Post Syndicated from Rafael Ribeiro, Moe Haidar original https://aws.amazon.com/blogs/big-data/automating-it-support-with-ai-how-nexthink-uses-opensearch-service-to-power-self-service-issue-resolution/
This is a guest post by Rafael Ribeiro and Moe Haidar, at Nexthink, in partnership with AWS.
Nexthink is the leader in digital employee experience, helping enterprises improve how employees interact with technology in the workplace. The company gives IT teams real-time visibility into endpoint performance, application usage, and employee sentiment across millions of devices worldwide.
At the heart of Nexthink’s innovation is Spark, an autonomous artificial intelligence (AI) agent that automates IT support. Spark resolves IT issues for employees, from troubleshooting application crashes to resetting configurations and running remediation scripts. Rather than routing tickets or providing scripted responses, the agent takes direct action, achieving a 77% resolution rate at first contact without human escalation.
Spark operates at enterprise scale, deployed across 12 AWS Regions to serve global customers with low-latency responses.
In this post, we explore how Nexthink combined Amazon OpenSearch Service vector search, Amazon Bedrock, and infrastructure as code to power the Spark agent’s retrieval layer.
The challenge: Why vector search for AI agents?
For an AI agent to autonomously resolve IT issues, it must quickly retrieve the most relevant context from a vast knowledge base. Traditional keyword search falls short because:
- Semantic understanding matters: An employee asking “my laptop is running slow” should match articles about “system performance optimization” even without exact keyword overlap.
- Accurate retrieval drives correct outcomes: The quality of an AI agent’s response is only as good as the context it retrieves. When the agent pulls the right documentation, scripts, and historical resolutions, it produces accurate, safe actions. When retrieval is imprecise, the consequences can be severe. An agent acting on the wrong context could run destructive commands like
rm -rf *, wipe critical data, or apply an incorrect fix that escalates the problem. Accurate vector search is the guardrail that keeps autonomous agents grounded in verified, relevant knowledge. - Speed is critical: Enterprise users expect near-instant responses, so retrieval must run in sub-second time across millions of documents.
This led Nexthink to implement Amazon OpenSearch Service with vector search capabilities, using Amazon Titan Text Embeddings V2 through Amazon Bedrock for embedding generation. With this architecture, Spark performs semantic search across all knowledge sources, retrieving contextually relevant information that drives accurate, autonomous issue resolution.
High-level architecture
The following diagram illustrates the high-level architecture of Nexthink’s Spark agent implementation with Amazon OpenSearch Service.
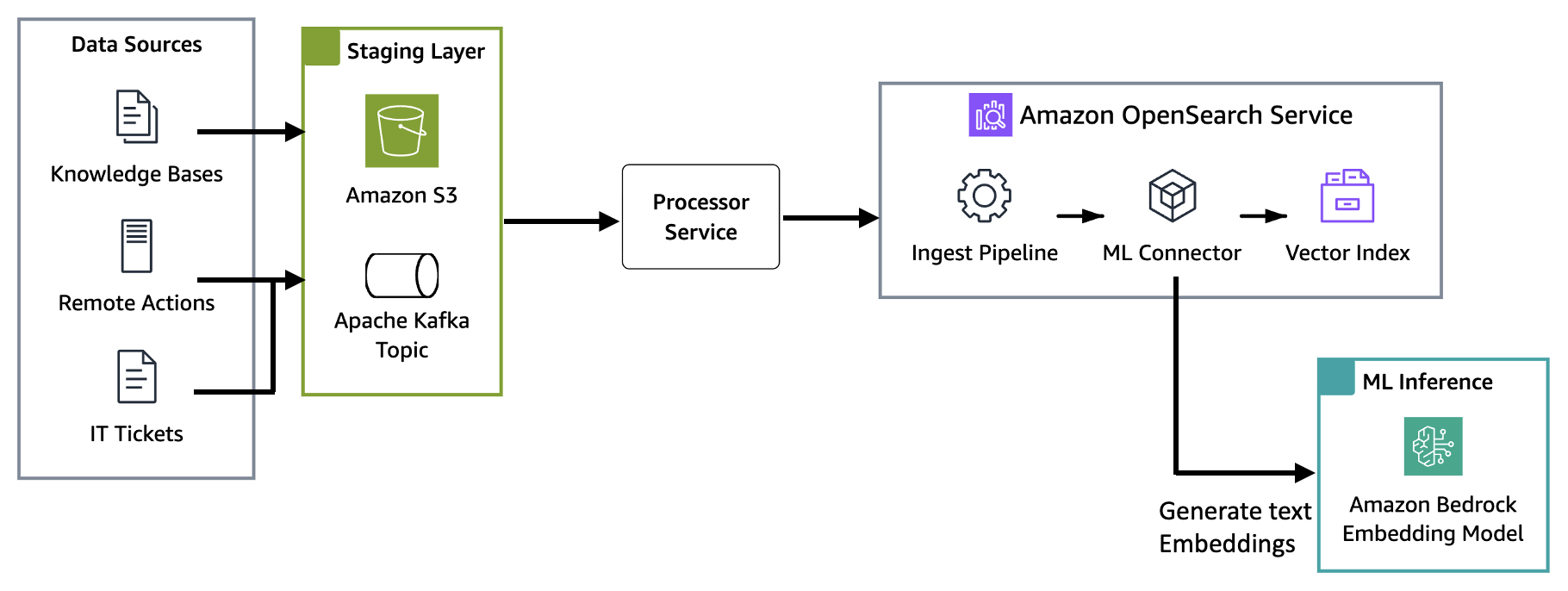
Architecture components
Amazon Elastic Kubernetes Service (Amazon EKS) hosts the Spark agent, which interprets user queries, retrieves relevant context, and runs autonomous resolutions. With container orchestration, the agent scales horizontally across Nexthink’s 12 AWS Regions while maintaining consistent response times. The agent communicates with Amazon OpenSearch Service to perform semantic searches, retrieving the most contextually relevant documentation and automation scripts for each user’s issue.
Amazon OpenSearch Service functions as the central vector store, providing the k-Nearest Neighbors (k-NN) capabilities required for semantic search. OpenSearch Service stores document embeddings (dense vector representations of text content) alongside traditional metadata fields. When the AI agent submits a query, OpenSearch Service performs approximate nearest neighbor (ANN) searches to find documents with semantically similar embeddings, even when exact keywords don’t match. This vector search capability, combined with the proven scalability and managed infrastructure of OpenSearch Service, makes it well suited for AI agent architectures that require fast, accurate context retrieval.
Amazon Bedrock provides the foundation models used to generate text embeddings. Nexthink uses Amazon Titan Text Embeddings V2, hosted on Amazon Bedrock, to convert both documents and queries into dense vector representations. OpenSearch Service integrates natively with Amazon Bedrock through the OpenSearch ML Connector, which handles embedding generation at both index and query time.
Data ingestion pipeline
A critical component of any AI agent architecture is the data ingestion pipeline. This mechanism transforms raw documents into searchable, semantically indexed content in OpenSearch Service. For Spark, the pipeline must handle diverse data sources while automatically generating vector embeddings for semantic search.
Step 1: Staging and preprocessing layer
Staging layer in Amazon S3
Knowledge bases (KBs) are staged in Amazon Simple Storage Service (Amazon S3) before being processed through the ingestion pipeline. Amazon S3 provides durable storage, versioning capabilities, and integration with OpenSearch Service ingestion mechanisms. When documentation updates occur, new versions are uploaded to Amazon S3, which triggers the ingestion pipeline to reprocess and re-embed the content.
Event-driven streaming with Apache Kafka
IT tickets, agent interactions, and remote actions are processed through Apache Kafka for reliable message delivery during traffic spikes. Its consumer group model lets the ingestion pipeline scale horizontally based on event volume.
Step 2: Embedding generation during indexing time
Nexthink uses ingest pipelines inside OpenSearch Service to process the data at ingestion time, including generating text embeddings. When documents are sent to OpenSearch Service, the text_embedding processor inside the ingest pipeline automatically invokes the machine learning (ML) Connector to generate embeddings.
The ML Connector is the OpenSearch Service built-in framework for integrating external ML services. It handles request signing between OpenSearch Service and Amazon Bedrock, parses the Amazon Bedrock response to extract embeddings, maps them to index fields, and manages retries on failure. This eliminated the need for custom integration code and accelerated Nexthink’s time to market.
The following ingestion pipeline configuration demonstrates how to configure the text_embedding processor.
In this configuration:
- model_id: References the registered ML model connected to Amazon Bedrock.
- field_map: Maps the source text field (
content) to the target embedding field (content_embedding).
Step 3: Embeddings and data structure in OpenSearch Service
Nexthink stores embeddings alongside textual and metadata information in their k-NN index. For the vector field, they use Hierarchical Navigable Small World (HNSW) with the Lucene engine, as shown in the following example.
In this configuration:
- method.name: Defines the algorithm used to organize vector data. Supported values are HNSW and Inverted File (IVF).
- method.engine: References the library that implements the HNSW method. Supported engines are Lucene and FAISS.
- method.space_type: References the vector space used to calculate the distance between vectors. Supported values include innerproduct, l2, and cosinesimil.
- content_embedding: References the k-NN vector field that serves the vector search.
Multi-tenant search and retrieval
Enterprise AI agent deployments must address a critical challenge: making sure that users only access data they’re authorized to see. For Nexthink, serving multiple enterprise customers from a shared infrastructure requires robust multi-tenant security. Each customer’s knowledge base, automation scripts, and support tickets must remain isolated while the shared vector index continues to perform well.
The following diagram illustrates the search flow from user query to ranked results.
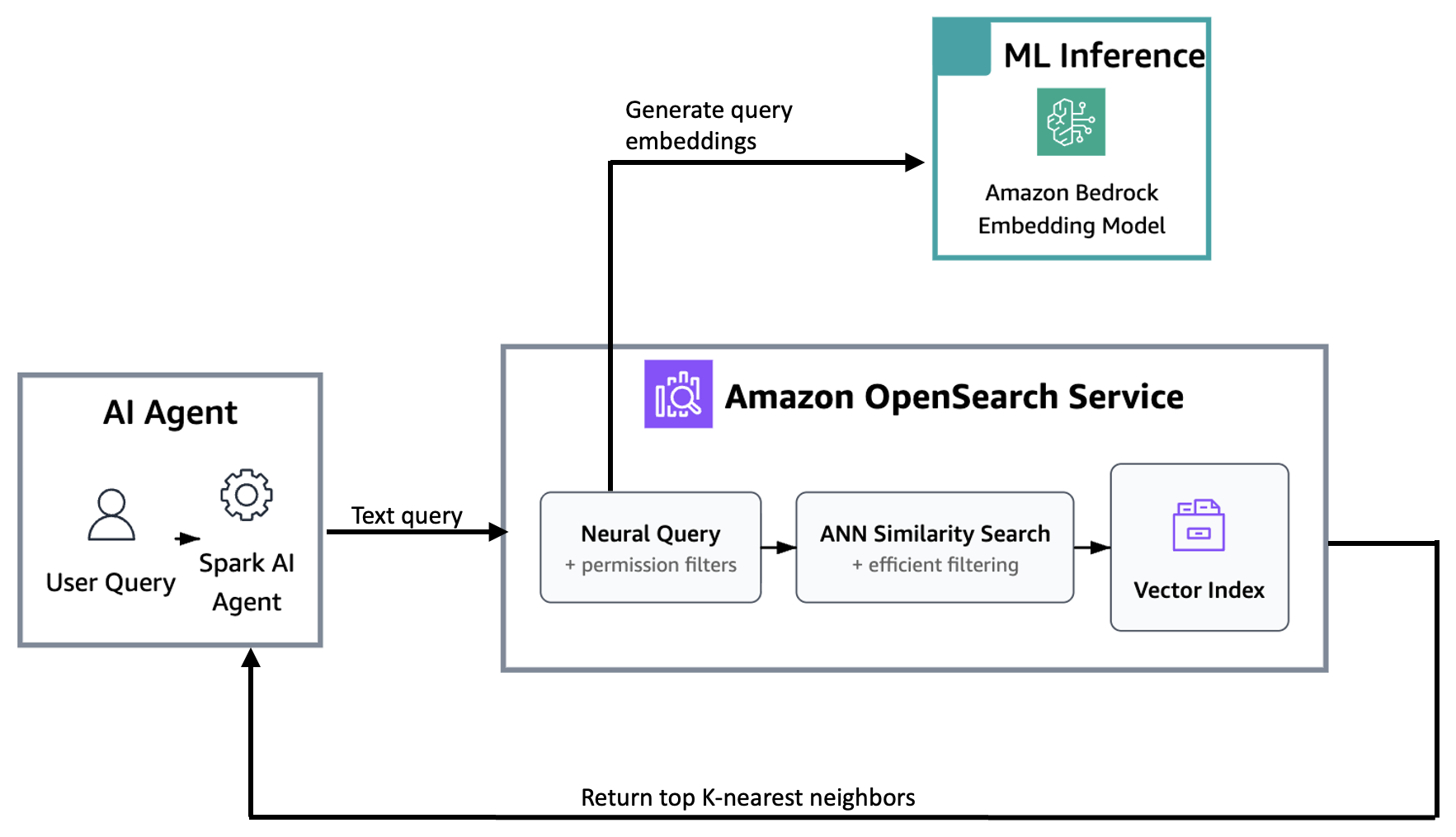
Tenant management
Nexthink stores information about each tenant inside the tenant_id field. This design lets permission filters run efficiently alongside vector similarity searches. Additionally, Nexthink stores the tenant_id as a keyword type in the index mapping shared previously, so that filtering runs without the overhead of text analysis. Instead of pre-filtering with k-NN queries through a score script filter, the OpenSearch engine uses an intelligent decision-based approach for k-NN filtering called efficient filtering.
Neural query example with efficient filtering
OpenSearch’s neural search simplifies vector search by handling embedding generation as part of the query itself. Instead of requiring the application to call an embedding model separately and then submit a raw k-NN query with a vector, a neural query accepts plain text and uses the registered ML Connector to generate the embedding on the fly. As a result, the Spark agent can send natural-language queries directly to OpenSearch Service without any client-side embedding logic.
The following query demonstrates how Nexthink combines neural search with tenant isolation through efficient filtering in OpenSearch Service.
In this query structure:
- bool.must: Contains the neural search clause that performs semantic matching against document embeddings.
- bool.filter: Applies the tenant isolation constraint, so that only documents belonging to
customer-123are returned.
Nexthink’s contribution to the technical community
A key principle in Nexthink’s architecture is treating infrastructure as code. With deployments spanning 12 AWS Regions, manual provisioning would be error-prone and time-consuming. Therefore, Nexthink uses several infrastructure as code (IaC) technologies, including Terraform, to provision resources.
Although the Terraform provider supports core OpenSearch Service resources like indices and index templates, it lacked support for some of the ML Commons resources required to integrate Amazon Bedrock:
- ML Connectors: Required to establish connections to external ML services like Amazon Bedrock.
- ML Model Groups: Needed to organize and manage related models.
- ML Models: Required to register models that use the connectors.
Without these resources, Nexthink initially relied on workarounds using local-exec provisioners and null_resource blocks to call the OpenSearch Service API directly. This approach was fragile, difficult to maintain, and didn’t integrate well with Terraform’s state management.
Contributing back
Rather than maintaining a private fork indefinitely, Nexthink chose to contribute their custom Terraform resources back to the OpenSearch Project community. This decision aligned with their engineering values to help other organizations implement similar architectures and contribute to the broader community.
Open source contribution links
The Terraform provider contributions are being added to the official OpenSearch project repository:
- Pull Request: Add support for ML Connector, ML Model Group, and ML Model resources #280.
- Feature Request: Contribution – Support for ML resources #281.
These contributions let any organization provision OpenSearch Service ML resources with Terraform, which streamlines the deployment of AI agent architectures that integrate with Amazon Bedrock or other ML services.
Conclusion
Nexthink’s implementation of Amazon OpenSearch Service for the Spark agent demonstrates how vector search capabilities can power autonomous IT support at enterprise scale. By combining semantic search with multi-tenant security and infrastructure as code practices, Nexthink achieved a 77% resolution rate at first contact, so that employees can resolve IT issues without human escalation.
Get started
Ready to build your own AI agent with vector search capabilities? Here are your next steps:
- Explore Amazon OpenSearch Service vector search features in the OpenSearch Service documentation.
- Configure ML Connectors for Amazon Bedrock using the ML Commons plugin guide.
- Automate with Terraform using the contributed resources in the terraform-provider-opensearch repository.
The combination of Amazon OpenSearch Service, Amazon Bedrock, and infrastructure as code practices provides a foundation for building intelligent, context-aware AI agents that deliver business value.