Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/linuxtag-2010-slides.html
On popular request, here are my (terse) slides from LinuxTag on systemd.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/linuxtag-2010-slides.html
On popular request, here are my (terse) slides from LinuxTag on systemd.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/linuxtag2k10.html
The upcoming week I’ll do two talks at LinuxTag 2010 at the Berlin Fair Grounds. One of them was only
added to the schedule today, about
systemd. Systemd has never been presented in a public talk before, so make
sure to attend this historic moment… ;-). Read about what has been written about systemd
so far, so that you can ask the sharpest questions during my
presentation.
My second talk might be about stuff a little less reported in the press, but
still very interesting, about Surround Sound in Gnome.
See you at LinuxTag!
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/mango-lassi-is-back.html
![]()
Sven Herzberg has recently
been doing a lot of work on Mango Lassi, a
project deserving love but which I as its original author haven’t touched
in 3 years.
His work is already bearing fruits:

Distribution packagers, please go and package his version, Mango Lassi is an
awesome, wonderful tool that needs distributor love.
If you want to use Mango Lassi without waiting for the distribution packagers to catch up, Sven has built some packages for you in the OpenSUSE Build Service.
Sven, KUTGW!
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/name-your-threads.html
Stefan Kost recently pointed me to the fact that the Linux system call
prctl(PR_SET_NAME) does not in fact change the process name, but the
task name (comm field) — in contrast to what the
man page suggests.
That makes it very useful for naming threads, since you can read back the
name you set with PR_SET_NAME earlier from the /proc file system
(/proc/$PID/task/$TID/comm on newer kernels,
/proc/$PID/task/$TID/stat‘s second field on older kernels), and hence
distuingish which thread might be responsible for the high CPU load or similar
problems.
So, now go, if you have a project which involves a lot of threads, name them
all individually, and make it easier to debug them. What’s missing now, of
course, is that gdb learns this and shows the comm name when doing info
threads.
I have changed PulseAudio now to name all threads it creates.
Of course, what would be even better than this is full file system extended
attribute support in procfs, so that we could attach arbitrary information to
processes and threads, including references to .desktop files and such.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/systemd-website.html
We now have a web
site, a mailing
list, a bugzilla component and moved our
git repositories to freedesktop.org. Make sure to update your check-outs.
For more details see our new web site.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/lac-video.html
The great people from the Linux Audio Conference uploaded
the video streams from the event. Among them you can find my
own presentation. Enjoy!
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/when-pa-and-when-not.html
#nocomments yes
One thing became very clear to me during my trip to the Linux Audio Conference 2010
in Utrecht: even many pro audio folks are not sure what Jack does that PulseAudio doesn’t do and what
PulseAudio does that Jack doesn’t do; why they are not competing, why
you cannot replace one by the other, and why merging them (at least in
the short term) might not make immediate sense. In other words, why
millions of phones on this world run PulseAudio and not Jack, and why
a music studio running PulseAudio is crack.
To light this up a bit and for future reference I’ll try to explain in the
following text why there is this seperation between the two systems and why this isn’t
necessarily bad. This is mostly a written up version of (parts of) my slides
from LAC, so if you attended that event you might find little new, but I hope
it is interesting nonetheless.
This is mostly written from my perspective as a hacker working on
consumer audio stuff (more specifically having written most of
PulseAudio), but I am sure most pro audio folks would agree with the
points I raise here, and have more things to add. What I explain below
is in no way comprehensive, just a list of a couple of points I think
are the most important, as they touch the very core of both
systems (and we ignore all the toppings here, i.e. sound effects, yadda, yadda).
First of all let’s clear up the background of the sound server use cases here:
| Consumer Audio (i.e. PulseAudio) | Pro Audio (i.e. Jack) |
|---|---|
| Reducing power usage is a defining requirement, most systems are battery powered (Laptops, Cell Phones). | Power usage usually not an issue, power comes out of the wall. |
| Must support latencies low enough for telephony and games. Also covers high latency uses, such as movie and music playback (2s of latency is a good choice). |
Minimal latencies are a definining requirement. |
| System is highly dynamic, with applications starting/stopping, hardware added and removed all the time. | System is usually static in its configuration during operation. |
| User is usually not proficient in the technologies used.[1] | User is usually a professional and knows audio technology and computers well. |
| User is not necessarily the administrator of his machine, might have limited access. | User usually administrates his own machines, has root privileges. |
| Audio is just one use of the system among many, and often just a background job. | Audio is the primary purpose of the system. |
| Hardware tends to have limited resources and be crappy and cheap. | Hardware is powerful, expensive and high quality. |
Of course, things are often not as black and white like this, there are uses
that fall in the middle of these two areas.
From the table above a few conclusions may be drawn:
Jack has been designed for low latencies, where synchronous
operation is advisable, meaning that a misbehaving client call stall
the entire pipeline. Changes of the pipeline or latencies usually
result in drop-outs in one way or the other, since the entire pipeline
is reconfigured, from the hardware to the various clients. Jack only
supports FLOAT32 samples and non-interleaved audio channels (and that
is a good thing). Jack does not employ reference-counted zero-copy
buffers. It does not try to simplify the hardware mixer in any
way.
PulseAudio OTOH can deal with varying latancies, dynamically
adjusting to the lowest latencies any of the connected clients
needs. Client communication is fully asynchronous, a single client
cannot stall the entire pipeline. PulseAudio supports a variety of PCM
formats and channel setups. PulseAudio’s design is heavily based on
reference-counted zero-copy buffers that are passed around, even
between processes, instead of the audio data itself. PulseAudio tries
to simplify the hardware mixer as suggested above.
Now, the two paragraphs above hopefully show how Jack is more
suitable for the pro audio use case and PulseAudio more for the
consumer audio use case. One question asks itself though: can we marry
the two approaches? Yes, we probably can, MacOS has a unified approach
for both uses. However, it is not clear this would be a good
idea. First of all, a system with the complexities introduced by
sample format/channel mapping conversion, as well as dynamically
changing latencies and pipelines, and asynchronous behaviour would
certainly be much less attractive to pro audio developers. In fact,
that Jack limits itself to synchronous, FLOAT32-only,
non-interleaved-only audio streams is one of the big features of its
design. Marrying the two approaches would corrupt that. A merged
solution would probably not have a good stand in the community.
But it goes even further than this: what would the use case for
this be? After all, most of the time, you don’t want your event
sounds, your Youtube, your VoIP and your Rhythmbox mixed into the new
record you are producing. Hence a clear seperation between the two
worlds might even be handy?
Also, let’s not forget that we lack the manpower to even create
such an audio chimera.
So, where to from here? Well, I think we should put the focus on
cooperation instead of amalgamation: teach PulseAudio to go out of the
way as soon as Jack needs access to the device, and optionally make
PulseAudio a normal JACK client while both are running. That way, the
user has the option to use the PulseAudio supplied streams, but
normally does not see them in his pipeline. The first part of this has
already been implemented: Jack2 and PulseAudio do not fight for the
audio device, a friendly handover takes place. Jack takes precedence,
PulseAudio takes the back seat. The second part is still missing: you
still have to manually hookup PulseAudio to Jack if you are interested
in its streams. If both are implemented starting Jack basically has
the effect of replacing PulseAudio’s core with the Jack core, while
still providing full compatibility with PulseAudio clients.
And that I guess is all I have to say on the entire Jack and
PulseAudio story.
Oh, one more thing, while we are at clearing things up: some news
sites claim that PulseAudio’s not necessarily stellar reputation in
some parts of the community comes from Ubuntu and other distributions
having integrated it too early. Well, let me stress here explicitly,
that while they might have made a mistake or two in packaging
PulseAudio and I publicly pointed that out (and probably not in a too
friendly way), I do believe that the point in time they adopted it was
right. Why? Basically, it’s a chicken and egg problem. If it is not
used in the distributions it is not tested, and there is no pressure
to get fixed what then turns out to be broken: in PulseAudio itself,
and in both the layers on top and below of it. Don’t forget that
pushing a new layer into an existing stack will break a lot of
assumptions that the neighboring layers made. Doing this must
break things. Most Free Software projects could probably use more
developers, and that is particularly true for Audio on Linux. And
given that that is how it is, pushing the feature in at that point in
time was the right thing to do. Or in other words, if the features are
right, and things do work correctly as far as the limited test base
the developers control shows, then one day you need to push into the
distributions, even if this might break setups and software that
previously has not been tested, unless you want to stay stuck in your
development indefinitely. So yes, Ubuntu, I think you did well with
adopting PulseAudio when you did.
[1] Side note: yes, consumers tend not to know what dB is, and expect
volume settings in “percentages”, a mostly meaningless unit in
audio. This even spills into projects like VLC or Amarok which expose
linear volume controls (which is a really bad idea).
[2] In case you are wondering why that is the case: if the latency is
low the buffers must be sized smaller. And if the buffers are sized smaller
then the CPU will have to wake up more often to fill them up for the same
playback time. This drives up the CPU load since less actual payload can be
processed for the amount of housekeeping that the CPU has to do during each
buffer iteration. Also, frequent wake-ups make it impossible for the CPU to go
to deeper sleep states. Sleep states are the primary way for modern CPUs
to save power.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/systemd-in-the-news.html
#nocomments yes
A few news sites brought articles (some shorter, others longer) about last week’s blog story on systemd:
Related to this, Scott’s cordial reply.
And this I find funny, make sure to vote for it… 😉
Many of the comments on those stories are quite interesting, though sometimes a little, uh…, misled… 😉
Generally the reception of the ideas seems to be very positive. And that’s certainly good news and encouraging.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/systemd.html
If you are well connected or good at reading between the lines
you might already know what this blog post is about. But even then
you may find this story interesting. So grab a cup of coffee,
sit down, and read what’s coming.
This blog story is long, so even though I can only recommend
reading the long story, here’s the one sentence summary: we are
experimenting with a new init system and it is fun.
Here’s the code. And here’s the story:
On every Unix system there is one process with the special
process identifier 1. It is started by the kernel before all other
processes and is the parent process for all those other processes
that have nobody else to be child of. Due to that it can do a lot
of stuff that other processes cannot do. And it is also
responsible for some things that other processes are not
responsible for, such as bringing up and maintaining userspace
during boot.
Historically on Linux the software acting as PID 1 was the
venerable sysvinit package, though it had been showing its age for
quite a while. Many replacements have been suggested, only one of
them really took off: Upstart, which has by now found
its way into all major distributions.
As mentioned, the central responsibility of an init system is
to bring up userspace. And a good init system does that
fast. Unfortunately, the traditional SysV init system was not
particularly fast.
For a fast and efficient boot-up two things are crucial:
What does that mean? Starting less means starting fewer
services or deferring the starting of services until they are
actually needed. There are some services where we know that they
will be required sooner or later (syslog, D-Bus system bus, etc.),
but for many others this isn’t the case. For example, bluetoothd
does not need to be running unless a bluetooth dongle is actually
plugged in or an application wants to talk to its D-Bus
interfaces. Same for a printing system: unless the machine
physically is connected to a printer, or an application wants to
print something, there is no need to run a printing daemon such as
CUPS. Avahi: if the machine is not connected to a
network, there is no need to run Avahi, unless some application wants
to use its APIs. And even SSH: as long as nobody wants to contact
your machine there is no need to run it, as long as it is then
started on the first connection. (And admit it, on most machines
where sshd might be listening somebody connects to it only every
other month or so.)
Starting more in parallel means that if we have
to run something, we should not serialize its start-up (as sysvinit
does), but run it all at the same time, so that the available
CPU and disk IO bandwidth is maxed out, and hence
the overall start-up time minimized.
Modern systems (especially general purpose OS) are highly
dynamic in their configuration and use: they are mobile, different
applications are started and stopped, different hardware added and
removed again. An init system that is responsible for maintaining
services needs to listen to hardware and software
changes. It needs to dynamically start (and sometimes stop)
services as they are needed to run a program or enable some
hardware.
Most current systems that try to parallelize boot-up still
synchronize the start-up of the various daemons involved: since
Avahi needs D-Bus, D-Bus is started first, and only when D-Bus
signals that it is ready, Avahi is started too. Similar for other
services: livirtd and X11 need HAL (well, I am considering the
Fedora 13 services here, ignore that HAL is obsolete), hence HAL
is started first, before livirtd and X11 are started. And
libvirtd also needs Avahi, so it waits for Avahi too. And all of
them require syslog, so they all wait until Syslog is fully
started up and initialized. And so on.
This kind of start-up synchronization results in the
serialization of a significant part of the boot process. Wouldn’t
it be great if we could get rid of the synchronization and
serialization cost? Well, we can, actually. For that, we need to
understand what exactly the daemons require from each other, and
why their start-up is delayed. For traditional Unix daemons,
there’s one answer to it: they wait until the socket the other
daemon offers its services on is ready for connections. Usually
that is an AF_UNIX socket in the file-system, but it could be
AF_INET[6], too. For example, clients of D-Bus wait that
/var/run/dbus/system_bus_socket can be connected to,
clients of syslog wait for /dev/log, clients of CUPS wait
for /var/run/cups/cups.sock and NFS mounts wait for
/var/run/rpcbind.sock and the portmapper IP port, and so
on. And think about it, this is actually the only thing they wait
for!
Now, if that’s all they are waiting for, if we manage to make
those sockets available for connection earlier and only actually
wait for that instead of the full daemon start-up, then we can
speed up the entire boot and start more processes in parallel. So,
how can we do that? Actually quite easily in Unix-like systems: we
can create the listening sockets before we actually start
the daemon, and then just pass the socket during exec()
to it. That way, we can create all sockets for all
daemons in one step in the init system, and then in a second step
run all daemons at once. If a service needs another, and it is not
fully started up, that’s completely OK: what will happen is that
the connection is queued in the providing service and the client
will potentially block on that single request. But only that one
client will block and only on that one request. Also, dependencies
between services will no longer necessarily have to be configured
to allow proper parallelized start-up: if we start all sockets at
once and a service needs another it can be sure that it can
connect to its socket.
Because this is at the core of what is following, let me say
this again, with different words and by example: if you start
syslog and and various syslog clients at the same time, what will
happen in the scheme pointed out above is that the messages of the
clients will be added to the /dev/log socket buffer. As
long as that buffer doesn’t run full, the clients will not have to
wait in any way and can immediately proceed with their start-up. As
soon as syslog itself finished start-up, it will dequeue all
messages and process them. Another example: we start D-Bus and
several clients at the same time. If a synchronous bus
request is sent and hence a reply expected, what will happen is
that the client will have to block, however only that one client
and only until D-Bus managed to catch up and process it.
Basically, the kernel socket buffers help us to maximize
parallelization, and the ordering and synchronization is done by
the kernel, without any further management from userspace! And if
all the sockets are available before the daemons actually start-up,
dependency management also becomes redundant (or at least
secondary): if a daemon needs another daemon, it will just connect
to it. If the other daemon is already started, this will
immediately succeed. If it isn’t started but in the process of
being started, the first daemon will not even have to wait for it,
unless it issues a synchronous request. And even if the other
daemon is not running at all, it can be auto-spawned. From the
first daemon’s perspective there is no difference, hence dependency
management becomes mostly unnecessary or at least secondary, and
all of this in optimal parallelization and optionally with
on-demand loading. On top of this, this is also more robust, because
the sockets stay available regardless whether the actual daemons
might temporarily become unavailable (maybe due to crashing). In
fact, you can easily write a daemon with this that can run, and
exit (or crash), and run again and exit again (and so on), and all
of that without the clients noticing or loosing any request.
It’s a good time for a pause, go and refill your coffee mug,
and be assured, there is more interesting stuff following.
But first, let’s clear a few things up: is this kind of logic
new? No, it certainly is not. The most prominent system that works
like this is Apple’s launchd system: on MacOS the listening of the
sockets is pulled out of all daemons and done by launchd. The
services themselves hence can all start up in parallel and
dependencies need not to be configured for them. And that is
actually a really ingenious design, and the primary reason why
MacOS manages to provide the fantastic boot-up times it
provides. I can highly recommend this
video where the launchd folks explain what they are
doing. Unfortunately this idea never really took on outside of the Apple
camp.
The idea is actually even older than launchd. Prior to launchd
the venerable inetd worked much like this: sockets were
centrally created in a daemon that would start the actual service
daemons passing the socket file descriptors during
exec(). However the focus of inetd certainly
wasn’t local services, but Internet services (although later
reimplementations supported AF_UNIX sockets, too). It also wasn’t a
tool to parallelize boot-up or even useful for getting implicit
dependencies right.
For TCP sockets inetd was primarily used in a way that
for every incoming connection a new daemon instance was
spawned. That meant that for each connection a new
process was spawned and initialized, which is not a
recipe for high-performance servers. However, right from the
beginning inetd also supported another mode, where a
single daemon was spawned on the first connection, and that single
instance would then go on and also accept the follow-up connections
(that’s what the wait/nowait option in
inetd.conf was for, a particularly badly documented
option, unfortunately.) Per-connection daemon starts probably gave
inetd its bad reputation for being slow. But that’s not entirely
fair.
Modern daemons on Linux tend to provide services via D-Bus
instead of plain AF_UNIX sockets. Now, the question is, for those
services, can we apply the same parallelizing boot logic as for
traditional socket services? Yes, we can, D-Bus already has all
the right hooks for it: using bus activation a service can be
started the first time it is accessed. Bus activation also gives
us the minimal per-request synchronisation we need for starting up
the providers and the consumers of D-Bus services at the same
time: if we want to start Avahi at the same time as CUPS (side
note: CUPS uses Avahi to browse for mDNS/DNS-SD printers), then we
can simply run them at the same time, and if CUPS is quicker than
Avahi via the bus activation logic we can get D-Bus to queue the
request until Avahi manages to establish its service name.
So, in summary: the socket-based service activation and the
bus-based service activation together enable us to start
all daemons in parallel, without any further
synchronization. Activation also allows us to do lazy-loading of
services: if a service is rarely used, we can just load it the
first time somebody accesses the socket or bus name, instead of
starting it during boot.
And if that’s not great, then I don’t know what is
great!
If you look at
the serialization graphs of the boot process of current
distributions, there are more synchronisation points than just
daemon start-ups: most prominently there are file-system related
jobs: mounting, fscking, quota. Right now, on boot-up a lot of
time is spent idling to wait until all devices that are listed in
/etc/fstab show up in the device tree and are then
fsck’ed, mounted, quota checked (if enabled). Only after that is
fully finished we go on and boot the actual services.
Can we improve this? It turns out we can. Harald Hoyer came up
with the idea of using the venerable autofs system for this:
Just like a connect() call shows that a service is
interested in another service, an open() (or a similar
call) shows that a service is interested in a specific file or
file-system. So, in order to improve how much we can parallelize
we can make those apps wait only if a file-system they are looking
for is not yet mounted and readily available: we set up an autofs
mount point, and then when our file-system finished fsck and quota
due to normal boot-up we replace it by the real mount. While the
file-system is not ready yet, the access will be queued by the
kernel and the accessing process will block, but only that one
daemon and only that one access. And this way we can begin
starting our daemons even before all file systems have been fully
made available — without them missing any files, and maximizing
parallelization.
Parallelizing file system jobs and service jobs does
not make sense for /, after all that’s where the service
binaries are usually stored. However, for file-systems such as
/home, that usually are bigger, even encrypted, possibly
remote and seldom accessed by the usual boot-up daemons, this
can improve boot time considerably. It is probably not necessary
to mention this, but virtual file systems, such as
procfs or sysfs should never be mounted via autofs.
I wouldn’t be surprised if some readers might find integrating
autofs in an init system a bit fragile and even weird, and maybe
more on the “crackish” side of things. However, having played
around with this extensively I can tell you that this actually
feels quite right. Using autofs here simply means that we can
create a mount point without having to provide the backing file
system right-away. In effect it hence only delays accesses. If an
application tries to access an autofs file-system and we take very
long to replace it with the real file-system, it will hang in an
interruptible sleep, meaning that you can safely cancel it, for
example via C-c. Also note that at any point, if the mount point
should not be mountable in the end (maybe because fsck failed), we
can just tell autofs to return a clean error code (like
ENOENT). So, I guess what I want to say is that even though
integrating autofs into an init system might appear adventurous at
first, our experimental code has shown that this idea works
surprisingly well in practice — if it is done for the right
reasons and the right way.
Also note that these should be direct autofs
mounts, meaning that from an application perspective there’s
little effective difference between a classic mount point and one
based on autofs.
Another thing we can learn from the MacOS boot-up logic is
that shell scripts are evil. Shell is fast and shell is slow. It
is fast to hack, but slow in execution. The classic sysvinit boot
logic is modelled around shell scripts. Whether it is
/bin/bash or any other shell (that was written to make
shell scripts faster), in the end the approach is doomed to be
slow. On my system the scripts in /etc/init.d call
grep at least 77 times. awk is called 92
times, cut 23 and sed 74. Every time those
commands (and others) are called, a process is spawned, the
libraries searched, some start-up stuff like i18n and so on set up
and more. And then after seldom doing more than a trivial string
operation the process is terminated again. Of course, that has to
be incredibly slow. No other language but shell would do something like
that. On top of that, shell scripts are also very fragile, and
change their behaviour drastically based on environment variables
and suchlike, stuff that is hard to oversee and control.
So, let’s get rid of shell scripts in the boot process! Before
we can do that we need to figure out what they are currently
actually used for: well, the big picture is that most of the time,
what they do is actually quite boring. Most of the scripting is
spent on trivial setup and tear-down of services, and should be
rewritten in C, either in separate executables, or moved into the
daemons themselves, or simply be done in the init system.
It is not likely that we can get rid of shell scripts during
system boot-up entirely anytime soon. Rewriting them in C takes
time, in a few case does not really make sense, and sometimes
shell scripts are just too handy to do without. But we can
certainly make them less prominent.
A good metric for measuring shell script infestation of the
boot process is the PID number of the first process you can start
after the system is fully booted up. Boot up, log in, open a
terminal, and type echo $$. Try that on your Linux
system, and then compare the result with MacOS! (Hint, it’s
something like this: Linux PID 1823; MacOS PID 154, measured on
test systems we own.)
A central part of a system that starts up and maintains
services should be process babysitting: it should watch
services. Restart them if they shut down. If they crash it should
collect information about them, and keep it around for the
administrator, and cross-link that information with what is
available from crash dump systems such as abrt, and in logging
systems like syslog or the audit system.
It should also be capable of shutting down a service
completely. That might sound easy, but is harder than you
think. Traditionally on Unix a process that does double-forking
can escape the supervision of its parent, and the old parent will
not learn about the relation of the new process to the one it
actually started. An example: currently, a misbehaving CGI script
that has double-forked is not terminated when you shut down
Apache. Furthermore, you will not even be able to figure out its
relation to Apache, unless you know it by name and purpose.
So, how can we keep track of processes, so that they cannot
escape the babysitter, and that we can control them as one unit
even if they fork a gazillion times?
Different people came up with different solutions for this. I
am not going into much detail here, but let’s at least say that
approaches based on ptrace or the netlink connector (a kernel
interface which allows you to get a netlink message each time any
process on the system fork()s or exit()s) that some people have
investigated and implemented, have been criticised as ugly and not
very scalable.
So what can we do about this? Well, since quite a while the
kernel knows Control
Groups (aka “cgroups”). Basically they allow the creation of a
hierarchy of groups of processes. The hierarchy is directly
exposed in a virtual file-system, and hence easily accessible. The
group names are basically directory names in that file-system. If
a process belonging to a specific cgroup fork()s, its child will
become a member of the same group. Unless it is privileged and has
access to the cgroup file system it cannot escape its
group. Originally, cgroups have been introduced into the kernel
for the purpose of containers: certain kernel subsystems can
enforce limits on resources of certain groups, such as limiting
CPU or memory usage. Traditional resource limits (as implemented
by setrlimit()) are (mostly) per-process. cgroups on the
other hand let you enforce limits on entire groups of
processes. cgroups are also useful to enforce limits outside of
the immediate container use case. You can use it for example to
limit the total amount of memory or CPU Apache and all its
children may use. Then, a misbehaving CGI script can no longer
escape your setrlimit() resource control by simply
forking away.
In addition to container and resource limit enforcement cgroups
are very useful to keep track of daemons: cgroup membership is
securely inherited by child processes, they cannot escape. There’s
a notification system available so that a supervisor process can
be notified when a cgroup runs empty. You can find the cgroups of
a process by reading /proc/$PID/cgroup. cgroups hence
make a very good choice to keep track of processes for babysitting
purposes.
A good babysitter should not only oversee and control when a
daemon starts, ends or crashes, but also set up a good, minimal,
and secure working environment for it.
That means setting obvious process parameters such as the
setrlimit() resource limits, user/group IDs or the
environment block, but does not end there. The Linux kernel gives
users and administrators a lot of control over processes (some of
it is rarely used, currently). For each process you can set CPU
and IO scheduler controls, the capability bounding set, CPU
affinity or of course cgroup environments with additional limits,
and more.
As an example, ioprio_set() with
IOPRIO_CLASS_IDLE is a great away to minimize the effect
of locate‘s updatedb on system interactivity.
On top of that certain high-level controls can be very useful,
such as setting up read-only file system overlays based on
read-only bind mounts. That way one can run certain daemons so
that all (or some) file systems appear read-only to them, so that
EROFS is returned on every write request. As such this can be used
to lock down what daemons can do similar in fashion to a poor
man’s SELinux policy system (but this certainly doesn’t replace
SELinux, don’t get any bad ideas, please).
Finally logging is an important part of executing services:
ideally every bit of output a service generates should be logged
away. An init system should hence provide logging to daemons it
spawns right from the beginning, and connect stdout and stderr to
syslog or in some cases even /dev/kmsg which in many
cases makes a very useful replacement for syslog (embedded folks,
listen up!), especially in times where the kernel log buffer is
configured ridiculously large out-of-the-box.
To begin with, let me emphasize that I actually like the code
of Upstart, it is very well commented and easy to
follow. It’s certainly something other projects should learn
from (including my own).
That being said, I can’t say I agree with the general approach
of Upstart. But first, a bit more about the project:
Upstart does not share code with sysvinit, and its
functionality is a super-set of it, and provides compatibility to
some degree with the well known SysV init scripts. It’s main
feature is its event-based approach: starting and stopping of
processes is bound to “events” happening in the system, where an
“event” can be a lot of different things, such as: a network
interfaces becomes available or some other software has been
started.
Upstart does service serialization via these events: if the
syslog-started event is triggered this is used as an
indication to start D-Bus since it can now make use of Syslog. And
then, when dbus-started is triggered,
NetworkManager is started, since it may now use
D-Bus, and so on.
One could say that this way the actual logical dependency tree
that exists and is understood by the admin or developer is
translated and encoded into event and action rules: every logical
“a needs b” rule that the administrator/developer is aware of
becomes a “start a when b is started” plus “stop a when b is
stopped”. In some way this certainly is a simplification:
especially for the code in Upstart itself. However I would argue
that this simplification is actually detrimental. First of all,
the logical dependency system does not go away, the person who is
writing Upstart files must now translate the dependencies manually
into these event/action rules (actually, two rules for each
dependency). So, instead of letting the computer figure out what
to do based on the dependencies, the user has to manually
translate the dependencies into simple event/action rules. Also,
because the dependency information has never been encoded it is
not available at runtime, effectively meaning that an
administrator who tries to figure our why something
happened, i.e. why a is started when b is started, has no chance
of finding that out.
Furthermore, the event logic turns around all dependencies,
from the feet onto their head. Instead of minimizing the
amount of work (which is something that a good init system should
focus on, as pointed out in the beginning of this blog story), it
actually maximizes the amount of work to do during
operations. Or in other words, instead of having a clear goal and
only doing the things it really needs to do to reach the goal, it
does one step, and then after finishing it, it does all
steps that possibly could follow it.
Or to put it simpler: the fact that the user just started D-Bus
is in no way an indication that NetworkManager should be started
too (but this is what Upstart would do). It’s right the other way
round: when the user asks for NetworkManager, that is definitely
an indication that D-Bus should be started too (which is certainly
what most users would expect, right?).
A good init system should start only what is needed, and that
on-demand. Either lazily or parallelized and in advance. However
it should not start more than necessary, particularly not
everything installed that could use that service.
Finally, I fail to see the actual usefulness of the event
logic. It appears to me that most events that are exposed in
Upstart actually are not punctual in nature, but have duration: a
service starts, is running, and stops. A device is plugged in, is
available, and is plugged out again. A mount point is in the
process of being mounted, is fully mounted, or is being
unmounted. A power plug is plugged in, the system runs on AC, and
the power plug is pulled. Only a minority of the events an init
system or process supervisor should handle are actually punctual,
most of them are tuples of start, condition, and stop. This
information is again not available in Upstart, because it focuses
in singular events, and ignores durable dependencies.
Now, I am aware that some of the issues I pointed out above are
in some way mitigated by certain more recent changes in Upstart,
particularly condition based syntaxes such as start on
(local-filesystems and net-device-up IFACE=lo) in Upstart
rule files. However, to me this appears mostly as an attempt to
fix a system whose core design is flawed.
Besides that Upstart does OK for babysitting daemons, even though
some choices might be questionable (see above), and there are certainly a lot
of missed opportunities (see above, too).
There are other init systems besides sysvinit, Upstart and
launchd. Most of them offer little substantial more than Upstart or
sysvinit. The most interesting other contender is Solaris SMF,
which supports proper dependencies between services. However, in
many ways it is overly complex and, let’s say, a bit academic
with its excessive use of XML and new terminology for known
things. It is also closely bound to Solaris specific features such
as the contract system.
Well, this is another good time for a little pause, because
after I have hopefully explained above what I think a good PID 1
should be doing and what the current most used system does, we’ll
now come to where the beef is. So, go and refill you coffee mug
again. It’s going to be worth it.
You probably guessed it: what I suggested above as requirements
and features for an ideal init system is actually available now,
in a (still experimental) init system called systemd, and
which I hereby want to announce. Again, here’s the
code. And here’s a quick rundown of its features, and the
rationale behind them:
systemd starts up and supervises the entire system (hence the
name…). It implements all of the features pointed out above and
a few more. It is based around the notion of units. Units
have a name and a type. Since their configuration is usually
loaded directly from the file system, these unit names are
actually file names. Example: a unit avahi.service is
read from a configuration file by the same name, and of course
could be a unit encapsulating the Avahi daemon. There are several
kinds of units:
All these units can have dependencies between each other (both
positive and negative, i.e. ‘Requires’ and ‘Conflicts’): a device
can have a dependency on a service, meaning that as soon as a
device becomes available a certain service is started. Mounts get
an implicit dependency on the device they are mounted from. Mounts
also gets implicit dependencies to mounts that are their prefixes
(i.e. a mount /home/lennart implicitly gets a dependency
added to the mount for /home) and so on.
A short list of other features:
It should be noted that systemd uses many Linux-specific
features, and does not limit itself to POSIX. That unlocks a lot
of functionality a system that is designed for portability to
other operating systems cannot provide.
All the features listed above are already implemented. Right
now systemd can already be used as a drop-in replacement for
Upstart and sysvinit (at least as long as there aren’t too many
native upstart services yet. Thankfully most distributions don’t
carry too many native Upstart services yet.)
However, testing has been minimal, our version number is
currently at an impressive 0. Expect breakage if you run this in
its current state. That said, overall it should be quite stable
and some of us already boot their normal development systems with
systemd (in contrast to VMs only). YMMV, especially if you try
this on distributions we developers don’t use.
The feature set described above is certainly already
comprehensive. However, we have a few more things on our plate. I
don’t really like speaking too much about big plans but here’s a
short overview in which direction we will be pushing this:
We want to add at least two more unit types: swap
shall be used to control swap devices the same way we
already control mounts, i.e. with automatic dependencies on the
device tree devices they are activated from, and
suchlike. timer shall provide functionality similar to
cron, i.e. starts services based on time events, the
focus being both monotonic clock and wall-clock/calendar
events. (i.e. “start this 5h after it last ran” as well as “start
this every monday 5 am”)
More importantly however, it is also our plan to experiment with
systemd not only for optimizing boot times, but also to make it
the ideal session manager, to replace (or possibly just augment)
gnome-session, kdeinit and similar daemons. The problem set of a
session manager and an init system are very similar: quick start-up
is essential and babysitting processes the focus. Using the same
code for both uses hence suggests itself. Apple recognized that
and does just that with launchd. And so should we: socket and bus
based activation and parallelization is something session services
and system services can benefit from equally.
I should probably note that all three of these features are
already partially available in the current code base, but not
complete yet. For example, already, you can run systemd just fine
as a normal user, and it will detect that is run that way and
support for this mode has been available since the very beginning,
and is in the very core. (It is also exceptionally useful for
debugging! This works fine even without having the system
otherwise converted to systemd for booting.)
However, there are some things we probably should fix in the
kernel and elsewhere before finishing work on this: we
need swap status change notifications from the kernel similar to
how we can already subscribe to mount changes; we want a
notification when CLOCK_REALTIME jumps relative to
CLOCK_MONOTONIC; we want to allow normal processes to get
some init-like powers; we need a well-defined
place where we can put user sockets. None of these issues are
really essential for systemd, but they’d certainly improve
things.
Currently, there are no tarball releases, but it should be
straightforward to check out the code from our
repository. In addition, to have something to start with, here’s
a tarball with unit configuration files that allows an
otherwise unmodified Fedora 13 system to work with systemd. We
have no RPMs to offer you for now.
An easier way is to download this Fedora 13 qemu image, which
has been prepared for systemd. In the grub menu you can select
whether you want to boot the system with Upstart or systemd. Note
that this system is minimally modified only. Service information
is read exclusively from the existing SysV init scripts. Hence it
will not take advantage of the full socket and bus-based
parallelization pointed out above, however it will interpret the
parallelization hints from the LSB headers, and hence boots faster
than the Upstart system, which in Fedora does not employ any
parallelization at the moment. The image is configured to output
debug information on the serial console, as well as writing it to
the kernel log buffer (which you may access with dmesg).
You might want to run qemu configured with a virtual
serial terminal. All passwords are set to systemd.
Even simpler than downloading and booting the qemu image is
looking at pretty screen-shots. Since an init system usually is
well hidden beneath the user interface, some shots of
systemadm and ps must do:

That’s systemadm showing all loaded units, with more detailed
information on one of the getty instances.

That’s an excerpt of the output of ps xaf -eo
pid,user,args,cgroup showing how neatly the processes are
sorted into the cgroup of their service. (The fourth column is the
cgroup, the debug: prefix is shown because we use the
debug cgroup controller for systemd, as mentioned earlier. This is
only temporary.)
Note that both of these screenshots show an only minimally
modified Fedora 13 Live CD installation, where services are
exclusively loaded from the existing SysV init scripts. Hence,
this does not use socket or bus activation for any existing
service.
Sorry, no bootcharts or hard data on start-up times for the
moment. We’ll publish that as soon as we have fully parallelized
all services from the default Fedora install. Then, we’ll welcome
you to benchmark the systemd approach, and provide our own
benchmark data as well.
Well, presumably everybody will keep bugging me about this, so
here are two numbers I’ll tell you. However, they are completely
unscientific as they are measured for a VM (single CPU) and by
using the stop timer in my watch. Fedora 13 booting up with
Upstart takes 27s, with systemd we reach 24s (from grub to gdm,
same system, same settings, shorter value of two bootups, one
immediately following the other). Note however that this shows
nothing more than the speedup effect reached by using the LSB
dependency information parsed from the init script headers for
parallelization. Socket or bus based activation was not utilized
for this, and hence these numbers are unsuitable to assess the
ideas pointed out above. Also, systemd was set to debug verbosity
levels on a serial console. So again, this benchmark data has
barely any value.
An ideal daemon for use with systemd does a few things
differently then things were traditionally done. Later on, we will
publish a longer guide explaining and suggesting how to write a daemon for use
with this systemd. Basically, things get simpler for daemon
developers:
The list above is very similar to what Apple
recommends for daemons compatible with launchd. It should be
easy to extend daemons that already support launchd
activation to support systemd activation as well.
Note that systemd supports daemons not written in this style
perfectly as well, already for compatibility reasons (launchd has
only limited support for that). As mentioned, this even extends to
existing inetd capable daemons which can be used unmodified for
socket activation by systemd.
So, yes, should systemd prove itself in our experiments and get
adopted by the distributions it would make sense to port at least
those services that are started by default to use socket or
bus-based activation. We have
written proof-of-concept patches, and the porting turned out
to be very easy. Also, we can leverage the work that has already
been done for launchd, to a certain extent. Moreover, adding
support for socket-based activation does not make the service
incompatible with non-systemd systems.
We are very interested in patches and help. It should be common
sense that every Free Software project can only benefit from the
widest possible external contributions. That is particularly true
for a core part of the OS, such as an init system. We value your
contributions and hence do not require copyright assignment (Very
much unlike Canonical/Upstart!). And also, we use git,
everybody’s favourite VCS, yay!
We are particularly interested in help getting systemd to work
on other distributions, besides Fedora and OpenSUSE. (Hey, anybody
from Debian, Gentoo, Mandriva, MeeGo looking for something to do?)
But even beyond that we are keen to attract contributors on every
level: we welcome C hackers, packagers, as well as folks who are interested
to write documentation, or contribute a logo.
At this time we only have source code
repository and an IRC channel (#systemd on
Freenode). There’s no mailing list, web site or bug tracking
system. We’ll probably set something up on freedesktop.org
soon. If you have any questions or want to contact us otherwise we
invite you to join us on IRC!
Update: our GIT repository has moved.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/bloom.html
For future reference (mostly for myself), here’s a little summary of how to
use Bloom filters in
real world applications.
Most references are terse and vague on how to pick the hash functions for
bloom filters, so here’s some detail about that: For small filters, just use a
boring and fast hash function like the djb hash
function and split up the 32bit result into smaller independent chunks for
each of the k hash indexes you’ll need. Often those 32 bits already provide
enough hash bits to get enough independent bloom filter indexes. And if they
don’t you basically have three options:
The size of the bloom filter and the number of hash functions you should be
using depending on your application can be calculated using the formulas on the
Wikipedia page:
m = -n*ln(p)/(ln(2)^2)
This will tell you the number of bits m to use for your filter, given the
number n of elements in your filter and the false positive probability p you
want to achieve. All that for the ideal number of hash functions k which you
can calculate like this:
k = 0.7*m/n
And that’s already everything you need to know to build good bloom filters.
If you know the p and n for your use case the above will tell you the m and k, and
how to choose the k hash functions.
Bloom filters are a really really useful tool, and given their simplicity
something every developer should be aware of.
(And in case you were wondering what this all is about, Kay Sievers and I
were discussing using bloom filters in the libudev netlink BSD socket filters,
to allow monitoring a certain subset of devices that is orthogonal to the usual
subsystem hierarchy, and all that in a way where the number of wakeups in
listening clients is minimized)
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/beware-of-rsvg-term.html
As a short followup on an older blog posting of mine:
So you are using librsvg’s rsvg_term() in your code? If so then
you are probably misusing it and triggering crashes in PulseAudio related code.
The same way everybody should stop using libxml2’s xmlCleanupParser()
call, stop using rsvg_term()! It’s really hard to use it correctly,
and uneeded anyway. Also see this bug
report.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/bossa2010.html
The slides for my talk about the audio infrastructure of Linux mobile
devices at BOSSA 2010 in Manaus/Brazil are now available
online. They are terse (as usual), and the most interesting stuff is
probably in what I said, and not so much in what I wrote in those slides. But
nonetheless I believe this might still be quite interesting for attendees as
well as non-attendees.
The talk focuses on the audio architecture of the Nokia N900 and the Palm
Pre, and of course particularly their use of PulseAudio for all things audio. I analyzed
and compared their patch sets to figure out what their priorities are, what we
should move into PulseAudio mainline, and what should better be left in their
private patch sets.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/decibel-data.html
#nocomments y
In recent versions PulseAudio
integrates the numerous mixer
elements ALSA exposes into one single powerful slider which tries to make
the best of the granularity and range of the hardware and extends that in
software so that we can provide an equally powerful slider on all systems.
That means if your hardware only supports a limited volume range (many
integrated USB speakers for example cannot be completely muted with the
hardware volume slider), limited granularity (some hardware sliders only have 8
steps or so), or no per-channel volumes (many sound cards have a single slider
that covers all channels), then PulseAudio tries its best to make use of the
next hardware volume slider in the pipeline to compensate for that, and so on,
finally falling back to software for everything that cannot be done in
hardware. This is
explained in more detail here.
Now this algorithm depends on that we know the actual attenuation factors
(factors like that are usually written in units of dB which is why I will call
this the “dB data” from now on) of the hardware volume controls. Thankfully
ALSA includes that information in its driver interfaces. However for some
hardware this data is not reliable. For example, one of my own cards (a
Terratec Aureon 5.1 MkII USB) contains invalid dB data in its USB descriptor
and ALSA passes that on to PulseAudio. The effect of that is that the
PulseAudio volume control behaves very weirdly for this card, in a way that the
volume “jumps” and changes in unexpected ways (or doesn’t change at all in some
ranges!) when you slowly move the slider, or that the volume is completely
muted over large ranges of the slider where it should not be. Also this breaks the
flat volume logic in PulseAudo, to the result that playing one stream
(let’s say a music stream) and then adding a second one (let’s say an event
sound) might incorrectly attenuate the first one (i.e. whenever you play an
event sound the music changes in volume).
Incorrect dB data is not a new problem. However PulseAudio is the first
application that actually depends on the correctness of this data. Previously
the dB info was shown as auxiliary information in some volume controls, and
only noticed and understood by very few, technical people. It was not used for
further calculations.
Now, the reasons I am writing this blog posting are firstly to inform you
about this type of bug and the results it has on the logic PulseAudio
implements, and secondly (and more importantly) to point you to this little Wiki page I wrote
that explains how to verify if this is indeed a problem on your card (in case
you are experiencing any of the symptoms mentioned above) and secondly what to
do to improve the situation, and how to get correct dB data that can be
included as quirk in your driver.
Thank you for your attention.
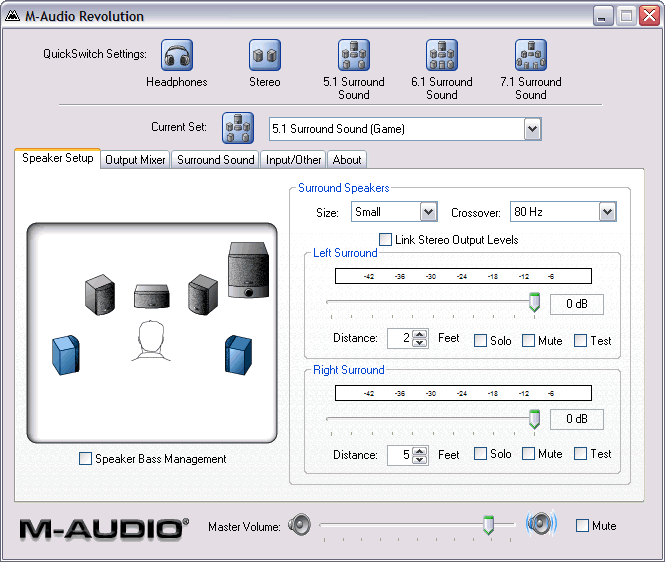
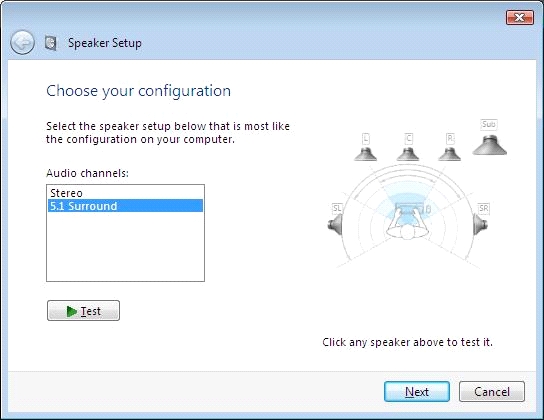
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/speaker-setup.html
While tracking down some surround sound related bugs I was missing a speaker
setup and testing utility. So I decided to do something about it and I present you gnome-speaker-setup:

The tool should be very robust and even deal with the weirdest channel
mappings. OTOH the artwork is not really good and appropriate. But I hope it still shows some resemblance to other
UIs
of this type. If you are an artist wand want to contribute better artwork make
sure to go through the Gnome Art Requests page,
and more specifically this particular
request.
This (or something like it) will hopefully and eventually end up in some way
or another in gnome-media. Until that day comes I’ll maintain this tool independently.
To compile this you need a recent Vala and libcanberra
0.23.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/udev-browse.html
It’s easy to get lost in /sys and not much fun typing long
udevadm info command lines all the time. Today, when I had enough of
that I sat down and spent an hour to write a little UI for exploring the
udev/sysfs tree: udev-browse. I wrote it for my own use, but I am quite sure I am not the only
one who wants a little bit simpler access to the device tree. So here you go.
And since everybody loves screenshots here you go:

Two usability hints: if you run udev-browse from a directory in
/sys udev-browse will automatically present the device of
that path on startup. And if you know the name of a device you can just type it
into the device listbox (which is focussed by default). The usual Gtk+ live
search will then find you the right entry right-away. It’s pretty nifty.
It’s written in Vala with minimal dependencies.
I want to keep the maintainership burden for this minimal. So no tarballs, no releases, and I won’t reply to your emails regarding this tool, unless they include a good, clean, git formatted patch. Thank you for your understanding.
Anyone wants to package this for Fedora? I’d be very thankful if someone would pick it up.
Have fun.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/beware-of-xmlCleanupParser.html
Everyone and his dog seem to call libxml2’s xmlCleanupParser() at
inappropriate places. For example Empathy does it,
and Abiword does it too. Google Code Search seems to reveal at least Inkscape and Dia
do it as well.
So, please, if your project links against libxml2 verify that it calls
xmlCleanupParser() only once, and right before exiting! And if it calls it more
often or somewhere else, then please fix that!
For more information see
my post on fedora-devel.
Thanks for your time.
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/on-oom.html
Building on what Havoc
wrote two years ago about the fallacies of OOM safety (Out Of Memory) in user code I’d
like to point you to this little mail
I just posted to jack-devel which tries to give you the bigger picture.
Should be interesting for non-audio folks, too.
Say NO to OOM safety!
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/no-more-dmidecode.html
Folks! Since quite some time now the kernel exports the DMI machine
information below /sys/class/dmi/id/. You may stop now parsing the
output of dmidecode thus depending on external tools and privileged
code.
For example, to read your BIOS vendor string all you need to do is this:
$ read bv < /sys/class/dmi/id/bios_vendor $ echo $bv
Which is of course much simpler, and cleaner, and safer than anything involving dmidecode.
Thank you for your time!
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/pa-in-ubuntu.html
#nocomments yes
<rant>
So in the past Ubuntu packaged PA in a way that, let’s say, was not
exactly optimal. I thought they’d gotten around fixing things since then. Turns
out they didn’t. Seems in their upcoming release they again did some genius
thing to make PA on Ubuntu perform worse than it could. The Ubuntu kernel
contains all kind of closed-source and other crap to no limits, but backporting
a tiny patch that is blessed and merged upstream and in Fedora for ages, that
they won’t do. Gah.
And it doesn’t stop there. This
patch is an outright insult. This
is disappointing.
Madness. Not good, Ubuntu, really not good! And I’ll get all the
complaints for this f**up again. Thanks!
/me is disappointed. Ubuntu, you really can do better than this.
</rant>
Post Syndicated from Lennart Poettering original https://0pointer.net/blog/projects/win7-plays-catchup.html
#nocomments y
Kinda fun watching
this video. As it seems the big new features of the Windows 7 audio stack are the
ability to move streams while they are live, to do role-based policy routing,
and to pause streams during phone calls. Hah! That’s so yesterday! A certain sound server I happen to know very
well has been supporting this for a longer time already, and you can even
buy that logic in various consumer
products.
Nice to know that in some areas of the audio stack it’s not us who need to
play catch-up with them, but they are the ones who need to play catch-up with
us.
{kind=link}
{kind=link}
{kind=link}