Post Syndicated from Laurie Denness original https://laur.ie/blog/2014/02/why-ill-be-letting-nagios-live-on-a-bit-longer-thank-you-very-much/
My my, hasn’t @supersheep stirred up a bit of controversy over Nagios over the last week?
In case you missed it, he brought up an excellent topic that’s close my heart: Nagios. In his words, we should stop using it, so we can let it die. (I read about this in DevOpsWeekly, which you should absolutely sign up to if you haven’t already, it’s fantastic)
Mr Sheep (Andy) brought up some excellent points, and when I read them I must admit getting fairly triggered and angry that someone would speak about one of my favourite things in such a horrible way! Then maybe I started thinking I had a problem. Was I blindly in love with this thing? Naive to the alternatives, a fan boy? Do I need help? Luckily I could reach out to my wonderful coworkers, and @benjammingh was quick to confirm that yes, I do need help, but then again don’t we all. That’s a separate issue.
Anyway, the folks at reddit had plenty to say about this too. Some of the answers are sane, some are… Not so. Other people were seemingly very angry too. I don’t blame them.. It’s a bold move to stand up and say a perfectly good piece of software “sucks” and “you shouldn’t use it”. Which was the intention, of course, to make us talk about it.
Now the dust has settled slightly, I’m going to tell you why I still love Nagios, and why it will be continued to be used at Etsy, addressing the points Andy brought up individually.
“Doesn’t scale at all”
Yeah, that Gearman thing freaks me out too. I don’t think I’d want to use it, even though we use Gearman extremely heavily at Etsy for the site (we even invited the creator in for our Code as Craft speaker series).
But what scale are people taking here? Is it really that hard?
We “only” have 10,000 checks in our primary datacenter, all active, usually on 2-3 minute check intervals with a bunch on 30 seconds. I’m honestly not sure if that’s impressive or embarrassing, but the machine is 80% idle, so it’s not like there isn’t overhead for more. And this isn’t a super-duper spec box by any means. In fact, it’s actually one of the oldest servers we have.
use_large_installation_tweaks
We had to enable use_large_installation_tweaks to get the latency down, but that made absolutely no difference to our Nagios operation. Our check latency is currently 2.324 seconds.
I’m not sure how familiar people are with this flag… Our latency crept up to minutes without it, and it’s not massively well documented online that you can probably enable it with almost no effect to anything except… Making Nagios not suck quite so much.
It’s literally a “go faster” flag.
Disable CPU scaling
Our Nagios boxes are HP or Dell servers, that by default have a “dynamic” CPU scaling setting enabled. Great for power saving, but for some reason the intelligence built into this system is absolutely horrible with Nagios. Because Nagios has extremely high context switches, but relatively low CPU, it causes a lot of problems with the intelligent management. If you’re still having latency issues, set the server to “static high performance mode” or equivalent.
We’ve tested this in a bunch of other places, and the only other place it helped was syslog-ng. Normally it’s pretty smart, but there *are* a few cases that trip it up.
Horizontal Scaling
The reason we’ve ended up with 10,000 checks on that single box is because that datacenter is now full, and we’ve moved onto another one, so we’ve started scaling Nagios horizontally rather than vertically. It makes a lot more sense to have a Nagios instance in each network/datacenter location so you can get a “clean view” of what’s going on inside that datacenter rather than letting a network link show half the hosts as dead. If you lose cross-DC connectivity, how will you ever know what really happened in that DC when it comes back?
This does present some small annoyances, for example we needed to come up with a solution for aggregating status together into one place. We use Nagdash for that. It uses the nagios-api, which I’ll come onto more later. We also use nagios-api to allow us to downtime hosts quickly and easily via irccat in IRC, regardless of the datacenter.
![]()
We’ve done the same with Ganglia and FITB too, for the same reasons. Much easier to scale things by adding more boxes, once you get over the hurdles of managing multiple instances. As long as you’re using configuration management.
“Second most horrible configuration”
After sendmail. Fair enough… m4 anyone? Some people like it though, it’s called preference.
Anyway, those are some strong feelings. Ever used XML based configuration? ini files? Yaml? Hadoop? In *my opinion* they’re worse. Maybe you’re a fan.
Regardless, if you spend your day picking through Nagios config files, then you probably either love it anyway, you’re doing a huge rewrite of your old config, or you’re probably doing it wrong. You can easily automate this.
We came up with a pretty simple solution for the split NRPE/Nagios configs thing at Etsy: Stop worrying about the NRPE configs and put every check on every host. The entire directory is 3MB, and does it matter if you have a check on a system you never use? No. Now you only have one config to worry about.
Andy acknowledges Chef/Puppet automation later where he calls using them to manage your Nagios configuration a “band aid”. Is managing your Apache config a “band aid”? How about your resolv.conf? Depending on your philosophy, you could basically call configuration management in general a giant bandaid. Is that a bad thing? No! That’s what makes it awesome. Our jobs is tying together components to construct a functioning system, at many many levels. At the highest level, at Etsy we’re here to make a shopping website. There are a bunch more systems tied together to make that possible lower down.
This is actually the Unix philosophy. Many small parts, applications that do a small specific thing, which you tie together using “|”. A pipe. You pipe data in to one application, and you manipulate it how you want on the way out. Which brings me onto:
“No programmatic interfaces”
At this point I am threatened with “If I catch you parsing status.dat I will beat your ass”. Bring it on!
We’re using the wonderful nagios-api project extremely heavily at Etsy because it provides a fantastic REST API for anything you’ve ever wanted in Nagios. And it does so by parsing status.dat. So sue me. Call me crazy, but isn’t parsing one machine readable output into another machine readable output basically computers? Where exactly is the issue in that?
Not only that, but it works really really well. We’ve contributed bits back to extend the functionality, and now our entire day to day workflow depends on it.
Would it be cool if it was built in? Maybe. Does it matter that it’s not? No. Again, pipes people. We’re using Chef as “echo” into Nagios, and then piping Nagios output into nagios-api for the output.
“Horrendous interface”
Well, it’s more “old” than anything else. At least everything is in the same place as you left it because it’s been the same since 1912. I wouldn’t argue if it was modernised slightly.
“Stupid wire format for clients”
I don’t think I’ve ever looked. Why are you looking? When was the last time NRPE broke? Maybe you have a good reason. I don’t.
“Throws away perfdata”
Again with the pipes! As Nagios logs this, we throw it into Splunk and Logstash. I admit we don’t bother doing much with it from there, as I like my graphs powered by something that was designed to graph, but a couple of times I’ve parsed the perfdata output in one of those two to get data I need.
All singing all dancing!
In the end though, I think the theme we’re coming onto here is that Andy really wants a big monolithic thing to handle everything for him, whereas actually I’m a massive fan of using the right tool for the job. You can buy a clock radio that is also a iPod dock, mp3 player, torch, battery charger, cheese grater, but it does all those things terribly.
For example, I don’t often need the perfdata because we have Ganglia for system level metrics, Graphite for our app level metrics, and we alert on data from both of those using Nagios.
In the end, Nagios is an extremely stable, extremely customisable piece of software, which does the job of scheduling and running shell scripts and then taking that and running other shell scripts to tell someone about it incredibly well. No it doesn’t do everything. Is that a bad thing?
Murphy said this excellently:
“Sensu has so many moving parts that I wouldn’t be able to sleep at night unless I set up a Nagios instance to make sure they were all running.”
(As a side note, yes all of our Nagios instances monitor each other, no they’ve never crashed)
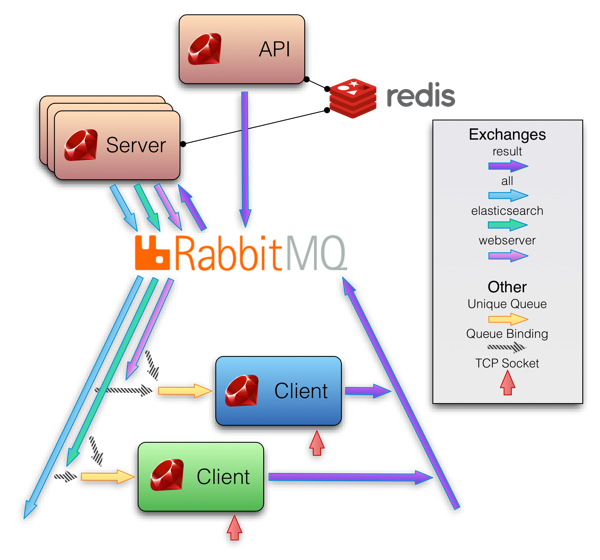
I will be honest; I haven’t used Sensu, because I’m in a happy place right now, but just the architectural diagram of how it works scares the shit out of me. When you need 7 arrow colours to describe where data is going in a monitoring system, I’m starting to fear it slightly. But hey, if it works, good on you guys. It just looks a lot like this. Nothing wrong with that, if you can make it stable and reliable.
{kind=link}
{kind=link}
Your mileage may vary
The nice thing about this world is people have choices. You may read everything I just wrote and still think Nagios is rubbish. No problem!
Certainly for us, things are working out pretty great, so Nagios will be with us for some time (drama involving monitoring plugins aside…). When we’ve hit a limit, that’ll be the next thing out the window or re-worked. But for now, long live Nagios. And it’s far from being on life support.
And, the best thing is, that doesn’t even stop Andy making something awesome. Hell, if it’s really good, maybe we’ll use it and contribute to it. But declaring Nagios as dead isn’t going to help that effort, actually. It will just alienate people. But I’m sure there are many of you who are sick of it, so please, don’t let us stop you.
Follow me on Twitter: @lozzd