Post Syndicated from Guest Author original https://blog.cloudflare.com/guest-blog-zero-trust-access-kubernetes/


Today, we’re excited to publish a blog post written by our friends at Kudelski Security, a managed security services provider. A few weeks back, Romain Aviolat, the Principal Cloud and Security Engineer at Kudelski Security approached our Zero Trust team with a unique solution to a difficult problem that was powered by Cloudflare’s Identity-aware Proxy, which we call Cloudflare Tunnel, to ensure secure application access in remote working environments.
We enjoyed learning about their solution so much that we wanted to amplify their story. In particular, we appreciated how Kudelski Security’s engineers took full advantage of the flexibility and scalability of our technology to automate workflows for their end users. If you’re interested in learning more about Kudelski Security, check out their work below or their research blog.
Zero Trust Access to Kubernetes
Over the past few years, Kudelski Security’s engineering team has prioritized migrating our infrastructure to multi-cloud environments. Our internal cloud migration mirrors what our end clients are pursuing and has equipped us with expertise and tooling to enhance our services for them. Moreover, this transition has provided us an opportunity to reimagine our own security approach and embrace the best practices of Zero Trust.
So far, one of the most challenging facets of our Zero Trust adoption has been securing access to our different Kubernetes (K8s) control-plane (APIs) across multiple cloud environments. Initially, our infrastructure team struggled to gain visibility and apply consistent, identity-based controls to the different APIs associated with different K8s clusters. Additionally, when interacting with these APIs, our developers were often left blind as to which clusters they needed to access and how to do so.
To address these frictions, we designed an in-house solution leveraging Cloudflare to automate how developers could securely authenticate to K8s clusters sitting across public cloud and on-premise environments. Specifically, for a given developer, we can now surface all the K8s services they have access to in a given cloud environment, authenticate an access request using Cloudflare’s Zero Trust rules, and establish a connection to that cluster via Cloudflare’s Identity-aware proxy, Cloudflare Tunnel.
Most importantly, this automation tool has enabled Kudelski Security as an organization to enhance our security posture and improve our developer experience at the same time. We estimate that this tool saves a new developer at least two hours of time otherwise spent reading documentation, submitting IT service tickets, and manually deploying and configuring the different tools needed to access different K8s clusters.
In this blog, we detail the specific pain points we addressed, how we designed our automation tool, and how Cloudflare helped us progress on our Zero Trust journey in a work-from-home friendly way.
Challenges securing multi-cloud environments
As Kudelski Security has expanded our client services and internal development teams, we have inherently expanded our footprint of applications within multiple K8s clusters and multiple cloud providers. For our infrastructure engineers and developers, the K8s cluster API is a crucial entry point for troubleshooting. We work in GitOps and all our application deployments are automated, but we still frequently need to connect to a cluster to pull logs or debug an issue.
However, maintaining this diversity creates complexity and pressure for infrastructure administrators. For end users, sprawling infrastructure can translate to different credentials, different access tools for each cluster, and different configuration files to keep track of.
Such a complex access experience can make real-time troubleshooting particularly painful. For example, on-call engineers trying to make sense of an unfamiliar K8s environment may dig through dense documentation or be forced to wake up other colleagues to ask a simple question. All this is error-prone and a waste of precious time.
Common, traditional approaches of securing access to K8s APIs presented challenges we knew we wanted to avoid. For example, we felt that exposing the API to the public internet would inherently increase our attack surface, that’s a risk we couldn’t afford. Moreover, we did not want to provide broad-based access to our clusters’ APIs via our internal networks and condone the risks of lateral movement. As Kudelski continues to grow, the operational costs and complexity of deploying VPNs across our workforce and different cloud environments would lead to scaling challenges as well.
Instead, we wanted an approach that would allow us to maintain small, micro-segmented environments, small failure domains, and no more than one way to give access to a service.
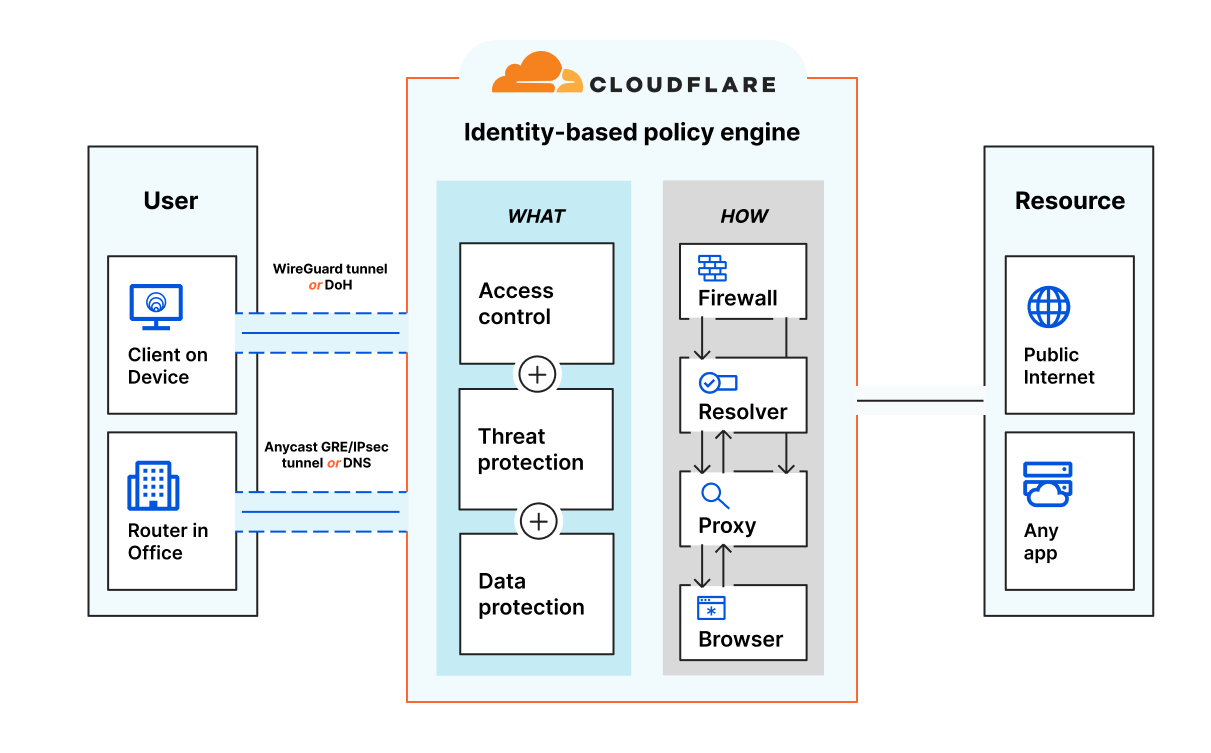
Leveraging Cloudflare’s Identity-aware Proxy for Zero Trust access
To do this, Kudelski Security’s engineering team opted for a more modern approach: creating connections between users and each of our K8 clusters via an Identity-aware proxy (IAP). IAPs are flexible to deploy and add an additional layer of security in front of our applications by verifying the identity of a user when an access request is made. Further, they support our Zero Trust approach by creating connections from users to individual applications — not entire networks.
Each cluster has its own IAP and its own sets of policies, which check for identity (via our corporate SSO) and other contextual factors like the device posture of a developer’s laptop. The IAP doesn’t replace the K8s cluster authentication mechanism, it adds a new one on top of it, and thanks to identity federation and SSO this process is completely transparent for our end users.
In our setup, Kudelski Security is using Cloudflare’s IAPs as a component of Cloudflare Access — a ZTNA solution and one of several security services unified by Cloudflare’s Zero Trust platform.
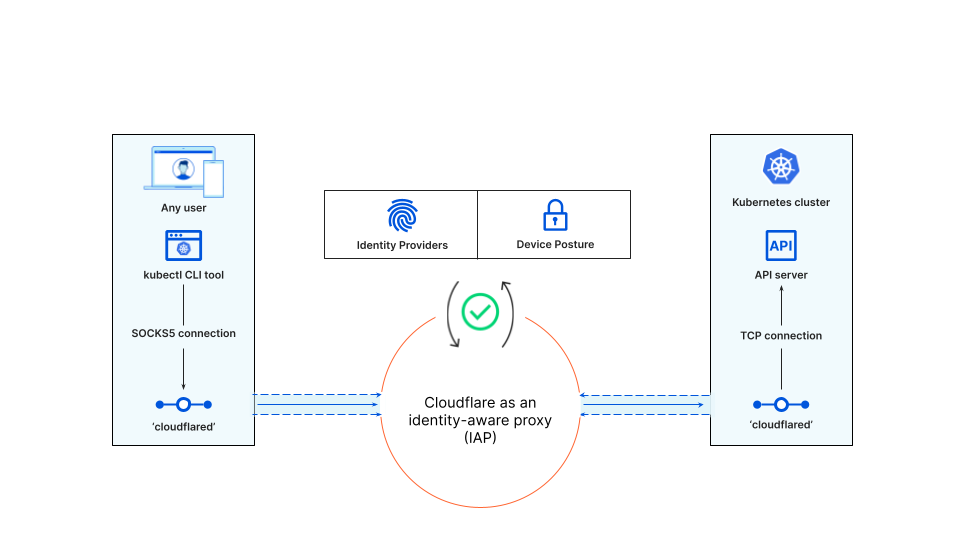
For many web-based apps, IAPs help create a frictionless experience for end users requesting access via a browser. Users authenticate via their corporate SSO or identity provider before reaching the secured app, while the IAP works in the background.
That user flow looks different for CLI-based applications because we cannot redirect CLI network flows like we do in a browser. In our case, our engineers want to use their favorite K8s clients which are CLI-based like kubectl or k9s. This means our Cloudflare IAP needs to act as a SOCKS5 proxy between the CLI client and each K8s cluster.
To create this IAP connection, Cloudflare provides a lightweight server-side daemon called cloudflared that connects infrastructure with applications. This encrypted connection runs on Cloudflare’s global network where Zero Trust policies are applied with single-pass inspection.
Without any automation, however, Kudelski Security’s infrastructure team would need to distribute the daemon on end user devices, provide guidance on how to set up those encrypted connections, and take other manual, hands-on configuration steps and maintain them over time. Plus, developers would still lack a single pane of visibility across the different K8s clusters that they would need to access in their regular work.
Our automated solution: k8s-tunnels!
To solve these challenges, our infrastructure engineering team developed an internal tool — called ‘k8s-tunnels’ — that embeds complex configuration steps which make life easier for our developers. Moreover, this tool automatically discovers all the K8s clusters that a given user has access to based on the Zero Trust policies created. To enable this functionality, we embedded the SDKs of some major public cloud providers that Kudelski Security uses. The tool also embeds the cloudflared daemon, meaning that we only need to distribute a single tool to our users.
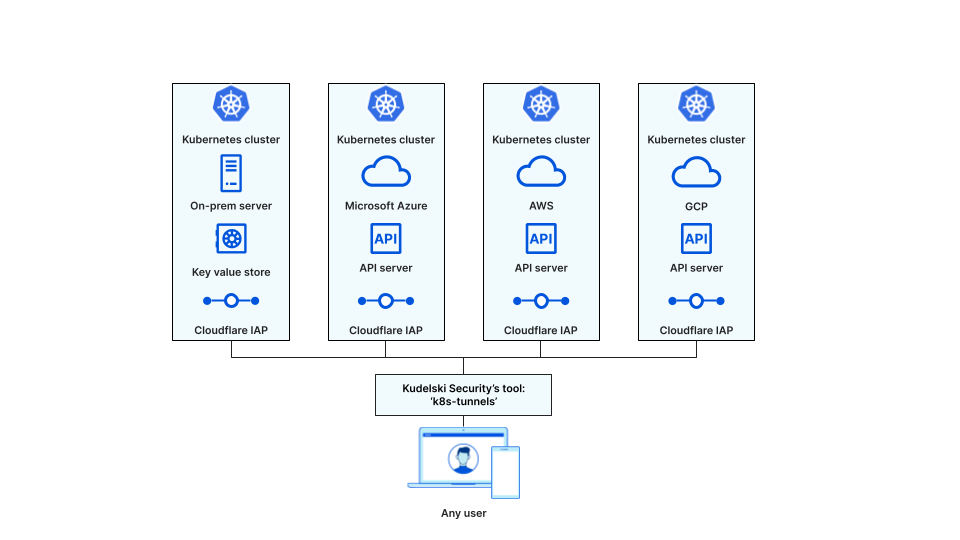
All together, a developer who launches the tool goes through the following workflow: (we assume that the user already has valid credentials otherwise the tool would open a browser on our IDP to obtain them)
1. The user selects one or more cluster to

2. k8s-tunnel will automatically open the connection with Cloudflare and expose a local SOCKS5 proxy on the developer machine
3. k8s-tunnel amends the user local kubernetes client configuration by pushing the necessary information to go through the local SOCKS5 proxy
4. k8s-tunnel switches the Kubernetes client context to the current connection

5. The user can now use his/her favorite CLI client to access the K8s cluster
The whole process is really straightforward and is being used on a daily basis by our engineering team. And, of course, all this magic is made possible through the auto-discovery mechanism we’ve built into k8s-tunnels. Whenever new engineers join our team, we simply ask them to launch the auto-discovery process and get started.
Here is an example of the auto-discovery process in action.
- k8s-tunnels will connect to our different cloud providers APIs and list the K8s clusters the user has access to
- k8s-tunnels will maintain a local config file on the user machine of those clusters so this process does not be run more than once

Automation enhancements
For on-premises deployments, it was a bit trickier as we didn’t have a simple way to store the K8s clusters metadata like we do with resource tags with public cloud providers. We decided to use Vault as a Key-Value-store to mimic public-cloud resource tags for on-prem. This way we can achieve auto-discovery of on-prem clusters following the same process as with a public-cloud provider.
Maybe you saw that in the previous CLI screenshot, the user can select multiple clusters at the same time! We quickly realized that our developers often needed to access multiple environments at the same time to compare a workload running in production and in staging. So instead of opening and closing tunnels every time they needed to switch clusters, we designed our tool such that they can now simply open multiple tunnels in parallel within a single k8s-tunnels instance and just switch the destination K8s cluster on their laptop.
Last but not least, we’ve also added the support for favorites and notifications on new releases, leveraging Cloudflare Workers, but that’s for another blog post.
What’s Next
In designing this tool, we’ve identified a couple of issues inside Kubernetes client libraries when used in conjunction with SOCKS5 proxies, and we’re working with the Kubernetes community to fix those issues, so everybody should benefit from those patches in the near future.
With this blog post, we wanted to highlight how it is possible to apply Zero Trust security for complex workloads running on multi-cloud environments, while simultaneously improving the end user experience.
Although today our ‘k8s-tunnels’ code is too specific to Kudelski Security, our goal is to share what we’ve created back with the Kubernetes community, so that other organizations and Cloudflare customers can benefit from it.