Post Syndicated from Amrit Singh original https://www.backblaze.com/blog/an-ideal-solution-daltixs-automated-data-lake-archive-saves-100k/

In the fast-moving consumer goods space, Daltix is a pioneer in providing complete, transparent, and high-quality retail data. With global industry leaders like GFK and Unilever depending on their pricing, product, promotion, and location data to build go-to market strategies and make critical decisions, maintaining a reliable data ecosystem is an imperative for Daltix.
As the company has grown since its founding in 2016, the amount of data Daltix is processing has increased exponentially. They’re currently managing around 250TB, but that amount is spread across billions of files, which soon created a massive drag on time and resources. With an infrastructure built almost entirely around AWS and billions of miniscule files to manage, Daltix started to outgrow AWS’ storage options in both scalability and cost efficiency.

We got to chat with Charlie Orford, Principal Software Engineer for Daltix, about how Datix switched to Backblaze B2 Cloud Storage and their takeaways from that process. Here are some highlights:
- They used a custom engine to migrate billions of files from AWS S3 to Backblaze B2.
- Monthly costs reduced by $2,500 while increasing data portability and reliability.
- Daltix established the infrastructure to automatically back up 8.4 million data objects every day.
Read on to learn how they did it.
A Complex Data Pipeline Built Around AWS
Most of the S3-based infrastructure Daltix built in the company’s early days is still intact. Historically, the data pipeline started with web-scraped resources written directly to Amazon S3, which were then standardized by Lamba-based extractors before being sent back to S3. Then AWS Batch picked up the resources to be augmented and enriched using other data sources.
All those steps took place before the data was ready for Daltix’s team of analysts. In order to optimize the pipeline and increase efficiency, Orford started absorbing pieces of that process into Kubernetes. But there was still a data storage problem; Daltix generates about 300GB of compressed data per day, and that figure was growing rapidly. “As we’d scaled up our data collection, we’d had to sharpen our focus on cost control, data portability, and reliability,” said Orford. “They’re obvious, but at scale, they’re extremely important.”
Cost Concerns Inspire The Search For Warm Archival Storage
By 2020, Daltix had started to realize the limitations of building so much of their infrastructure in AWS. For example, heavy customization around S3 metadata made the ability to move objects entirely dependent on the target system’s compatibility with S3. Orford was also concerned about the costs of permanently storing such a huge data lake in S3. As he puts it, “It was clear that there was no need to have everything in S3 forever. If we didn’t do anything about it, our S3 costs were going to continue to rise and eventually dwarf virtually all of our other AWS costs.”
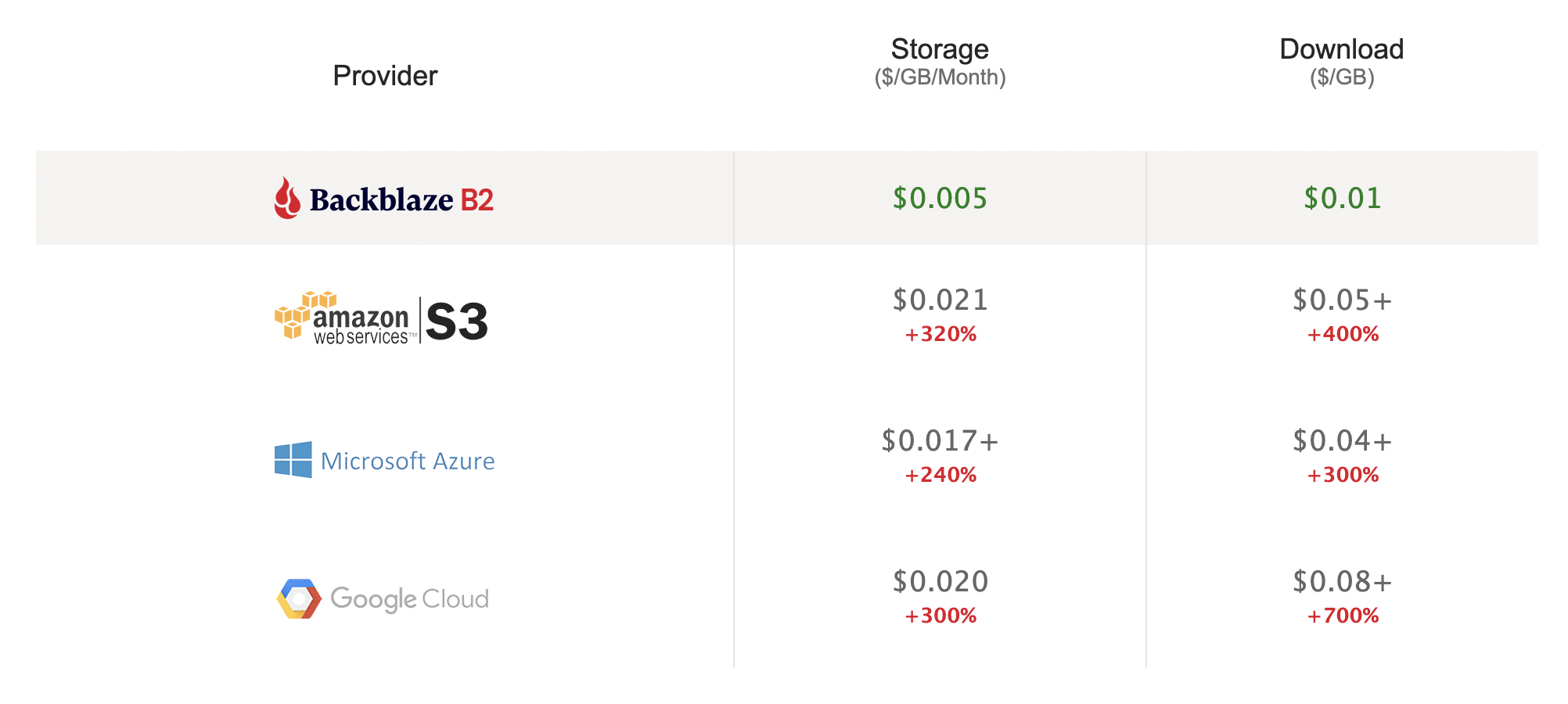
Because Daltix works with billions of tiny files, using Glacier was out of the question as its pricing model is based around retrieval fees. Even using Glacier Instant Retrieval, the sheer number of files Daltix works with would have forced them to rack up an additional $200,000 in fees per year. So Daltix’s data collection team—which produces more than 85% of the company’s overall data—pushed for an alternative solution that could address a number of competing concerns:
- The sheer size of the data lake.
- The need to store raw resources as discrete files (which means that batching is not an option).
- Limitations on the team’s ability to invest time and effort.
- A desire for simplicity to guarantee the solution’s reliability.
Daltix settled on using Amazon S3 for hot storage and moving warm storage into a new archival solution, which would reduce costs while keeping priority data accessible—even if the intention is to keep files stored away. “It was important to find something that would be very easy to integrate, have a low development risk, and start meaningfully eating into our costs,” said Orford. “For us, Backblaze really ticked all the boxes.”
Initial Migration Unlocks Immediate Savings of $2,000 Per Month
Before launching into a full migration, Orford and his team tested a proof of concept (POC) to make sure the solution addressed his key priorities:
- Making sure the huge volume of data was migrated successfully.
- Avoiding data corruption and checking for errors with audit logs.
- Preserving custom metadata on each individual object.
“Early on, Backblaze worked with us hand-in-hand to come up with a custom migration tool that fit all our requirements,” said Orford. “That’s what gave us the confidence to proceed.” In partnership with Flexify, Backblaze delivered a tailor-made engine to ensure that the migration process would transfer the entire data lake reliably and with object-level metadata intact. After the initial POC bucket was migrated successfully, Daltix had everything they needed to start modeling and forecasting future costs. “As soon as we started interacting with Backblaze, we stopped looking at other options,” Orford said.
In August 2021, Daltix moved a 120TB bucket of 2.2 billion objects from standard storage in S3 to Backblaze B2 cloud storage. That initial migration alone unlocked an immediate cost savings of $2,000 per month, or $24,000 per year.

Quadruple the Data, Direct S3 Compatibility, and $100,000 Cumulative Savings
Today, Daltix is migrating about 3.2 million data objects (approximately 70GB of data) from Amazon S3 into Backblaze B2 every day. They keep 18 months of hot data in S3, and as soon as an object reaches 18 months and one day, it becomes eligible for archiving in B2. On the rare occasions that Daltix receives requests for data outside that 18-month window, they can pull data directly from Backblaze B2 into Amazon S3 thanks to Backblaze’s S3-compatible API and ever-available data.
Daily audit logs summarize how much data has been transferred, and the entire migration process happens automatically every day. “It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective,” Orford said. “Backblaze B2 is an ideal solution for us.”
As daily data collection increases and more data ages out of the hot storage window, Orford expects more cost reductions. Orford expects it will take about a year and a half for daily migrations to nearly triple their current levels: that means Daltix will be backing up 9 million objects (about 450GB of data) to Backblaze B2 every day. Taking that long-term view, we see incredible cost savings for Daltix by switching from Amazon S3 to Backblaze B2. “By 2023, we forecast we will have realized a cumulative saving in the region of $75,000-$100,000 on our storage spend thanks to leveraging Backblaze B2, with expected ongoing savings of at least $30,000 per year,” said Orford.
“It runs in the background, there’s nothing to manage, we have full visibility, and it’s cost effective. B2 is an ideal solution for us.” —Charlie Orford, Principal Software Engineer, Daltix
Crunch the Numbers and See for Yourself
Want to find out what your business could do with an extra $30,000 a year? Check out our Cloud Storage Pricing Calculator to see what you could save switching to Backblaze B2.
The post “An Ideal Solution”: Daltix’s Automated Data Lake Archive Saves $100K appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.