Post Syndicated from Mohammad Sabeel original https://aws.amazon.com/blogs/big-data/build-an-analytics-pipeline-that-is-resilient-to-avro-schema-changes-using-amazon-athena/
As technology progresses, the Internet of Things (IoT) expands to encompass more and more things. As a result, organizations collect vast amounts of data from diverse sensor devices monitoring everything from industrial equipment to smart buildings. These sensor devices frequently undergo firmware updates, software modifications, or configuration changes that introduce new monitoring capabilities or retire obsolete metrics. As a result, the data structure (schema) of the information transmitted by these devices evolves continuously.
Organizations commonly choose Apache Avro as their data serialization format for IoT data due to its compact binary format, built-in schema evolution support, and compatibility with big data processing frameworks. This becomes crucial when sensor manufacturers release updates that add new metrics or deprecate old ones, allowing for seamless data processing. For example, when a sensor manufacturer releases a firmware update that adds new temperature precision metrics or deprecates legacy vibration measurements, Avro’s schema evolution capabilities allow for seamless handling of these changes without breaking existing data processing pipelines.
However, managing schema evolution at scale presents significant challenges. For example, organizations need to store and process data from thousands of sensors and update their schemas independently, handle schema changes occurring as frequently as every hour due to rolling device updates, maintain historical data compatibility while accommodating new schema versions, query data across multiple time periods with different schemas for temporal analysis, and ensure minimal query failures due to schema mismatches.
To address this challenge, this post demonstrates how to build such a solution by combining Amazon Simple Storage Service (Amazon S3) for data storage, AWS Glue Data Catalog for schema management, and Amazon Athena for one-time querying. We’ll focus specifically on handling Avro-formatted data in partitioned S3 buckets, where schemas can change frequently while providing consistent query capabilities across all data regardless of schema versions.
This solution is specifically designed for Hive-based tables, such as those in the AWS Glue Data Catalog, and is not applicable for Iceberg tables. By implementing this approach, organizations can build a highly adaptive and resilient analytics pipeline capable of handling extremely frequent Avro schema changes in partitioned S3 environments.
Solution overview
In this post as an example, we’re simulating a real-world IoT data pipeline with the following requirements:
- IoT devices continuously upload sensor data in Avro format to an S3 bucket, simulating real-time IoT data ingestion
- The schema change happens frequently over time
- Data will be partitioned hourly to reflect typical IoT data ingestion patterns
- Data needs to be queryable using the most recent schema version through Amazon Athena.
To achieve these requirements, we demonstrate the solution using automated schema detection. We use AWS Command Line Interface (AWS CLI) and AWS SDK for Python (Boto3) scripts to simulate an automated mechanism that continually monitors the S3 bucket for new data, detects schema changes in incoming Avro files, and triggers necessary updates to the AWS Glue Data Catalog.
For schema evolution handling, our solution will demonstrate how to create and update table definitions in the AWS Glue Data Catalog, incorporate Avro schema literals to handle schema changes, and use the Athena partition projection for efficient querying across schema versions. The data steward or admin needs to know when and how the schema is updated so that the admin can manually change the columns in the UpdateTable API call. For validation and querying, we use Amazon Athena queries to verify table definitions and partition details and demonstrate successful querying of data across different schema versions. By simulating these components, our solution addresses the key requirements outlined in the introduction:
- Handling frequent schema changes (as often as hourly)
- Managing data from thousands of sensors updating independently
- Maintaining historical data compatibility while accommodating new schemas
- Enabling querying across multiple time periods with different schemas
- Minimizing query failures due to schema mismatches
Although in a production environment this would be integrated into a sophisticated IoT data processing application, our simulation using AWS CLI and Boto3 scripts effectively demonstrates the principles and techniques for managing schema evolution in large-scale IoT deployments.
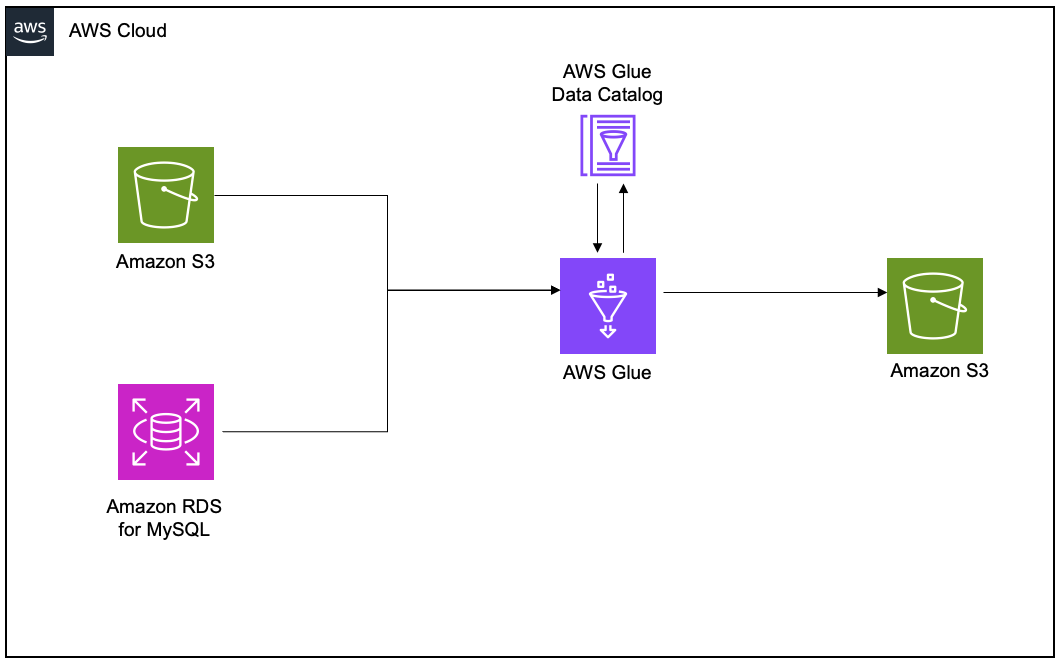
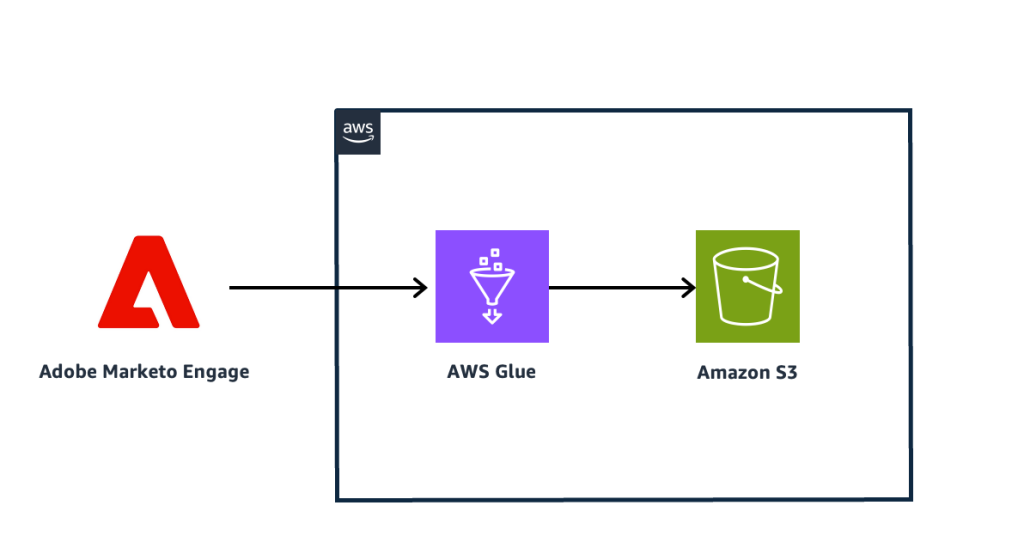
The following diagram illustrates the solution architecture.

Prerequisites:
To perform the solution, you need to have the following prerequisites:
Create the base table
In this section, we simulate the initial setup of a data pipeline for IoT sensor data. This step is crucial because it establishes the foundation for our schema evolution demonstration. This initial table serves as the starting point from which our schema will evolve. It allows us to demonstrate how to handle schema changes over time. In this scenario, the base table contains three key fields: customerID (bigint), sentiment (a struct containing customerrating), and dt (string) as a partition column. And Avro schema literal (‘avro.schema.literal’)along with other configurations. Follow these steps:
- Create a new file named
`CreateTableAPI.py` with the following content. Replace 'Location': 's3://amzn-s3-demo-bucket/' with your S3 bucket details and <AWS Account ID> with your AWS account ID:
import boto3
import time
if __name__ == '__main__':
database_name = " blogpostdatabase"
table_name = "blogpost_table_test"
catalog_id = ''
client = boto3.client('glue')
response = client.create_table(
CatalogId=catalog_id,
DatabaseName=database_name,
TableInput={
'Name': table_name,
'Description': 'sampletable',
'Owner': 'root',
'TableType': 'EXTERNAL_TABLE',
'LastAccessTime': int(time.time()),
'LastAnalyzedTime': int(time.time()),
'Retention': 0,
'Parameters' : {
'avro.schema.literal': '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 }] } ], "default" : 0 }]}'
},
'StorageDescriptor': {
'Columns': [
{
'Name': 'customerID',
'Type': 'bigint',
'Comment': 'from deserializer'
},
{
'Name': 'sentiment',
'Type': 'struct<customerrating:bigint>',
'Comment': 'from deserializer'
}
],
'Location': 's3:///',
'InputFormat': 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat',
'OutputFormat': 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat',
'SerdeInfo': {
'SerializationLibrary': 'org.apache.hadoop.hive.serde2.avro.AvroSerDe',
'Parameters': {
'avro.schema.literal': '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 } ] } ], "default" : 0 }]}'
}
}
},
'PartitionKeys': [
{
'Name': 'dt',
'Type': 'string'
}
]
}
)
print(response)
- Run the script using the command:
python3 CreateTableAPI.py
The schema literal serves as a form of metadata, providing a clear description of your data structure. In Amazon Athena, Avro table schema Serializer/Deserializer (SerDe) properties are essential for schema is compatible with the data stored in files, facilitating accurate translation for query engines. These properties enable the precise interpretation of Avro-formatted data, allowing query engines to correctly read and process the information during execution.
The Avro schema literal provides a detailed description of the data structure at the partition level. It defines the fields, their data types, and any nested structures within the Avro data. Amazon Athena uses this schema to correctly interpret the Avro data stored in Amazon S3. It makes sure that each field in the Avro file is mapped to the correct column in the Athena table.
The schema information helps Athena optimize query run by understanding the data structure in advance. It can make informed decisions about how to process and retrieve data efficiently. When the Avro schema changes (for example, when new fields are added), updating the schema literal allows Athena to recognize and work with the new structure. This is crucial for maintaining query compatibility as your data evolves over time. The schema literal provides explicit type information, which is essential for Avro’s type system. This provides accurate data type conversion between Avro and Athena SQL types.
For complex Avro schemas with nested structures, the schema literal informs Athena how to navigate and query these nested elements. The Avro schema can specify default values for fields, which Athena can use when querying data where certain fields might be missing. Athena can use the schema to perform compatibility checks between the table definition and the actual data, helping to identify potential issues. In the SerDe properties, the schema literal tells the Avro SerDe how to deserialize the data when reading it from Amazon S3.
It’s crucial for the SerDe to correctly interpret the binary Avro format into a form Athena can query. The detailed schema information aids in query planning, allowing Athena to make informed decisions about how to execute queries efficiently. The Avro schema literal specified in the table’s SerDe properties provides Athena with the exact field mappings, data types, and physical structure of the Avro file. This enables Athena to perform column pruning by calculating precise byte offsets for required fields, reading only those specific portions of the Avro file from S3 rather than retrieving the entire record.
Parameters' : {
'avro.schema.literal': '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 }] } ], "default" : 0 }]}'
},
- After creating the table, verify its structure using the
SHOW CREATE TABLE command in Athena:
CREATE EXTERNAL TABLE `blogpost_table_test`(
`customerid` bigint COMMENT 'from deserializer',
`sentiment` struct<customerrating:bigint> COMMENT 'from deserializer')
PARTITIONED BY (
`dt` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
WITH SERDEPROPERTIES (
'avro.schema.literal'='{\"type\" : \"record\", \"name\" : \"customerdata\", \"namespace\" : \"com.data.test.avro\", \"fields\" : [{ \"name\" : \"customerID\", \"type\" : \"long\", \"default\" : -1 },{ \"name\" : \"sentiment\", \"type\" : [ \"null\", { \"type\" : \"record\", \"name\" : \"sentiment\", \"doc\" : \"***** CoreETL ******\", \"fields\" : [ { \"name\" : \"customerrating\", \"type\" : \"long\", \"default\" : 0 } ] } ], \"default\" : 0 }]}')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/'
TBLPROPERTIES (
'avro.schema.literal'='{\"type\" : \"record\", \"name\" : \"customerdata\", \"namespace\" : \"com.data.test.avro\", \"fields\" : [{ \"name\" : \"customerID\", \"type\" : \"long\", \"default\" : -1 },{ \"name\" : \"sentiment\", \"type\" : [ \"null\", { \"type\" : \"record\", \"name\" : \"sentiment\", \"doc\" : \"***** CoreETL ******\", \"fields\" : [ { \"name\" : \"customerrating\", \"type\" : \"long\", \"default\" : 0 } ] } ], \"default\" : 0 }]}')
Note that the table is created with the initial schema as described below:
[
{
"Name": "customerid",
"Type": "bigint",
"Comment": "from deserializer"
},
{
"Name": "sentiment",
"Type": "struct<confirmedImpressions:bigint>",
"Comment": "from deserializer"
},
{
"Name": "dt",
"Type": "string",
"PartitionKey": "Partition (0)"
}
]
With the table structure in place, you can load the first set of IoT sensor data and establish the initial partition. This step is crucial for setting up the data pipeline that will handle incoming sensor data.
- Download the example sensor data from the following S3 bucket
s3://aws-blogs-artifacts-public/artifacts/BDB-4745
Download initial schema from the first partition
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-4745/dt=2024-03-21/initial_schema_sample1.avro
Download second schema from the second partition
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-4745/dt=2024-03-22/second_schema_sample2.avro
Download third schema from the third partition
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-4745/dt=2024-03-23/third_scehama_sample3avro
- Upload the Avro-formatted sensor data to your partitioned S3 location. This represents your first day of sensor readings, organized in the date-based partition structure. Replace the bucket name
amzn-s3-demo-bucket with your S3 bucket name and add a partitioned folder for the dt field.
s3://amzn-s3-demo-bucket/dt=2024-03-21/
- Register this partition in the AWS Glue Data Catalog to make it discoverable. This tells AWS Glue where to find your sensor data for this specific date:
ALTER TABLE iot_sensor_data ADD PARTITION (dt='2024-03-21');
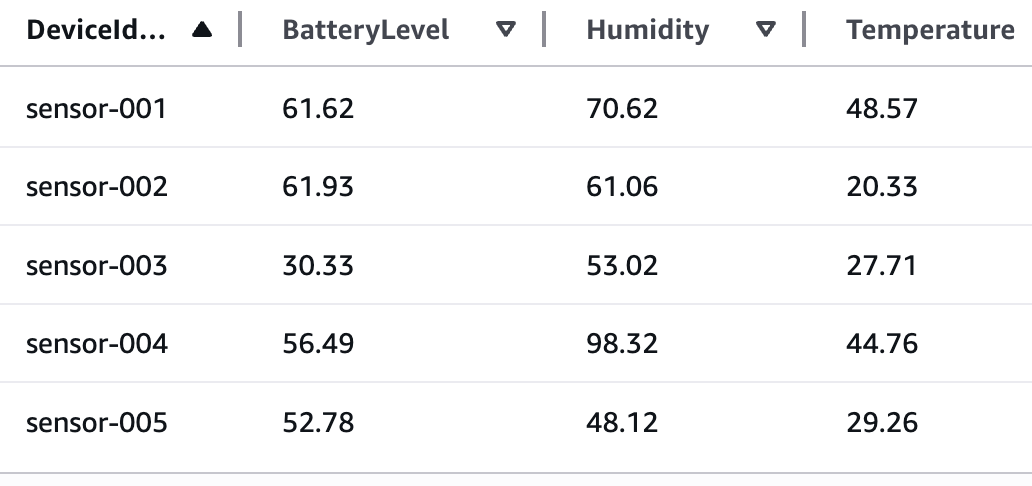
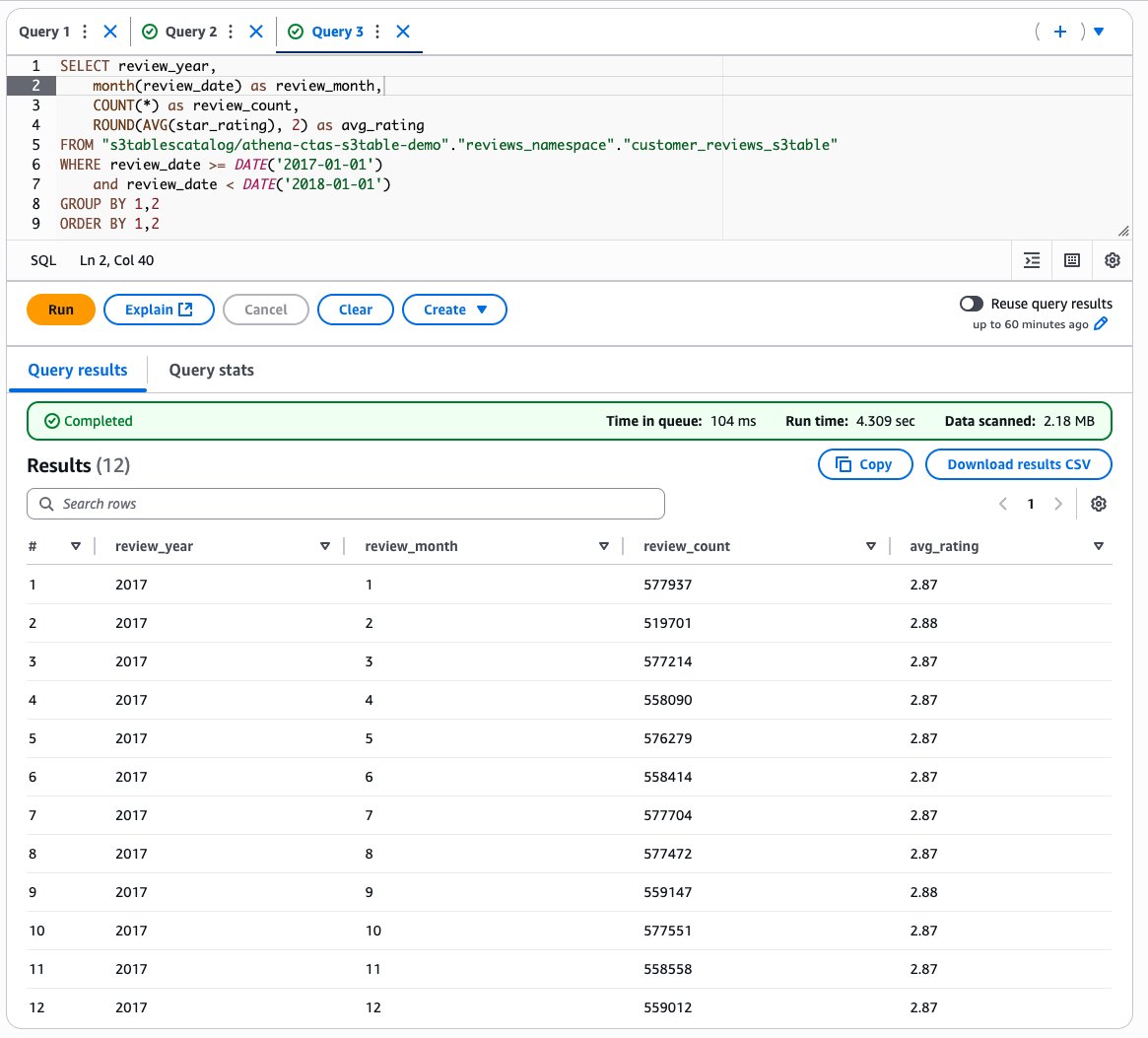
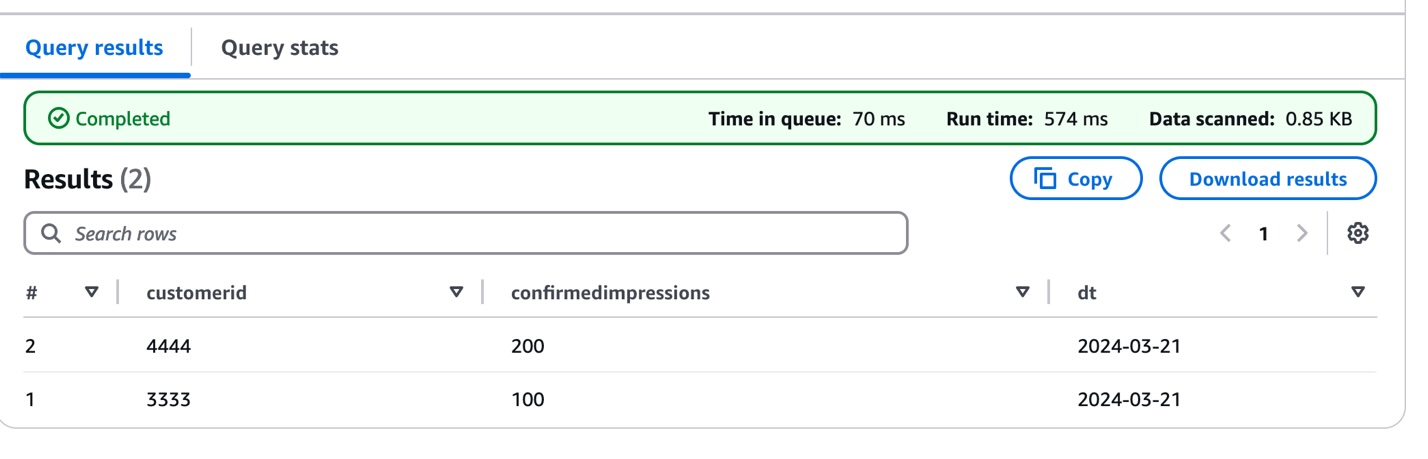
- Validate your sensor data ingestion by querying the newly loaded partition. This query helps verify that your sensor readings are correctly loaded and accessible:
SELECT * FROM "blogpostdatabase "."iot_sensor_data" WHERE dt='2024-03-21';
The following screenshot shows the query results.

This initial data load establishes the foundation for the IoT data pipeline, which means you can begin tracking sensor measurements while preparing for future schema evolution as sensor capabilities expand or change.
Now, we demonstrate how the IoT data pipeline handles evolving sensor capabilities by introducing a schema change in the second data batch. As sensors receive firmware updates or new monitoring features, their data structure needs to adapt accordingly. To show this evolution, we add data from sensors that now include visibility measurements:
- Examine the evolved schema structure that accommodates the new sensor capability:
{
"fields": [
{
"Name": "customerid",
"Type": "bigint",
"Comment": "from deserializer"
},
{
"Name": "sentiment",
"Type": "struct<confirmedImpressions:bigint,visibility:bigint>",
"Comment": "from deserializer"
},
{
"Name": "dt",
"Type": "string",
"PartitionKey": "Partition (0)"
}
]
}
Note the addition of the visibility field within the sentiment structure, representing the sensor’s enhanced monitoring capability.
- Upload this enhanced sensor data to a new date partition:
s3://amzn-s3-demo-bucket/dt=2024-03-22/
- Verify data consistency across both the original and enhanced sensor readings:
SELECT * FROM "blogpostdatabase"."blogpost_table_test" LIMIT 10;
This demonstrates how the pipeline can handle sensor upgrades while maintaining compatibility with historical data. In the next section, we explore how to update the table definition to properly manage this schema evolution, providing seamless querying across all sensor data regardless of when the sensors were upgraded. This approach is particularly valuable in IoT environments where sensor capabilities frequently evolve, which means you can maintain historical data while accommodating new monitoring features.
Update the AWS Glue table
To accommodate evolving sensor capabilities, you need to update the AWS Glue table schema. Although traditional methods such as MSCK REPAIR TABLE or ALTER TABLE ADD PARTITION work for small datasets for updating partition information, you can use an alternate method to handle tables with more than 100K partitions efficiently.
We use the Athena partition projection, which eliminates the need to process extensive partition metadata, which can be time-consuming for large datasets. Instead, it dynamically infers partition existence and location, allowing for more efficient data management. This method also speeds up query planning by quickly identifying relevant partitions, leading to faster query execution. Additionally, it reduces the number of API calls to the metadata store, potentially lowering costs associated with these operations. Perhaps most importantly, this solution maintains performance as the number of partitions grows, prodicing scalability for evolving datasets. These benefits combine to create a more efficient and cost-effective way of handling schema evolution in large-scale data environments.
To update your table schema to handle the new sensor data, follow these steps:
- Copy the following code into the
UpdateTableAPI.py file:
import boto3
client = boto3.client('glue')
db = 'blogpostdatabase'
tb = 'blogpost_table_test'
response = client.get_table(
DatabaseName=db,
Name=tb
)
print(response)
table_input = {
'Description': response['Table'].get('Description', ''),
'Name': response['Table'].get('Name', ''),
'Owner': response['Table'].get('Owner', ''),
'Parameters': response['Table'].get('Parameters', {}),
'PartitionKeys': response['Table'].get('PartitionKeys', []),
'Retention': response['Table'].get('Retention'),
'StorageDescriptor': response['Table'].get('StorageDescriptor', {}),
'TableType': response['Table'].get('TableType', ''),
'ViewExpandedText': response['Table'].get('ViewExpandedText', ''),
'ViewOriginalText': response['Table'].get('ViewOriginalText', '')
}
for col in table_input['StorageDescriptor']['Columns']:
if col['Name'] == 'sentiment':
col['Type'] = 'struct<confirmedImpressions:bigint,visibility:bigint>'
table_input['StorageDescriptor']['SerdeInfo']['Parameters']['avro.schema.literal'] = '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 },{"name":"visibility","type":"long","default":0}] } ], "default" : 0 }]}'
table_input['Parameters']['avro.schema.literal'] = '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 },{"name":"visibility","type":"long","default":0} ] } ], "default" : 0 }]}'
table_input['Parameters']['projection.dt.type'] = 'date'
table_input['Parameters']['projection.dt.format'] = 'yyyy-MM-dd'
table_input['Parameters']['projection.enabled'] = 'true'
table_input['Parameters']['projection.dt.range'] = '2024-03-21,NOW'
response = client.update_table(
DatabaseName=db,
TableInput=table_input
)
This Python script demonstrates how to update an AWS Glue table to accommodate schema evolution and enable partition projection:
- It uses Boto3 to interact with AWS Glue API.
- Retrieves the current table definition from the AWS Glue Data Catalog.
- Updates the
'sentiment' column structure to include new fields.
- Modifies the Avro schema literal to reflect the updated structure.
- Adds partition projection parameters for the partition column
dt
table_input['Parameters']['projection.dt.type'] = 'date'
table_input['Parameters']['projection.dt.format'] = 'yyyy-MM-dd'
table_input['Parameters']['projection.enabled'] = 'true'
table_input['Parameters']['projection.dt.range'] = '2024-03-21,NOW'
- Sets projection type to
'date'
- Defines date format as
'yyyy-MM-dd'
- Enables partition projection
- Sets date range from
'2024-03-21' to 'NOW'
projection.date.type='date' --> Data type of the partition column
projection.date.format='yyyy-MM-dd' -> Data format of the partition column
projection.enabled='true' -> Enable the partition projection
projection.date.range='2024-04-26,NOW'. -> The range of the partition column
- Run the script using the following command:
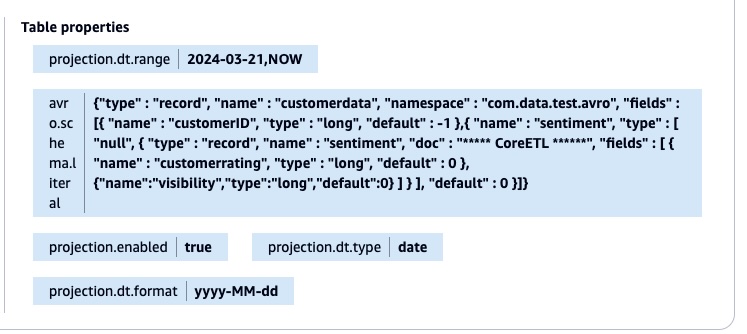
python3 UpdateTableAPI.py
The script applies all changes back to the AWS Glue table using the UpdateTable API call. The following screenshot shows the table property with the new Avro schema literal and the partition projection.

After the table property is updated, you don’t need to add the partitions manually using the MSCK REPAIR TABLE or ALTER TABLE command. You can validate the result by running the query in the Athena console.
SELECT * FROM "blogpostdatabase"." blogpost_table_test " limit 10;
The following screenshot shows the query results.

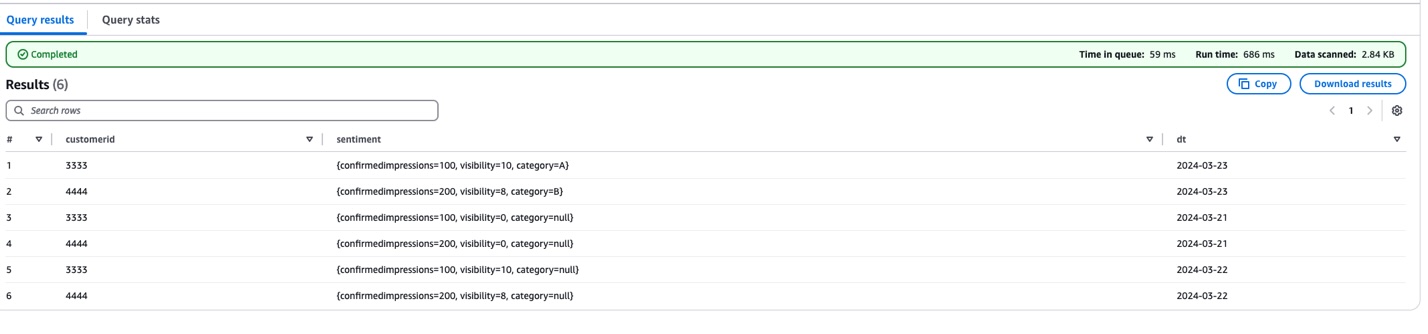
This schema evolution strategy efficiently handles new data fields across different time periods. Consider the 'visibility' field introduced on 2024-03-22. For data from 2024-03-21, where this field doesn’t exist, the solution automatically returns a default value of 0. This approach makes the query consistent across all partitions, regardless of their schema version.
Here’s the Avro schema configuration that enables this flexibility:
{
"type": "record",
"name": "customerdata",
"fields": [
{"name": "customerID", "type": "long", "default": -1},
{"name": "sentiment", "type": ["null", {
"type": "record",
"name": "sentiment",
"fields": [
{"name": "customerrating", "type": "long", "default": 0},
{"name": "visibility", "type": "long", "default": 0}
]
}], "default": null}
]
}
Using this configuration, you can run queries across all partitions without modifications, maintain backward compatibility without data migration, and support gradual schema evolution without breaking existing queries.
Building on the schema evolution example, we now introduce a third enhancement to the sensor data structure. This new iteration adds a text-based classification capability through a 'category' field (string type) to the sentiment structure. This represents a real-world scenario where sensors receive updates that add new classification capabilities, requiring the data pipeline to handle both numeric measurements and textual categorizations.
The following is the enhanced schema structure:
{
"fields": [
{
"Name": "customerid",
"Type": "bigint"
},
{
"Name": "sentiment",
"Type": "struct<confirmedImpressions:bigint,visibility:bigint,category:string>"
},
{
"Name": "dt",
"Type": "string"
}
]
}
This evolution demonstrates how the solution flexibly accommodates different data types as sensor capabilities expand while maintaining compatibility with historical data.
To implement this latest schema evolution for the new partition (dt=2024-03-23), we update the table definition to include the ‘category’ field. Here’s the modified UpdateTableAPI.py script that handles this change:
- Update the file
UpdateTableAPI.py:
import boto3
client = boto3.client('glue')
db = 'blogpostdatabase'
tb = 'blogpost_table_test'
response = client.get_table(
DatabaseName=db,
Name=tb
)
print(response)
table_input = {
'Description': response['Table'].get('Description', ''),
'Name': response['Table'].get('Name', ''),
'Owner': response['Table'].get('Owner', ''),
'Parameters': response['Table'].get('Parameters', {}),
'PartitionKeys': response['Table'].get('PartitionKeys', []),
'Retention': response['Table'].get('Retention'),
'StorageDescriptor': response['Table'].get('StorageDescriptor', {}),
'TableType': response['Table'].get('TableType', ''),
'ViewExpandedText': response['Table'].get('ViewExpandedText', ''),
'ViewOriginalText': response['Table'].get('ViewOriginalText', '')
}
for col in table_input['StorageDescriptor']['Columns']:
if col['Name'] == 'sentiment':
col['Type'] = 'struct<confirmedImpressions:bigint,visibility:bigint,category:string>'
table_input['StorageDescriptor']['SerdeInfo']['Parameters']['avro.schema.literal'] = '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 },{"name":"visibility","type":"long","default":0},{"name":"category","type":"string","default":"null"} ] } ], "default" : 0 }]}'
table_input['Parameters']['avro.schema.literal'] = '{"type" : "record", "name" : "customerdata", "namespace" : "com.data.test.avro", "fields" : [{ "name" : "customerID", "type" : "long", "default" : -1 },{ "name" : "sentiment", "type" : [ "null", { "type" : "record", "name" : "sentiment", "doc" : "***** CoreETL ******", "fields" : [ { "name" : "customerrating", "type" : "long", "default" : 0 },{"name":"visibility","type":"long","default":0},{"name":"category","type":"string","default":"null"} ] } ], "default" : 0 }]}'
table_input['Parameters']['projection.dt.type'] = 'date'
table_input['Parameters']['projection.dt.format'] = 'yyyy-MM-dd'
table_input['Parameters']['projection.enabled'] = 'true'
table_input['Parameters']['projection.dt.range'] = '2024-03-21,NOW'
response = client.update_table(
DatabaseName=db,
TableInput=table_input
)
- Verify the changes by running the following query:
SELECT * FROM "blogpostdatabase"."blogpost_table_test" LIMIT 10;
The following screenshot shows the query results.

There are three key changes in this update:
- Added
'category' field (string type) to the sentiment structure
- Set default value
"null" for the category field
- Maintained existing partition projection settings
To support that latest sensor data enhancement, we updated the table definition to include a new text-based 'category' field in the sentiment structure. The modified UpdateTableAPI script adds this capability while maintaining the established schema evolution patterns. It achieves this by updating both the AWS Glue table schema and the Avro schema literal, setting a default value of "null" for the category field.
This provides backward compatibility. Older data (before 2024-03-23) shows "null" for the category field, and new data includes actual category values. The script maintains the partition projection settings, enabling efficient querying across all time periods.
You can verify this update by querying the table in Athena, which will now show the complete data structure, including numeric measurements (customerrating, visibility) and text categorization (category) across all partitions. This enhancement demonstrates how the solution can seamlessly incorporate different data types while preserving historical data integrity and query performance.
Cleanup
To avoid incurring future costs, delete your Amazon S3 data if you no longer need it.
Conclusion
By combining Avro’s schema evolution capabilities with the power of AWS Glue APIs, we’ve created a robust framework for managing diverse, evolving datasets. This approach not only simplifies data integration but also enhances the agility and effectiveness of your analytics pipeline, paving the way for more sophisticated predictive and prescriptive analytics.
This solution offers several key advantages. It’s flexible, adapting to changing data structures without disrupting existing analytics processes. It’s scalable, able to handle growing volumes of data and evolving schemas efficiently. You can automate it and reduce the manual overhead in schema management and updates. Finally, because it minimizes data movement and transformation costs, it’s cost-effective.
Related references
About the authors
 Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Support Engineer at Amazon Web Services (AWS) with over 14 years of experience in Information Technology (IT). As a member of the Technical Field Community (TFC) Analytics team, he is a Subject matter expert in Analytics services AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena services. Sabeel provides expert guidance and technical support to enterprise and strategic customers, helping them optimize their data analytics solutions and overcome complex challenges. With deep subject matter expertise he enables organizations to build scalable, efficient, and cost-effective data processing pipelines.
Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Support Engineer at Amazon Web Services (AWS) with over 14 years of experience in Information Technology (IT). As a member of the Technical Field Community (TFC) Analytics team, he is a Subject matter expert in Analytics services AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena services. Sabeel provides expert guidance and technical support to enterprise and strategic customers, helping them optimize their data analytics solutions and overcome complex challenges. With deep subject matter expertise he enables organizations to build scalable, efficient, and cost-effective data processing pipelines.
Indira Balakrishnan Indira Balakrishnan is a Principal Solutions Architect in the Amazon Web Services (AWS) Analytics Specialist Solutions Architect (SA) Team. She helps customers build cloud-based Data and AI/ML solutions to address business challenges. With over 25 years of experience in Information Technology (IT), Indira actively contributes to the AWS Analytics Technical Field community, supporting customers across various Domains and Industries. Indira participates in Women in Engineering and Women at Amazon tech groups to encourage girls to pursue STEM path to enter careers in IT. She also volunteers in early career mentoring circles.









 Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS Analytics services.
Pathik Shah is a Sr. Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big data analytics space since then, helping customers build scalable and robust solutions using AWS Analytics services. Aritra Gupta is a Senior Technical Product Manager on the Amazon S3 team at Amazon Web Services. He helps customers build and scale data lakes. Based in Seattle, he likes to play chess and badminton in his spare time.
Aritra Gupta is a Senior Technical Product Manager on the Amazon S3 team at Amazon Web Services. He helps customers build and scale data lakes. Based in Seattle, he likes to play chess and badminton in his spare time.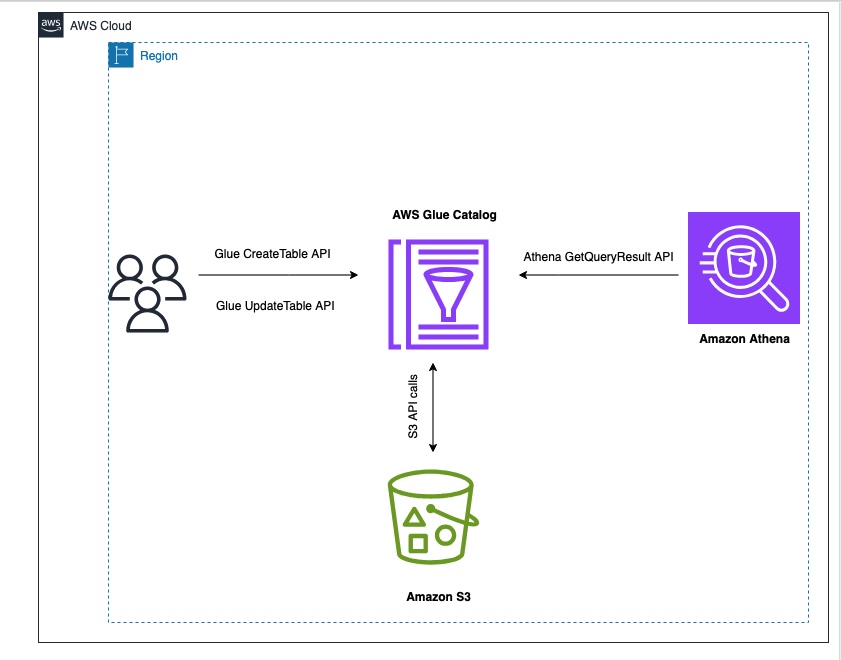

 Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Support Engineer at Amazon Web Services (AWS) with over 14 years of experience in Information Technology (IT). As a member of the Technical Field Community (TFC) Analytics team, he is a Subject matter expert in Analytics services AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena services. Sabeel provides expert guidance and technical support to enterprise and strategic customers, helping them optimize their data analytics solutions and overcome complex challenges. With deep subject matter expertise he enables organizations to build scalable, efficient, and cost-effective data processing pipelines.
Mohammad Sabeel Mohammad Sabeel is a Senior Cloud Support Engineer at Amazon Web Services (AWS) with over 14 years of experience in Information Technology (IT). As a member of the Technical Field Community (TFC) Analytics team, he is a Subject matter expert in Analytics services AWS Glue, Amazon Managed Workflows for Apache Airflow (MWAA), and Amazon Athena services. Sabeel provides expert guidance and technical support to enterprise and strategic customers, helping them optimize their data analytics solutions and overcome complex challenges. With deep subject matter expertise he enables organizations to build scalable, efficient, and cost-effective data processing pipelines. Indira Balakrishnan Indira Balakrishnan is a Principal Solutions Architect in the Amazon Web Services (AWS) Analytics Specialist Solutions Architect (SA) Team. She helps customers build cloud-based Data and AI/ML solutions to address business challenges. With over 25 years of experience in Information Technology (IT), Indira actively contributes to the AWS Analytics Technical Field community, supporting customers across various Domains and Industries. Indira participates in Women in Engineering and Women at Amazon tech groups to encourage girls to pursue STEM path to enter careers in IT. She also volunteers in early career mentoring circles.
Indira Balakrishnan Indira Balakrishnan is a Principal Solutions Architect in the Amazon Web Services (AWS) Analytics Specialist Solutions Architect (SA) Team. She helps customers build cloud-based Data and AI/ML solutions to address business challenges. With over 25 years of experience in Information Technology (IT), Indira actively contributes to the AWS Analytics Technical Field community, supporting customers across various Domains and Industries. Indira participates in Women in Engineering and Women at Amazon tech groups to encourage girls to pursue STEM path to enter careers in IT. She also volunteers in early career mentoring circles.




 Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions. Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing. Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance. Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines. Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.



 Guy Bachar is a Sr. Solutions Architect at AWS. He specializes in assisting capital markets and FinTech customers with their cloud transformation journeys. His expertise encompasses identity management, security, and unified communication.
Guy Bachar is a Sr. Solutions Architect at AWS. He specializes in assisting capital markets and FinTech customers with their cloud transformation journeys. His expertise encompasses identity management, security, and unified communication. Sayan Chakraborty is a Sr. Solutions Architect at AWS. He helps large enterprises build secure, scalable, and performant solutions on AWS. With a background in enterprise and technology architecture, he has experience delivering large-scale digital transformation programs across a wide range of industry verticals.
Sayan Chakraborty is a Sr. Solutions Architect at AWS. He helps large enterprises build secure, scalable, and performant solutions on AWS. With a background in enterprise and technology architecture, he has experience delivering large-scale digital transformation programs across a wide range of industry verticals. Darshit Thakkar is a Technical Product Manager at AWS and works out of Boston, Massachusetts. He works closely with customers to understand how they use data, and drives product innovations that make data more actionable at scale.
Darshit Thakkar is a Technical Product Manager at AWS and works out of Boston, Massachusetts. He works closely with customers to understand how they use data, and drives product innovations that make data more actionable at scale.





 Shubham Purwar is an AWS Analytics Specialist Solution Architect. He helps organizations unlock the full potential of their data by designing and implementing scalable, secure, and high-performance analytics solutions on the AWS platform. With deep expertise in AWS analytics services, he collaborates with customers to uncover their distinct business requirements and create customized solutions that deliver actionable insights and drive business growth. In his free time, Shubham loves to spend time with his family and travel around the world.
Shubham Purwar is an AWS Analytics Specialist Solution Architect. He helps organizations unlock the full potential of their data by designing and implementing scalable, secure, and high-performance analytics solutions on the AWS platform. With deep expertise in AWS analytics services, he collaborates with customers to uncover their distinct business requirements and create customized solutions that deliver actionable insights and drive business growth. In his free time, Shubham loves to spend time with his family and travel around the world. Nitin Kumar is a Cloud Engineer (ETL) at AWS, specialized in AWS Glue. With a decade of experience, he excels in aiding customers with their big data workloads, focusing on data processing and analytics. He is committed to helping customers overcome ETL challenges and develop scalable data processing and analytics pipelines on AWS. In his free time, he likes to watch movies and spend time with his family.
Nitin Kumar is a Cloud Engineer (ETL) at AWS, specialized in AWS Glue. With a decade of experience, he excels in aiding customers with their big data workloads, focusing on data processing and analytics. He is committed to helping customers overcome ETL challenges and develop scalable data processing and analytics pipelines on AWS. In his free time, he likes to watch movies and spend time with his family. Prashanthi Chinthala is a Cloud Engineer (DIST) at AWS. She helps customers overcome EMR challenges and develop scalable data processing and analytics pipelines on AWS.
Prashanthi Chinthala is a Cloud Engineer (DIST) at AWS. She helps customers overcome EMR challenges and develop scalable data processing and analytics pipelines on AWS.

























































 Lead FinOps Engineer at BMW Group and has a strong background in data engineering, AI, and FinOps. He focuses on driving cloud efficiency initiatives and fostering a cost-aware culture within the company to leverage the cloud sustainably.
Lead FinOps Engineer at BMW Group and has a strong background in data engineering, AI, and FinOps. He focuses on driving cloud efficiency initiatives and fostering a cost-aware culture within the company to leverage the cloud sustainably. Selman Ay is a Data Architect specializing in end-to-end data solutions, architecture, and AI on AWS. Outside of work, he enjoys playing tennis and engaging outdoor activities.
Selman Ay is a Data Architect specializing in end-to-end data solutions, architecture, and AI on AWS. Outside of work, he enjoys playing tennis and engaging outdoor activities. Cizer Pereira is a Senior DevOps Architect at AWS Professional Services. He works closely with AWS customers to accelerate their journey to the cloud. He has a deep passion for cloud-based and DevOps solutions, and in his free time, he also enjoys contributing to open source projects.
Cizer Pereira is a Senior DevOps Architect at AWS Professional Services. He works closely with AWS customers to accelerate their journey to the cloud. He has a deep passion for cloud-based and DevOps solutions, and in his free time, he also enjoys contributing to open source projects.















 Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.




















 Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She collaborates with the service team to enhance product features, works with AWS customers and partners to architect lake house solutions, and establishes best practices.
Aarthi Srinivasan is a Senior Big Data Architect with AWS Lake Formation. She collaborates with the service team to enhance product features, works with AWS customers and partners to architect lake house solutions, and establishes best practices. Parul Saxena is a Senior Big Data Specialist Solutions Architect in AWS. She helps customers and partners build highly optimized, scalable, and secure solutions. She specializes in Amazon EMR, Amazon Athena, and AWS Lake Formation, providing architectural guidance for complex big data workloads and assisting organizations in modernizing their architectures and migrating analytics workloads to AWS.
Parul Saxena is a Senior Big Data Specialist Solutions Architect in AWS. She helps customers and partners build highly optimized, scalable, and secure solutions. She specializes in Amazon EMR, Amazon Athena, and AWS Lake Formation, providing architectural guidance for complex big data workloads and assisting organizations in modernizing their architectures and migrating analytics workloads to AWS.










 Charlie can now further update the SQL query and use it to power QuickSight dashboards that can be shared with Sales team members.
Charlie can now further update the SQL query and use it to power QuickSight dashboards that can be shared with Sales team members.
 Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect on the AWS Lake Formation team. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.





 Kenny Rajan is a Principal Enterprise Architect at AWS specializing in integrating generative AI with enterprise systems like SAP and Adobe. He helps organizations modernize their digital experience platforms and supply chain and back-end systems through data and AI-powered cloud solutions. Outside of work, he contributes to technology education and charitable initiatives.
Kenny Rajan is a Principal Enterprise Architect at AWS specializing in integrating generative AI with enterprise systems like SAP and Adobe. He helps organizations modernize their digital experience platforms and supply chain and back-end systems through data and AI-powered cloud solutions. Outside of work, he contributes to technology education and charitable initiatives. Rafał Pawłaszek is a Senior Cloud Application Architect at AWS. Rafał supports customer transformation to the cloud and customer enablement in the cloud. Outside of work, he is interested in astronomy, astrophysics, and psychology, and loves spending time with family.
Rafał Pawłaszek is a Senior Cloud Application Architect at AWS. Rafał supports customer transformation to the cloud and customer enablement in the cloud. Outside of work, he is interested in astronomy, astrophysics, and psychology, and loves spending time with family. Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems using new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket.
Basheer Sheriff is a Senior Solutions Architect at AWS. He loves to help customers solve interesting problems using new technology. He is based in Melbourne, Australia, and likes to play sports such as football and cricket. Kamen Sharlandjiev is a Sr. Big Data Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!










 Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends.
Chiho Sugimoto is a Cloud Support Engineer on the AWS Big Data Support team. She is passionate about helping customers build data lakes using ETL workloads. She loves planetary science and enjoys studying the asteroid Ryugu on weekends. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his new road bike. Shubham Agrawal is a Software Development Engineer on the AWS Glue team. He has expertise in designing scalable, high-performance systems for handling large-scale, real-time data processing. Driven by a passion for solving complex engineering problems, he focuses on building seamless integration solutions that enable organizations to maximize the value of their data.
Shubham Agrawal is a Software Development Engineer on the AWS Glue team. He has expertise in designing scalable, high-performance systems for handling large-scale, real-time data processing. Driven by a passion for solving complex engineering problems, he focuses on building seamless integration solutions that enable organizations to maximize the value of their data. Joju Eruppanal is a Software Development Manager on the AWS Glue team. He strives to delight customers by helping his team build software. He loves exploring different cultures and cuisines.
Joju Eruppanal is a Software Development Manager on the AWS Glue team. He strives to delight customers by helping his team build software. He loves exploring different cultures and cuisines. Julie Zhao is a Senior Product Manager at AWS Glue. She joined AWS in 2021 and brings three years of startup experience leading products in IoT data platforms. Prior to startups, she spent over 10 years in networking with Cisco and Juniper across engineering and product. She is passionate about building products to solve customer problems.
Julie Zhao is a Senior Product Manager at AWS Glue. She joined AWS in 2021 and brings three years of startup experience leading products in IoT data platforms. Prior to startups, she spent over 10 years in networking with Cisco and Juniper across engineering and product. She is passionate about building products to solve customer problems.














 Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions.
Xu Feng is a Senior Industry Solution Architect at AWS, responsible for designing, building, and promoting industry solutions for the Media & Entertainment and Advertising sectors, such as intelligent customer service and business intelligence. With 20 years of software industry experience, currently focused on researching and implementing generative AI and AI-powered data solutions. Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.
Xu Da is a Amazon Web Services (AWS) Partner Solutions Architect based out of Shanghai, China. He has more than 25 years of experience in IT industry, software development and solution architecture. He is passionate about collaborative learning, knowledge sharing, and guiding community in their cloud technologies journey.
















 Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data. Praveen Kumar is a Principal Analytics Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-centered services. His areas of interests are serverless technology, modern cloud data warehouses, streaming, and generative AI applications.
Praveen Kumar is a Principal Analytics Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-centered services. His areas of interests are serverless technology, modern cloud data warehouses, streaming, and generative AI applications. Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends.
Stuti Deshpande is a Big Data Specialist Solutions Architect at AWS. She works with customers around the globe, providing them strategic and architectural guidance on implementing analytics solutions using AWS. She has extensive experience in big data, ETL, and analytics. In her free time, Stuti likes to travel, learn new dance forms, and enjoy quality time with family and friends. Scott Rigney is a Senior Technical Product Manager with AWS and has expertise in analytics, data science, and machine learning. He is passionate about building software products that enable enterprises to make data-driven decisions and drive innovation.
Scott Rigney is a Senior Technical Product Manager with AWS and has expertise in analytics, data science, and machine learning. He is passionate about building software products that enable enterprises to make data-driven decisions and drive innovation.