Post Syndicated from Ben Freiberg original https://aws.amazon.com/blogs/architecture/lessons-learned-from-scaling-to-1-million-lambda-functions/
In this post, we share our journey and the lessons learned from building and running a fully serverless, multi-account software as a service (SaaS) platform at scale. We’ll explore why true scale-to-zero is critical, how we handle quota management, why engaging AWS service teams early saved us from outages, and which unexpected practices emerged once we scaled from thousands to over a million functions.
At ProGlove, we build smart wearable barcode scanning solutions that connect frontline workers to digital workflows. Our scanners integrate with Insight, our AWS-based SaaS platform, to provide real-time visibility into processes, helping customers in manufacturing, logistics and retail improve productivity, reduce errors and enhance ergonomics on the shop floor.
We chose a one AWS account per tenant architecture to achieve clearer security boundaries, streamlined ownership of services, and more transparent cost. It is important to focus on efficiency with dedicated tenant resources at scale, because resource wastage will also scale. The ability to scale-to-zero removes this concern.
Phase 1: The “simple” origins (0 to 1,000 Lambda functions)
When you first build a serverless system, you think in single digits. A handful of AWS Lambda functions, maybe a few dozen at most. It’s hard to imagine what changes when your platform operates thousands of AWS accounts and deploys over one million Lambda functions into production, each isolated to a single customer’s account.
We followed standard playbooks, where “scale-to-zero” was merely a nice-to-have. We used serverless best practices like Amazon Simple Queue Service (Amazon SQS) for decoupling and long-polling to keep the application responsive and resilient. At this scale, a few idle functions or a handful of accounts were a negligible expense and the benefits of a high-level managed service like AWS Lambda really showed.
Microservice composition
Each microservice in our platform follows a consistent structure: 5 to 15 Lambda functions coordinated by AWS Step Functions, with Amazon EventBridge handling event routing and Amazon DynamoDB as the primary data store.
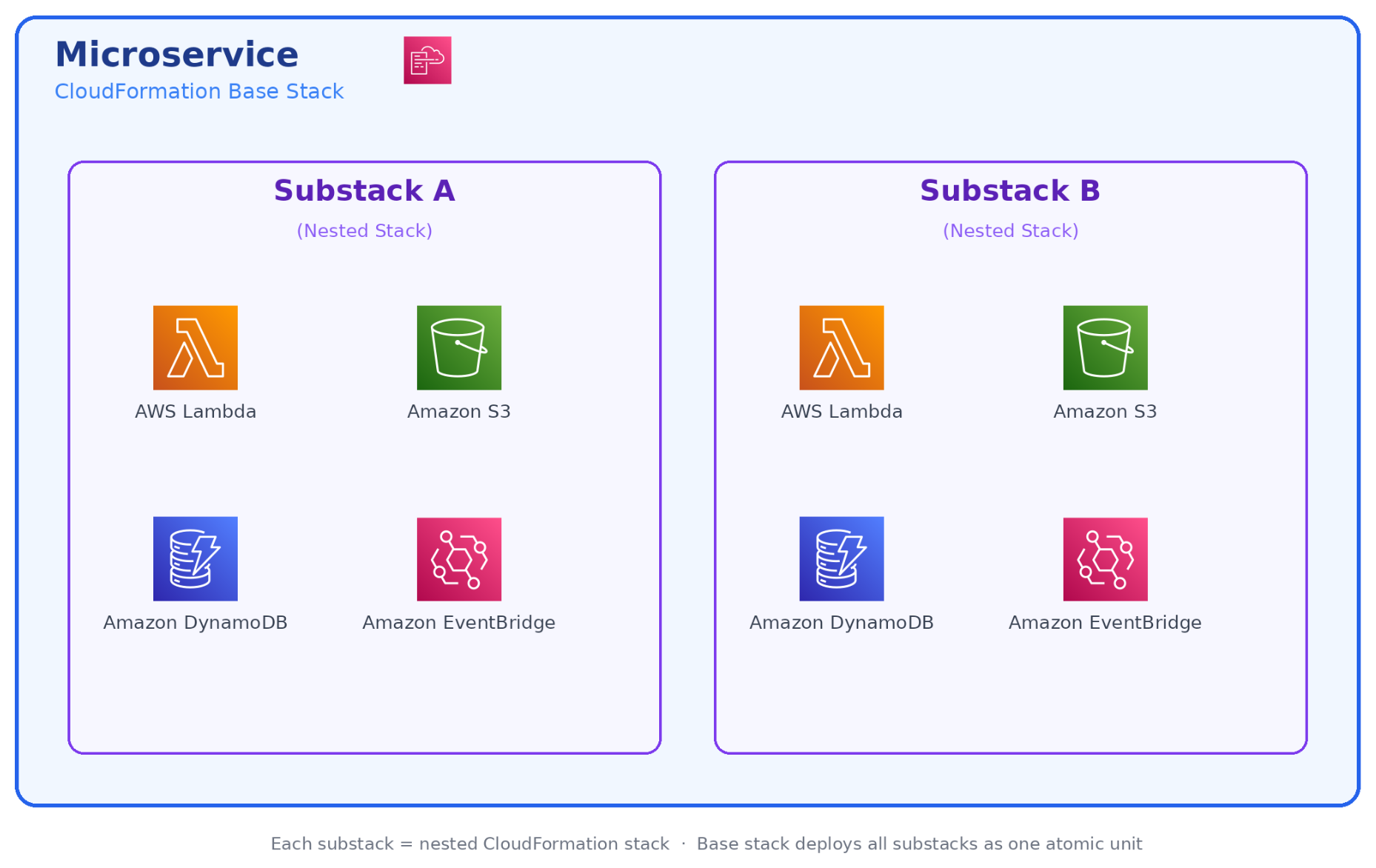
These resources are bundled together into a dedicated AWS CloudFormation stack for deployment.
As we onboarded our first handful of tenants, it quickly became clear that deploying and updating AWS CloudFormation stacks individually per account wouldn’t scale. We adopted AWS CloudFormation StackSets, which let us push infrastructure updates to multiple accounts in parallel from a central management account. At this stage, StackSets felt like a superpower. One deployment operation and many accounts are updated simultaneously. We evaluated building a fully custom replacement later, but ultimately concluded that the maintenance overhead wasn’t worth the marginal control gains and stayed with StackSets as our core mechanism.
Phase 2: The first 50 accounts
Growing to 50 tenant accounts forced us to confront problems that weren’t visible at single-digit scale. Three areas in particular required deliberate architectural decisions: observability, account provisioning, and quota isolation.
Automating account creation
We knew manual provisioning would not scale. Instead we built an automated account factory on top of AWS Organizations: an AWS Step Functions workflow in the management account handles the full provisioning lifecycle: Creating the account, applying baseline service control policies (SCPs), bootstrapping cross-account IAM roles, and triggering the initial CloudFormation StackSet deployment. All done using cross-account AWS Lambda invocations. New tenant accounts go from request to ready in under 15 minutes, at near-zero incremental cost per provisioning run.
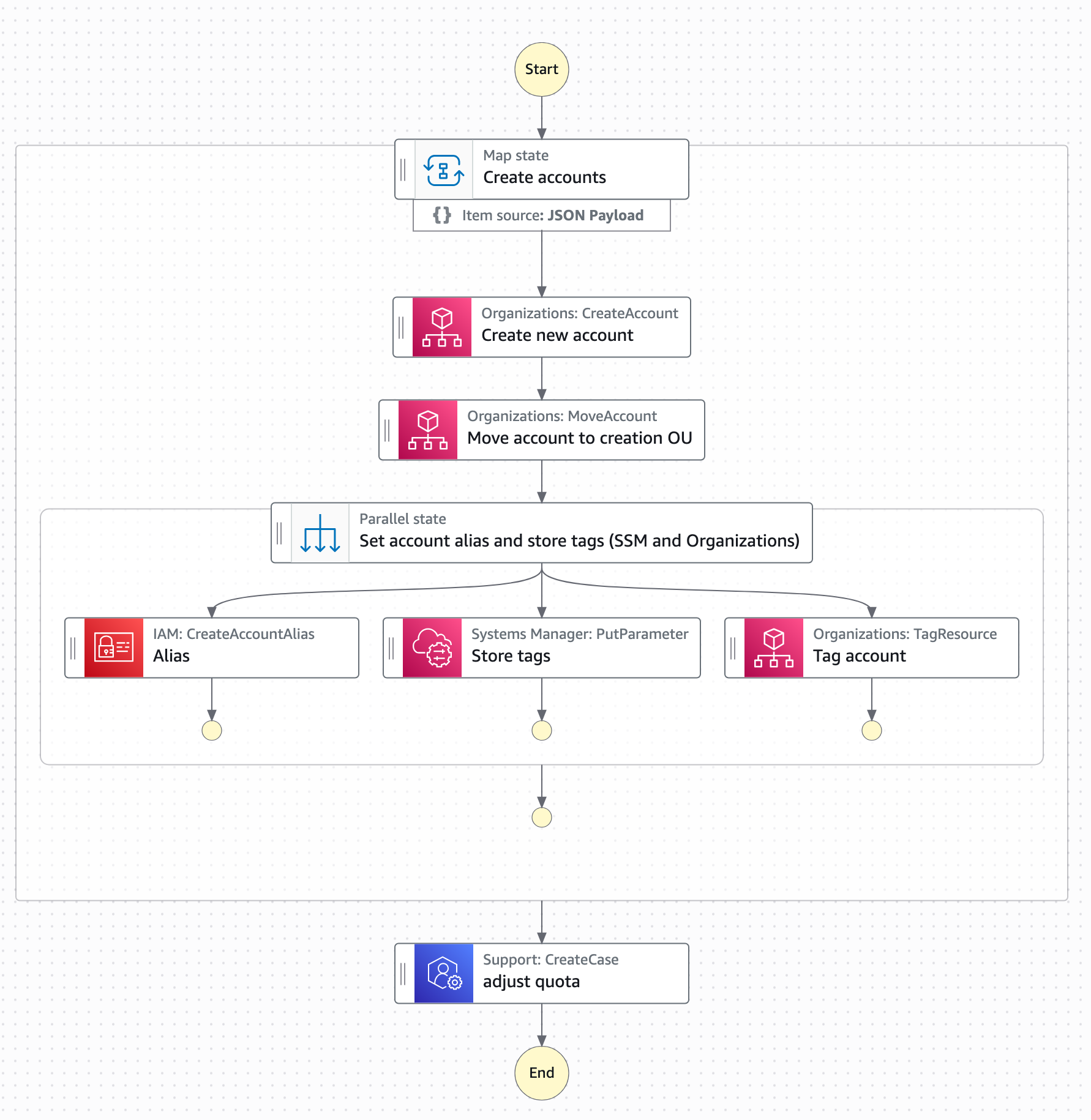
The quota isolation benefit
One underappreciated advantage of the account-per-tenant model is quota separation. Each account gets its own Lambda concurrent execution limit, its own Amazon API Gateway throttle, and its own service quotas across the board. In a shared-account SaaS model at this scale, a single noisy tenant could exhaust shared concurrency and cause cascading failures across all other tenants. With account isolation, that class of problem simply doesn’t exist as each tenant’s activity is bound to their own account.
Phase 3: Scaling challenges (the self-DDoS)
As our fleet grew beyond a few hundred accounts, we began to experience the “Physics of Scale”. We discovered that when hundreds of backend service instances simultaneously access other services, the resulting request volume can resemble a coordinated attack, impacting not only our own infrastructure but also AWS.
One time, we faced a massive metric spike where our own functions effectively overwhelmed (similar to a DDoS attack) our internal APIs. The root cause was synchronized schedules: every Lambda was using the same rate(5 minutes) expression, which aligned to the top of the minute across thousands of accounts.
The solution was request scattering. We now use a standardized internal library that enforces jitter, randomized batch offsets, and staggered updates across all scheduled functions.
Rule of Thumb: “Never do the same thing at the same time everywhere”.
Multi-account observability as a cost driver
With several dozen accounts, manual log access per account became unworkable. We adopted a third-party observability platform, forwarding Amazon CloudWatch logs and metrics cross-account to a centralized dashboard. At roughly $3 per account per month, the cost felt insignificant.
That assumption was soon replaced by a very real learning: at thousands of accounts, $3 per account per month becomes an impactful expense that demands active management. We learned to treat per-account observability costs with the same scrutiny you apply to compute costs.
What came as a surprise to us were the actual cost drivers: instead of Lambda compute or storage costs, we found that forwarding all observability data almost doubled our cloud bill. As a result, we had to learn how to differentiate between high and low priority observability data and only move around the priority data.
With all mitigations combined we managed to bring observability costs down to around $0.7 per account. Additionally, we were able to switch accounts to almost 0 after some time of inactivity by only monitoring a small set of very basic metrics.
Phase 4: Rethinking architectural patterns for scale-to-zero
One of the most painful lessons was realizing that traditional Amazon SQS “best practices” increased costs in our use-case and scale.
Replacing SQS and the DLQ dilemma
After we scaled to over a thousand AWS accounts, we understood that “idle” doesn’t necessarily mean there are no costs – even when using Serverless. When Lambda functions consume events from EventBridge through an SQS queue to increase resilience, they constantly make requests to the queue even when there are no messages to process.
To eliminate the cost of continuous polling, we removed Amazon SQS from the path between Amazon EventBridge and AWS Lambda.
- Metric-Driven Safety: Instead of relying on a queue to buffer requests, we monitor
AsyncEventsDroppedandConcurrentExecutionsto make sure we stay within our quotas without losing events. - The Centralized DLQ: Polling individual Dead Letter Queues (DLQs) in every account reintroduced the same polling cost issues. We solved this by routing failures to a centralized DLQ as shown in the following two diagrams.
- The Isolation Trade-off: This approach requires extreme discipline to make sure we don’t break our data isolation patterns, as events from different tenants converge in a single location for recovery. Because of cost implications at scale, the use of SQS moved from a silo to a bridged model where the AWS account ID can be treated as a tenant ID.
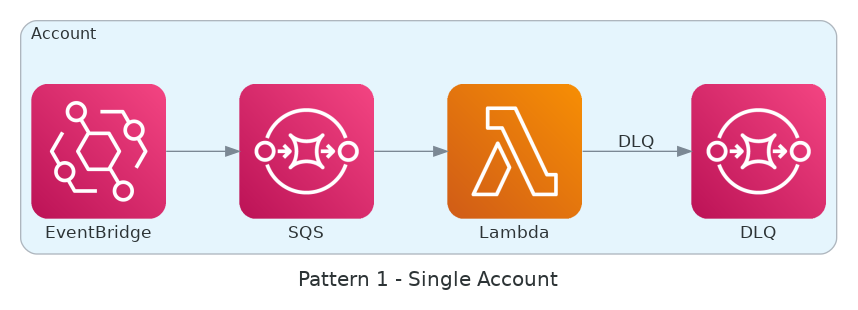
Individual DLQ per queue
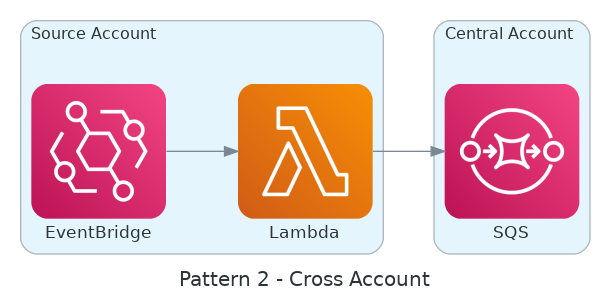
Centralized DLQ polling
Phase 5: Industrializing the deployment engine
Serverless architectures grow to large numbers of infrastructure components: where a monolith or Amazon Elastic Compute Cloud (Amazon EC2)-based service might be a handful of resources, a single microservice in our stack spans dozens of Lambda functions, EventBridge rules, DynamoDB tables, and Step Functions state machines. Multiplied across thousands of accounts, deployment complexity compounds quickly.
Initially, we used AWS CloudFormation StackSets to roll out updates in parallel. However, at the scale of 1 million Lambda functions, StackSets hit a performance ceiling and occasionally produced errors that added up significantly at our volume.
From custom engines to collaborative roadmaps
The bottlenecks became such a blocker that we began building our own internal serverless deployment system to replace StackSets. This caught the attention of the AWS CloudFormation service team, who committed to supporting our use case at the scale we required and partnered with us closely from that point on.
By engaging early and often, we were able to:
- Influence the Roadmap: We provided the scale requirements that helped AWS prioritize StackSet stability and performance improvements.
- Automate Resiliency: We built a deployment tracking service that aggregates StackSet events through Amazon EventBridge. A central AWS Step Functions state machine now acts as our “single-pane-of-glass,” acting on failures and triggering retries for occasional AWS internal errors.
Phase 6: Mature governance and FinOps
Being able to scale a serverless platform with a small team of engineers requires consistent and efficient governance practices. This applies to both cloud governance topics as well as engineering practices. Otherwise it will be next to impossible to keep software delivery and development performance as well as reliability at a high level over time.
Cost optimization also changes at a higher maturity level: once cost control is tightly monitored and automated, the discipline changes from housekeeping tasks to collect easy cost savings towards increasingly complex architectural changes. For example, if a new feature significantly increases the number of Lambda invocations and drives up cost, you will need to re-think the architecture and include the new focus on cost.
The mono-repo strategy
We consolidated 20 microservices into a single mono-repo. This helped us to:
- Enforce consistent tooling and security scanning across more than a million functions.
- Coordinate runtime and library upgrades through a single source of truth for configuration.
- Make sure every change passes through the same CI/CD chain with guaranteed compatibility.
The “Almost-Zero” Reality
Even with a scale-to-zero mandate, we learned that “zero” is often “almost-zero”.
- The Monitoring Tax: We avoided services like NAT Gateways, but monitoring introduced additional costs such as CloudWatch Alarms. Aggregating metrics in external observability tools added up quickly.
- The Optimization Payoff: By aggressively optimizing these costs, we reduced our idle cost for inactive accounts to less than $1 per month.
Think beyond the obvious services
One of the most valuable habits we built was resisting the urge to immediately default to a familiar pattern or write custom code. AWS offers a growing catalog of fully managed, event-driven services such as Amazon EventBridge Pipes, AWS AppSync, Amazon SQS FIFO, and others, that can remove entire categories of custom Lambda code. Before writing a function, ask whether a native service integration already solves the problem.
A deliberate research step of exploring native AWS capabilities before opening an editor consistently paid off. It reduces the surface area you own, eliminates maintenance burden, and builds the team’s instinct for choosing the right service over reinventing it. Serverlessland is an excellent starting point for discovering patterns and service combinations you may not have considered.
Conclusion: Scaling efficiency faster than growth
Scaling from 0 to 1M Lambda functions across thousands of AWS accounts is a question of efficiency not of capacity. Every new account, every new customer, adds potential operational load. The only way to stay ahead is to make sure efficiency scales faster than growth. For us, that means true scale-to-zero, proactive and efficient quota management, tight collaboration with AWS service teams, disciplined developer education, and a mono-repo that enforces consistency.
We’ve learned that the difference between success and failure at this scale lies in unexpected aspects like the hard-learned fact that observability becomes an increasingly complex problem the more distributed your platform becomes.
The benefits are substantial. With the right automation and architectural rigor, a lean team can operate a large-scale infrastructure. Using a cloud-native approach based on serverless services is the most important operational advantage in this case.
To apply these lessons to your own workloads, discover event-driven patterns and service combinations on Serverless Land.