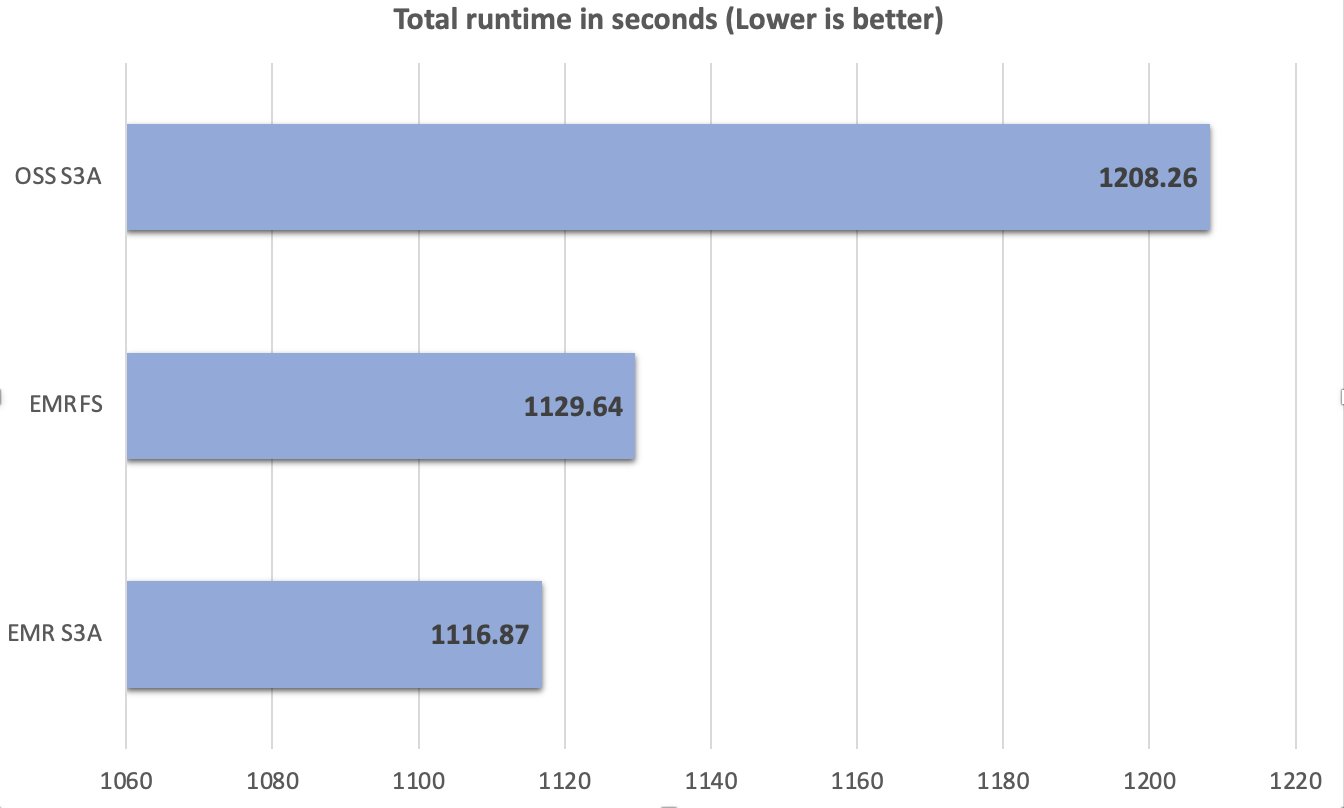
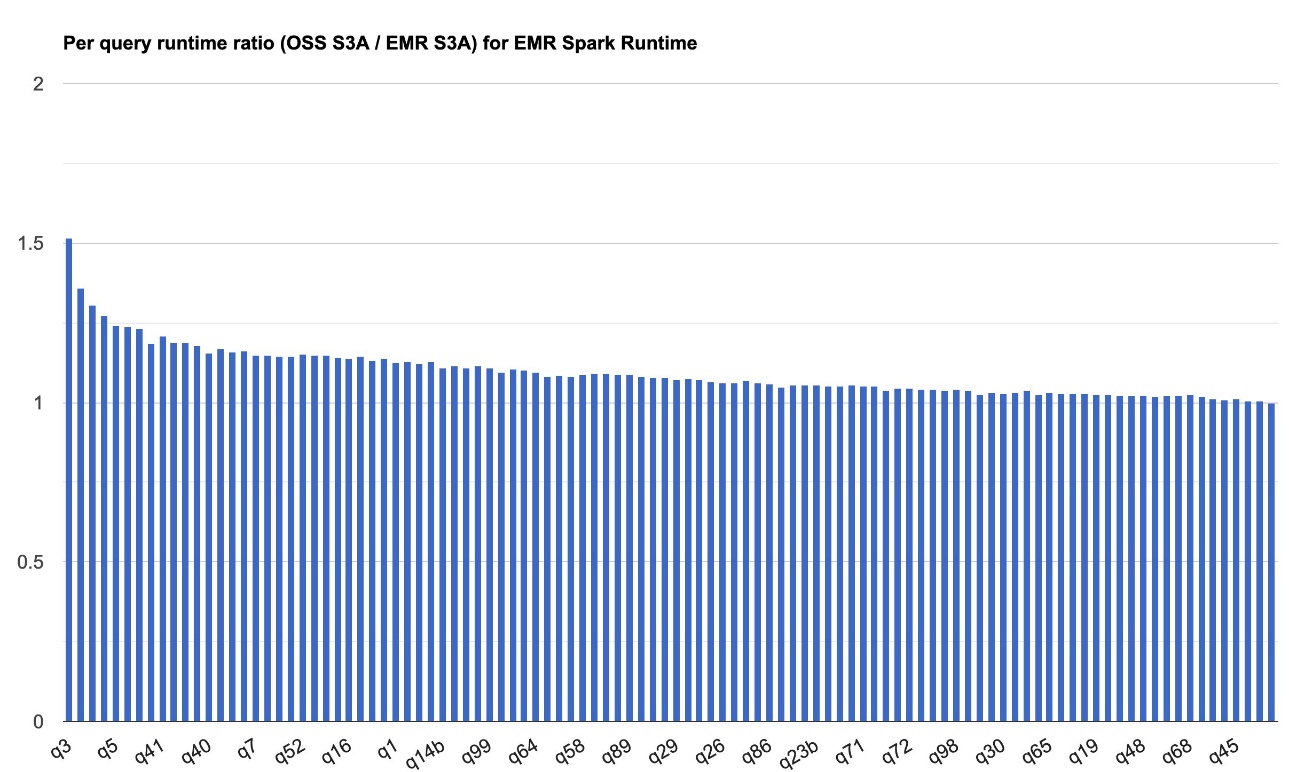
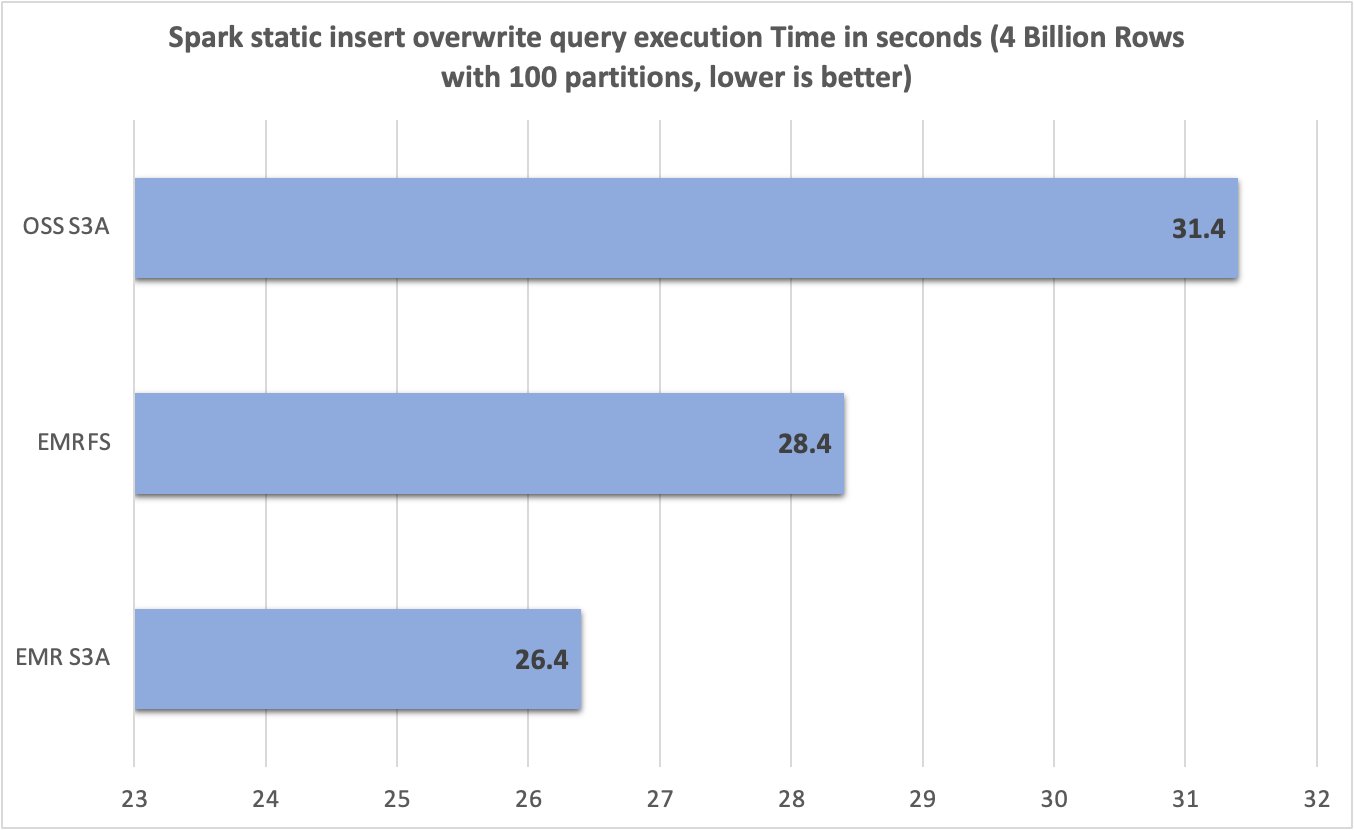
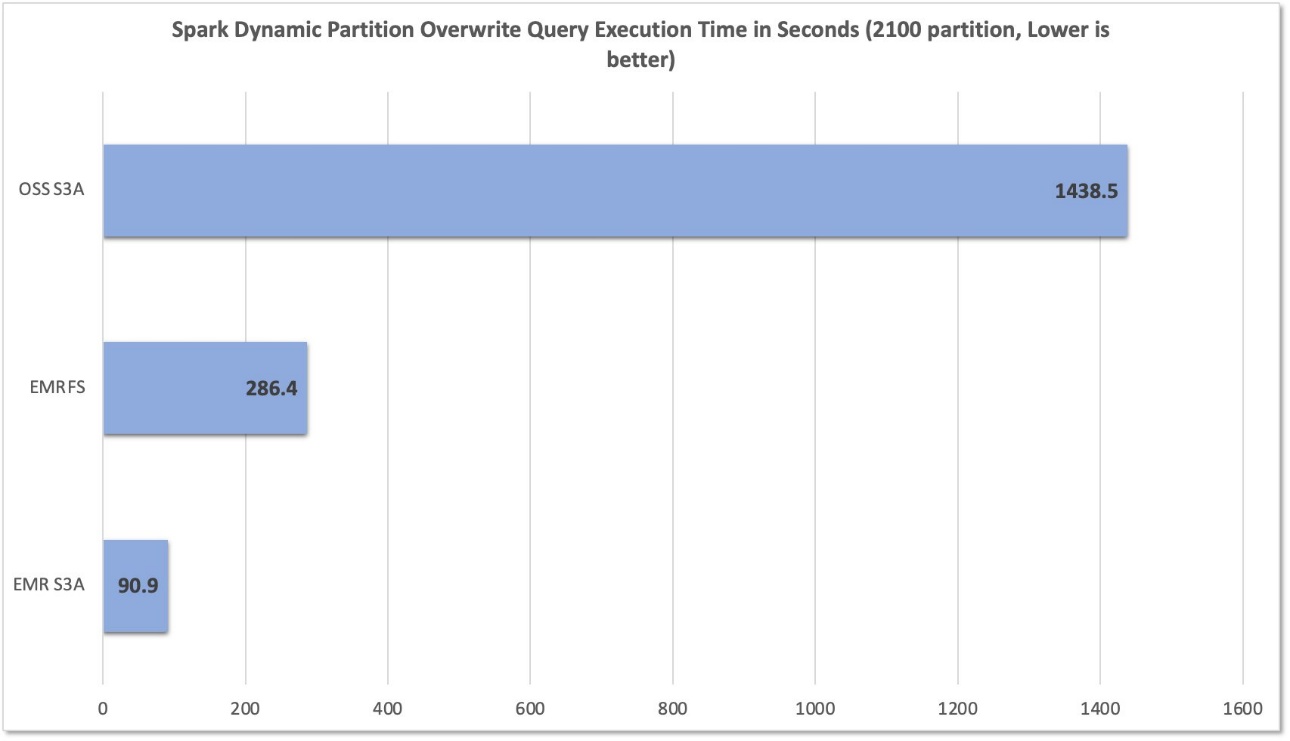
Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/announcing-replication-support-and-intelligent-tiering-for-amazon-s3-tables/
Today, we’re announcing two new capabilities for Amazon S3 Tables: support for the new Intelligent-Tiering storage class that automatically optimizes costs based on access patterns, and replication support to automatically maintain consistent Apache Iceberg table replicas across AWS Regions and accounts without manual sync.
Organizations working with tabular data face two common challenges. First, they need to manually manage storage costs as their datasets grow and access patterns change over time. Second, when maintaining replicas of Iceberg tables across Regions or accounts, they must build and maintain complex architectures to track updates, manage object replication, and handle metadata transformations.
S3 Tables Intelligent-Tiering storage class
With the S3 Tables Intelligent-Tiering storage class, data is automatically tiered to the most cost-effective access tier based on access patterns. Data is stored in three low-latency tiers: Frequent Access, Infrequent Access (40% lower cost than Frequent Access), and Archive Instant Access (68% lower cost compared to Infrequent Access). After 30 days without access, data moves to Infrequent Access, and after 90 days, it moves to Archive Instant Access. This happens without changes to your applications or impact on performance.
Table maintenance activities, including compaction, snapshot expiration, and unreferenced file removal, operate without affecting the data’s access tiers. Compaction automatically processes only data in the Frequent Access tier, optimizing performance for actively queried data while reducing maintenance costs by skipping colder files in lower-cost tiers.
By default, all existing tables use the Standard storage class. When creating new tables, you can specify Intelligent-Tiering as the storage class, or you can rely on the default storage class configured at the table bucket level. You can set Intelligent-Tiering as the default storage class for your table bucket to automatically store tables in Intelligent-Tiering when no storage class is specified during creation.
Let me show you how it works
You can use the AWS Command Line Interface (AWS CLI) and the put-table-bucket-storage-class and get-table-bucket-storage-class commands to change or verify the storage tier of your S3 table bucket.
# Change the storage class
aws s3tables put-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
--storage-class-configuration storageClass=INTELLIGENT_TIERING
# Verify the storage class
aws s3tables get-table-bucket-storage-class \
--table-bucket-arn $TABLE_BUCKET_ARN \
{ "storageClassConfiguration":
{
"storageClass": "INTELLIGENT_TIERING"
}
}S3 Tables replication support
The new S3 Tables replication support helps you maintain consistent read replicas of your tables across AWS Regions and accounts. You specify the destination table bucket and the service creates read-only replica tables. It replicates all updates chronologically while preserving parent-child snapshot relationships. Table replication helps you build global datasets to minimize query latency for geographically distributed teams, meet compliance requirements, and provide data protection.
You can now easily create replica tables that deliver similar query performance as their source tables. Replica tables are updated within minutes of source table updates and support independent encryption and retention policies from their source tables. Replica tables can be queried using Amazon SageMaker Unified Studio or any Iceberg-compatible engine including DuckDB, PyIceberg, Apache Spark, and Trino.
You can create and maintain replicas of your tables through the AWS Management Console or APIs and AWS SDKs. You specify one or more destination table buckets to replicate your source tables. When you turn on replication, S3 Tables automatically creates read-only replica tables in your destination table buckets, backfills them with the latest state of the source table, and continually monitors for new updates to keep replicas in sync. This helps you meet time-travel and audit requirements while maintaining multiple replicas of your data.
Let me show you how it works
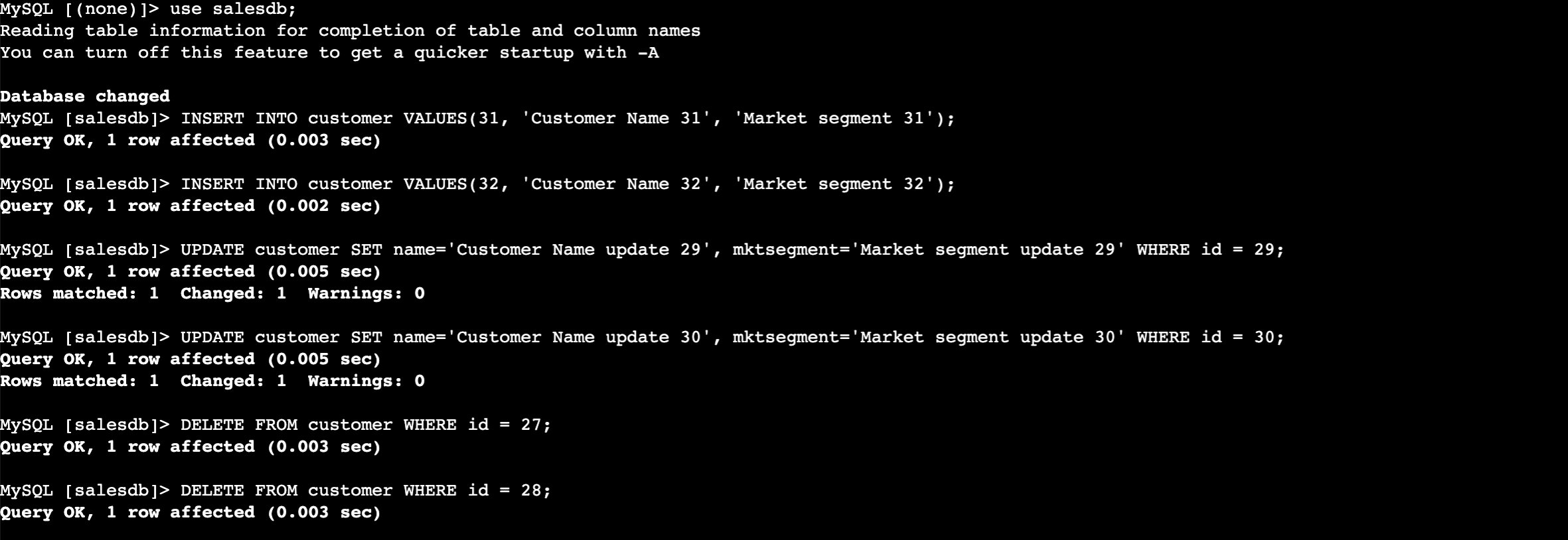
To show you how it works, I proceed in three steps. First, I create an S3 table bucket, create an Iceberg table, and populate it with data. Second, I configure the replication. Third, I connect to the replicated table and query the data to show you that changes are replicated.
For this demo, the S3 team kindly gave me access to an Amazon EMR cluster already provisioned. You can follow the Amazon EMR documentation to create your own cluster. They also created two S3 table buckets, a source and a destination for the replication. Again, the S3 Tables documentation will help you to get started.
I take a note of the two S3 Tables bucket Amazon Resource Names (ARNs). In this demo, I refer to these as the environment variables SOURCE_TABLE_ARN and DEST_TABLE_ARN.
First step: Prepare the source database
I start a terminal, connect to the EMR cluster, start a Spark session, create a table, and insert a row of data. The commands I use in this demo are documented in Accessing tables using the Amazon S3 Tables Iceberg REST endpoint.
sudo spark-shell \
--packages "org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,software.amazon.awssdk:bundle:2.20.160,software.amazon.awssdk:url-connection-client:2.20.160" \
--master "local[*]" \
--conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" \
--conf "spark.sql.defaultCatalog=spark_catalog" \
--conf "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog" \
--conf "spark.sql.catalog.spark_catalog.type=rest" \
--conf "spark.sql.catalog.spark_catalog.uri=https://s3tables.us-east-1.amazonaws.com/iceberg" \
--conf "spark.sql.catalog.spark_catalog.warehouse=arn:aws:s3tables:us-east-1:012345678901:bucket/aws-news-blog-test" \
--conf "spark.sql.catalog.spark_catalog.rest.sigv4-enabled=true" \
--conf "spark.sql.catalog.spark_catalog.rest.signing-name=s3tables" \
--conf "spark.sql.catalog.spark_catalog.rest.signing-region=us-east-1" \
--conf "spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO" \
--conf "spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialProvider" \
--conf "spark.sql.catalog.spark_catalog.rest-metrics-reporting-enabled=false"
spark.sql("""
CREATE TABLE s3tablesbucket.test.aws_news_blog (
customer_id STRING,
address STRING
) USING iceberg
""")
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust1', 'val1')")
spark.sql("SELECT * FROM s3tablesbucket.test.aws_news_blog LIMIT 10").show()
+-----------+-------+
|customer_id|address|
+-----------+-------+
| cust1| val1|
+-----------+-------+So far, so good.
Second step: Configure the replication for S3 Tables
Now, I use the CLI on my laptop to configure the S3 table bucket replication.
Before doing so, I create an AWS Identity and Access Management (IAM) policy to authorize the replication service to access my S3 table bucket and encryption keys. Refer to the S3 Tables replication documentation for the details. The permissions I used for this demo are:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*",
"s3tables:*",
"kms:DescribeKey",
"kms:GenerateDataKey",
"kms:Decrypt"
],
"Resource": "*"
}
]
}After having created this IAM policy, I can now proceed and configure the replication:
aws s3tables-replication put-table-replication \
--table-arn ${SOURCE_TABLE_ARN} \
--configuration '{
"role": "arn:aws:iam::<MY_ACCOUNT_NUMBER>:role/S3TableReplicationManualTestingRole",
"rules":[
{
"destinations": [
{
"destinationTableBucketARN": "${DST_TABLE_ARN}"
}]
}
]
The replication starts automatically. Updates are typically replicated within minutes. The time it takes to complete depends on the volume of data in the source table.
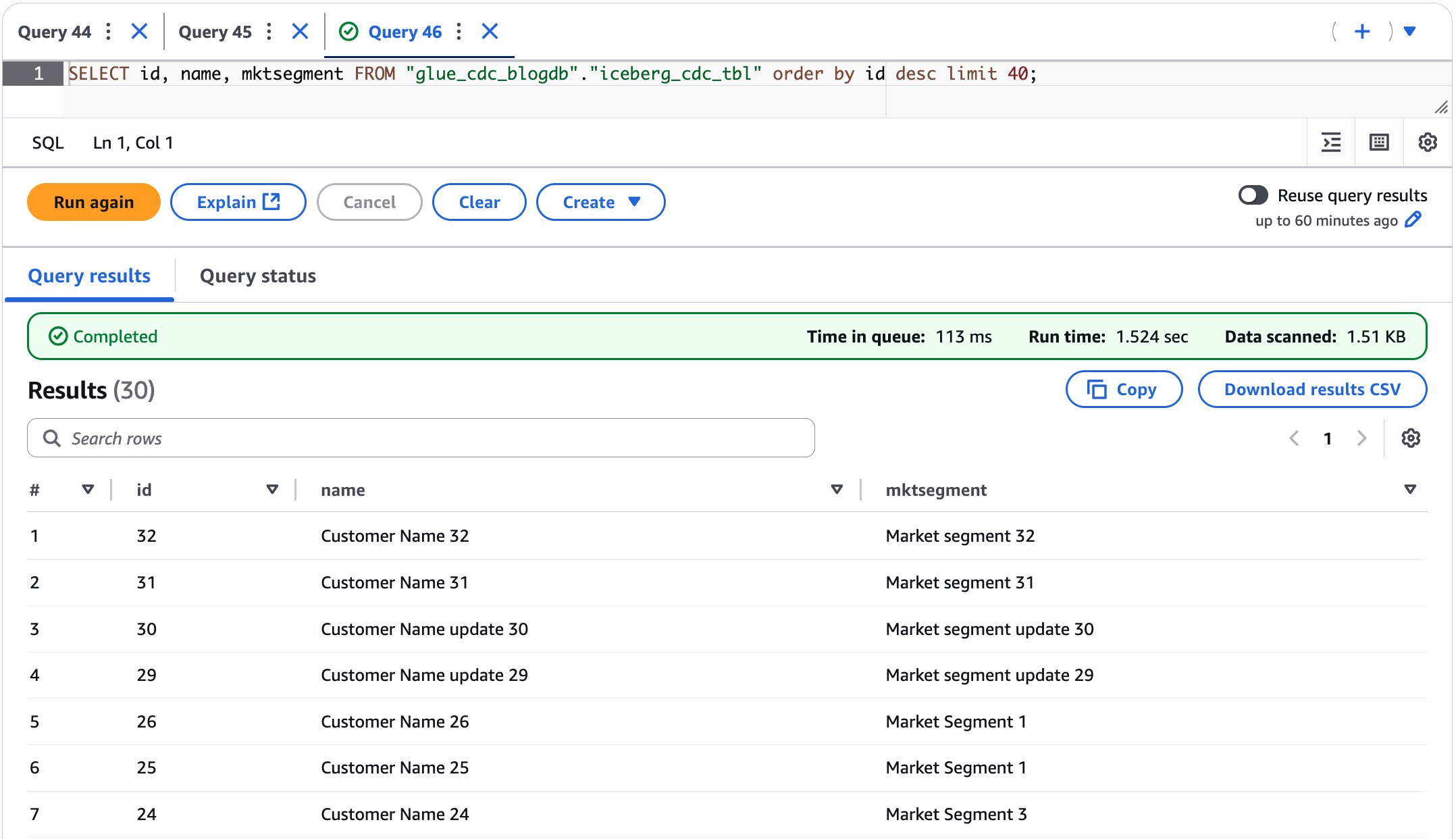
Third step: Connect to the replicated table and query the data
Now, I connect to the EMR cluster again, and I start a second Spark session. This time, I use the destination table.
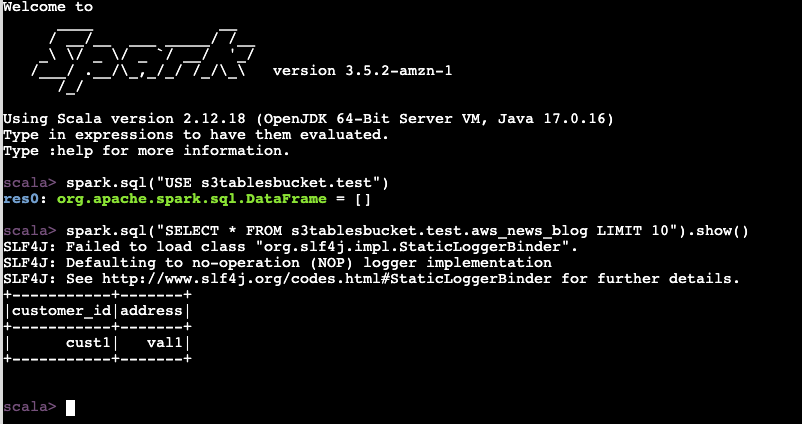
To verify the replication works, I insert a second row of data on the source table.
spark.sql("INSERT INTO s3tablesbucket.test.aws_news_blog VALUES ('cust2', 'val2')")
I wait a few minutes for the replication to trigger. I follow the status of the replication with the get-table-replication-status command.
aws s3tables-replication get-table-replication-status \
--table-arn ${SOURCE_TABLE_ARN} \
{
"sourceTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test/table/e0fce724-b758-4ee6-85f7-ca8bce556b41",
"destinations": [
{
"replicationStatus": "pending",
"destinationTableBucketArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst",
"destinationTableArn": "arn:aws:s3tables:us-east-1:012345678901:bucket/manual-test-dst/table/5e3fb799-10dc-470d-a380-1a16d6716db0",
"lastSuccessfulReplicatedUpdate": {
"metadataLocation": "s3://e0fce724-b758-4ee6-8-i9tkzok34kum8fy6jpex5jn68cwf4use1b-s3alias/e0fce724-b758-4ee6-85f7-ca8bce556b41/metadata/00001-40a15eb3-d72d-43fe-a1cf-84b4b3934e4c.metadata.json",
"timestamp": "2025-11-14T12:58:18.140281+00:00"
}
}
]
}When replication status shows ready, I connect to the EMR cluster and I query the destination table. Without surprise, I see the new row of data.

Additional things to know
Here are a couple of additional points to pay attention to:
- Replication for S3 Tables supports both Apache Iceberg V2 and V3 table formats, giving you flexibility in your table format choice.
- You can configure replication at the table bucket level, making it straightforward to replicate all tables under that bucket without individual table configurations.
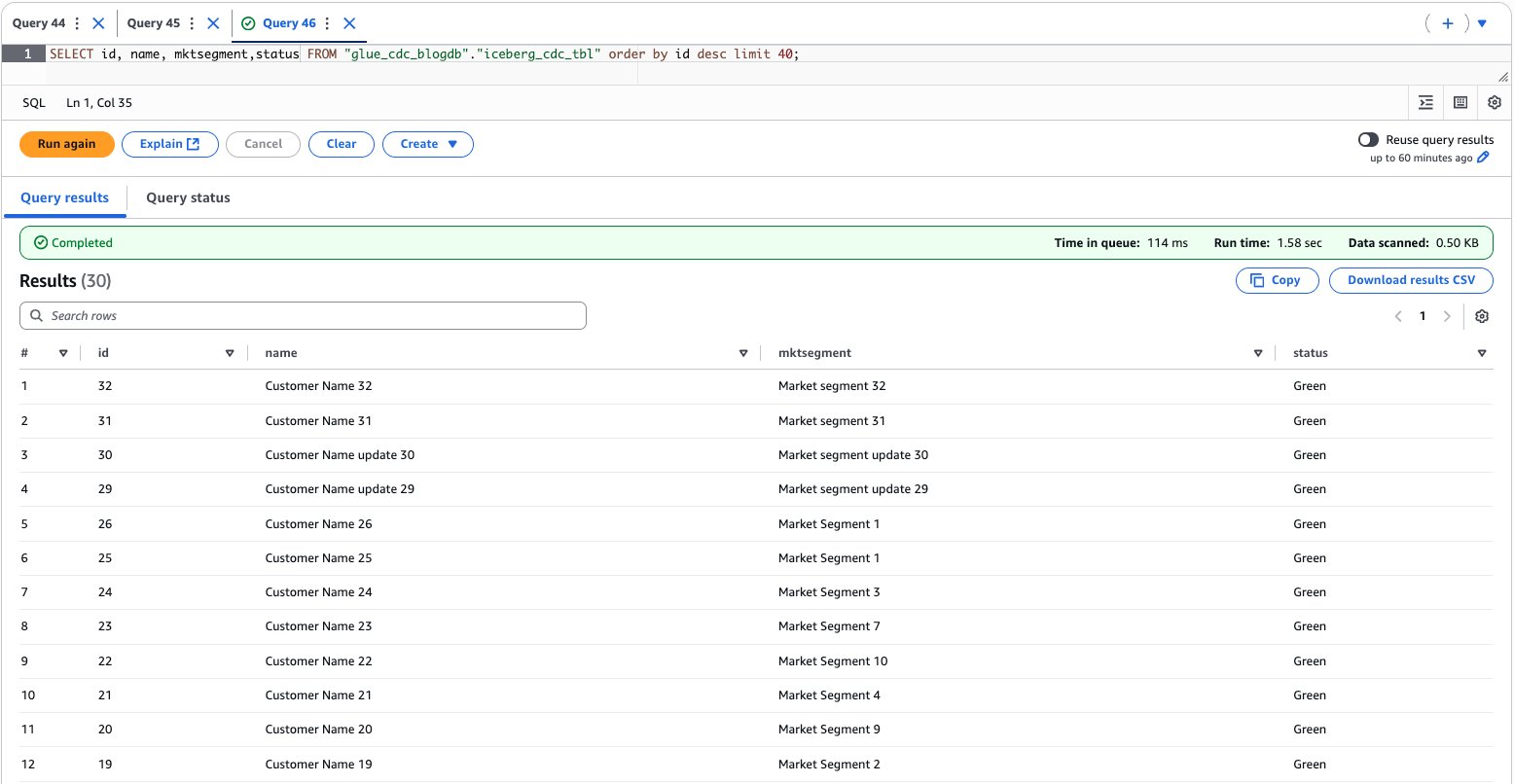
- Your replica tables maintain the storage class you choose for your destination tables, which means you can optimize for your specific cost and performance needs.
- Any Iceberg-compatible catalog can directly query your replica tables without additional coordination—they only need to point to the replica table location. This gives you flexibility in choosing query engines and tools.
Pricing and availability
You can track your storage usage by access tier through AWS Cost and Usage Reports and Amazon CloudWatch metrics. For replication monitoring, AWS CloudTrail logs provide events for each replicated object.
There are no additional charges to configure Intelligent-Tiering. You only pay for storage costs in each tier. Your tables continue to work as before, with automatic cost optimization based on your access patterns.
For S3 Tables replication, you pay the S3 Tables charges for storage in the destination table, for replication PUT requests, for table updates (commits), and for object monitoring on the replicated data. For cross-Region table replication, you also pay for inter-Region data transfer out from Amazon S3 to the destination Region based on the Region pair.
As usual, refer to the Amazon S3 pricing page for the details.
Both capabilities are available today in all AWS Regions where S3 Tables are supported.
To learn more about these new capabilities, visit the Amazon S3 Tables documentation or try them in the Amazon S3 console today. Share your feedback through AWS re:Post for Amazon S3 or through your AWS Support contacts.







 Atul Felix Payapilly is a software development engineer for Amazon EMR at Amazon Web Services.
Atul Felix Payapilly is a software development engineer for Amazon EMR at Amazon Web Services. Akshaya KP is a software development engineer for Amazon EMR at Amazon Web Services.
Akshaya KP is a software development engineer for Amazon EMR at Amazon Web Services.
 Giovanni Matteo is the Senior Manager for the Amazon EMR Spark and Iceberg group.
Giovanni Matteo is the Senior Manager for the Amazon EMR Spark and Iceberg group.