Post Syndicated from Manan Goel original https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
In 2021 and 2020, we told you about the new features in Amazon Redshift that make it easier, faster, and more cost-effective to analyze all your data and find rich and powerful insights. In 2022, we are happy to report that the Amazon Redshift team was hard at work. We worked backward from customer requirements and announced multiple new features to make it easier, faster, and more cost-effective to analyze all your data. This post covers some of these new features.
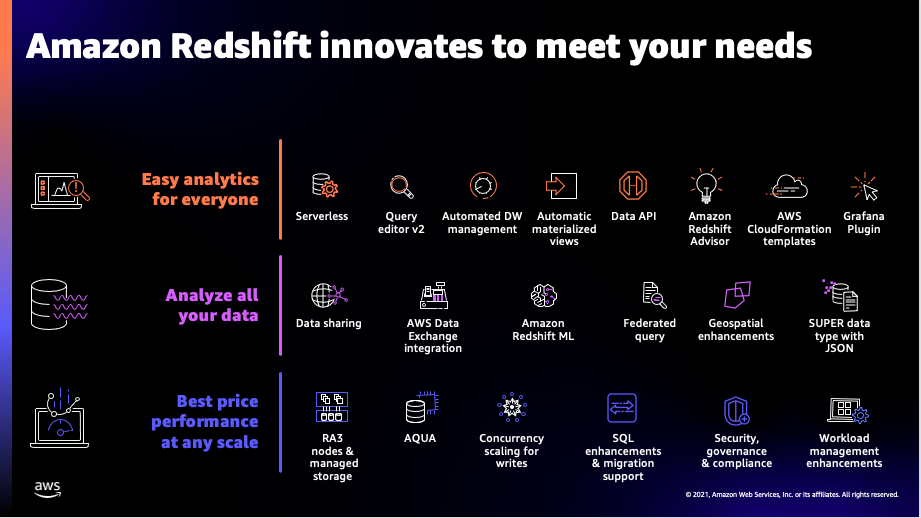
At AWS, for data and analytics, our strategy is to give you a modern data architecture that helps you break free from data silos; have purpose-built data, analytics, machine learning (ML), and artificial intelligence services to use the right tool for the right job; and have open, governed, secure, and fully managed services to make analytics available to everyone. Within AWS’s modern data architecture, Amazon Redshift as the cloud data warehouse remains a key component, enabling you to run complex SQL analytics at scale and performance on terabytes to petabytes of structured and unstructured data, and make the insights widely available through popular business intelligence (BI) and analytics tools. We continue to work backward from customers’ requirements, and in 2022 launched over 40 features in Amazon Redshift to help customers with their top data warehousing use cases, including:
- Self-service analytics
- Easy data ingestion
- Data sharing and collaboration
- Data science and machine learning
- Secure and reliable analytics
- Best price performance analytics
Let’s dive deeper and discuss the new Amazon Redshift features in these areas.
Self-service analytics
Customers continue to tell us that data and analytics is becoming ubiquitous, and everyone in their organization needs analytics. We announced Amazon Redshift Serverless (in preview) in 2021 to make it easy to run and scale analytics in seconds without having to provision and manage data warehouse infrastructure. In July 2022, we announced the general availability of Redshift Serverless, and since then thousands of customers, including Peloton, Broadridge Financials, and NextGen Healthcare, have used it to quickly and easily analyze their data. Amazon Redshift Serverless automatically provisions and intelligently scales data warehouse capacity to deliver high performance for all your analytics, and you only pay for the compute used for the duration of the workloads on a per-second basis. Since GA, we have added features like resource tagging, simplified monitoring, and availability in additional AWS Regions to further simplify billing and expand the reach across more Regions worldwide.
In 2021, we launched Amazon Redshift Query Editor V2, which is a free web-based tool for data analysts, data scientists, and developers to explore, analyze, and collaborate on data in Amazon Redshift data warehouses and data lakes. In 2022, Query Editor V2 got additional enhancements such as notebook support for improved collaboration to author, organize, and annotate queries; user access through identity provider (IdP) credentials for single sign-on; and the ability to run multiple queries concurrently to improve developer productivity.

Autonomics is another area where we are actively working to use ML-based optimizations and give customers a self-learning and self-optimizing data warehouse. In 2022, we announced the general availability of Automated Materialized Views (AutoMVs) to improve the performance of queries (reduce the total runtime) without any user effort by automatically creating and maintaining materialized views. AutoMVs, combined with automatic refresh, incremental refresh, and automatic query rewriting for materialized views, made materialized views maintenance free, giving you faster performance automatically. In addition, the automatic table optimization (ATO) capability for schema optimization and automatic workload management (auto WLM) capability for workload optimization got further improvements for better query performance.
Easy data ingestion
Customers tell us that they have their data distributed over multiple data sources like transactional databases, data warehouses, data lakes, and big data systems. They want the flexibility to integrate this data with no-code/low-code, zero-ETL data pipelines or analyze this data in place without moving it. Customers tell us that their current data pipelines are complex, manual, rigid, and slow, resulting in incomplete, inconsistent, and stale views of data, limiting insights. Customers have asked us for a better way forward, and we are pleased to announce a number of new capabilities to simplify and automate data pipelines.
Amazon Aurora zero-ETL integration with Amazon Redshift (preview) enables you to run near-real-time analytics and ML on petabytes of transactional data. It offers a no-code solution for making transactional data from multiple Amazon Aurora databases available in Amazon Redshift data warehouses within seconds of being written to Aurora, eliminating the need to build and maintain complex data pipelines. With this feature, Aurora customers can also access Amazon Redshift capabilities such as complex SQL analytics, built-in ML, data sharing, and federated access to multiple data stores and data lakes. This feature is now available in preview for Amazon Aurora MySQL-Compatible Edition version 3 (with MySQL 8.0 compatibility), and you can request access to the preview.
Amazon Redshift now supports auto-copy from Amazon S3 (preview) to simplify data loading from Amazon Simple Storage Service (Amazon S3) into Amazon Redshift. You can now set up continuous file ingestion rules (copy jobs) to track your Amazon S3 paths and automatically load new files without the need for additional tools or custom solutions. Copy jobs can be monitored through system tables, and they automatically keep track of previously loaded files and exclude them from the ingestion process to prevent data duplication. This feature is now available in preview; you can try this feature by creating a new cluster using the preview track.
Customers continue to tell us that they need instantaneous, in-the-moment, real-time analytics, and we are pleased to announce the general availability of streaming ingestion support in Amazon Redshift for Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK). This feature eliminates the need to stage streaming data in Amazon S3 before ingesting it into Amazon Redshift, enabling you to achieve low latency, measured in seconds, while ingesting hundreds of megabytes of streaming data per second into your data warehouses. You can use SQL within Amazon Redshift to connect to and directly ingest data from multiple Kinesis data streams or MSK topics, create auto-refreshing streaming materialized views with transformations on top of streams directly to access streaming data, and combine real-time data with historical data for better insights. For example, Adobe has integrated Amazon Redshift streaming ingestion as part of their Adobe Experience Platform for ingesting and analyzing, in real time, the web and applications clickstream and session data for various applications like CRM and customer support applications.
Customers have told us that they want simple, out-of-the-box integration between Amazon Redshift, BI and ETL (extract, transform, and load) tools, and business applications like Salesforce and Marketo. We are pleased to announce the general availability of Informatica Data Loader for Amazon Redshift, which enables you to use Informatica Data Loader for high-speed and high-volume data loading into Amazon Redshift for free. You can simply select the Informatica Data Loader option on the Amazon Redshift console. Once in Informatica Data Loader, you can connect to sources such as Salesforce or Marketo, choose Amazon Redshift as a target, and begin to load your data.

Data sharing and collaboration
Customers continue to tell us that they want to analyze all their first-party and third-party data and make the rich data-driven insights available to their customers, partners, and suppliers. We launched new features in 2021, such as Data Sharing and AWS Data Exchange integration, to make it easier for you to analyze all of your data and share it within and outside your organizations.
A great example of a customer using data sharing is Orion. Orion provides real-time data as a service (DaaS) solutions for customers in the financial services industry, such as wealth management, asset management, and investment management providers. They have over 2,500 data sources that are primarily SQL Server databases sitting both on premises and in AWS. Data is streamed using Kafka connecters into Amazon Redshift. They have a producer cluster that receives all this data and then uses Data Sharing to share data in real time for collaboration. This is a multi-tenant architecture that serves multiple clients. Given the sensitivity of their data, data sharing is a way to provide workload isolation between clusters and also securely share that data to end-users.
In 2022, we continued to invest in this area to improve the performance, governance, and developer productivity with new features to make it easier, simpler, and faster to share and collaborate on data.
As customers are building large-scale data sharing configurations, they have asked for simplified governance and security for shared data, and we are adding centralized access control with AWS Lake Formation for Amazon Redshift datashares to enable sharing live data across multiple Amazon Redshift data warehouses. With this feature, Amazon Redshift now supports simplified governance of Amazon Redshift datashares by using AWS Lake Formation as a single pane of glass to centrally manage data or permissions on datashares. You can view, modify, and audit permissions, including row-level and column-level security on the tables and views in the Amazon Redshift datashares, using Lake Formation APIs and the AWS Management Console, and allow the Amazon Redshift datashares to be discovered and consumed by other Amazon Redshift data warehouses.
Data science and machine learning
Customers continue to tell us that they want their data and analytics systems to help them answer a wide range of questions, from what is happening in their business (descriptive analytics) to why is it happening (diagnostic analytics) and what will happen in the future (predictive analytics). Amazon Redshift provides features like complex SQL analytics, data lake analytics, and Amazon Redshift ML for customers to analyze their data and discover powerful insights. Redshift ML integrates Amazon Redshift with Amazon SageMaker, a fully managed ML service, enabling you to create, train, and deploy ML models using familiar SQL commands.
Customers have also asked us for better integration between Amazon Redshift and Apache Spark, so we are excited to announce Amazon Redshift integration for Apache Spark to make data warehouses easily accessible for Spark-based applications. Now, developers using AWS analytics and ML services such as Amazon EMR, AWS Glue, and SageMaker can effortlessly build Apache Spark applications that read from and write to their Amazon Redshift data warehouses. Amazon EMR and AWS Glue package the Redshift-Spark connector so you can easily connect to your data warehouse from your Spark-based applications. You can use several pushdown capabilities for operations such as sort, aggregate, limit, join, and scalar functions so that only the relevant data is moved from your Amazon Redshift data warehouse to the consuming Spark application. You can also make your applications more secure by utilizing AWS Identity and Access Management (IAM) credentials to connect to Amazon Redshift.
Secure and reliable analytics
Customers continue to tell us that their data warehouses are mission-critical systems that need high availability, reliability, and security. We launched a number of new features in 2022 in this area.
Amazon Redshift now supports Multi-AZ deployments (in preview) for RA3 instance-based clusters, which enables running your data warehouse in multiple AWS Availability Zones simultaneously and continuous operation in unforeseen Availability Zone-wide failure scenarios. Multi-AZ support is already available for Redshift Serverless. An Amazon Redshift Multi-AZ deployment allows you to recover in case of Availability Zone failures without any user intervention. An Amazon Redshift Multi-AZ data warehouse is accessed as a single data warehouse with one endpoint, and helps you maximize performance by distributing workload processing across multiple Availability Zones automatically. No application changes are needed to maintain business continuity during unforeseen outages.
In 2022, we launched features like role-based access control, row-level security, and data masking (in preview) to make it easier for you to manage access and decide who has access to which data, including obfuscating personally identifiable information (PII) like credit card numbers.
You can use role-based access control (RBAC) to control end-user access to data at a broad or granular level based on an end-user’s job role and permissions. With RBAC, you can create a role using SQL, grant a collection of granular permissions to the role, and then assign that role to end-users. Roles can be granted object-level, column-level, and system-level permissions. Additionally, RBAC introduces out-of-box system roles for DBAs, operators, security admins, or customized roles.
Row-level security (RLS) simplifies design and implementation of fine-grained access to the rows in tables. With RLS, you can restrict access to a subset of rows within a table based on the users’ job role or permissions with SQL.
Amazon Redshift support for dynamic data masking (DDM), which is now available in preview, allows you to simplify protecting PII such as Social Security numbers, credits card numbers, and phone numbers in your Amazon Redshift data warehouse. With dynamic data masking, you control access to your data through simple SQL-based masking policies that determine how Amazon Redshift returns sensitive data to the user at query time. You can create masking policies to define consistent, format-preserving, and irreversible masked data values. You can apply a masking policy on a specific column or list of columns in a table. Also, you have the flexibility of choosing how to show the masked data. For example, you can completely hide the data, replace partial real values with wildcard characters, or define your own way to mask the data using SQL expressions, Python, or AWS Lambda user-defined functions. Additionally, you can apply a conditional masking policy based on other columns, which selectively protects the column data in a table based on the values in one or more different columns.
We also announced enhancements to audit logging, native integration with Microsoft Azure Active Directory, and support for default IAM roles in additional Regions to further simplify security management.
Best price performance analytics
Customers continue to tell us that they need fast and cost-effective data warehouses that deliver high performance at any scale while keeping costs low. From day 1 since Amazon Redshift’s launch in 2012, we have taken a data-driven approach and used fleet telemetry to build a cloud data warehouse service that gives you the best price performance at any scale. Over the years, we have evolved Amazon Redshift’s architecture and launched features such as Redshift Managed Storage (RMS) for separation of storage and compute, Amazon Redshift Spectrum for data lake queries, automatic table optimization for physical schema optimization, automatic workload management to prioritize workloads and allocate the right compute and memory, cluster resize to scale compute and storage vertically, and concurrency scaling to dynamically scale compute out or in. Our performance benchmarks continue to demonstrate Amazon Redshift’s price performance leadership.
In 2022, we added new features such as the general availability of concurrency scaling for write operations like COPY, INSERT, UPDATE, and DELETE to support virtually unlimited concurrent users and queries. We also introduced performance improvements for string-based data processing through vectorized scans over lightweight, CPU-efficient, dictionary-encoded string columns, which allows the database engine to operate directly over compressed data.
We also added support for SQL operators such as MERGE (single operator for inserts or updates); CONNECY_BY (for hierarchical queries); GROUPING SETS, ROLLUP, and CUBE (for multi-dimensional reporting); and increased the size of the SUPER data type to 16 MB to make it easier for you to migrate from legacy data warehouses to Amazon Redshift.
Conclusion
Our customers continue to tell us that data and analytics remains a top priority for them and the need to cost-effectively extract more business value from their data during these times is more pronounced than any other time in the past. Amazon Redshift as your cloud data warehouse enables you to run complex SQL analytics with scale and performance on terabytes to petabytes of structured and unstructured data and make the insights widely available through popular BI and analytics tools.
Although we launched over 40 features in 2022 and the pace of innovation continues to accelerate, it remains day 1 and we look forward to hearing from you on how these features help you unlock more value for your organizations. We invite you to try these new features and get in touch with us through your AWS account team if you have further comments.
About the author
 Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.
Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.