Post Syndicated from Satish Kamat original https://aws.amazon.com/blogs/compute/building-fault-tolerant-multi-agent-ai-workflows-with-aws-lambda-durable-functions/
Agentic AI workflows coordinate multiple agents that reason, plan, and act across multi-step processes. Each step is expensive, non-deterministic, and unpredictable in latency. Human review gates can pause execution for days. Transient failures are expected, and restarting a half-finished workflow wastes time and money. Duplicate actions, like charging a payment twice or sending the same request again, create financial and compliance risk. Until now, solving these problems meant building custom infrastructure such as state machines, queues, checkpoint stores before writing a single line of business logic.
Prior authorization is one of the most time-consuming steps in healthcare delivery. A provider must get approval from an insurer before certain treatments or medications are covered. The insurer evaluates whether the care is medically necessary, safe, and cost-effective.
Agentic AI is transforming this process. What previously took days — extracting clinical data, evaluating medical necessity, checking payer-specific criteria, and getting physician sign-off — can now be handled by AI agents that pull records, apply guidelines, and draft justification letters automatically.
This post shows how AWS Lambda durable functions can orchestrate an agentic healthcare prior authorization workflow. The pipeline coordinates multiple AI agents, a human review gate, and an external payer submission into a single fault-tolerant function. Using two key patterns — callbacks for human-in-the-loop approvals and asynchronous agent invocations, and polling for long-running external tasks — Lambda durable functions let you focus on the clinical workflow rather than building custom state machines, retry logic, and checkpoint infrastructure.
Overview of AWS Lambda durable functions
Lambda durable functions extend the standard Lambda programming model with a checkpoint and replay mechanism. You wrap your handler with the durable execution SDK, which enhances the Lambda context with durable operations such as context.step(), context.waitForCallback(), and context.waitForCondition(). These operations checkpoint progress, handle failures, and suspend execution during wait periods. If a failure occurs or the function resumes after being suspended, Lambda invokes your function again. It restores the previous state by replaying the event handler from the start and skipping over previously completed durable operations. Lambda durable functions offer additional patterns such as parallel execution, durable invocations, and saga-style compensations. Refer to the AWS Durable Execution SDK Developer Guide for the full set of capabilities.
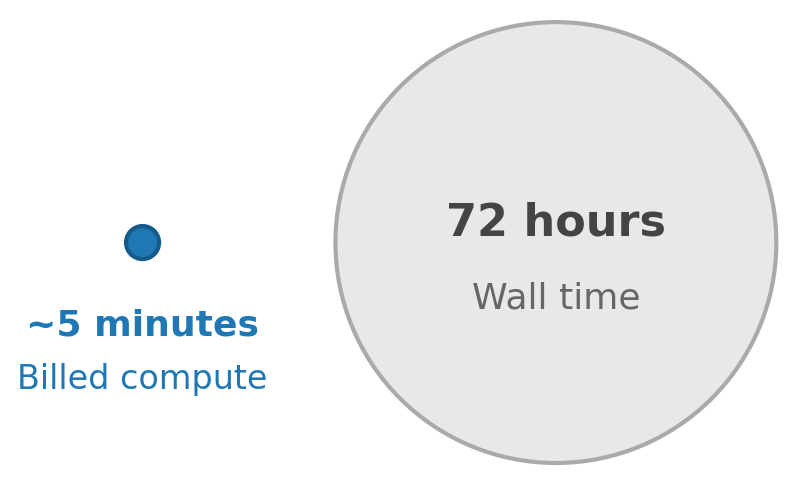
Agentic AI workflows are a natural fit for durable functions because each agent invocation is typically expensive, slow, and prone to transient failures, which are exactly the properties that benefit from automatic checkpointing and replay. Beyond orchestrating agent steps, durable functions can pause the workflow execution for external input. You can suspend the execution until a human approval arrives, or poll an external system for completion with configurable backoff. For on-demand functions, you don’t incur compute charges while execution is suspended (see Lambda pricing for details).
The healthcare prior authorization pipeline
The prior authorization workflow orchestrator coordinates four AI agents, a human review gate, and a payer submission.
- Clinical extraction agent (step). Extracts relevant clinical data (diagnosis codes, procedure history, lab results) from the patient’s medical records.
- Medical necessity agent (step). Evaluates whether the procedure meets clinical guidelines based on the extracted data.
- Payer criteria agent (step). Checks the specific payer’s authorization requirements and identifies any missing documentation.
- Justification generation agent (step). Produces the prior authorization justification letter using the outputs of the previous three agents.
- Physician review (callback). The orchestrator suspends and waits for a physician to review and approve the generated justification. Because this uses
waitForCallback(), the function incurs no compute charges while the physician takes minutes, hours, or days to respond. - Payer submission and adjudication (polling). Once approved, the orchestrator submits the authorization request to the payer system using an idempotent step with a
clientRequestToken(shown in the code below) to help prevent duplicate submissions. It then polls the payer’s adjudication status usingwaitForCondition()with exponential backoff, suspending between each check.
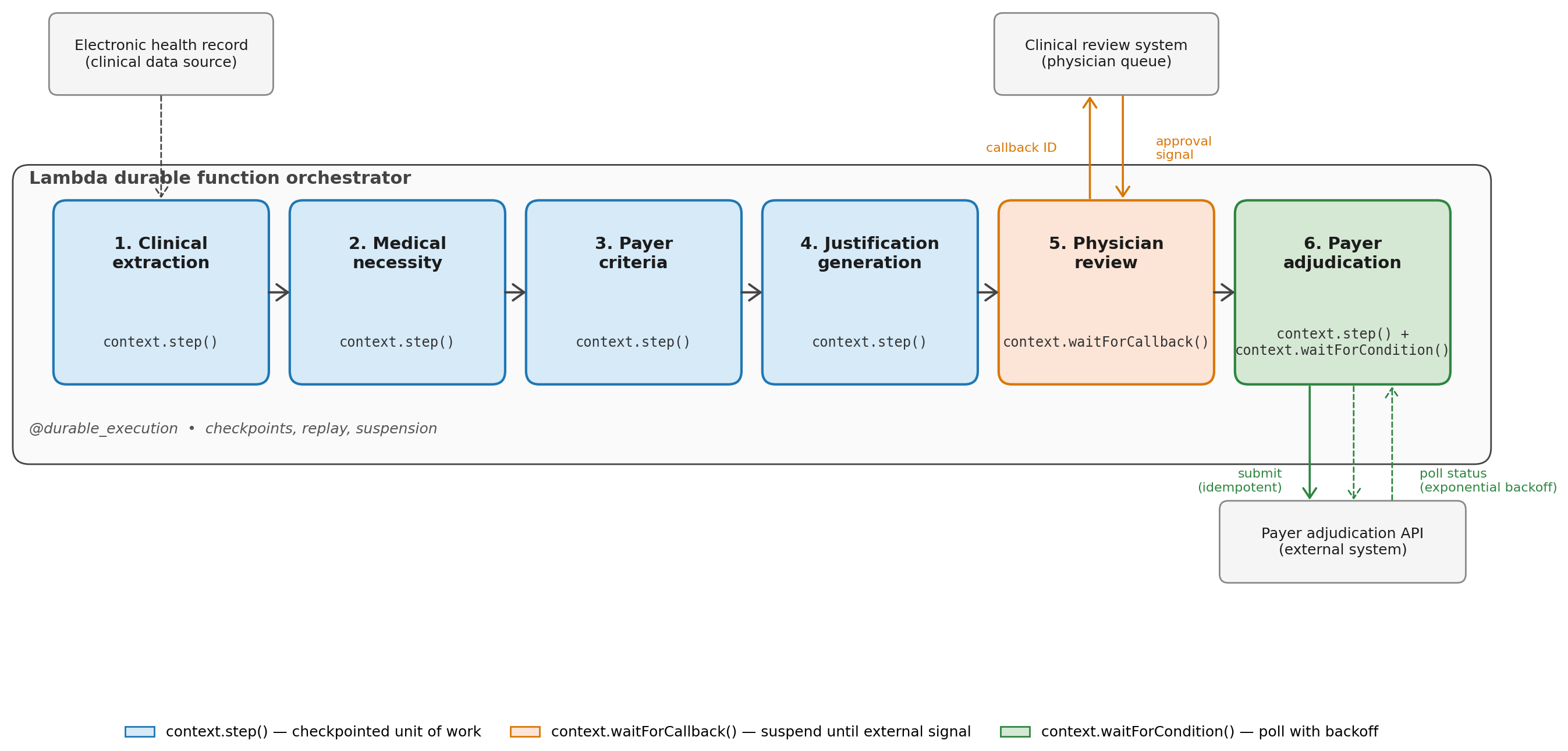
Figure 2. The six-stage prior authorization pipeline, orchestrated by a single Lambda durable function.
Putting it together in code
The entire pipeline, from agent steps to human review to payer submission and polling, lives in a single function that reads top to bottom:
How the orchestrator handles failures
The orchestrator is designed to handle the failure modes that come up in real workflows:
- An agent step fails. If the medical necessity agent fails after the clinical extraction agent has completed, Lambda durable function replays the handler, skips the extraction step which was already checkpointed, and retries only the failed step. This helps avoid re-incurring the time, cost, and token spend of completed steps.
- The physician rejects the justification. The callback returns
approved: false, the orchestrator returns aREJECTEDstatus, and no payer submission occurs. - Payer adjudication exceeds the max attempts.
waitForCondition()raises a timeout error after the configured attempt limit, which you can catch and route to a manual review queue or compensating action. - The submit step retries after a transient failure. Because the submission carries a
clientRequestTokenderived from the execution ID, retries against the payer are idempotent at the payer API level, which helps prevent duplicate authorization requests.
The callback pattern
The callback pattern allows the orchestrator to suspend execution and wait for an external signal before resuming. When the durable function reaches a context.waitForCallback(), it sends a unique callbackId to an external system and then suspends. When the external system completes its work, it calls the Lambda API with SendDurableExecutionCallbackSuccess (or SendDurableExecutionCallbackFailure) to resume the orchestrator from where it left off.
In the prior authorization pipeline, this is how the physician review step works. After the justification generation agent produces a letter, the orchestrator emits a callback ID to the clinical review system and suspends. The physician receives the draft in their review queue, reads it, and either approves or rejects it through the review UI. The UI calls the Lambda callback API with the result, and the orchestrator resumes with the approval decision.
Because the function is fully suspended, it incurs no compute charges during the review window, whether that’s 10 minutes or 3 days.
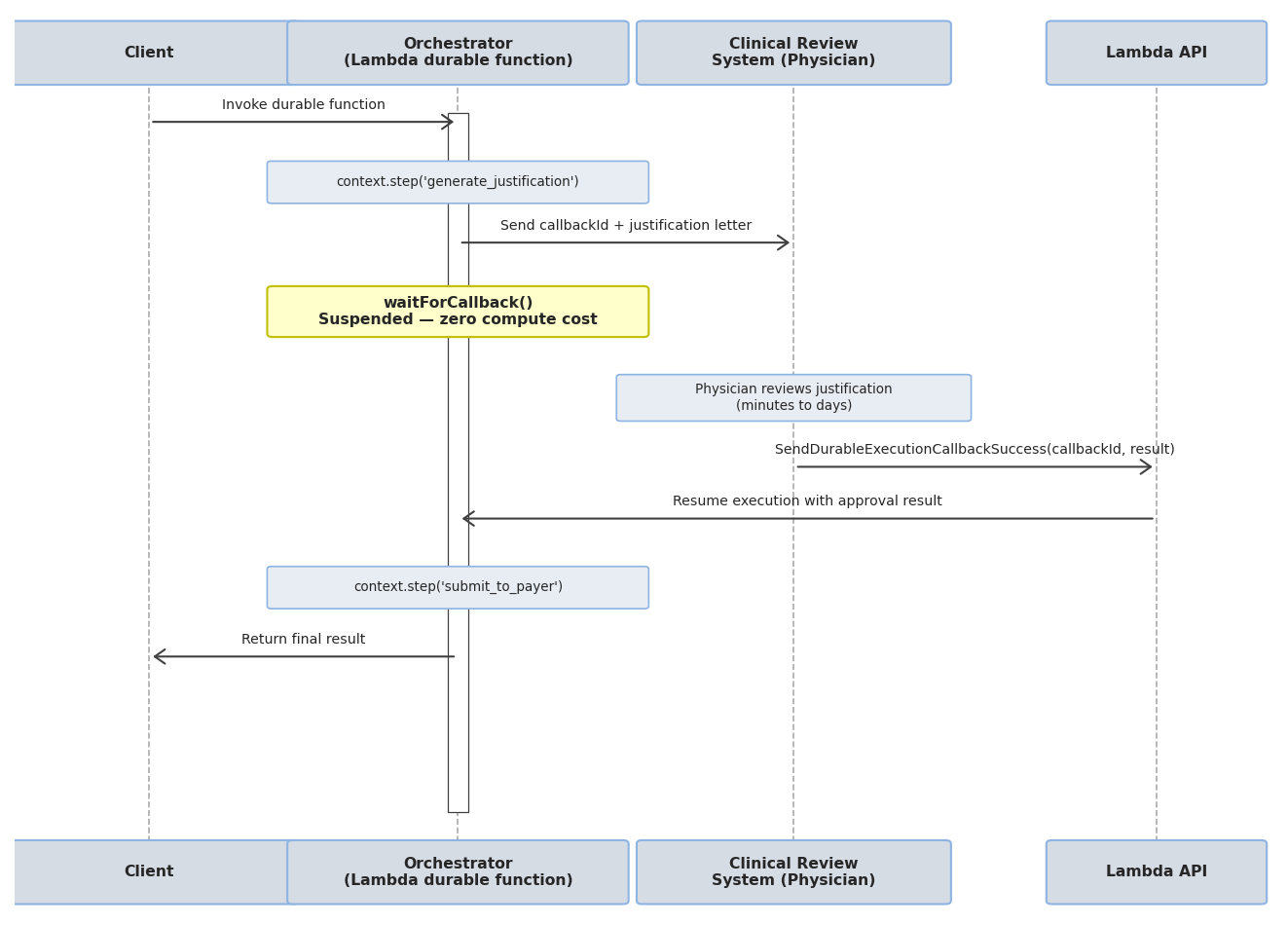
Figure 3. The callback flow for the physician review step. The orchestrator emits a callback ID to the clinical review system and suspends. When the physician approves or rejects, the review system calls SendDurableExecutionCallbackSuccess to resume the orchestrator with the decision.
The callback pattern is appropriate when:
- A human needs to review and approve a result (hours to days).
- An external agent is invoked asynchronously and the orchestrator should resume when it finishes.
- A webhook or third-party system signals completion.
The polling pattern
When an external system cannot send a callback, for example a payer API that offers no webhook support, the polling pattern provides an alternative. The orchestrator monitors the long-running task by periodically checking its status using context.waitForCondition().
It runs a check function periodically as configured by a wait strategy and evaluates the result. If the task isn’t complete, suspends for a configurable delay before checking again. The function incurs no compute charges during each wait interval. Each poll result is automatically checkpointed, so on replay the orchestrator skips previously completed checks.
In the prior authorization pipeline, this is how the payer adjudication step works. Most payer APIs accept a submission and return a tracking ID, but don’t push a completion signal back. The orchestrator calls waitForCondition() with the payer’s status API, an exponential backoff strategy (30 seconds to 5 minutes), and a maximum attempt count that covers the payer’s typical adjudication window.
Lambda durable functions provide waitForCondition() with built-in support for configurable backoff strategies, maximum attempt limits, and timeouts, which can help reduce the need for separate polling infrastructure such as scheduled rules, state machines, or custom retry logic.
Figure 4. The polling flow for the payer adjudication step
Polling is appropriate when:
- An async job does not support callbacks.
- An external API or system exposes only a status or Describe endpoint.
- The orchestrator waits for a resource to become available.
Cost and operational concerns
Here are a few implications when using orchestration of agentic workflows with Lambda durable functions:
- Retries don’t re-run completed agents. If the fourth agent fails, the first three are not re-invoked, so the organization does not pay token costs twice for the same work.
- Idempotency tokens help prevent duplicate payer submissions. A retry that crosses the submission step reuses the
clientRequestToken, which helps the payer deduplicate on their side. This is an important property when duplicate authorization requests can trigger compliance issues. - Replay-aware logger streamlines logging. The SDK’s logger (
context.logger) is replay-aware, meaning that it automatically suppresses duplicate log lines during replay. - Operational visibility is consolidated. Instead of stitching together logs from a state machine, a queue, a checkpoint table, and a poller, the entire workflow is one function with one execution history. Lambda publishes durable-execution-specific Amazon CloudWatch metrics, including
ApproximateRunningDurableExecutions,DurableExecutionDuration, andDurableExecutionFailed, so you can track running workflows, detect failures, and set alarms at the execution level. Lambda also publishes durable execution status change events to Amazon EventBridge (RUNNING,SUCCEEDED,FAILED,TIMED_OUT) for triggering notifications or downstream workflows, and you can enable AWS X-Ray for distributed tracing across the entire execution. For more details, see Monitoring durable functions in the Lambda developer guide.
Using coding agents to build and test durable functions
To accelerate building agentic workflow orchestration with Lambda durable functions, you can use the Kiro power for Lambda durable functions or the Agent Plugin for AWS Serverless, which is available in any AI coding assistant tool that supports agent plugins such as Claude Code and Cursor. You can also install agent skills from the plugin individually in any AI coding assistant tool that supports agent skills. This helps your coding agents such as Kiro to:
- Scaffold an orchestrator function from a prose description of the workflow, wiring up
context.step(),wait_for_callback(), andwait_for_condition()calls based on the described stages. - Generate unit tests that exercise the replay behavior, including tests that inject failures at specific steps to confirm that completed checkpoints are skipped on retry.
- Generate integration tests that simulate callback delivery and polling responses so you can validate end-to-end behavior without a full external system.
Conclusion
Agentic AI workflows can be non-deterministic, long-running, and failure-prone. Lambda durable functions can help address these challenges by adding checkpointing, replay, and suspension to the Lambda programming model, so completed work is skipped on retry and failures resume exactly where they occurred.
In this post, we walked through a healthcare prior authorization pipeline to illustrate two patterns: Callbacks for human-in-the-loop approvals and asynchronous agent invocations, and polling for monitoring long-running external tasks.
Beyond these two patterns, Lambda durable functions offer additional capabilities for building resilient workflows such as parallel execution, child contexts for isolated execution context for grouping operations, and saga-style compensations. Refer to the Lambda durable functions Developer Guide for the full set of capabilities. For pricing of on-demand and provisioned-concurrency functions, see the Lambda pricing page.
Get started with Lambda durable functions with examples from Serverlessland and install the Agent Plugin for AWS Serverless.