Post Syndicated from Ayush Kulkarni original https://aws.amazon.com/blogs/compute/deploying-ai-models-for-inference-with-aws-lambda-using-zip-packaging/
AWS Lambda provides an event-driven programming model, scale-to-zero capability, and integrations with over 200 AWS services. This can make it a good fit for CPU-based inference applications that use customized, lightweight models and complete within 15 minutes.
Users usually package their function code as container images when using machine learning (ML) models that are larger than 250 MB, which is the Lambda deployment package size limit for zip files. In this post, we demonstrate an approach that downloads ML models directly from Amazon S3 into your function’s memory so that you can continue packaging your function code using zip files. To optimize startup latency without implementing application-level performance optimizations, we use Lambda SnapStart. SnapStart is an opt-in capability available for Java, Python, and .NET functions that optimizes startup latency—from 16.5s down to 1.6s for the application used in this post.
Application architecture
In this post, we demonstrate how to build a chatbot, using a 4-bit quantized version of the DeepSeek-R1-Distill-Qwen-1.5B-GGUF model for inference along with Lambda Function URL (FURL) and Lambda Web Adapter (LWA) to stream text responses. A FURL is a dedicated HTTP(s) endpoint for your Lambda function, and you can use LWA, an open-source project available on AWS Labs, for familiar web application frameworks (such as FastAPI, Next.JS, or Spring Boot) with Lambda. For a detailed explanation of how this response streaming architecture works, refer to this AWS Compute post.
Today, Lambda functions are run on CPU-based Amazon Elastic Compute Cloud (Amazon EC2) instances that use x86 and ARM64 architectures. For this reason, you must use SDKs that enable large language model (LLM) inference on CPUs. In this post, we also demonstrate how to use the llama.cpp project (through the llama-cpp-python library) and the FastAPI web framework to handle web requests. To use models that exceed the 250 MB zip package size limit of Lambda, you can download them from an S3 bucket during function initialization. The following figure describes this architecture in detail.
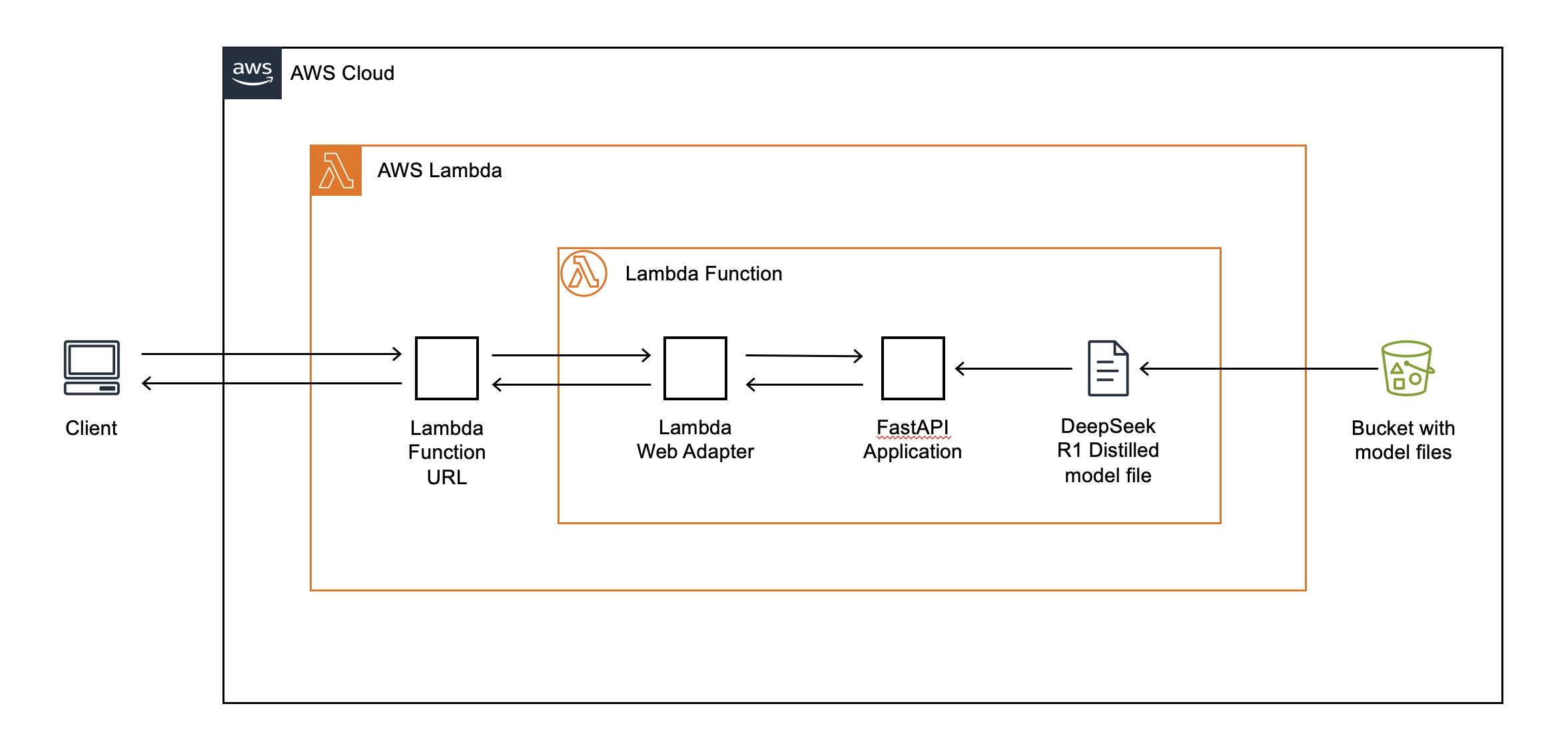
Figure 1: Application architecture
You can refer to this GitHub repository for the application code used in this example.
Downloading ML models during function initialization
As an alternative to packaging ML models using OCI container images, you can download them from durable storage, such as Amazon S3, during initialization. Initialization (or INIT) refers to the phase when Lambda downloads your function code, starts the language runtime and runs your function initialization code, which is code outside the handler. Loading large files directly into memory can be faster than first downloading them to disk and then loading them into memory. To do so, you can use a Linux capability called memfd, to directly download the ML model from Amazon S3 directly into memory, while referencing it using a standard file descriptor. Referencing the model using a file descriptor is necessary for llama.cpp to successfully import the model. This is comprised of two steps.
First, create a memory-only file descriptor:
Then, download the model into the memory-mapped file referenced by the previously created file descriptor.
Querying the chatbot
After deploying our sample chatbot application, we begin interacting with it.
The first query to the chatbot results in a new execution environment being initialized. When Lambda runs the initialization code described in the previous section, your ML model is directly downloaded from Amazon S3 into the function’s memory. After this, Lambda runs the function’s handler method. Looking at the X-Ray trace segment in the following figure, we observe that the first Init times out after 10 s. The second Init completes in 16.68 s. Furthermore, the first Init times out because Lambda limits the duration of this phase to 10s. If Init takes longer than this, then Lambda retries it during function invocation applying the function’s configured execution duration timeout.
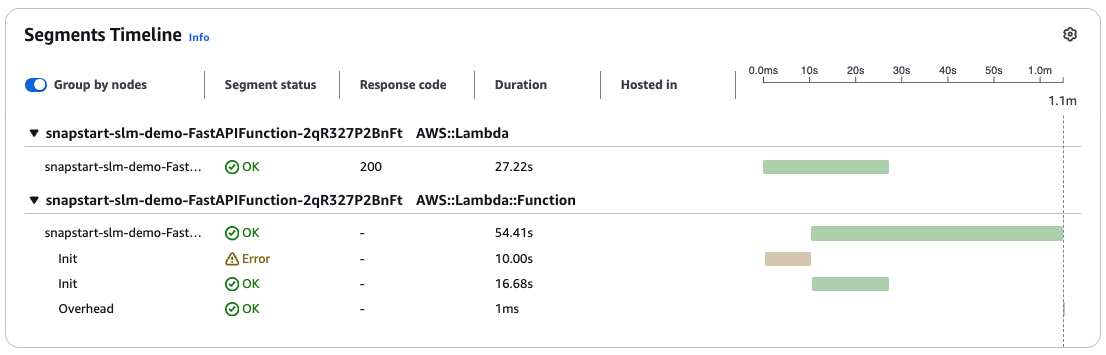
Figure 2: Init duration, indicated by AWS X-Ray trace segment
Optimizing startup performance with SnapStart
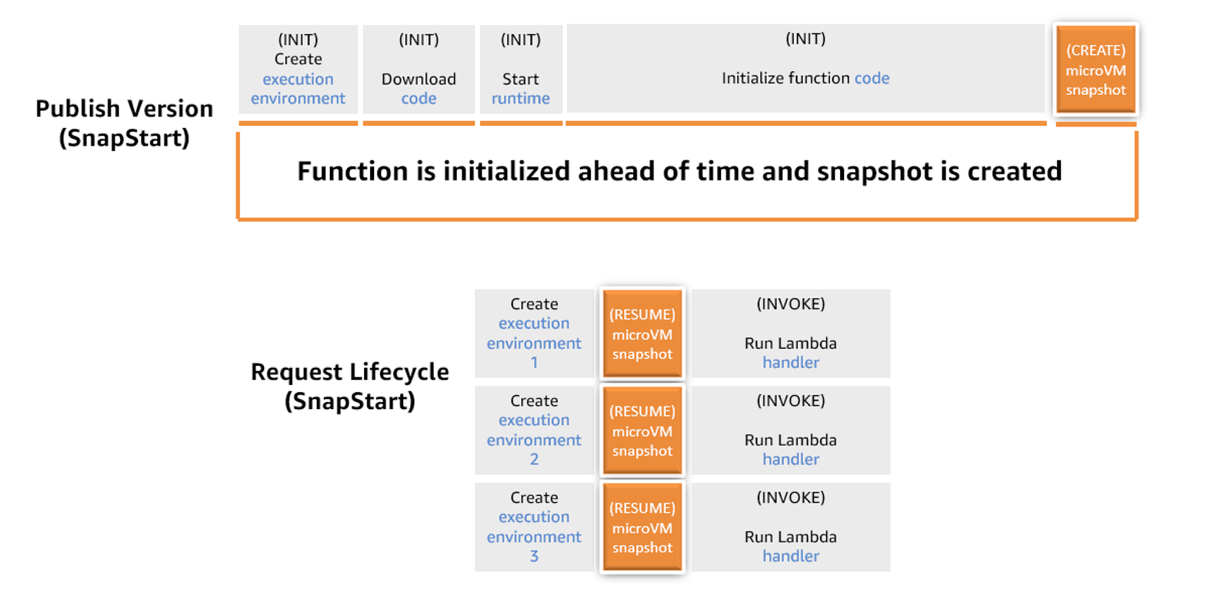
To optimize function startup latency, you can use Lambda SnapStart. SnapStart is designed to optimize startup latency stemming from long-running function initialization code. Lambda uses SnapStart to initialize your function when you publish a function version, as shown in the following figure. Then, Lambda takes a Firecracker microVM snapshot of the memory and disk state of the initialized execution environment, encrypts the snapshot, and intelligently caches it to optimize retrieval latency.
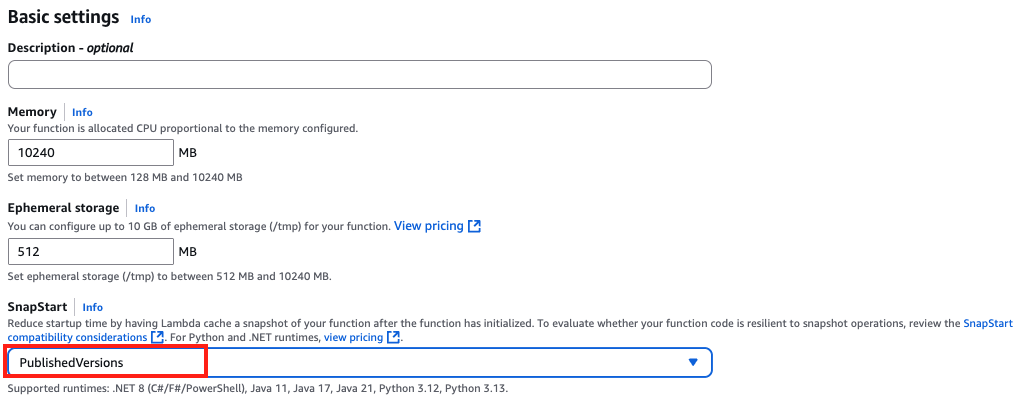

Figure 3: Enabling SnapStart
Querying the chatbot again shows a significant speed-up in initialization latency. You can verify this by viewing your function’s Amazon CloudWatch Logs, and searching for the “RESTORE_REPORT” log line, as shown in the following figure. For the sample application used, restore duration is 1.39 s. This is a considerable improvement over the Init duration of 16.68 s. Performance results may vary. But best of all, you don’t need to change a single line of code to achieve this improvement!

Figure 4: Achieving faster startup latency with SnapStart
Tuning inference performance
Inference performance depends on the CPU resources allocated to your function. Lambda allocates CPU power in proportion to the amount of memory configured for your function. Allocating more memory results in faster inference results, measured by the rate at which prompt tokens are evaluated (tokens evaluated per second), and the rate at which output tokens are produced (tokens generated per second). For this example, we allocate the maximum—in other words 10 GB memory—to maximize performance. Performance results obtained at other memory size configurations are included in the following table. As the table shows, doubling the memory allocated from 5 GB to 10 GB results in an 83% improvement in tokens evaluated and generated (per second), with only a 24% increase in billed GB-seconds. Performance results may vary. Refer to the sample code to instrument performance at different memory sizes.
| Memory Size (MB) |
Tokens evaluated per second |
Tokens generated per second |
Billed Duration (ms) |
Billed GB-seconds |
| 10240 | 44.68 | 29.53 | 36,660 | 366.60 |
| 9216 | 41.67 | 26.77 | 37,690 | 339.21 |
| 8192 | 37.17 | 22.05 | 44,298 | 354.38 |
| 7168 | 33.67 | 21.78 | 44,818 | 313.73 |
| 6144 | 28.89 | 18.43 | 52,579 | 315.47 |
| 5120 | 24.41 | 16.07 | 59,036 | 295.18 |
| 4096 | 19.07 | 12.94 | 72,648 | 290.59 |
| 3072 | 13.39 | 9.20 | 101,468 | 304.40 |
| 2048 | 10.01 | 6.77 | 135,862 | 271.72 |
Table 1: Inference performance at different memory sizes
Understanding how application costs scale with usage
To estimate the cost of running this workload, we begin by making some assumptions about our traffic patterns. We estimate about 30,000 inference calls per month to our Lambda function, with each inference call averaging 10s in duration. We set function memory to 10 GB, because it represents the ideal price-performance for our use case. We deploy our application in the US-West-2 (Oregon) AWS Region. Initially, because our number of invokes is low, we assume a 5% cold-start rate. In other words, 5% of invokes result in a cold-start when a new execution environment is created. When using SnapStart with the Lambda managed Python runtime, you are charged for caching your function’s snapshot and for restoring execution from your function’s snapshot.
With these parameters, the monthly Lambda bill is $91.1, calculated as shown in the following table. The monthly costs shown in the table are only illustrative.
| Charge | Calculation | Monthly Cost |
| Compute | 30,000 inferences * 10 seconds per inference * 10 GB (configured memory) * $0.00001667 per GB-second | $50.01 |
| Requests | $0.2 per million requests * 30,000 inferences | $0.006 |
| SnapStart – Cache | 10 GB function memory * 2.59M GB-seconds per month * $0.0000015046 per GB-second | $38.99 |
| SnapStart – Restore | 10 GB function memory * $0.0001397998 per GB restore * 1500 cold-starts | $2.09 |
| Total | Compute + Requests + SnapStart Cache + SnapStart Restore | $91.1 |
At low invocation volume, the added charges for the SnapStart account for approximately 50% of total monthly cost. For this added charge, cold-start latency reduces from 16.68 s to1.39 s, without having to implement complex optimizations ourselves. We can demonstrate how these costs scale with usage. We assume that our chatbot grows in popularity with traffic increasing 10 times to 300,000 monthly inference calls. Although cold-start rates for individual Lambda functions can vary due to several factors, Lambda’s re-use of execution environments generally results in cold-start rates decreasing with higher traffic volume. For the purposes of this example, we assume that our cold-start rate drops to 1% of all invokes with the 10 times growth in traffic.With these assumptions, our monthly Lambda bill at 10 times higher traffic volume is $543.3. Added charges for SnapStart now constitute less than 10% of our total bill, as shown in the following table. Monthly costs shown in this table are only illustrative.
| Charge | Calculation | Monthly Cost |
| Compute | 300,000 inferences * 10 seconds per inference * 10 GB (configured memory) * $0.00001667 per GB-second | $500.01 |
| Requests | $0.2 per million requests * 300,000 inferences | $0.06 |
| SnapStart – Cache | 10 GB function memory * 2.59M GB-seconds per month * $0.0000015046 per GB-second | $38.99 |
| SnapStart – Restore | 10 GB function memory * $0.0001397998 per GB restore * 3000 cold-starts | $4.18 |
| Total | Compute + Requests + SnapStart Cache + SnapStart Restore | $543.24 |
Considerations
Lambda functions are run on CPU-based EC2 instances. If your ML models need GPU-based inference, foundational LLMs, or exceed the Lambda limits on execution duration (15 minutes) and function memory (10 GB), then you can use AWS Machine Learning, AWS Generative AI, or AWS Compute services.
Moreover, you should know the following things about Lambda SnapStart:
Handling uniqueness: If your initialization code generates unique content that is included in the snapshot, then the content isn’t unique when it’s reused across execution environments. To maintain uniqueness when using SnapStart, you must generate unique content after initialization, such as if your code uses custom random number generation that doesn’t rely on built-in-libraries or caches any information such as DNS entries that might expire during initialization. To learn how to restore uniqueness, visit Handling uniqueness with Lambda SnapStart in the Lambda Developer Guide.
Performance tuning: To maximize performance, we recommend that you preload dependencies and initialize resources that contribute to startup latency in your initialization code instead of in the function handler. This moves the latency associated with these operations during version publish, rather than during function invocation and can yield faster startup performance. To learn more, visit Performance tuning for Lambda SnapStart in the Lambda Developer Guide.
Networking best practices: The state of connections that your function establishes during the initialization phase isn’t guaranteed when Lambda resumes your function from a snapshot. In most cases, network connections that an AWS SDK establishes automatically resume. For other connections, review the Networking best practices for Lambda SnapStart in the Lambda Developer Guide.
Conclusion
In this post, we demonstrated how you can download ML models directly from Amazon S3 into your function’s memory, enabling you to deploy your AWS Lambda functions using zip packages. To optimize startup latency without implementing application-level performance optimizations, we also demonstrated the use of Lambda SnapStart, an opt-in capability available for Java, Python, and .NET. For the application used in this post, SnapStart reduced startup latency from 16.68 s down to 1.39 s.
To learn more about Lambda, refer to our documentation. For details about Lambda SnapStart, refer to our launch posts for Java, Python and .Net, and the documentation.
You can refer to this GitHub repository for the application code used in this example.