Post Syndicated from Donnie Prakoso original https://aws.amazon.com/blogs/aws/new-fine-grained-visual-embedding-powered-by-amazon-quicksight/
Today, we are announcing a new feature, Fine-Grained Visual Embedding Powered by Amazon QuickSight. With this feature, individual visualizations from Amazon QuickSight dashboards can now be embedded in high-traffic webpages and applications. Additionally, this feature enables you to provide rich insights for your end-users where they need them the most, without server or software setup or infrastructure management.
This is a quick preview of this new feature:

Quick Preview: Fine-Grained Visual Embedding Powered by Amazon QuickSight
New Feature: Fine-Grained Visual Embedding
Amazon QuickSight is a cloud-based embeddable and ML-powered business intelligence (BI) service that delivers interactive data visualizations, analysis, and reporting to enable data-driven decision-making within the organization and with the end user, without servers to manage.
Amazon QuickSight supports embedded analytics, a feature that enables you to incorporate branded analytics into internal portals or public sites. Customers can easily embed interactive dashboards, natural language querying (NLQ), or the complete BI-authoring experience seamlessly in their applications. This provides convenience for your end users to simplify the process of data-informed decisions.
Our customers want to be able to embed visuals from various dashboards into their applications and websites in order to bring forth deeply integrated data-driven experiences to enhance end user experiences. Previously, customers needed to build, scale, and maintain generation layer and charting libraries to embed individual visualizations.
With Fine-Grained Visual Embedding Powered by Amazon QuickSight, developers and ISVs now have the ability to embed any visuals from dashboards into their applications using APIs. As for enterprises, they can embed visuals into their internal sites using 1-Click Embedding. For end-users, Fine-Grained Visual Embedding provides a seamless and integrated experience to access a variety of key data visuals to get insights.
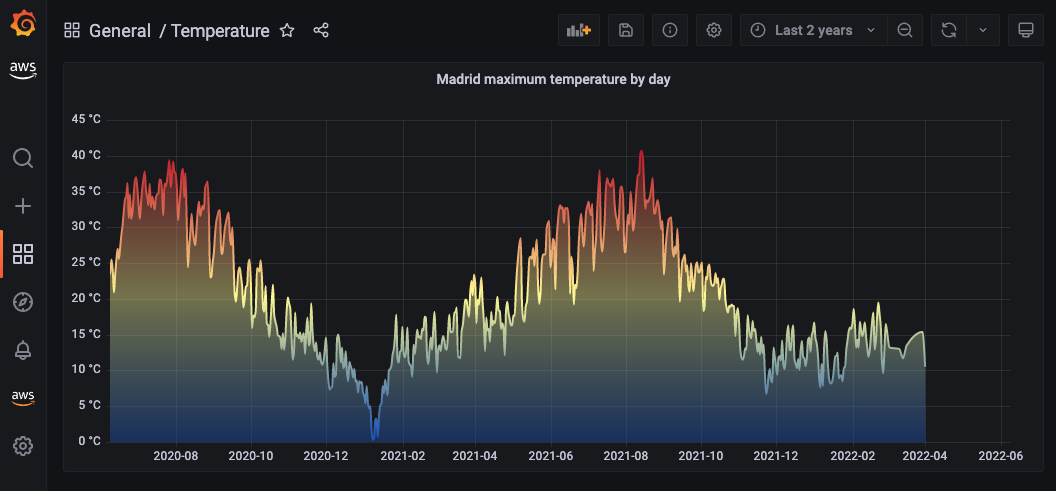
Here’s an example view where we can embed a visual using this feature in a sample web application page:

Sample Web App with a Visual
The embedded visuals are automatically updated when the source data changes or when the visual is updated. Embedded visuals scale automatically without the need to manage servers from your end and are optimized for high performance on high-traffic pages.
Get Started with Fine-Grained Visual Embedding
There are two ways to use Fine-Grained Visual Embedding, with 1-Click Embedding or using QuickSight APIs to generate the embed URL. The 1-Click Embedding feature makes it easy for nontechnical users to generate embed code that can be inserted directly into internal portals or public sites. Using APIs, ISVs and developers can embed rich visuals in their applications. Furthermore, with row-level security, data access is secured enabling users to access only their data.
To start using this feature, let’s turn to the Amazon QuickSight dashboard. Here, I already have a dashboard using a dataset that you can follow from the Create an Amazon QuickSight dashboard using sample data documentation.

Amazon QuickSight Dashboard Using Sample Data
Using 1-Click Embedding to Generate Embed Code
Amazon QuickSight supports 1-Click Embedding—a feature that allows you to get the embed code without any development efforts. There are two types of 1-Click Embedding: 1) 1-Click Enterprise Embedding and 2) 1-Click Public Embedding. With enterprise embedding, it allows you to enable access to the dashboard with registered users in your account. In public embedding, you can enable access to the dashboards for anyone.
To get the embed code via 1-Click Embedding, you can select the visual you want to embed, then select Menu Options and choose Embed visual.

Select Embed visual from Menu Options
Once you select Embed visual, you will get a new menu on the right side, which contains the details of the visual you selected.

Copy the Embed code
The Embed code section contains iframe code that you can insert into your application, portal, or website. Domains hosting these embedded visuals must be on an allow list, which you can learn more about on the Allow listing static domains page. This is a sample display of how the embed code is rendered:

Sample Display of Fine-Grained Visual Embedding Powered by Amazon QuickSight
When there is a change in the visual source within Amazon QuickSight, it will also be reflected within the web app or app where you embed your visuals. In addition, embedded visuals from QuickSight will automatically scale as traffic on the website grows.
From a customer’s perspective, 1-Click Embedding will help customers provide key data visuals from various dashboards in Amazon QuickSight for end users anywhere on their websites without requiring technical skills.
Programmatically Generate Embed URL
In addition to the 1-Click Embedding, you can also perform visual embedding through the API. To perform visual embedding through the API, you can use AWS CLI or SDK to call the API GenerateEmbedUrlForAnonymousUser or GenerateEmbedUrlForRegisteredUser.
You can use the GenerateEmbedUrlForAnonymousUser API to embed visuals in your applications for your users without provisioning them in Amazon QuickSight.
You can also use GenerateEmbedUrlForRegisteredUser API to embed visuals in your application for your users that are provisioned in Amazon QuickSight.
The API works by passing the ExperienceConfiguration parameter in DashboardVisual with the properties below:
{
'DashboardId':'<DASHBOARD_ID>',
'SheetId':'<SHEET_ID>',
'VisualId':'<VISUAL_ID>'
}
Then, to get the IDs for Dashboard, Sheet, and Visual, you can find the value of these properties under IDs for Developers menu section for the visual you selected.

IDs for Developers
Using CLI to Generate Embed URL
After collecting all the required IDs, we can pass them as parameters. Here’s an example API command to generate an embed URL:
aws quicksight generate-embed-url-for-anonymous-user \
--aws-account-id <ACCOUNT_ID> \
--session-lifetime-in-minutes 15 \
--authorized-resource-arns “<DASHBOARD_ARN>”
--namespace default
--experience-configuration '{"DashboardVisual": \
{
"InitialDashboardVisualId": \
{
"DashboardId”:”<DASHBOARD_ID>”, \
"SheetId”:”<SHEET_ID>”, \
"VisualId”:”<VISUAL_ID” \
}
}}'
If the request is successful, you will get the following response. You can then use the EmbedUrl property within your web or application.
{
"Status": 200,
"EmbedUrl": “<EMBED_URL>”,
"RequestId": “<REQUEST_ID>”,
"AnonymousUserArn": “<ARN>”
}
Using SDK to Generate Embed URL
In addition to the AWS CLI, generating embed URLs can also be done using the AWS SDK. Here’s an example in Python:
response = client.generate_embed_url_for_anonymous_user(
AwsAccountId='123456789012',
SessionLifetimeInMinutes=15,
Namespace='default',
AuthorizedResourceArns=[
'<DASHBOARD_ARN>',
],
ExperienceConfiguration={
'DashboardVisual': {
'InitialDashboardVisualId': {
'DashboardId':'<DASHBOARD_ID>',
'SheetId':'<SHEET_ID>',
'VisualId':'<VISUAL_ID>'
}
}
},
AllowedDomains=[
'https://YOUR-DOMAIN.com',
]
)
With API, you have the flexibility to configure allowed domains at runtime. From the example above, you can pass your domains in AllowedDomains property.
When the request is successful, the API will return a successful response, along with a URL from Visual Embedding that can be inserted into external web apps. Example response as below:
{
"Status": 200,
"EmbedUrl":"<EMBED_URL>",
"RequestId": "<REQUEST_ID>”
}
Using the API approach gives developers the flexibility to programmatically generate embed URLs. Developers can specify the access for visuals for nonregistered and registered users in Amazon QuickSight.
Demo
To see Fine-Grained Visual Embedding Powered by Amazon QuickSight in action, have a look at this demo:
Pricing and Availability
You can use this new feature, Fine-Grained Visual Embedding in Amazon QuickSight Enterprise Edition, in all supported Regions. For more detailed information, please visit the documentation page.
Happy building,
— Donnie






 Откакто се роди вторият ми син, ремонтирам вилата. Ще рече 11 години вече. Строена е когато аз съм се родил, в най-голения недоимък на материали.
Откакто се роди вторият ми син, ремонтирам вилата. Ще рече 11 години вече. Строена е когато аз съм се родил, в най-голения недоимък на материали.