Post Syndicated from Guest Author original https://blog.cloudflare.com/exploring-webassembly-ai-services-on-cloudflare-workers/
This is a guest post by Videet Parekh, Abelardo Lopez-Lagunas, Sek Chai at Latent AI.
Edge networks present a significant opportunity for Artificial Intelligence (AI) performance and applicability. AI technologies already make it possible to run compelling applications like object and voice recognition, navigation, and recommendations.
AI at the edge presents a host of benefits. One is scalability—it is simply impractical to send all data to a centralized cloud. In fact, one study has predicted a global scope of 90 zettabytes generated by billions of IoT devices by 2025. Another is privacy—many users are reluctant to move their personal data to the cloud, whereas data processed at the edge are more ephemeral.
When AI services are distributed away from centralized data centers and closer to the service edge, it becomes possible to enhance the overall application speed without moving data unnecessarily. However, there are still challenges to make AI from the deep-cloud run efficiently on edge hardware. Here, we use the term deep-cloud to refer to highly centralized, massively-sized data centers. Deploying edge AI services can be hard because AI is both computational and memory bandwidth intensive. We need to tune the AI models so the computational latency and bandwidth can be radically reduced for the edge.
The Case for Distributed AI Services
Edge network infrastructure for distributed AI is already widely available. Edge networks like Cloudflare serve a significant proportion of today’s Internet traffic, and can serve as the bridge between devices and the centralized cloud. Highly-performant AI services are possible because of the distributed processing that has excellent spatial proximity to the edge data.
We at Latent AI are exploring ways to deploy AI at the edge, with technology that transforms and compresses AI models for the edge. The size of our edge AI model is many orders of magnitudes smaller than the sensor data (e.g., kilobytes or megabytes for the edge AI model, compared to petabytes of edge data). We are exploring using WebAssembly (WASM) within the Cloudflare Workers environment. We want to identify possible operating points for the distributed AI services by exploring achievable performance on the available edge infrastructure.
Architectural Approach for Exploration
WebAssembly (WASM) is a new open-standard format for programs that run on the Web. It is a popular way to enable high-performance web-based applications. WASM is closer to machine code, and thus faster than JavaScript (JS) or JIT. Compiler optimizations, already done ahead of time, reduce the overhead in fetching and parsing application code. Today, WASM offers the flexibility and portability of JS at the near-optimum performance of compiled machine code.
AI models have notoriously large memory usage demands because configuring them requires high parameter counts. Cloudflare already extends support for WASM using their Wrangler CLI, and we chose to use it for our exploration. Wrangler is the open-source CLI tool used to manage Workers, and is designed to enable a smooth developer experience.
How Latent AI Accelerates Distributed AI Services
Latent AI’s mission is to enable ambient computing, regardless of any resource constraints. We develop developer tools that greatly reduce the computing resources needed to process AI on the edge while being completely hardware-agnostic.
Latent AI’s tools significantly compress AI models to reduce their memory size. We have shown up to 10x compression for state-of-the-art models. This capability addresses the load time latencies challenging many edge network deployments. We also offer an optimized runtime that executes a neural network natively. Results are a 2-3x speedup on runtime without any hardware-specific accelerators. This dramatic performance boost offers fast and efficient inferences for the edge.
Our compression uses quantization algorithms to convert parameters for the AI model from 32-bit floating-point toward 16-bit or 8-bit models, with minimal loss of accuracy. The key benefit of moving to lower bit-precision is the higher power efficiency with less storage needed. Now AI inference can be processed using more efficient parallel processor hardware on the continuum of platforms at the distributed edge.

Selecting Real-World WASM Neural Network Examples
For our exploration, we use state-of-the-art deep neural networks called MobileNet. MobileNets are designed specifically for embedded platforms such as smartphones, and can achieve high recognition accuracy in visual object detection. We compress MobileNets AI models to be small fast, in order to represent the variety of use cases that can be deployed as distributed AI services. Please see this blog for more details on the AI model architecture.
We use the MobileNetV2 model variant for our exploration. The models are trained with different visual objects that can be detected: (1) a larger sized model with 10 objects derived from ImageNet dataset, and (2) a smaller version with just two classes derived from the COCO dataset. The COCO dataset are public open-source databases of images that are used as benchmarks for AI models. Images are labeled with detected objects such as persons, vehicles, bicycles, traffic lights, etc. Using Latent AI’s compression tool, we were able to compress and compile the MobileNetV2 models into WASM programs. In the WASM form, we can achieve fast and efficient processing of the AI model with a small storage footprint.
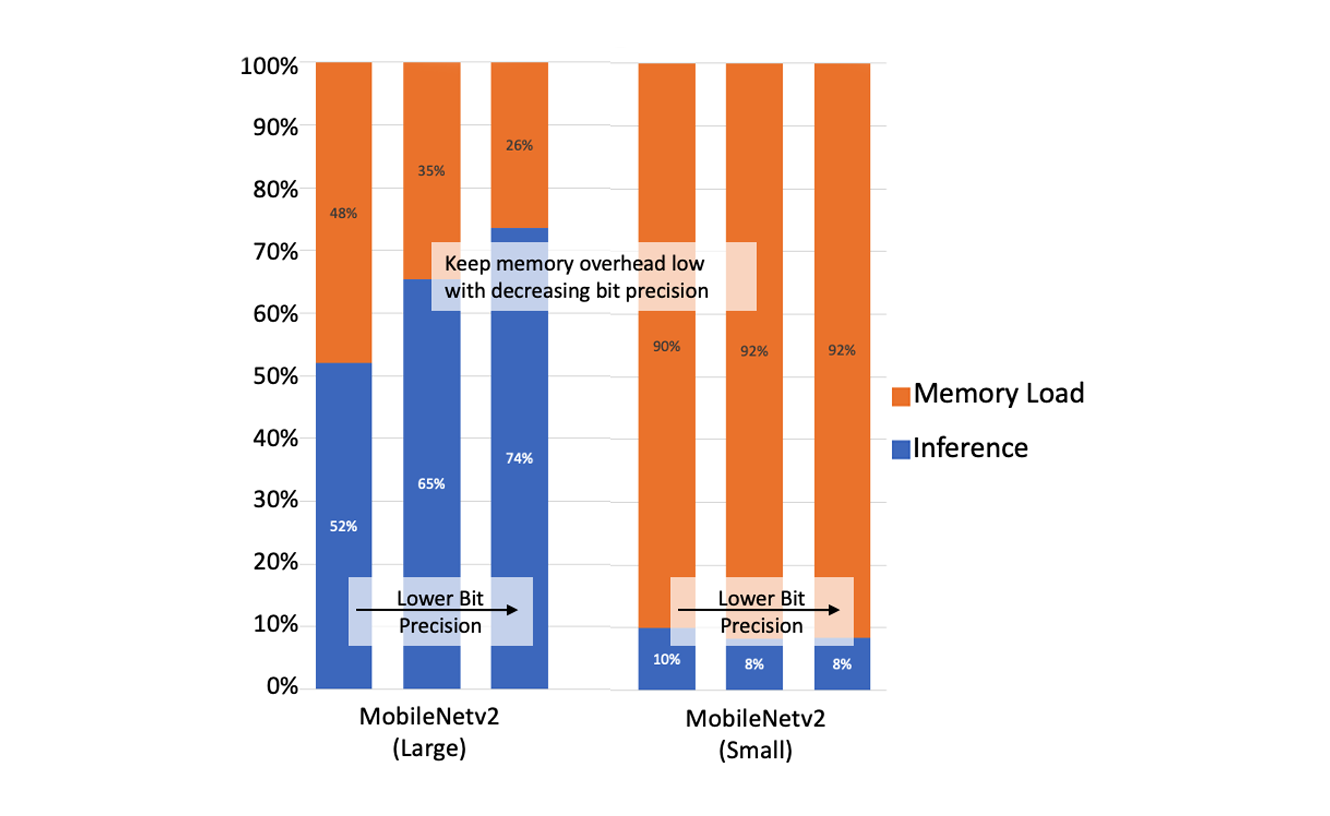
We want WASM neural networks to be as fast and efficient as possible. We spun up a Workers app to accept an image from a client, convert and preprocess the image into a cleaned data array, run it through the model and then return a class for that image. For both the large and small MobileNetv2 models, we create three variants with different bit-precision (32-bit floating point, 16-bit integer, and 8-bit integer). The average memory and inference times for the large AI model are 110ms and 189ms, respectively; And for the smaller AI model, they are 159ms and 15ms, respectively.
Our analysis suggests that overall processing can be improved by reducing the overhead for memory operations. For the large model, lowering bit precision to 8-bits reduces memory operations from 48% to 26%. For the small model, the memory load times dominate over the inference computation with over 90% of the latency in memory operations.
It is important to note that our results are based on our initial exploration, which is focused more on functionality rather than optimization. We make sure the results are consistent by averaging our measurements over 50-100 iterations. We do acknowledge that there are still network and system related latencies that can be further optimized, but we believe that the early results described here show promise with respect to AI model inferences on the distributed edge.
Learning from Real-World WASM Neural Network Example
What lessons can we draw from our example use case?
First of all, we recommend a minimal compute and memory footprint for AI models deployed to the network edge. A small footprint allows for better line up of data types for WASM AI models to reduce memory load overhead. WASM practitioners know that WASM speed-ups come from the tighter coupling of the API between JavaScript API and native machine code. Because WASM code does not need to speculate on data types, parallelizing compilation for WASM can achieve better optimization.
Furthermore, we encourage the use of running AI models at 8-bit precision to reduce the overall size. These 8-bit AI models are readily compressed and compiled for the target hardware to greatly reduce the overhead in hosting the models for inference. Furthermore, for video imagery, there is no overhead to convert digitized raw data (e.g. image files digitized and stored as integers) to floating-point values for use with floating point AI models.
Finally, we suggest the use of a smart cache for AI models so that Workers can essentially reduce memory load times and focus solely on neural network inferences at runtime. Again, 8-bit models allow more AI models to be hosted and ready for inference. Referring to our exploratory results, hosted small AI models can be served at approximately 15ms inference time, offering a very compelling user experience with low latency and local processing. The WASM API provides a significant performance increase over pure-JS toolchains like Tensorflow.js. For example, for inference time for the large AI model of 189ms on WASM, we have observed a range of 1500ms on Tensorflow.js workflow, which is approximately an 8X difference in compute latency.
Unlocking the Future of the Distributed Edge
With exceedingly optimized WASM neural networks, distributed edge networks can move the inference closer to users, offering new edge AI services closer to the source of the data. With Latent AI technology to compress and compile WASM neural networks, the distributed edge networks can (1) host more models, (2) offer lower latency responses, and (3) potentially lower power utilization with more efficient computing.

Imagine for example that the small AI model described earlier can distinguish if a person is in a video feed. Digital systems, e.g. door bell and doorway entry cameras, can hook up to Cloudflare Workers to verify if a person is present in the camera field of view. Similarly, other AI services could conduct sound analyses to check for broken windows and water leaks. With these distributed AI services, applications can run without access to deep cloud services. Furthermore, the sensor platform can be made with ultra low cost, low power hardware, in very compact form factors.
Application developers can now offer AI services with neural networks trained, compressed, and compiled natively as a WASM neural network. Latent AI developer tools can compress WASM neural networks and provide WASM runtimes offering blazingly fast inferences for the device and infrastructure edge. With scale and speed baked in, developers can easily create high-performance experiences for their users, wherever they are, at any scale. More importantly, we can scale enterprise applications on the edge, while offering the desired return on investments using edge networks.
About Latent AI
Latent AI is an early-stage venture spinout of SRI International. Our mission is to enable developers and change the way we think about building AI for the edge. We develop software tools designed to help companies add AI to edge devices and to empower users with new smart IoT applications. For more information about the availability of LEIP SDK, please feel free to contact us at [email protected] or check out our website.