Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/sending-amazon-eventbridge-events-to-private-endpoints-in-a-vpc/
This post is written by Emily Shea, Senior GTM Specialist, Event-Driven Architectures.
Building with events can help you accelerate feature velocity and build scalable, fault tolerant applications. You can achieve loose coupling in your application using asynchronous communication via events. Loose coupling allows each development team to build and deploy independently and each component to scale and fail without impacting the others. This approach is referred to as event-driven architecture.
Amazon EventBridge helps you build event-driven architectures. You can publish events to the EventBridge event bus and EventBridge routes those events to targets. You can write rules to filter events and only send them to the interested targets. For example, an order fulfillment service may only be interested in events of type ‘new order created.’
EventBridge is serverless, so there is no infrastructure to manage and the service scales automatically. EventBridge has native integrations with over 100 AWS services and over 40 SaaS providers.
Amazon EventBridge has a native integration with AWS Lambda, and many AWS customers use events to trigger Lambda functions to process events. You may also want to send events to workloads running on Amazon EC2 or containerized workloads deployed with Amazon ECS or Amazon EKS. These services are deployed into an Amazon Virtual Private Cloud, or VPC.
For some use cases, you may be able to expose public endpoints for your VPC. You can use EventBridge API destinations to send events to any public HTTP endpoint. API destinations include features like OAuth support and rate limiting to control the number of events you are sending per second.
However, some customers are not able to expose public endpoints for security or compliance purposes. This tutorial shows you how to send EventBridge events to a private endpoint in a VPC using a Lambda function to relay events. This solution deploys the Lambda function connected to the VPC and uses IAM permissions to enable EventBridge to invoke the Lambda function. Learn more about Lambda VPC connectivity here.
In this blog post, you learn how to send EventBridge events to a private endpoint in a VPC. You set up an example application with an EventBridge event bus, a Lambda function to relay events, a Flask application running in an EKS cluster to receive events behind an Application Load Balancer (ALB), and a secret stored in Secrets Manager for authenticating requests. This application uses EKS and Secrets Manager to demonstrate sending and authenticating requests to a containerized workload, but the same pattern applies for other container orchestration services like ECS and your preferred secret management solution.
Continue reading for the full example application and walkthrough. If you have an existing application in a VPC, you can deploy just the event relay portion and input your VPC details as parameters.
Solution overview

- An event is sent to the EventBridge bus.
- If the event matches a certain pattern (ex, if ‘detail-type’ is ‘inbound-event-sent’), an EventBridge rule uses EventBridge’s input transformer to format the event as an HTTP call.
- The EventBridge rule pushes the event to a Lambda function connected to the VPC and a CloudWatch Logs group for debugging.
- The Lambda function calls Secrets Manager and retrieves a secret key. It appends the secret key to the event headers and then makes an HTTP call to the ALB URL endpoint.
- ALB routes this HTTP call to a node group in the EKS cluster. The Flask application running on the EKS cluster calls Secret Manager, confirms that the secret key is valid, and then processes the event.
- The Lambda function receives a response from ALB.
- If the Flask application fails to process the event for any reason, the Lambda function raises an error. The function’s failure destination is configured to send the event and the error message to an SQS dead letter queue.
- If the Flask application successfully processes the event and the ‘return-response-event’ flag in the event was set to ‘true’, then the Lambda function publishes a new ‘outbound-event-sent’ event to the same EventBridge bus.
- Another EventBridge rule matches detail-type ‘outbound-event-sent’ events and routes these to the CloudWatch Logs group for debugging.
Prerequisites
To run the application, you must install the AWS CLI, Docker CLI, eksctl, kubectl, and AWS SAM CLI.
To clone the repository, run:
git clone https://github.com/aws-samples/eventbridge-events-to-vpc.gitCreating the EKS cluster
- In the example-vpc-application directory, use eksctl to create the EKS cluster using the config file.
cd example-vpc-application eksctl create cluster --config-file eksctl_config.yamlThis takes a few minutes. This step creates an EKS cluster with one node group in us-east-1. The EKS cluster has a service account with IAM permissions to access the Secrets Manager secret you create later.
- Use your AWS account’s default Amazon Elastic Container Registry (ECR) private registry to store the container image. First, follow these instructions to authenticate Docker to ECR. Next, run this command to create a new ECR repository. The create-repository command returns a repository URI (for example, 123456789.dkr.ecr.us-east-1.amazonaws.com/events-flask-app).
aws ecr create-repository --repository-name events-flask-appUse the repository URI in the following commands to build, tag, and push the container image to ECR.
docker build --tag events-flask-app . docker tag events-flask-app:latest {repository-uri}:1 docker push {repository-uri}:1 - In the Kuberenetes deployment manifest file (
/example-vpc-application/manifests/deployment.yaml), fill in your repository URI and container image version (for example,123456789.dkr.ecr.us-east-1.amazonaws.com/events-flask-app:1)
Deploy the Flask application and Application Load Balancer
- Within the example-vpc-application directory, use kubectl to apply the Kubernetes manifest files. This step deploys the ALB, which takes time to create and you may receive an error message during the deployment (‘no endpoints available for service “aws-load-balancer-webhook-service”‘). Rerun the same command until the ALB is deployed and you no longer receive the error message.
kubectl apply --kustomize manifests/ - Once the deployment is completed, verify that the Flask application is running by retrieving the Kubernetes pod logs. The first command retrieves a pod name to fill in for the second command.
kubectl get pod --namespace vpc-example-app kubectl logs --namespace vpc-example-app {pod-name} --followYou should see the Flask application outputting ‘Hello from my container!’ in response to GET request health checks.


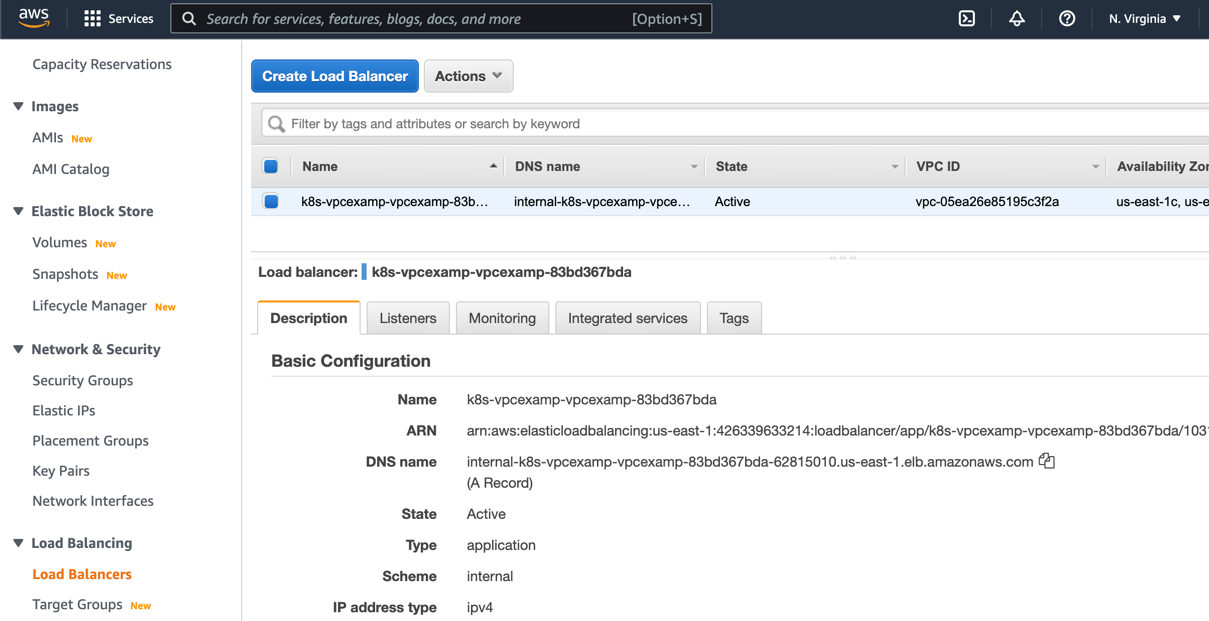
Get VPC and ALB details
Next, you retrieve the security group ID, private subnet IDs, and ALB DNS Name to deploy the Lambda function connected to the same VPC and private subnet and send events to the ALB.
- In the AWS Management Console, go to the VPC dashboard and find Subnets. Copy the subnet IDs for the two private subnets (for example, subnet name ‘eksctl-events-cluster/SubnetPrivateUSEAST1A’).

- In the VPC dashboard, under Security, find the Security Groups tab. Copy the security group ID for ‘eksctl-events-cluster/ClusterSharedNodeSecurityGroup’.

- Go to the EC2 dashboard. Under Load Balancing, find the Load Balancer tab. There is a load balancer associated with your VPC ID. Copy the DNS name for the load balancer, adding ‘http://’ as a prefix (for example, http://internal-k8s-vpcexamp-vpcexamp-c005e07d1a-1074647274.us-east-1.elb.amazonaws.com).



Create the Secrets Manager VPC endpoint
You need a VPC endpoint for your application to call Secrets Manager.
- In the VPC dashboard, find the Endpoints tab and choose Create Endpoint. Select Secrets Manager as the service, and then select the VPC, private subnets, and security group that you copied in the previous step. Choose Create.


Deploy the event relay application
Deploy the event relay application using the AWS Serverless Application Model (AWS SAM) CLI:
- Open a new terminal window and navigate to the event-relay directory. Run the following AWS SAM CLI commands to build the application and step through a guided deployment.
cd event-relay sam build sam deploy --guidedThe guided deployment process prompts for input parameters. Enter ‘event-relay-app’ as the stack name and accept the default Region. For other parameters, submit the ALB and VPC details you copied: Url (ALB DNS name), security group ID, and private subnet IDs. For the Secret parameter, pass any value.The AWS SAM template saves this value as a Secrets Manager secret to authenticate calls to the container application. This is an example of how to pass secrets in the event relay HTTP call. Replace this with your own authentication method in production environments.
- Accept the defaults for the remaining options. For ‘Deploy this changeset?’, select ‘y’. Here is an example of the deployment parameters.


Test the event relay application
Both the Flask application in a VPC and the event relay application are now deployed. To test the event relay application, keep the Kubernetes pod logs from a previous step open to monitor requests coming into the Flask application.
- You can open a new terminal window and run this AWS CLI command to put an event on the bus, or go to the EventBridge console, find your event bus, and use the Send events UI.
aws events put-events \ --entries '[{"EventBusName": "event-relay-bus" ,"Source": "eventProducerApp", "DetailType": "inbound-event-sent", "Detail": "{ \"event-id\": \"123\", \"return-response-event\": true }"}]'When the event is relayed to the Flask application, a POST request in the Kubernetes pod logs confirms that the application processed the event.

- Navigate to the CloudWatch Logs groups in the AWS Management Console. In the ‘/aws/events/event-bus-relay-logs’ group, there are logs for the EventBridge events. In ‘/aws/lambda/EventRelayFunction’ stream, the Lambda function relays the inbound event and puts a new outbound event on the EventBridge bus.
- You can test the SQS dead letter queue by creating an error. For example, you can manually change the Lambda function code in the console to pass an incorrect value for the secret. After sending a test event, navigate to the SQS queue in the console and poll for messages. The message shows the error message from the Flask application and the full event that failed to process.

Cleaning up
In the VPC dashboard in the AWS Management Console, find the Endpoints tab and delete the Secrets Manager VPC endpoint. Next, run the following commands to delete the rest of the example application. Be sure to run the commands in this order as some of the resources have dependencies on one another.
sam delete --stack-name event-relay-app
kubectl --namespace vpc-example-app delete ingress vpc-example-app-ingressFrom the example-vpc-application directory, run this command.
eksctl delete cluster --config-file eksctl_config.yamlConclusion
Event-driven architectures and EventBridge can help you accelerate feature velocity and build scalable, fault tolerant applications. This post demonstrates how to send EventBridge events to a private endpoint in a VPC using a Lambda function to relay events and emit response events.
To learn more, read Getting started with event-driven architectures and visit EventBridge tutorials on Serverless Land.
























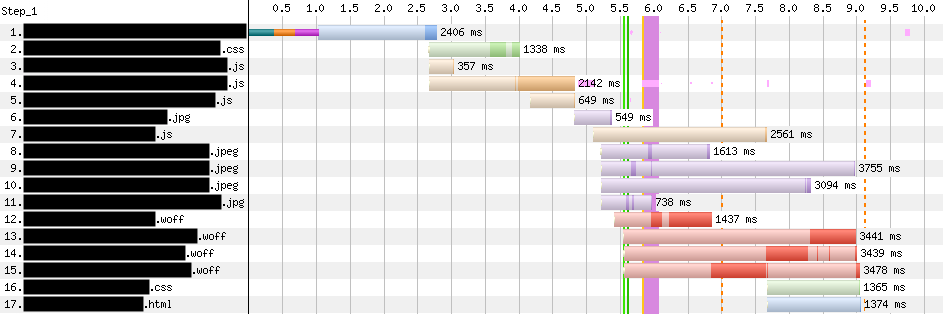
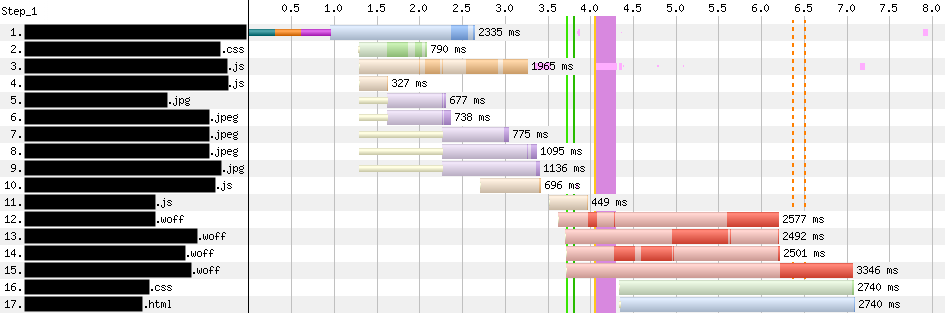




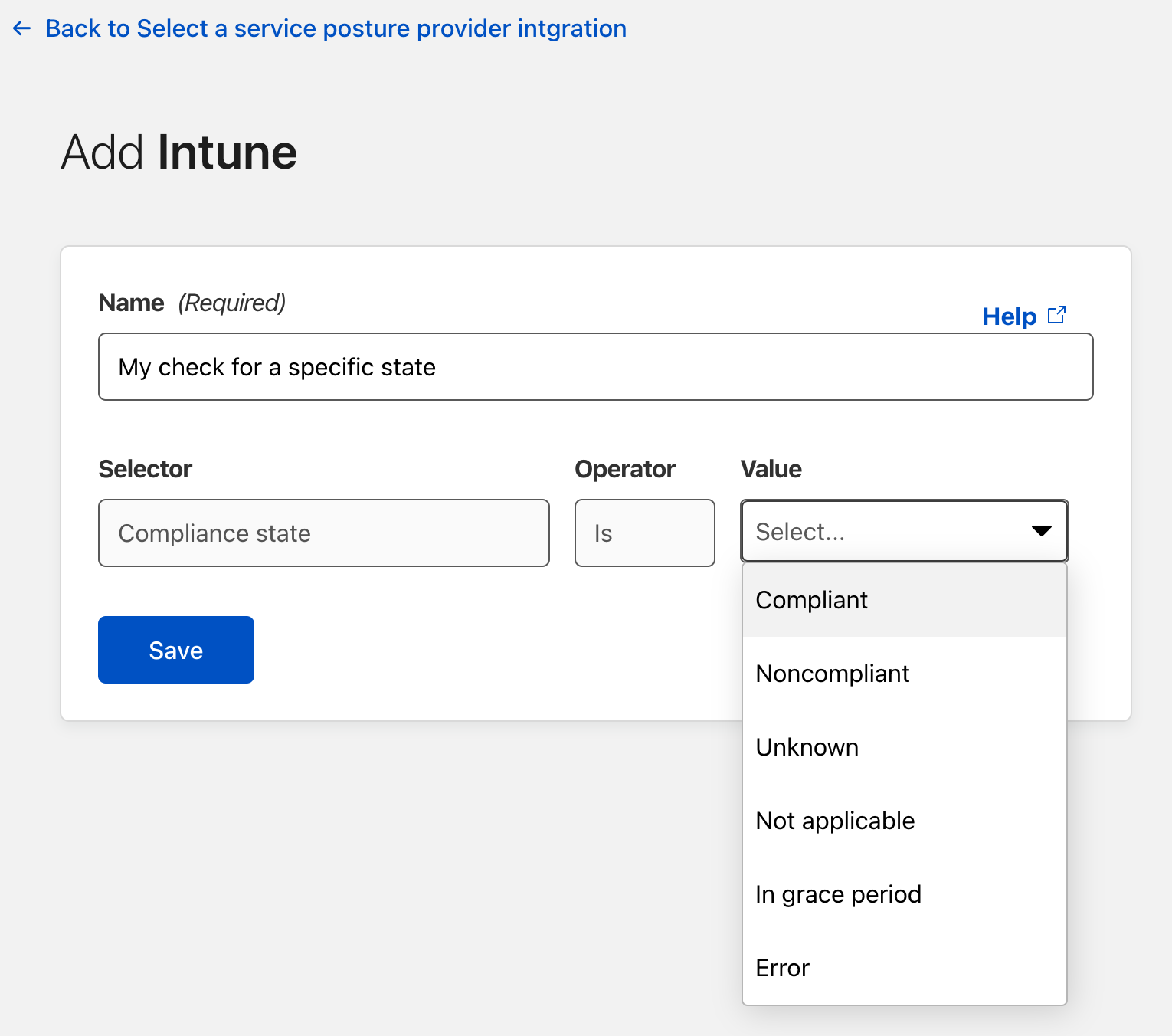



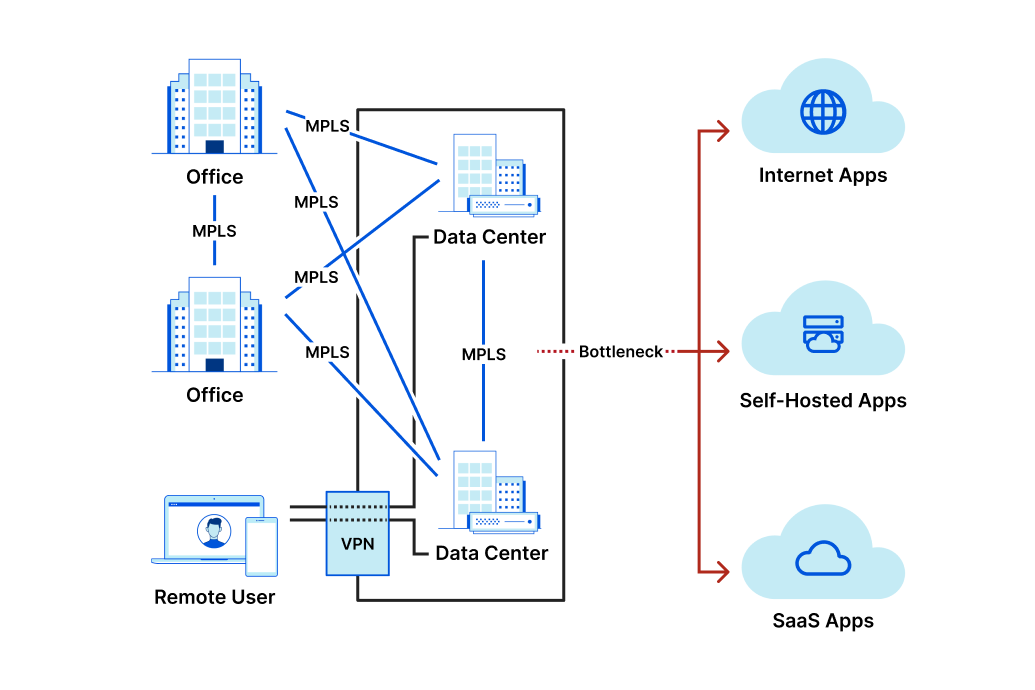
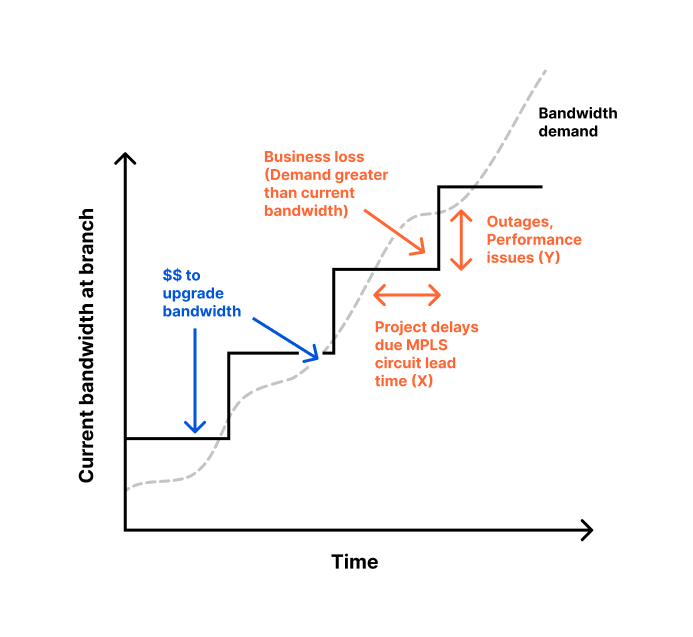


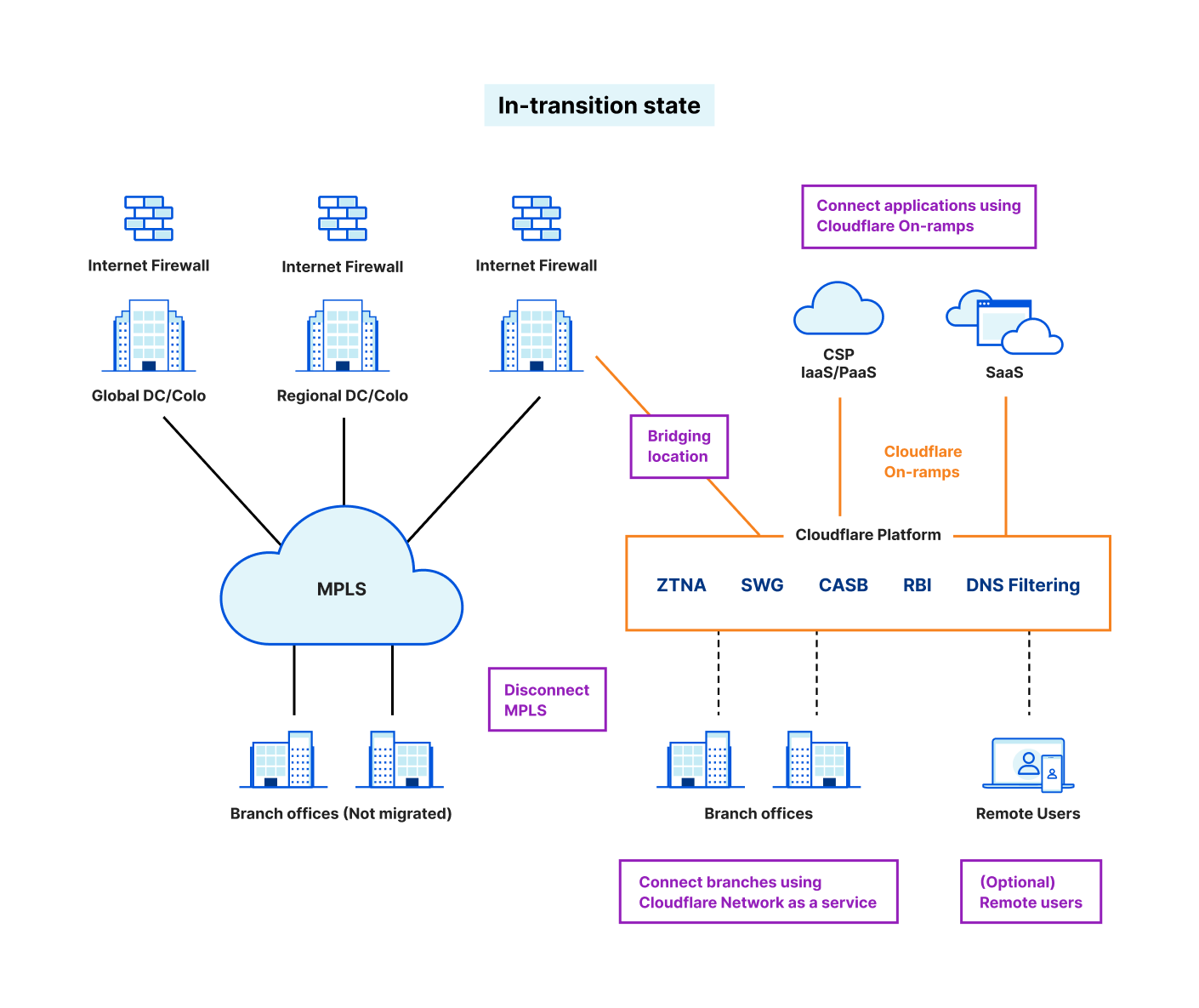
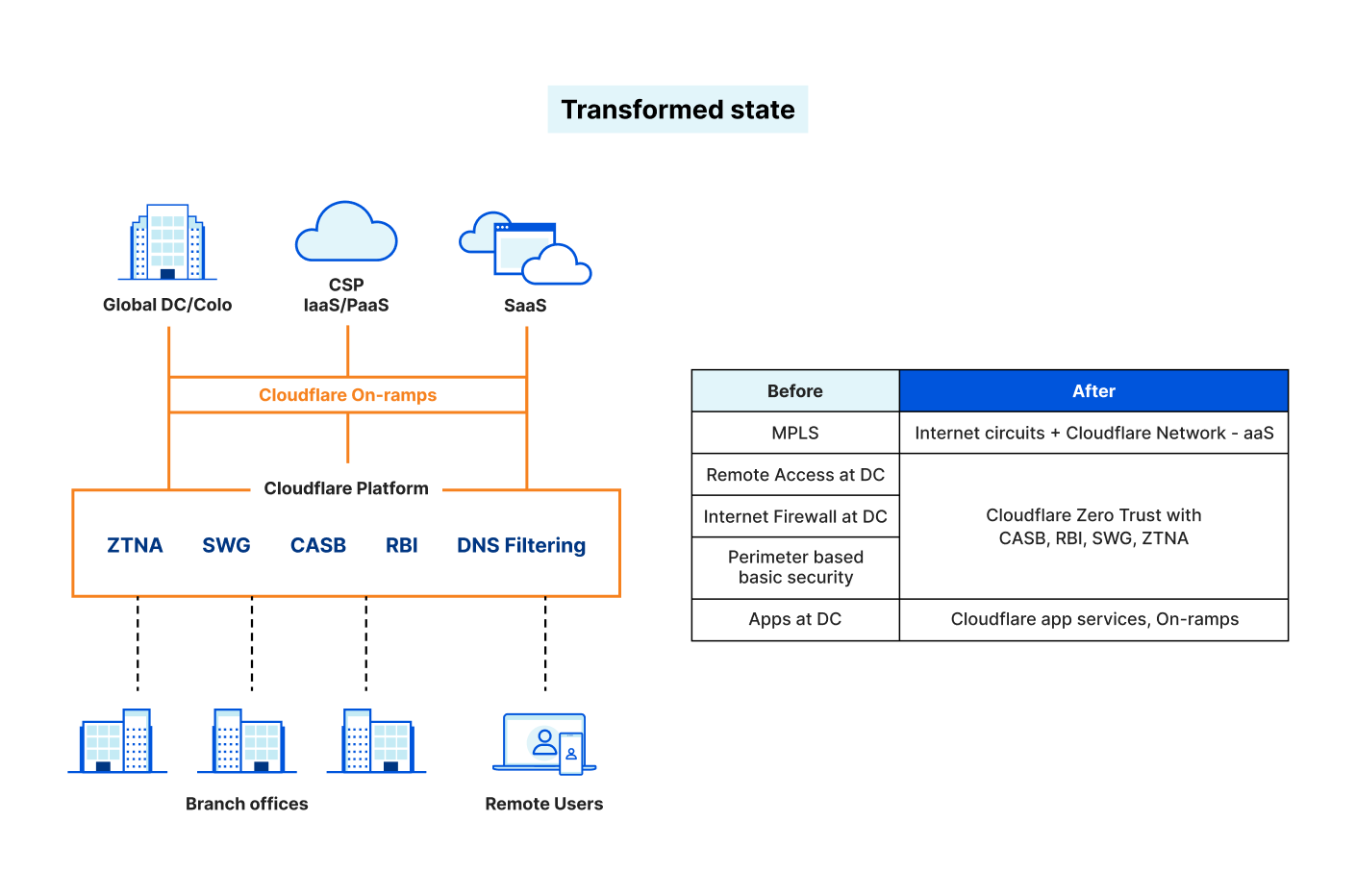




 Cloudflare Access augments or replaces corporate VPN clients by securing SaaS and internal applications. Access works with your identity providers and endpoint protection platforms to enforce default-deny, Zero Trust rules limiting access to corporate applications, private IP spaces, and hostnames.
Cloudflare Access augments or replaces corporate VPN clients by securing SaaS and internal applications. Access works with your identity providers and endpoint protection platforms to enforce default-deny, Zero Trust rules limiting access to corporate applications, private IP spaces, and hostnames. Cloudflare Gateway is our threat and data protection solution. It keeps data safe from malware, ransomware, phishing, command and control, Shadow IT, and other Internet risks over all ports and protocols.
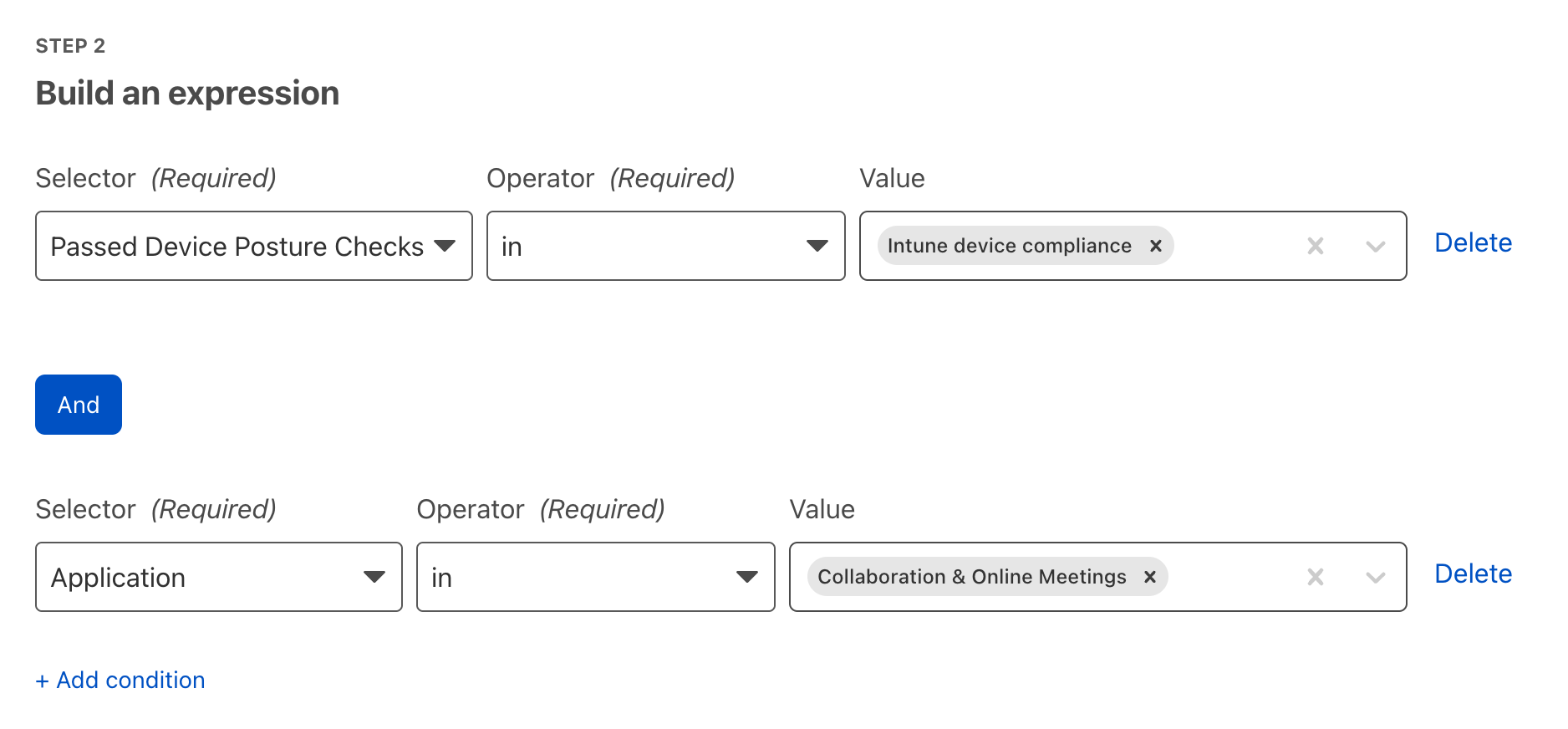
Cloudflare Gateway is our threat and data protection solution. It keeps data safe from malware, ransomware, phishing, command and control, Shadow IT, and other Internet risks over all ports and protocols. Cloudflare Area 1 Email Security crawls the Internet to stop phishing, Business Email Compromise (BEC), and email supply chain attacks at the earliest stage of the attack cycle, and enhances built-in security from cloud email providers.
Cloudflare Area 1 Email Security crawls the Internet to stop phishing, Business Email Compromise (BEC), and email supply chain attacks at the earliest stage of the attack cycle, and enhances built-in security from cloud email providers. Cloudflare Browser Isolation makes web browsing safer and faster, running in the cloud away from your network and endpoints, insulating devices from attacks.
Cloudflare Browser Isolation makes web browsing safer and faster, running in the cloud away from your network and endpoints, insulating devices from attacks. Cloudflare CASB (Cloud Access Security Broker) gives customers comprehensive visibility and control over SaaS apps to easily prevent data leaks, block insider threats, and avoid compliance violations.
Cloudflare CASB (Cloud Access Security Broker) gives customers comprehensive visibility and control over SaaS apps to easily prevent data leaks, block insider threats, and avoid compliance violations. Cloudflare Data Loss Prevention enables customers to detect and prevent data exfiltration or data destruction. Analyze network traffic and internal “endpoint” devices to identify leakage or loss of confidential information, and stay compliant with industry and data privacy regulations.
Cloudflare Data Loss Prevention enables customers to detect and prevent data exfiltration or data destruction. Analyze network traffic and internal “endpoint” devices to identify leakage or loss of confidential information, and stay compliant with industry and data privacy regulations.
{kind=link}