Post Syndicated from Paul Lappas original https://aws.amazon.com/blogs/big-data/optimizing-tables-in-amazon-redshift-using-automatic-table-optimization/
Amazon Redshift is the most popular and fastest cloud data warehouse that lets you easily gain insights from all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift automates common maintenance tasks and is self-learning, self-optimizing, and constantly adapting to your actual workload to deliver the best possible performance.
Amazon Redshift has several features that automate performance tuning: automatic vacuum delete, automatic table sort, automatic analyze, and Amazon Redshift Advisor for actionable insights into optimizing cost and performance. In addition, automatic workload management (WLM) makes sure that you use cluster resources efficiently, even with dynamic and unpredictable workloads. Amazon Redshift can even automatically refresh and rewrite materialized views, speeding up query performance by orders of magnitude with pre-computed results. These capabilities use machine learning (ML) to adapt as your workloads shift, enabling you to get insights faster without spending valuable time managing your data warehouse.
Although Amazon Redshift provides industry-leading performance out of the box for most workloads, some queries benefit even more by pre-sorting and rearranging how data is physically set up on disk. In Amazon Redshift, you can set the proper sort and distribution keys for tables and allow for significant performance improvements for the most demanding workloads.
Automatic table optimization is a new self-tuning capability that helps you achieve the performance benefits of sort and distribution keys without manual effort. Automatic table optimization continuously observes how queries interact with tables and uses ML to select the best sort and distribution keys to optimize performance for the cluster’s workload. If Amazon Redshift determines that applying a key will improve cluster performance, tables are automatically altered within hours without requiring administrator intervention. Optimizations made by the Automatic table optimization feature have been shown to increase cluster performance by 24% and 34% using the 3 TB and 30 TB TPC-DS benchmark, respectively, versus a cluster without Automatic table optimization.
In this post, we illustrate how you can take advantage of the Automatic table optimization feature for your workloads and easily manage several thousands of tables with zero administration.
Solution overview
The following diagram is an architectural illustration of how Automatic table optimization works:
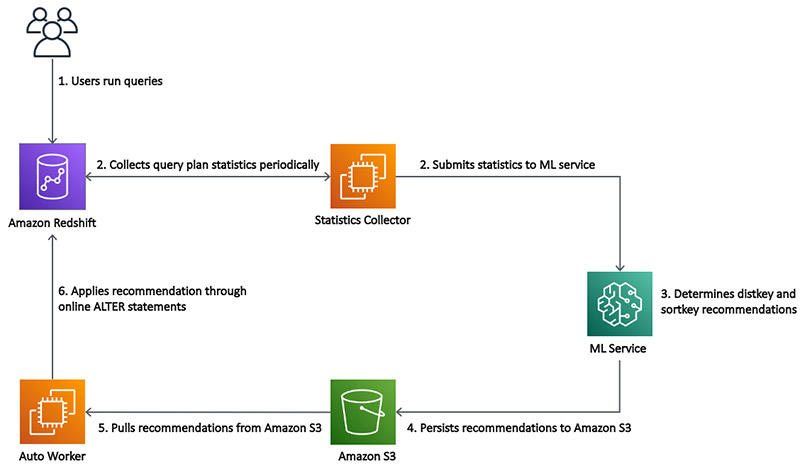
As you can notice, as users query the data in Amazon Redshift, automatic table optimization collects the query statistics that are analyzed using a machine learning service to predict recommendations about the sort and distribution keys. These recommendations are later applied using online ALTER statements into the respective Amazon Redshift tables automatically.
For this post, we consider a simplified version of the of the star schema benchmark (SSB), which consists of the lineitem fact table along with the part and orders dimensional tables.

We use the preceding dimensional setup to create the tables using the defaults and illustrate how Automatic table optimization can automatically optimize it based on the query patterns.
To try this solution in your AWS account, you need access to an Amazon Redshift cluster and a SQL client such as SQLWorkbench/J. For more information, see Create a sample Amazon Redshift cluster.
Creating SSB tables using the defaults
Let’s start with creating a representative set of tables from the SSB schema and letting Amazon Redshift pick the default settings for the table design.
- Create the following tables to set up the dimensional model for the retail system dataset:
As you can see from the table DDL, apart from the table column definition, no other options are specified. Amazon Redshift defaults the sort key and distribution style to AUTO.
- We now load data from the public Amazon Simple Storage Service (Amazon S3) bucket to our new tables. Use any SQL client tool and run the following command, providing your AWS account ID and Amazon Redshift role:
- Wait until the table COPY is complete.
Amazon Redshift automatically assigns the data encoding for the columns and chooses the sort and distribution style based on the size of the table.
- Use the following query to review the decisions that Amazon Redshift makes for the column encoding:
- Verify the table design choices for the sort and distribution key with the following code:
The tables distribution is set to AUTO(EVEN) or AUTO(ALL), depending on the size of table, and sort key is AUTO(SORTKEY).
Until now, because no active workloads were ran against these tables, no specific key choices have been made other than marking them as AUTO.
Querying the SSB tables to emulate the workload
Now end-users can use the created tables, and Amazon Redshift can support out-of-box performance.
The following are some sample queries that we can run using this SSB schema. These queries are run a few repeated times to have Amazon Redshift learn the access patterns for sort and distribution key optimization. To run the query several times, we use the \watch option available with the psql client. Otherwise just run this a few dozen times:
The preceding queries are run a few hundred times every 2 seconds, and you can press Ctrl+C to cancel the queries.
Alternatively, you can also use the query editor to schedule the query and run it multiple times.
Reviewing recommended sort and distribution keys
Automatic table optimization uses Amazon Redshift Advisor sort and distribution key recommendations. The Advisor continuously monitors the cluster’s workload and proposes the right sort and distribution keys to improve query speed. With Automatic Table Optimization, the Advisor recommendations are visible in the SVV_ALTER_TABLE_RECOMMENDATIONS system table. This view shows recommendations for all tables, whether or not they are defined for automatic optimization. Recommendations that have auto_eligible = False are not automatically applied, but you can run the DDL to apply the recommendation manually. See the following code:
Applying recommendations to the target tables
Amazon Redshift takes advantage of the new Automatic table optimization feature to apply the optimization made by the Advisor to the target tables. The conversion is run by the automation during periods of low workload intensity so as to minimize impact on user queries. This can be verified by running the following query:
You can view all the optimizations that are applied on the tables using the following query:
Amazon Redshift can self-learn based on the workload, learn from the table access patterns, and apply the table design optimizations automatically.
Now let’s run the sample workload queries again after optimization:
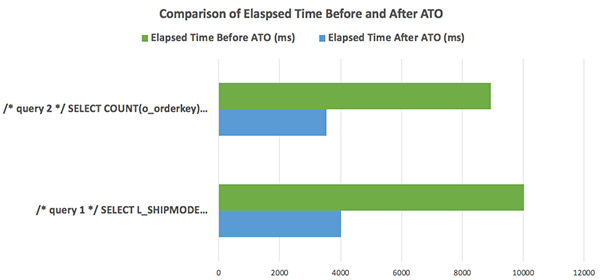
With the sort and distribution optimization, query 1 and query 2 run with 40% less time elapsed, also shown by the following visual.
Converting existing tables for optimization
You can easily convert existing tables for Automatic table optimization using the ALTER table command and switch the sort and distribution styles to AUTO so that it can be automatically optimized by Amazon Redshift. See the following code:
Lead time to apply the recommendation
Amazon Redshift continuously learns from workloads, and optimizations are inserted into the svv_alter_table_recomendations. When an optimization is available, it runs within a defined frequency, as well as in periods of low workload intensity, so as to minimize impact on user queries. For more information about the lead time of applying the recommendation, see https://docs.aws.amazon.com/redshift/latest/dg/t_Creating_tables.html
Conclusion
Automatic table optimization for Amazon Redshift is a new capability that applies sort and distribution keys without the need for administrator intervention. Using automation to tune the design of tables lets you get started more easily and decreases the amount of administrative effort. Automatic table optimization enables easy management of large numbers of tables in a data warehouse because Amazon Redshift self-learns, self-optimizes, and adapts to your actual workload to deliver you the best possible performance.
About the Author
 Paul Lappas is a Principal Product Manager at Amazon Redshift. Paul is responsible for Amazon Redshift’s self-tuning capabilities including Automatic Table Optimization, Workload Manager, and the Amazon Redshift Advisor. Paul is passionate about helping customers leverage their data to gain insights and make critical business decisions. In his spare time Paul enjoys playing tennis, cooking, and spending time with his wife and two boys.
Paul Lappas is a Principal Product Manager at Amazon Redshift. Paul is responsible for Amazon Redshift’s self-tuning capabilities including Automatic Table Optimization, Workload Manager, and the Amazon Redshift Advisor. Paul is passionate about helping customers leverage their data to gain insights and make critical business decisions. In his spare time Paul enjoys playing tennis, cooking, and spending time with his wife and two boys.
 Thiyagarajan Arumugam is a Principal Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
Thiyagarajan Arumugam is a Principal Solutions Architect at Amazon Web Services and designs customer architectures to process data at scale. Prior to AWS, he built data warehouse solutions at Amazon.com. In his free time, he enjoys all outdoor sports and practices the Indian classical drum mridangam.
 KamCheung Ting is a Senior Software Engineer at Amazon Redshift. He joined Redshift in 2014 and specializes in storage engine, autonomous DB and concurrency scaling.
KamCheung Ting is a Senior Software Engineer at Amazon Redshift. He joined Redshift in 2014 and specializes in storage engine, autonomous DB and concurrency scaling.