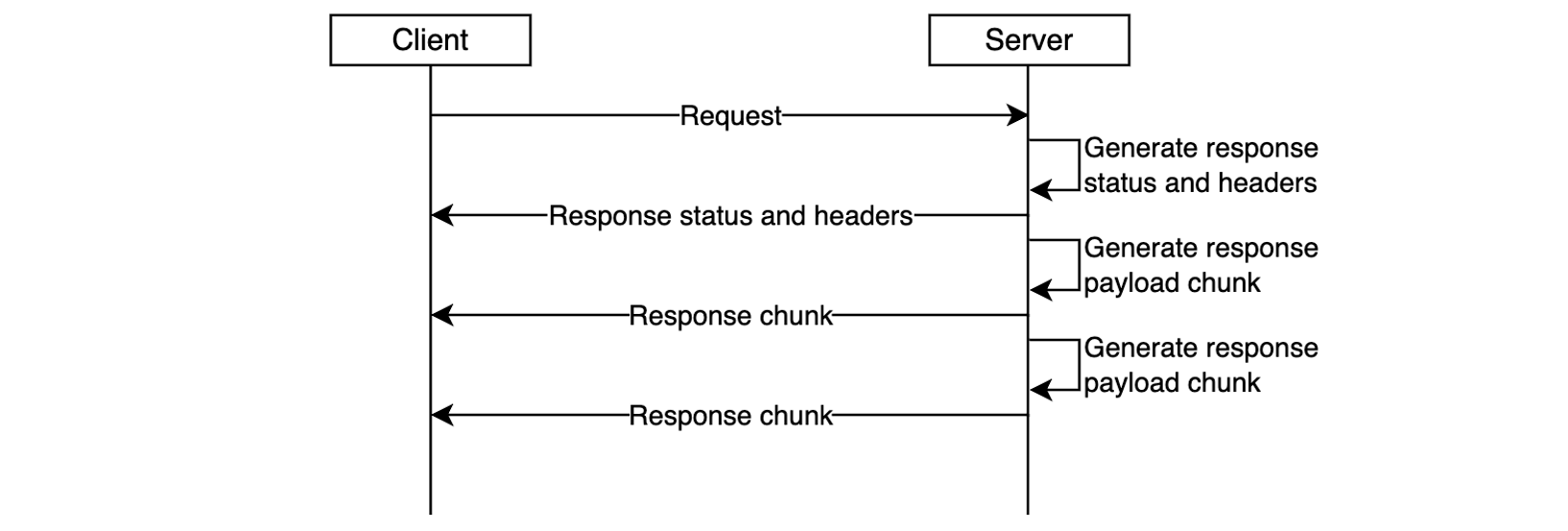
The Step Functions generalized callback pattern can solve this latency issue by pausing execution for up to one year while waiting for task completion (this does not incur additional cost). When such an asynchronous operation finishes, a callback mechanism resumes the workflow where it left off. This generalized callback pattern transforms asynchronous operations into synchronous ones, and it maintains cost efficiency and operational agility.
Scenarios
To help us see where this generalized callback pattern could be applied, let’s look at a few scenarios. Each of these scenarios makes use of AWS Step Functions state machines to run the applications’ workflows.
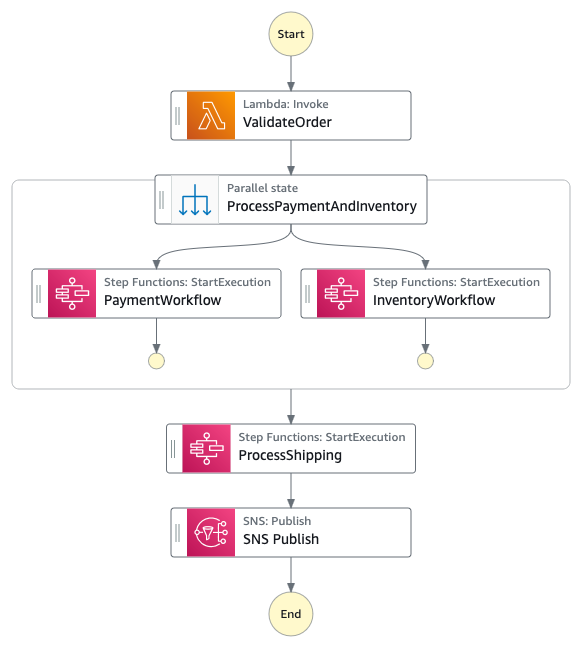
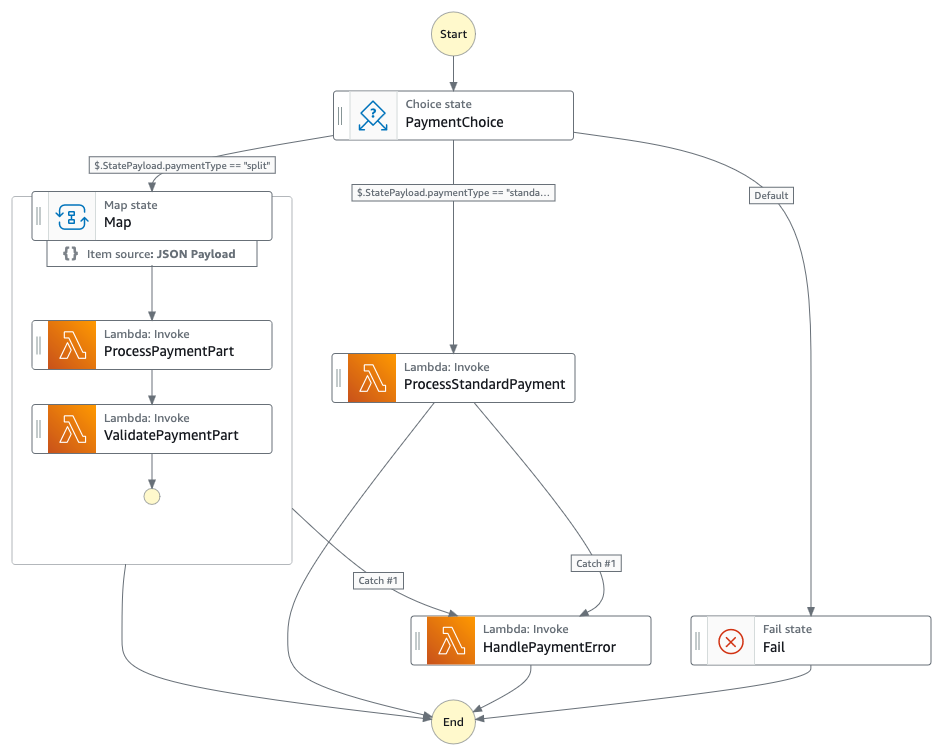
Scenario 1: Document translation with personally identifiable information compliance
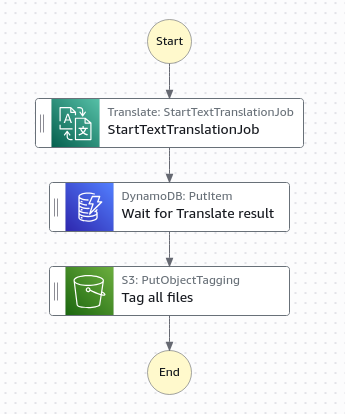
Organizations must manage personally identifiable information (PII) when translating documents because PII can be duplicated across language outputs. For example, when translating a document containing “Jane Doe,” that name appears in both the original and translated versions, creating multiple instances of sensitive data that need compliance measures. Amazon Translate batch translation has a default concurrency of 10, meaning that translations could take more than 10 minutes or be queued for longer periods. Additionally, the Amazon Translate batch translation operation is asynchronous, holding the translation request in a queue until completed. The generalized callback pattern in this post makes sure that Step Functions state machine workflows resume appropriately to apply consistent PII handling across all outputs. In this scenario the design makes use of tagging Amazon Simple Storage Service (Amazon S3) files as containing PII or not, which in turn associates S3 lifecycle policies for specific retention periods to those S3 objects.

Figure 2: A text translation workflow diagram
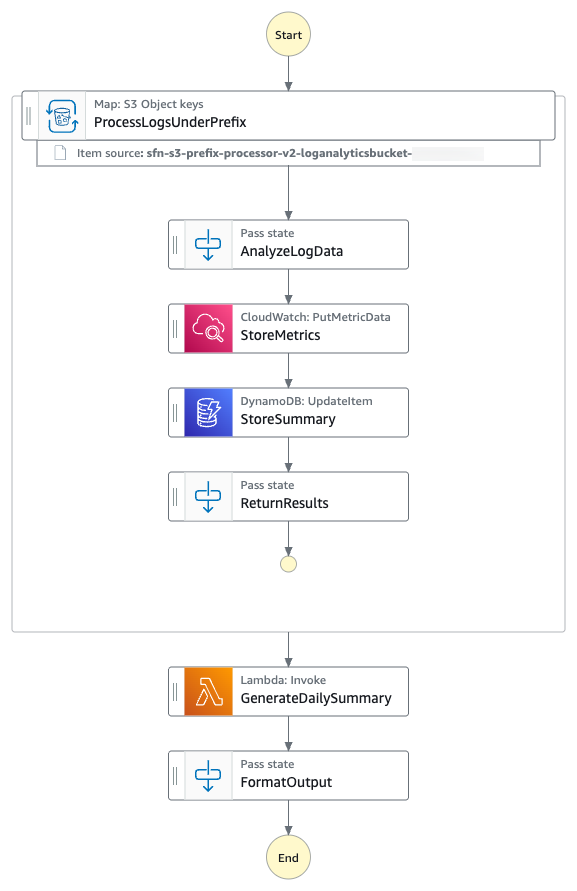
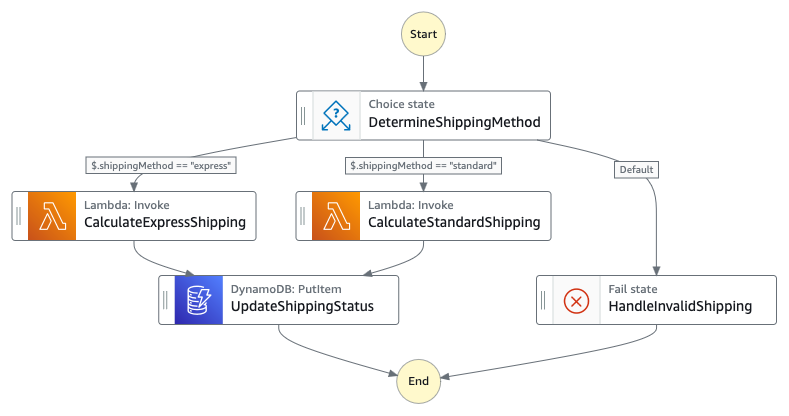
Scenario 2: Using concurrent execution to pause the state machine until processes have completed
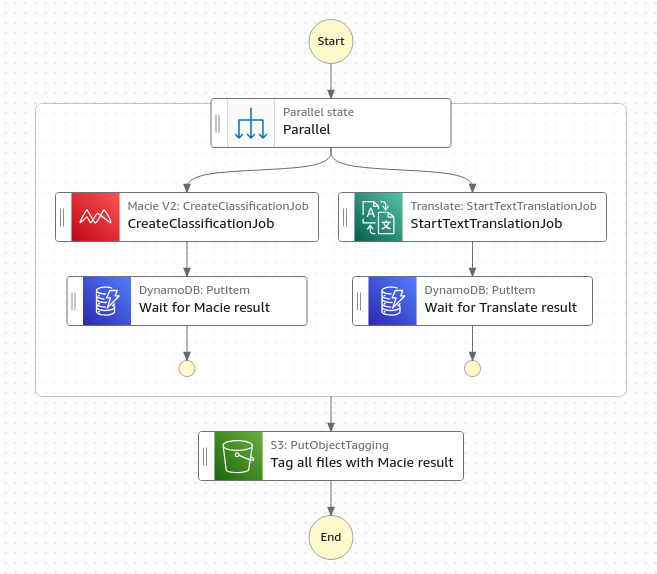
Continuing from scenario 1, Macie and Amazon Translate can run in parallel (each approximately 10 minutes) rather than sequentially (approximately 20 minutes) for a better user experience. Similarly to Amazon Translate batch translation operations being asynchronous, the Macie create classification operation is also asynchronous. Step Functions state machines enable concurrent execution of both service requests. The generalized callback pattern enables the state machine to pause each parallel workflow and resume only when the asynchronous services have completed their jobs. Without this pattern, both services would immediately return 200 OK responses, causing the workflow to continue prematurely before translations or classification results are available. If the classification results are not available later in the workflow, then the appropriate PII tags will not be applied and therefore the appropriate lifecycle retention policy will also not be applied, resulting in not adhering to PII handling practices.

Figure 3: A parallel classification and translation workflow diagram
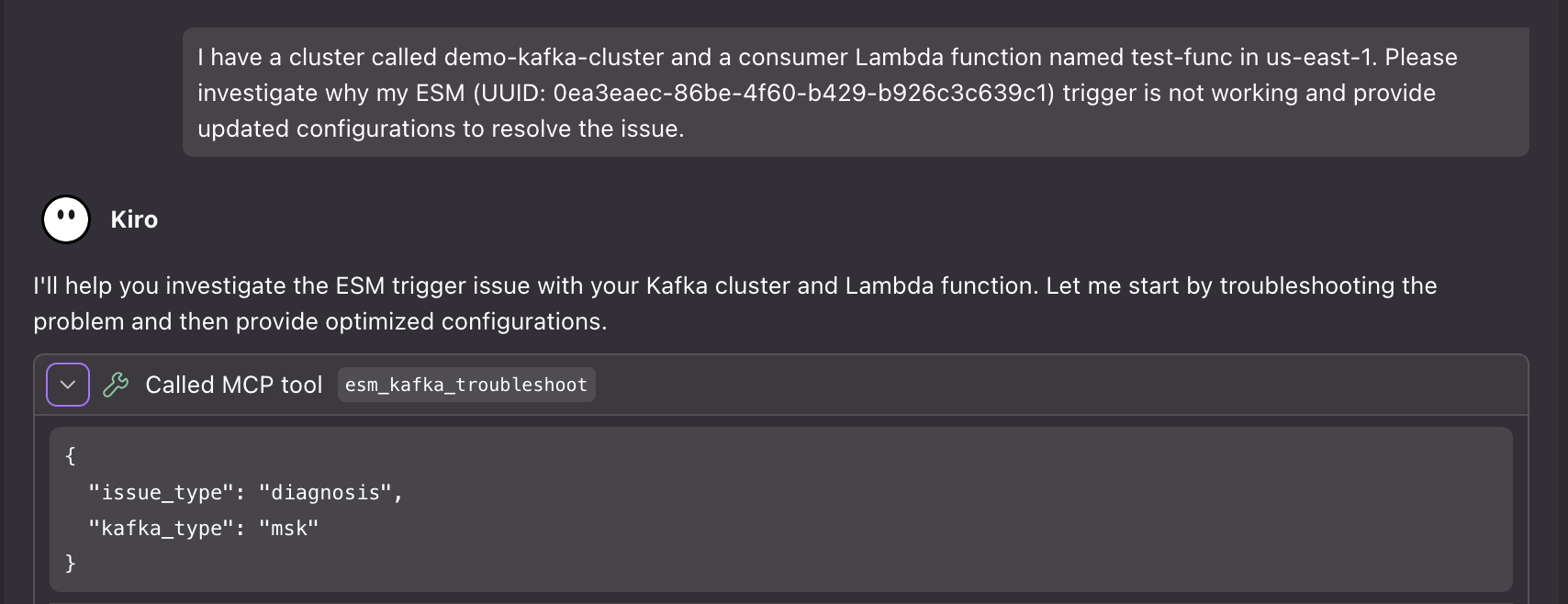
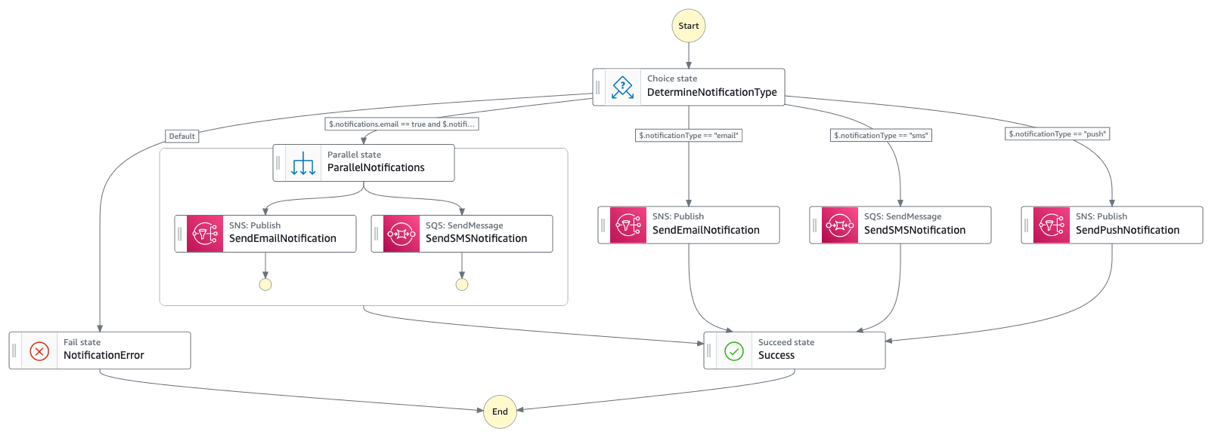
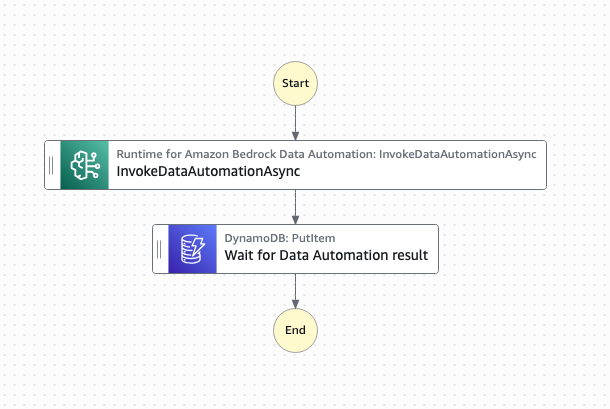
Scenario 3: Intelligent document processing
Organizations that use Bedrock Data Automation for intelligent document processing must take into consideration Regional concurrency limits. BDA has Regional concurrency limits “Max number of concurrent jobs” of 25 jobs in the us-east-1 and us-west-2 Regions. Also, BDA has a concurrency limit of only five jobs in other supported Regions, so large document batches could be queued for extended periods resulting in long processing wait times for the user. This service functionality is handled asynchronously as the duration of the request could be many minutes. The generalized callback pattern makes sure that workflows resume appropriately as soon as a job finishes rather than waiting an arbitrary time to check if the job has been completed. For example, the generalized callback pattern for BDA can be used to enhance the solution outlined in the blog post, Scalable intelligent document processing using Amazon Bedrock Data Automation.

Figure 4: A data automation workflow diagram
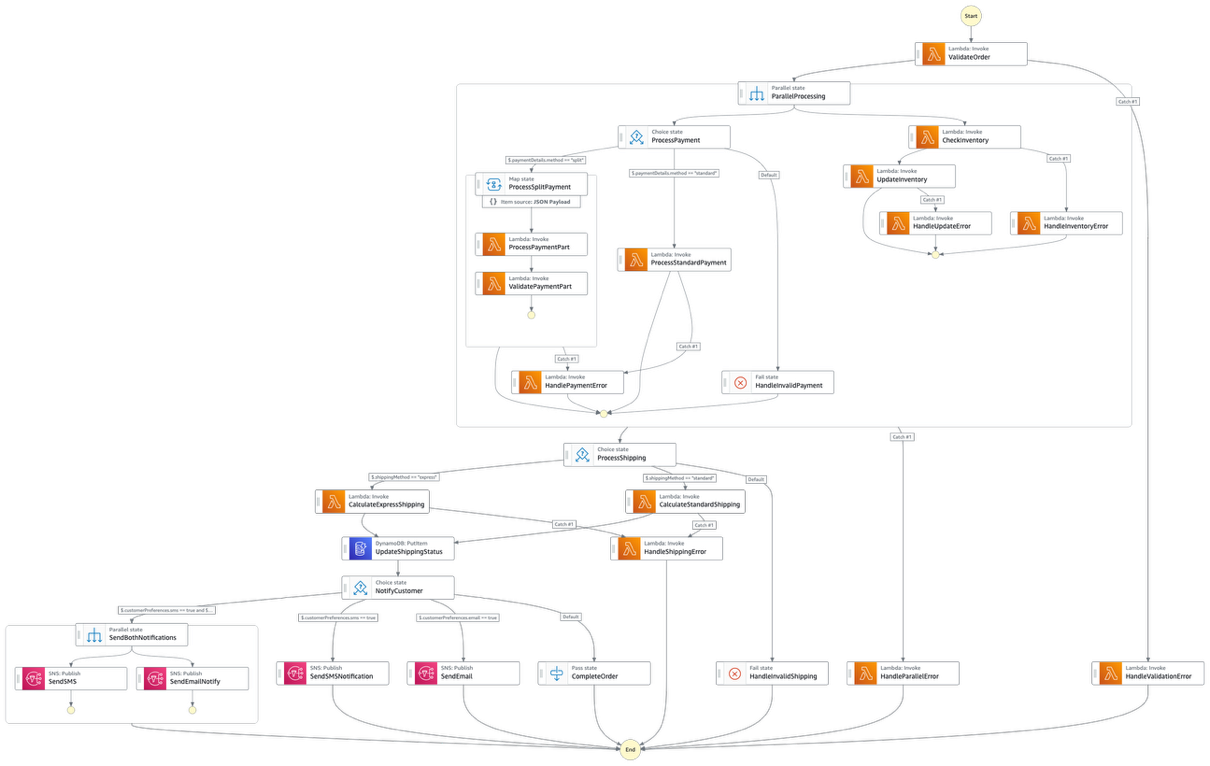
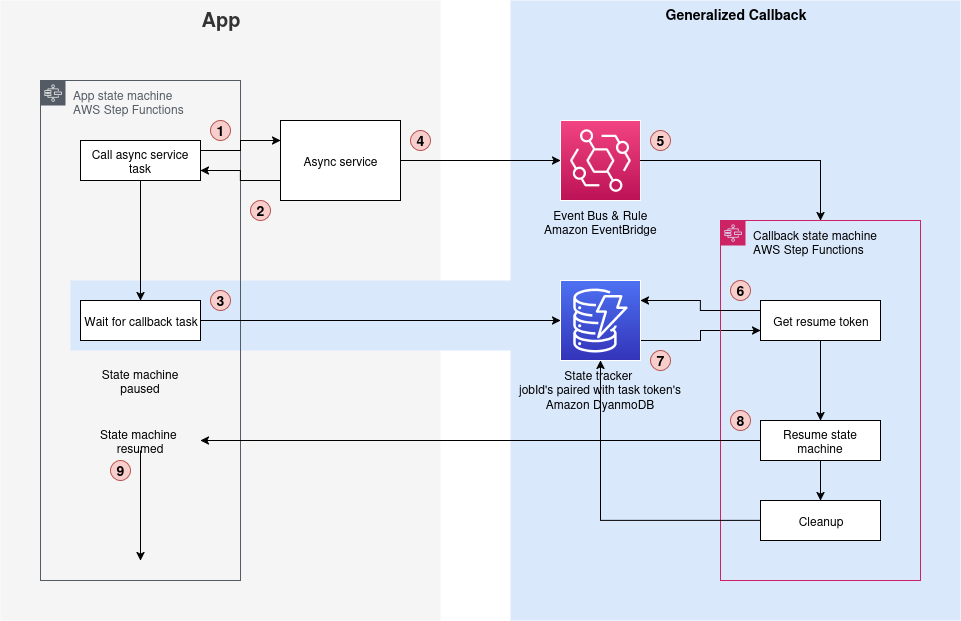
Solution architecture
The following architecture diagram shows the generalized callback pattern (the blue section on the right side) integrated with your existing application (the grey section on the left side).

Figure 5: The Step Functions generalized callback architecture
Key components of this post’s solution architecture
This generalized callback pattern architecture consists of four essential components working together. Each component plays a specific role while maintaining cost efficiency and operational reliability. The following components form the foundation of this pattern:
- Step Functions task: Implements the “Wait for Callback” task state generating unique task tokens for workflow resumption.
- EventBridge rule: Monitors asynchronous service completion events and is customizable for different service patterns. AWS services make use of an event bus to route service event notifications to other services, such as job completions.
- DynamoDB: Provides persistent storage correlating job IDs with task tokens for quick lookup.
- Step Functions state machine: Manages the resume process and makes sure of proper cleanup of stored tokens.
Solution process
This generalized callback pattern operates through a coordinated sequence of four key steps. Each step builds upon the previous one. The following process demonstrates how the pattern manages workflow execution. The diagram above shows more detailed steps following these key steps.
- Start the asynchronous operation for which you want to wait for completion. The asynchronous service responds with success (200 OK) and the state machine continues. Initiating an Amazon Translate batch translation operation is one example of such an asynchronous operation.
- Trigger the generalized callback pattern with the “Wait for Callback” capability. Pair the task token with the jobId in DynamoDB using the unique jobId as the primary key. Example:
{
id = translationJobId,
token = stepFunctionTaskToken
}
- Monitor for completion: When the asynchronous service completes the requested job, such as translation of documents, an event is created in EventBridge that contains the jobId and status. Example:
{
jobId = translationJobId,
status = complete
}
- Resume workflow: The EventBridge rule triggers the workflow to resume, which looks up the task token using the jobId, resumes the paused Step Functions execution, and cleans up the database entry.
Not every service creates events for every action, so validate that your service operation generates the expected events. For example, Macie does not create events when no findings are discovered. In these cases, implement more event generation mechanisms through Amazon CloudWatch Logs subscriptions that trigger Lambda functions to create custom events.
Technical implementation of the solution
For rapid deployment of this post’s solution, AWS CDK users can use this sample CDK pattern with all key components. Alternatively, you can implement the individual components yourself by using the following steps, with each component customizable to your requirements.
Some of the JSON-based snippets below are Amazon States Language (ASL) snippets, which is the language that defines an AWS Step Functions state machine. State machines can be built in the AWS Console using the drag and drop visual builder, or with ASL. The visual builder generates this ASL and you can toggle to view/edit the workflow code (ASL).
Use a Step Functions task that supports “WaitForCallback” to store task token in DynamoDB
Use a Step Functions task that supports ”WaitForCallback” to store the task token in DynamoDB alongside the job ID from the asynchronous service.
AWS services generate a unique ID for that service which refers to that job/request/action. DynamoDB holds the mappings between job IDs and task tokens, supporting multiple state machines paused in parallel with concurrent execution. To prevent clashes when different asynchronous services generate overlapping IDs (for example, if Service A and Service B both generate ID “12345”), use separate DynamoDB tables for each service to maintain ID uniqueness. The sample AWS CDK pattern demonstrates this approach by providing dedicated DynamoDB tables and Step Functions state machines for each service integration. This ID-token structure allows for quick lookups for workflow resumption and cleanup.
The following ASL accomplishes this by using a DynamoDB PutItem task:
"DynamoDB PutItem": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Parameters": {
"TableName": "resumeTokenSessionTable",
"Item": {
"id": { "S.$": "$.JobId" },
"token": { "S.$": "$$.Task.Token" },
"ttl": { "S.$": "$.ttl" }
},
"ConditionExpression": "attribute_not_exists(id)"
},
"Next": "XXXX"
}
In this example, the Item object stores three values: the job ID ($.JobId), the task token ($$.Task.Token), and a TTL value ($.ttl). The ttl field configures Time to Live for automatic cleanup based on your service’s expected completion time. Since this stores only three small string values, data usage per entry is minimal. The primary consideration is the number of concurrent operations, as each active asynchronous job requires one DynamoDB entry until completion or TTL expiration.
The DynamoDB table uses “id” as the primary key and includes a “token” attribute. These fields are essential for the “WaitForCallback” pattern: the “id” (job ID) allows your asynchronous service to look up the correct entry, while the “token” (Step Functions task token) is what your service sends back to Step Functions to resume the paused workflow. The following JSON shows an example of these values:
{
"id": { "S": "xxxxxxxx-yyyy-zzzz-aaaa-bbbbbbbbbbbb" },
"token": { "S": "11111111-2222-3333-4444-555555555555" },
"ttl": { "S": "1480550400" }
}
When your asynchronous service completes its work, it retrieves the task token using the job ID, then calls Step Functions with that token to resume execution from where it paused.
The task token acts as a unique identifier for resuming execution at the exact pause point. To prevent overriding an existing record when a duplicate id is used, you can specify a “ConditionExpression”. This ASL shows just the ConditionExpression.
“ConditionExpression”: “attribute_not_exists(id)”
Create an EventBridge rule to monitor event patterns from your asynchronous service
EventBridge integration forms the heart of the event-driven resumption mechanism. You can create EventBridge rules to monitor specific event patterns from asynchronous AWS services. Most AWS services automatically publish completion events to default EventBridge at no cost, and you can use the EventBridge rule wizard to identify correct event patterns. For services that do not publish events—such as Macie that creates no events when no findings are discovered—implement shims by using Amazon CloudWatch Logs to trigger Lambda functions that generate custom events. This JSON shows the EventBridge Rule pattern definition.
"EventPattern": {
"source": [
"aws.translate"
],
"detail-type": [
"Translate TextTranslationJob State Change"
],
"detail": {
"jobStatus": [
"COMPLETED"
],
}
}
Resume the workflow
At this point, you know the operation has completed, so you can safely resume the workflow. Using the job ID, call the DynamoDB GetItem operation to receive the task token. This ASL shows the task definition to get the task token for a given job ID retrieved from the event notification.
"getResumeToken": {
"Next": "sendTaskSuccess",
"Type": "Task",
"ResultPath": "$.getResumeToken",
"Resource": "arn:aws:states:::dynamodb:getItem",
"Parameters": {
"Key": {
"id": { "S.$": "$.id" }
},
"TableName": "resumeTokenSessionTable"
}
}
Use the task token to resume the workflow and then delete the DynamoDB entry for cleanup. This ASL shows the task definition to use the task token to resume the state machine at the point where it was paused at.
"sendTaskSuccess": {
"Next": "deleteResumeToken",
"Type": "Task",
"ResultPath": "$.sendTaskSuccess",
"Resource": "arn:aws:states:::aws-sdk:sfn:sendTaskSuccess",
"Parameters": {
"TaskToken.$": "$.getResumeToken.Item.token.S",
"Output": {
"status": "resume"
}
}
}
This ASL shows the task definition to clean up the DynamoDB to remove the used task token.
"deleteResumeToken": {
"End": true,
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:deleteItem",
"Parameters": {
"Key": {
"id": { "S.$": "$.id" }
},
"TableName": "resumeTokenSessionTable"
}
}
This completes the technical implementation of our solution. With all components in place—the WaitForCallback task, EventBridge rules, workflow resumption logic, and DynamoDB storage—you now have a fully functional generalized callback pattern implementation that eliminates polling and efficiently manages asynchronous operations.
Now that we’ve established how to implement the generalized callback pattern technically, let’s explore the best practices and important considerations that will help you optimize and secure your implementation.
Best practices and considerations
When implementing the generalized callback pattern in AWS Step Functions, it’s essential to understand and apply best practices that optimize costs, enhance security, and ensure efficient operation. This section outlines key considerations and recommendations for implementing the pattern effectively, focusing on cost optimization strategies and security measures that help maintain a robust and secure serverless workflow. By following these guidelines, you can maximise the benefits of the generalized callback pattern while minimising potential risks and unnecessary expenses.
Optimize costs by using this post’s generalized callback pattern
Managing costs for long-running asynchronous operations can present challenges. Traditional polling accumulates unnecessary expenses through repeated state transitions and execution time, but this post’s generalized callback pattern is an event-driven approach that significantly reduces operational costs.
Eliminate polling costs and minimize execution time
The generalized callback pattern reduces costs by eliminating polling transitions and pausing execution during wait periods. For standard workflows billed at $0.000025 per state transition, using just two transitions instead of continuous polling achieves approximately an 87% cost reduction. A 15-minute translation job polling every minute would need 15 transitions as opposed to two with the generalized callback pattern. For express workflows billed at $0.000001 per request and $0.00001667 per GB-second, the pattern delivers significant savings through reduced request count and minimal execution time. Traditional polling keeps workflows active during the entire operation, accumulating execution time charges. By contrast, the generalized callback pattern eliminates execution time charges during the wait period. In the translation job example mentioned previously in this paragraph, this could reduce the execution time from more than 15 minutes to just the seconds needed to start jobs and complete processes.
Increase resource efficiency
The callback pattern increases resource efficiency by removing constant polling, resulting in substantial reduction in CloudWatch logging and associated monitoring costs. This creates a more cost-effective solution with a reduced AWS resource footprint.
Further cost-optimize the callback pattern
Enhance cost efficiency through DynamoDB optimizations. Choose on-demand mode for unpredictable workloads or provisioned mode with auto scaling for consistent patterns, configure auto scaling settings based on usage, and implement TTL to automatically remove expired items without consuming write capacity.
Security considerations for the callback pattern
The callback pattern involves storing task tokens, processing events, and managing workflow resumption across multiple AWS services. Implementing proper access controls is essential to protect the integrity of your workflows and prevent unauthorized access or manipulation of the pattern’s components.
This section outlines the security considerations for the callback pattern, focusing on access controls for data storage and event processing.
Data storage security
Enable DynamoDB encryption at rest by using AWS owned or user managed AWS Key Management Service (AWS KMS) keys. Implement identity-based policies by defining the Step Functions AWS Identity and Access Management (IAM) role actions (such as PutItem, GetItem, and DeleteItem) and resource-based policies that specify which IAM principals can access the table. Together, these help ensure that only authorized state machines access token storage and operations are limited to minimum permissions. Also, configure TTL to automatically remove expired tokens so that these tokens do not accidentally get reused, which can result in errors with resuming the relevant AWS Step Function workflows.
Event processing security
Scope EventBridge rules precisely to match only specific necessary events. For Amazon Translate job completion, rules should explicitly match only translation job completion events, thus preventing unauthorized triggers. IAM roles should follow least-privilege principles so that only specific actions can cause workflows to resume.
Conclusion
The callback pattern presented in this post provides a solution for managing long-running asynchronous operations in serverless architectures. You can use the Step Functions “Wait for Callback” task state with EventBridge and DynamoDB to transform asynchronous services into synchronous workflows without the overhead of polling. This pattern reduces costs, improves efficiency through event-driven architecture, and maintains security through proper access controls. You can use the provided CDK implementation to implement this pattern and adapt it to your specific needs while following recommended security and cost optimization practices.
About the authors
 Maria John is a Senior Solutions Architect at Amazon Web Services, helping customers build solutions on AWS.
Maria John is a Senior Solutions Architect at Amazon Web Services, helping customers build solutions on AWS.
 Philip Whiteside is a Senior Solutions Architect at Amazon Web Services. Philip is passionate about overcoming barriers by utilizing technology.
Philip Whiteside is a Senior Solutions Architect at Amazon Web Services. Philip is passionate about overcoming barriers by utilizing technology.
















 Maria John is a Senior Solutions Architect at Amazon Web Services, helping customers build solutions on AWS.
Maria John is a Senior Solutions Architect at Amazon Web Services, helping customers build solutions on AWS. Philip Whiteside is a Senior Solutions Architect at Amazon Web Services. Philip is passionate about overcoming barriers by utilizing technology.
Philip Whiteside is a Senior Solutions Architect at Amazon Web Services. Philip is passionate about overcoming barriers by utilizing technology.