Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/reinvent-session-preview-under-the-hood-at-amazon-ads/
My colleagues have spent months creating, reviewing, and improving the content for their upcoming AWS re:Invent sessions. While I do my best not to play favorites, I would like to tell you about one that recently caught my eye!
Session ADM301 (Under the Hood at Amazon Ads) takes place on Tuesday, November 30th at 2 PM. In the session, my colleagues will introduce Amazon Ads, outline the challenges that come with building an advertising system at scale, and then show how they solved those challenges using multiple AWS services. I was able to review a near-final version of their presentation and this post is based on what I learned from that review.
Amazon Ads uses an omnichannel strategy with four elements: building awareness, increasing consideration, engaging shoppers, and driving purchases. Using the well-known “start from the customer and work backwards” model that we use at Amazon, they identified three distinct customer types and worked to design a system that would address their needs. The customer types were:
- Advertisers running campaigns
- Third-party partners who use Amazon Ads APIs to build tools & services
- Shoppers on a purchase journey
Advertisers and third-party developers wanted an experience that spanned both UIs and programmatic interfaces, encompassing campaign management, budgeting, ad serving, a data lake for ad events, and machine learning to improve ad selection & relevance.
 Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
Scaling is a really interesting problem, with challenges around performance, storage, availability, cost, and effectiveness. In addition to handling hundreds of millions of ad requests per second (trillions of ads per day) within a latency budget of 120 ms, the ad server must be able to:
- Track tens of billions of campaign objects, with overall storage measured in hundreds of petabytes
- Deliver > 99.9999% availability
- Handle peak events such as Prime Day automatically
- Run economically and enforce advertiser budgets in near real-time
- Deliver highly relevant ads using predictions from hundreds of machine learning models
As just one example of what it takes to handle a workload of this magnitude, they needed a caching system capable of handling 500 million requests per second!
As is often the case, the system went through multiple iterations before it reached its current form, and is still under active development. The presentation recaps the journey that the team went through, with architectural snapshots and performance metrics for each iteration.
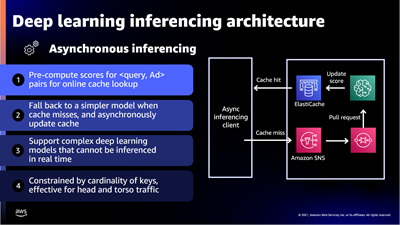 The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
The presentation wraps up by discussing some of the ways that they were able to apply machine learning at scale. For example, to select the right ad for each request, Amazon Ads uses deep learning models to predict relevant ads to show shoppers, predict whether a shopper will click or purchase, and allocate and price an ad. In order to do this, they needed to be able to score thousands of ads per request within a 20 ms window at over 100K transactions per second, all across hundreds of models that each required different hardware and software optimizations.
To handle this workload they built a micro-service inferencing architecture on top of Amazon Elastic Container Service (Amazon ECS) and AWS App Mesh with specific hardware and software optimizations for each type of inference model. For low-latency inferencing the Ads team began with a CPU-based solution and then moved to GPUs to reduce prediction time even as complexity and the number of models grew.
This looks like a very interesting session and I hope that you will be able to attend in person or to watch it online as part of virtual re:Invent.
— Jeff;