Post Syndicated from Rahul Chaturvedi original https://aws.amazon.com/blogs/big-data/share-data-securely-across-regions-using-amazon-redshift-data-sharing/
Today’s global, data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This requires you to seamlessly share and consume live, consistent data as a single source of truth without copying the data, regardless of where LOB users are located.
Amazon Redshift is a fast, scalable, secure, and fully managed data warehouse that enables you to analyze all your data using standard SQL easily and cost-effectively. Amazon Redshift data sharing allows you to securely share live, transactionally consistent data in one Amazon Redshift cluster with another Amazon Redshift cluster across accounts and Regions, without needing to copy or move data from one cluster to the other.
Amazon Redshift data sharing was initially launched in March 2021, and support for cross-account data sharing was added in August 2021. Cross-Region support became generally available in February 2022. This provides full flexibility and agility to easily share data across Amazon Redshift clusters in the same AWS account, different accounts, or different Regions.
In this post, we discuss how to configure cross-Region data sharing between different accounts or in the same account.
Solution overview
It’s easy to set up cross-account and cross-Region data sharing from producer to consumer clusters, as shown in the following flow diagram. The workflow consists of the following components:
- Producer cluster administrator – The producer admin is responsible for the following:
- Create an Amazon Redshift database share (a new named object to serve as a unit of sharing, referred to as a datashare) on the AWS Management Console
- Add database objects (schemas, tables, views) to the datashare
- Specify a list of consumers that the objects should be shared with
- Consumer cluster administrator – The consumer admin is responsible for the following:
- Examine the datashares that are made available and review the content of each share
- Create an Amazon Redshift database from the datashare object
- Assign permissions on this database to appropriate users and group in the consumer cluster
- Users and groups in the consumer cluster – Users and groups can perform the following actions:
- List the shared objects as part of standard metadata queries
- Start querying immediately

In the following sections, we discuss use cases and how to implement the cross-Region sharing feature between different accounts or in the same account.
Use cases
Common use cases for the data sharing feature include implementing multi-tenant patterns, data sharing for workload isolation, and security considerations related to data sharing.
In this post, we demonstrate cross-Region data sharing, which is especially useful for the following use cases:
- Support for different kinds of business-critical workloads – You can use a central extract, transform, and load (ETL) cluster that shares data with multiple business intelligence (BI) or analytic clusters owned by geographically distributed business groups
- Enabling cross-group collaboration – The solution enables seamless collaboration across teams and business groups for broader analytics, data science, and cross-product impact analysis
- Delivering data as a service – You can share data as a service across your organization
- Sharing data between environments – You can share data among development, test, and production environments at different levels of granularity
- Licensing access to data in Amazon Redshift – You can publish Amazon Redshift datasets in the AWS Data Exchange that customers can find, subscribe to, and query in minutes.
Cross-Region data sharing between different accounts
In this use case, we share data from a cluster in an account in us-east-1 with a cluster owned by a different account in us-west-2. The following diagram illustrates this architecture.

When setting up cross-Region data sharing across different AWS accounts, there’s an additional step to authorize a datashare on the producer account and associate the datashare on the consumer account. The reason is that for such shares that go outside of your account or organization, you must have a two-step authentication process. For example, consider a scenario where the database analyst creates a database share using the console and now requires the producer administrator to authorize this datashare. For same-account sharing, we don’t require that two-step approach because you’re granting access within the perimeter of your own account.
This setup broadly follows a four-step process:
- Create a datashare on the producer account.
- Authorize the datashare on the producer account.
- Associate the datashare on the consumer account.
- Query the datashare.
Create a datashare
To create your datashare, complete the following steps:
- On the Amazon Redshift console, create a producer cluster with encryption enabled.
This is in your source account. For instructions on how to automate process of creating an Amazon Redshift cluster, refer to Automate building an integrated analytics solution with AWS Analytics Automation Toolkit.
On the Datashares tab, no datashares are currently available on the producer account.

- Create a consumer cluster with encryption enabled in a different AWS account and different Region.
This is your target account. On the Datashares tab, no datashares are currently available on the consumer side.

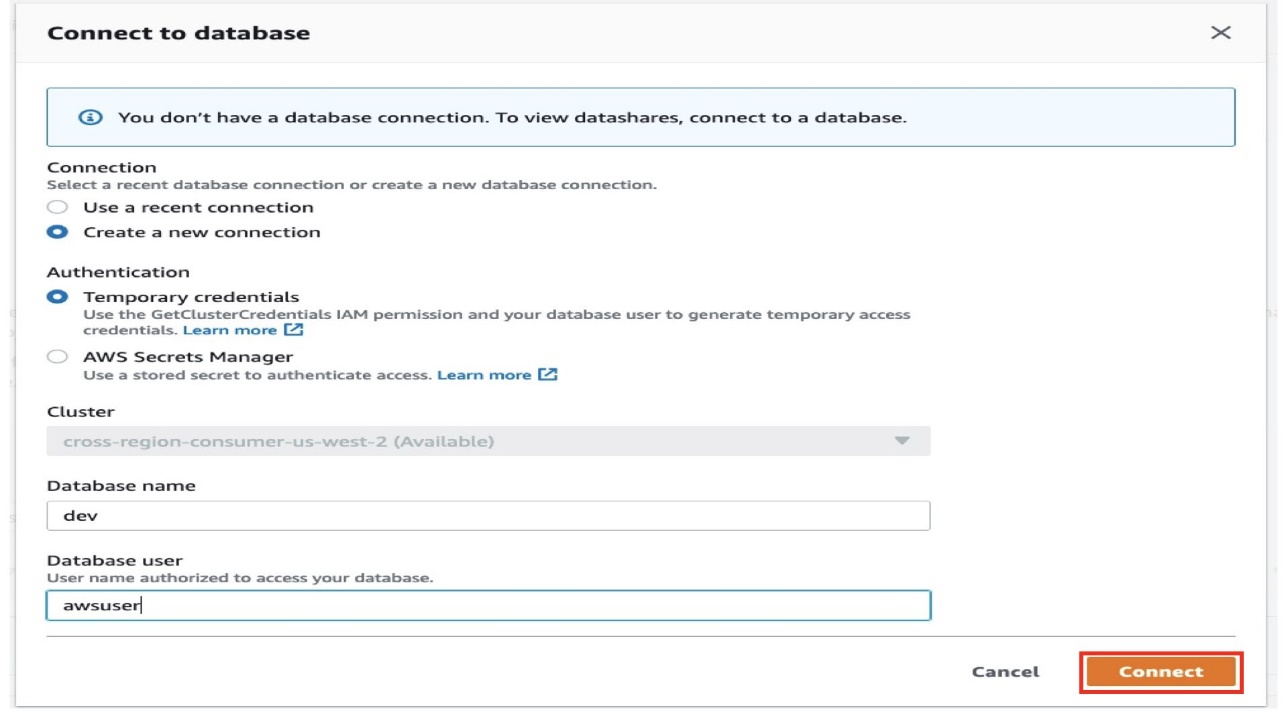
- Choose Connect to database to start setting up your datashare.

- For Connection, select Create a new connection.

You can connect to the database using either temporary credentials or AWS Secrets Manager. Refer to Querying a database using the query editor to learn more about these two connection options. We use temporary credentials in this post.
- For Authentication, select Temporary credentials.
- For Database name, enter a name (for this post,
dev). - For Database user, enter the user authorized to access the database (for this post,
awsuser). - Choose Connect.
- Repeat these steps on the producer cluster.
- Next, create a datashare on the producer.
- For Datashare type, select Datashare.
- For Database name, enter a name.
- For Database name, choose the database you specified earlier.
- For Publicly accessible, select Enable.
- In the Datashare objects section, choose Add to add the database schemas and tables to share.\


In our case, we add all tables and views from the public schema to the datashare.
- Choose Add.


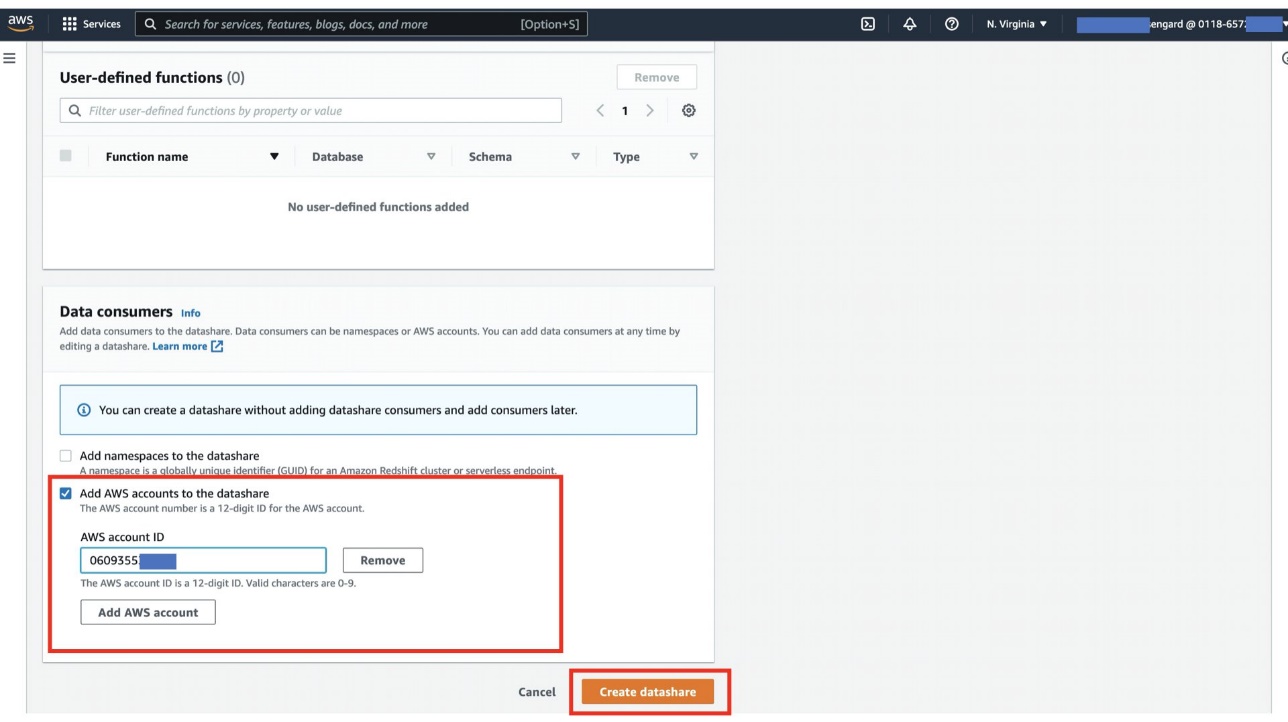
Next, you add the consumer account in order to add a cross-account, cross-Region consumer to this datashare.
- In the Data consumers section, select Add AWS accounts to the datashare and enter your AWS account ID.
- Choose Create datashare.
Authorize the datashare
To authorize this datashare, complete the following steps:
- On the Amazon Redshift console, choose Datashares in the navigation pane.
- Choose the datashare you created earlier.
- In the Data consumers section, select the data consumer ID and choose Authorize.
- Choose Authorize to confirm.



Associate the datashare
On the consumer account in a different Region, we have multiple clusters. In this step, the consumer administrator associates this datashare to only to one of those clusters. As a consumer, you have the option to accept or decline a datashare. We associate this datashare to cross-region-us-west-2-team-a.
- On the Datashares page, choose the From other accounts tab to find the database you created in the source account.
- Select the appropriate datashare and choose Associate.

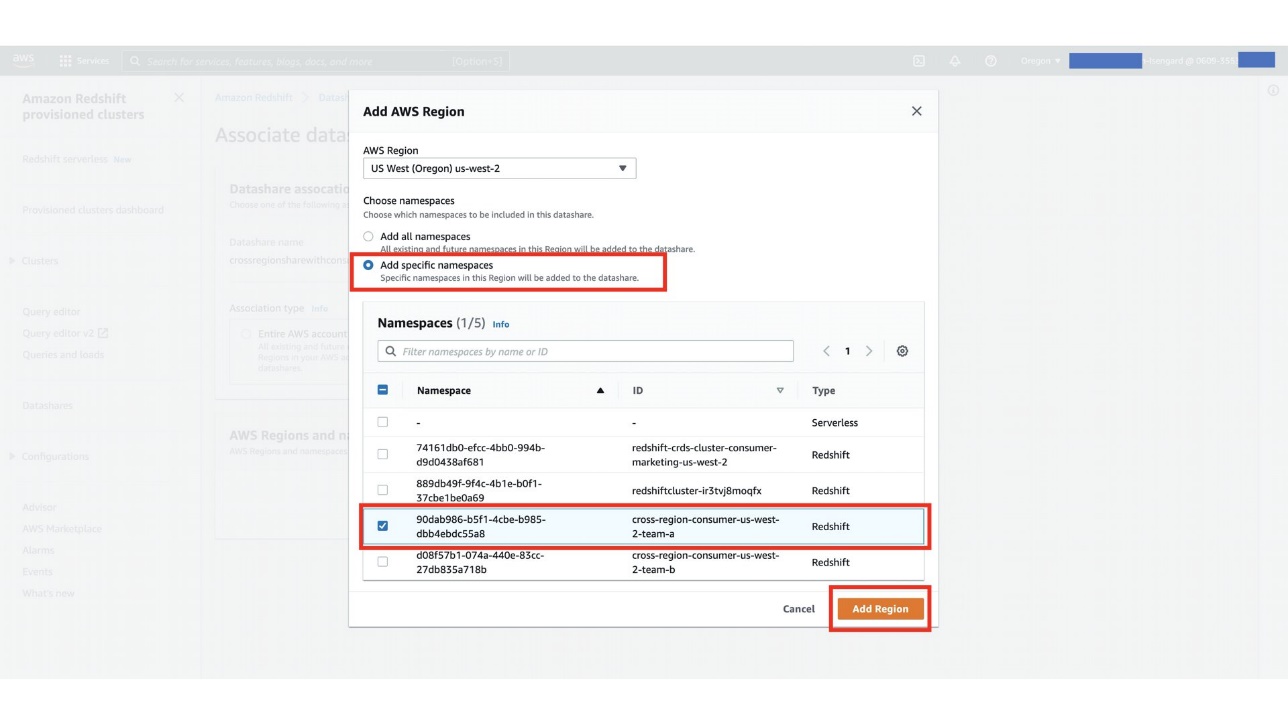
In the next step, you as a consumer admin have the option to associate the datashare with specific clusters in a different Region. Each cluster has its own globally unique identifier, known as a namespace. For this post, we associate the datashare to cluster cross-region-us-west-2-team-a with the namespace 90dab986-b5f1-4cbe-b985-dbb4ebdc55a8 in the us-west-2 Region.
- For Choose namespaces, select Add specific namespaces.
- Select your namespace and choose Add Region.
- Choose Clusters in the navigation pane.
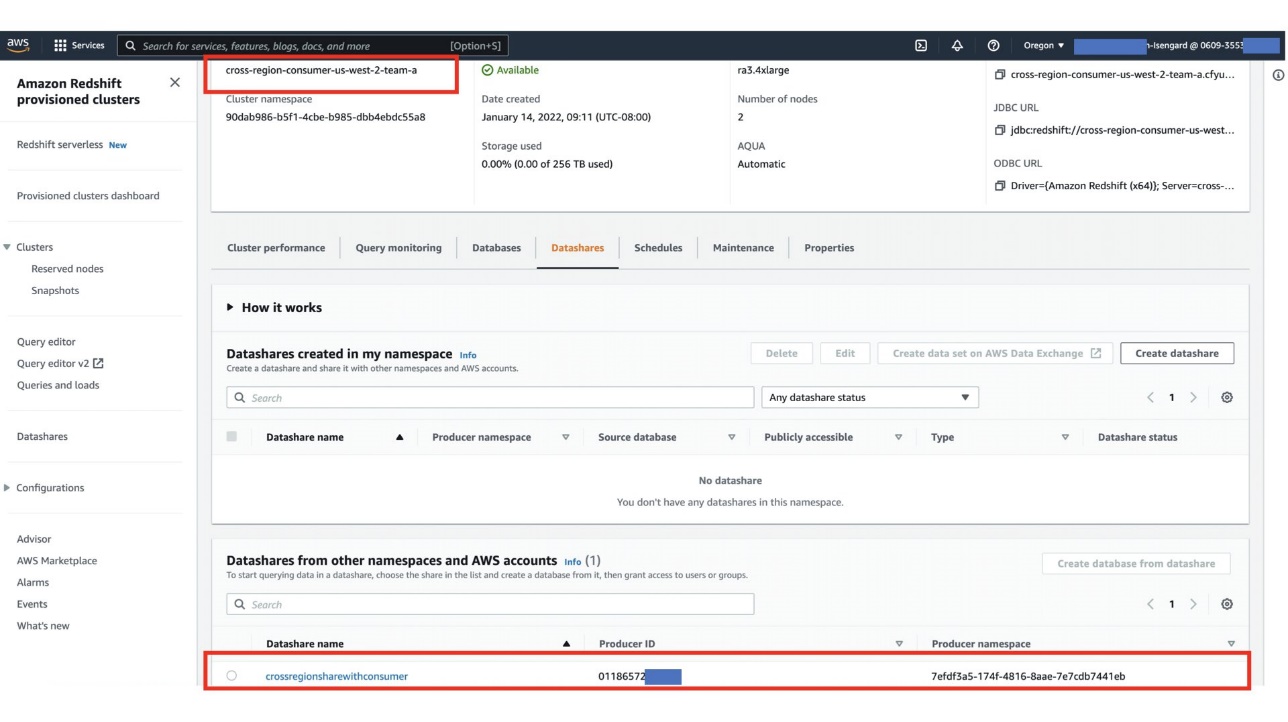
- Choose the cluster that you authorized access to the datashare.
- On the Datashares tab, confirm the datashare from the producer cluster is listed in the Datashares from other namespaces and AWS accounts section.
Query the datashare
You can query shared data using standard SQL interfaces, JDBC or ODBC drivers, and the Data API. You can also query data with high performance from familiar BI and analytic tools. You can run queries by referring to the objects from other Amazon Redshift databases that are both local to and remote from your cluster that you have permission to access.
You can do so simply by staying connected to local databases in your cluster. Then you can create consumer databases from datashares to consume shared data.
After you have done so, you can run cross-database queries joining the datasets. You can query objects in consumer databases using the three-part notation consumer_database_name.schema_name.table_name. You can also query using external schema links to schemas in the consumer database. You can query both local data and data shared from other clusters within the same query. Such a query can reference objects from the current connected database and from other non-connected databases, including consumer databases created from datashares.
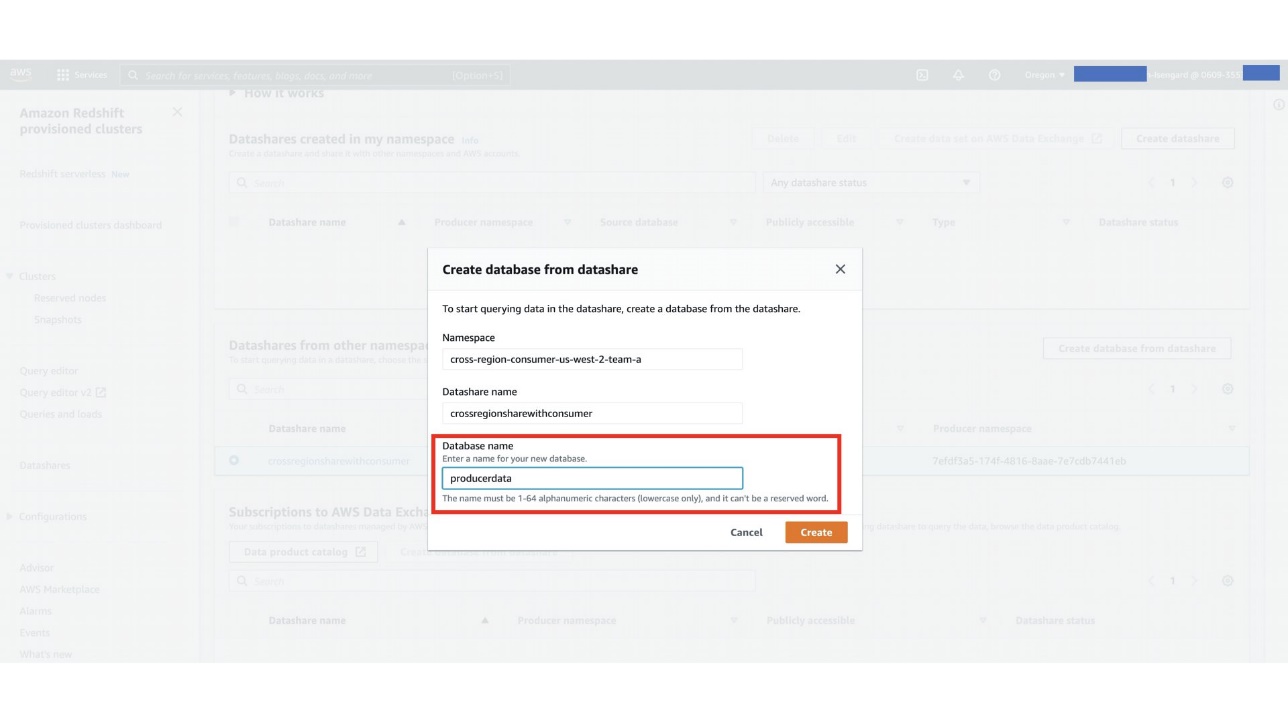
- On the consumer cluster, create a database to map the datashare objects to your cluster.
- You can now join your local schema objects with the objects in the shared database in a single query.
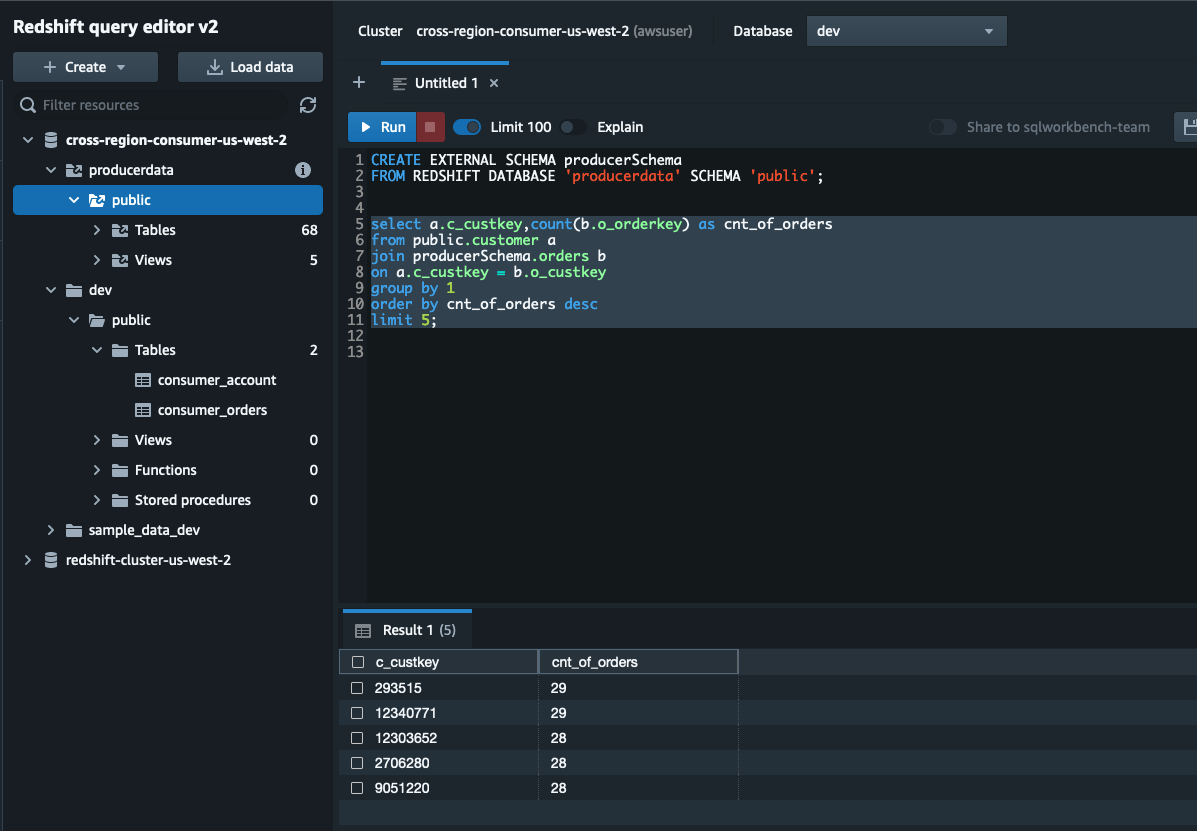
You can access the shared objects using a three-part notation, as highlighted in the following query:
The following screenshot shows our query results.

One alternative to using three-part notation is to create external schemas for the shared objects. As shown in the following code, we create producerSchema to map the datashare schema to a local schema:
Cross-Region data sharing in the same account
When setting up cross-Region data sharing in the same account, we don’t need to follow the authorize-associate flow on the console. We can easily configure this share using SQL commands. Complete the following steps:
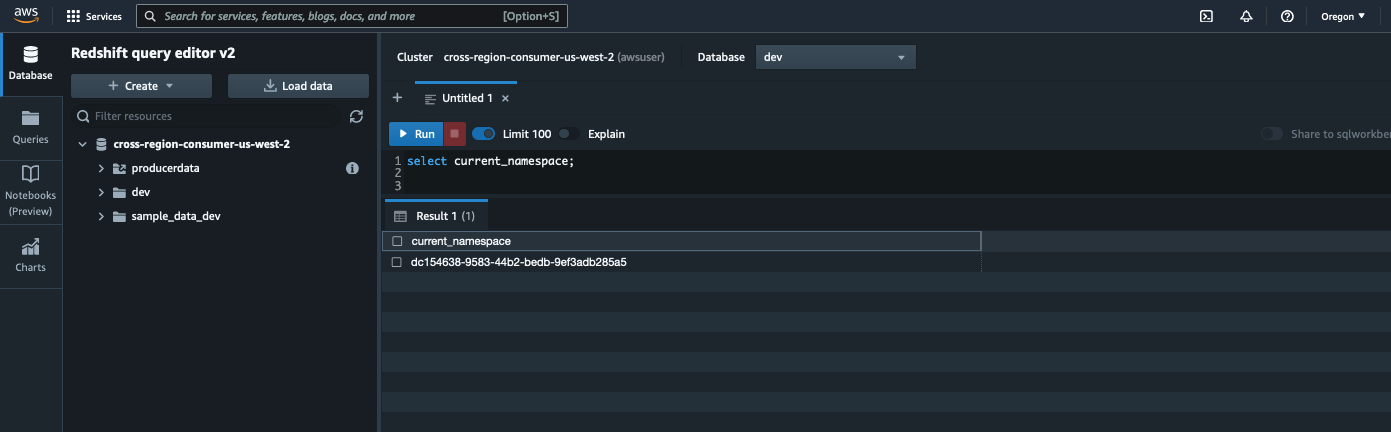
- On the consumer cluster, run the following SQL statement to get the current namespace:
The following screenshot shows our results.
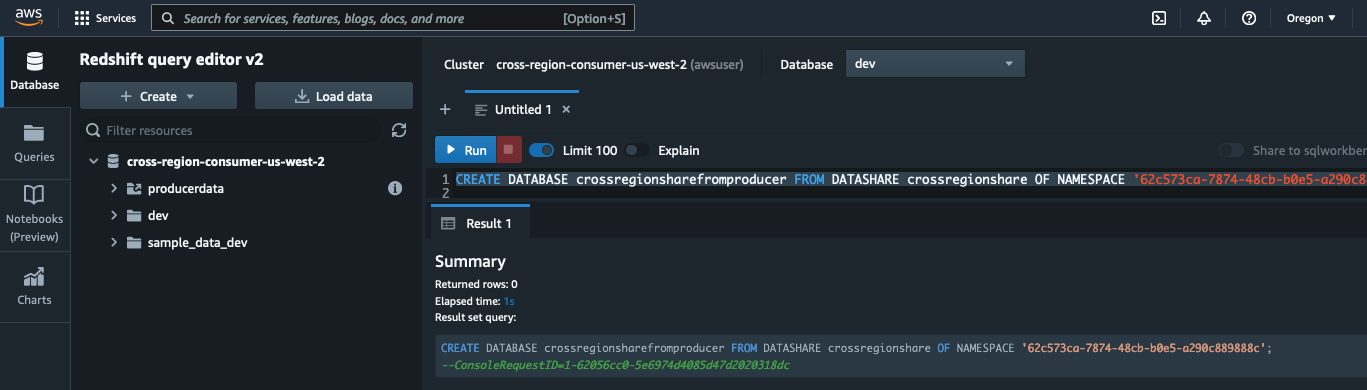
- On the producer cluster, run the SQL commands as shown in the following screenshot.
This step involves creating a datashare and making it publicly accessible so that the consumer can access it from across the Region. It then adds the database objects to the datashare, followed by granting permissions on this datashare to the consumer namespace. Use your consumer namespace from the previous step.

- Capture the producer namespace from the producer cluster to use in the next step.


The consumer cluster now has access to the datashare that was created on the producer.
- You can verify this from
svv_datashares.

- After you confirm that the datashare is available on consumer, the next step is to map the objects of the datashare to a database in order to start querying them, as shown in the following screenshots.




Considerations for using cross-Region data sharing
Keep in mind the following when using cross-Region data sharing:
- You must enable encryption both the producer and consumer accounts.
- For cross-Region data sharing, the consumer pays the cross-Region data transfer fee from the producer Region to the consumer Region based on the price of Amazon Simple Storage Service (Amazon S3), in addition to the cost of using the Amazon Redshift cluster.
- You can’t share stored procedures and Python UDF functions.
- This feature is only supported on the RA3 instance type.
- The producer cluster administrator is responsible for implementing any Region locality and compliance requirements (such as GDPR) by performing the following actions:
- Share only data that can be shared outside a Region in a datashare.
- Authorize the appropriate data consumer to access the datashare.
- The performance of the queries on data shared across Regions depends on the compute capacity of the consumer clusters.
- Network throughput between different Regions could yield different query performance. For instance, data sharing from us-east-1 to
us-east-2could yield better performance compared tous-east-1toap-northeast-1.
Summary
Amazon Redshift cross-Region data sharing is now available. Previously, data sharing was only allowed within the same Region. With this launch, you can share data across Regions with clusters residing in the same account or different accounts.
We look forward to hearing from you about your experience. If you have questions or suggestions, please leave a comment.
About the Authors
 Rahul Chaturvedi is an Analytics Specialist Solutions Architect AWS. Prior to this role, he was a Data Engineer at Amazon Advertising and Prime Video, where he helped build petabyte-scale data lakes for self-serve analytics.
Rahul Chaturvedi is an Analytics Specialist Solutions Architect AWS. Prior to this role, he was a Data Engineer at Amazon Advertising and Prime Video, where he helped build petabyte-scale data lakes for self-serve analytics.
 Kishore Arora is a Sr Analytics Specialist Solutions Architect at AWS. In this role, he helps customers modernize their data platform and architect big data solutions with AWS purpose-built data services. Prior to this role, he was a big data architect and delivery lead working with Tier-1 telecom customers.
Kishore Arora is a Sr Analytics Specialist Solutions Architect at AWS. In this role, he helps customers modernize their data platform and architect big data solutions with AWS purpose-built data services. Prior to this role, he was a big data architect and delivery lead working with Tier-1 telecom customers.
 BP Yau is a Sr Product Manager at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
BP Yau is a Sr Product Manager at AWS. He is passionate about helping customers architect big data solutions to process data at scale. Before AWS, he helped Amazon.com Supply Chain Optimization Technologies migrate its Oracle data warehouse to Amazon Redshift and build its next generation big data analytics platform using AWS technologies.
 Srikanth Sopirala is a Principal Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family, and road cycling.
Srikanth Sopirala is a Principal Analytics Specialist Solutions Architect at AWS. He is a seasoned leader with over 20 years of experience, who is passionate about helping customers build scalable data and analytics solutions to gain timely insights and make critical business decisions. In his spare time, he enjoys reading, spending time with his family, and road cycling.