Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/new-amazon-emr-on-amazon-elastic-kubernetes-service-eks/
Tens of thousands of customers use Amazon EMR to run big data analytics applications on frameworks such as Apache Spark, Hive, HBase, Flink, Hudi, and Presto at scale. EMR automates the provisioning and scaling of these frameworks and optimizes performance with a wide range of EC2 instance types to meet price and performance requirements. Customer are now consolidating compute pools across organizations using Kubernetes. Some customers who manage Apache Spark on Amazon Elastic Kubernetes Service (EKS) themselves want to use EMR to eliminate the heavy lifting of installing and managing their frameworks and integrations with AWS services. In addition, they want to take advantage of the faster runtimes and development and debugging tools that EMR provides.
Today, we are announcing the general availability of Amazon EMR on Amazon EKS, a new deployment option in EMR that allows customers to automate the provisioning and management of open-source big data frameworks on EKS. With EMR on EKS, customers can now run Spark applications alongside other types of applications on the same EKS cluster to improve resource utilization and simplify infrastructure management.
Customers can deploy EMR applications on the same EKS cluster as other types of applications, which allows them to share resources and standardize on a single solution for operating and managing all their applications. Customers get all the same EMR capabilities on EKS that they use on EC2 today, such as access to the latest frameworks, performance optimized runtimes, EMR Notebooks for application development, and Spark user interface for debugging.

Amazon EMR automatically packages the application into a container with the big data framework and provides pre-built connectors for integrating with other AWS services. EMR then deploys the application on the EKS cluster and manages logging and monitoring. With EMR on EKS, you can get 3x faster performance using the performance-optimized Spark runtime included with EMR compared to standard Apache Spark on EKS.
Amazon EMR on EKS – Getting Started
If you already have a EKS cluster where you run Spark jobs, you simply register your existing EKS cluster with EMR using the AWS Management Console, AWS Command Line Interface (CLI) or APIs to deploy your Spark appication.
For exampe, here is a simple CLI command to register your EKS cluster.
$ aws emr create-virtual-cluster \
--name <virtual_cluster_name> \
--container-provider '{
"id": "<eks_cluster_name>",
"type": "EKS",
"info": {
"eksInfo": {
"namespace": "<namespace_name>"
}
}
}'In the EMR Management console, you can see it in the list of virtual clusters.
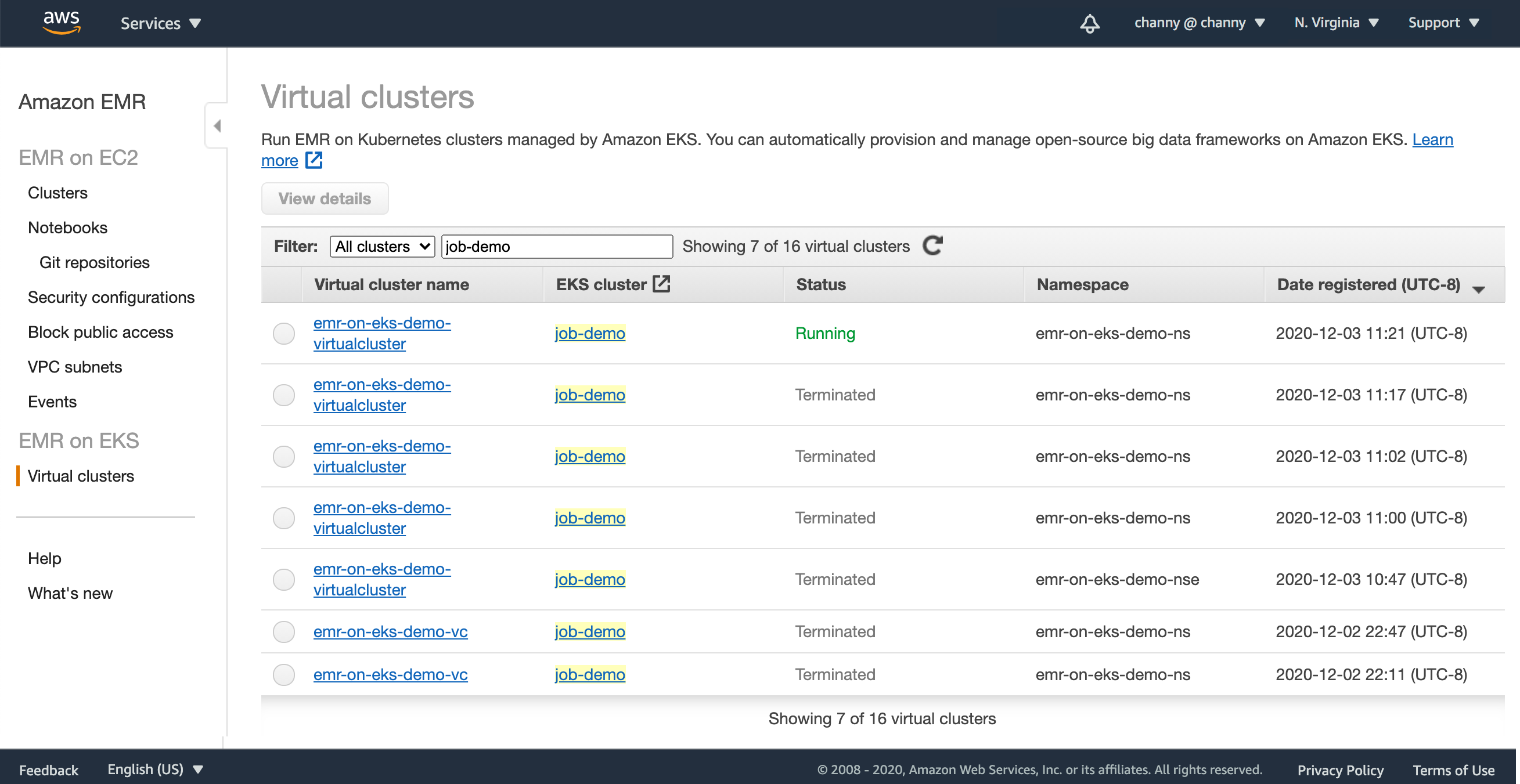
When Amazon EKS clusters are registered, EMR workloads are deployed to Kubernates nodes and pods to manage application execution and auto-scaling, and sets up managed endpoints so that you can connect notebooks and SQL clients. EMR builds and deploys a performance-optimized runtime for the open source frameworks used in analytics applications.
You can simply start your Spark jobs.
$ aws emr start-job-run \
--name <job_name> \
--virtual-cluster-id <cluster_id> \
--execution-role-arn <IAM_role_arn> \
--virtual-cluster-id <cluster_id> \
--release-label <<emr_release_label> \
--job-driver '{
"sparkSubmitJobDriver": {
"entryPoint": <entry_point_location>,
"entryPointArguments": ["<arguments_list>"],
"sparkSubmitParameters": <spark_parameters>
}
}'To monitor and debug jobs, you can use inspect logs uploaded to your Amazon CloudWatch and Amazon Simple Storage Service (S3) location configured as part of monitoringConfiguration. You can also use the one-click experience from the console to launch the Spark History Server.
Integration with Amazon EMR Studio
Now you can submit analytics applications using AWS SDKs and AWS CLI, Amazon EMR Studio notebooks, and workflow orchestration services like Apache Airflow. We have developed a new Airflow Operator for Amazon EMR on EKS. You can use this connector with self-managed Airflow or by adding it to the Plugin Location with Amazon Managed Workflows for Apache Airflow.
You can also use newly previewed Amazon EMR Studio to perform data analysis and data engineering tasks in a web-based integrated development environment (IDE). Amazon EMR Studio lets you submit notebook code to EMR clusters deployed on EKS using the Studio interface. After seting up one or more managed endpoints to which Studio users can attach a Workspace, EMR Studio can communicate with your virtual cluster.
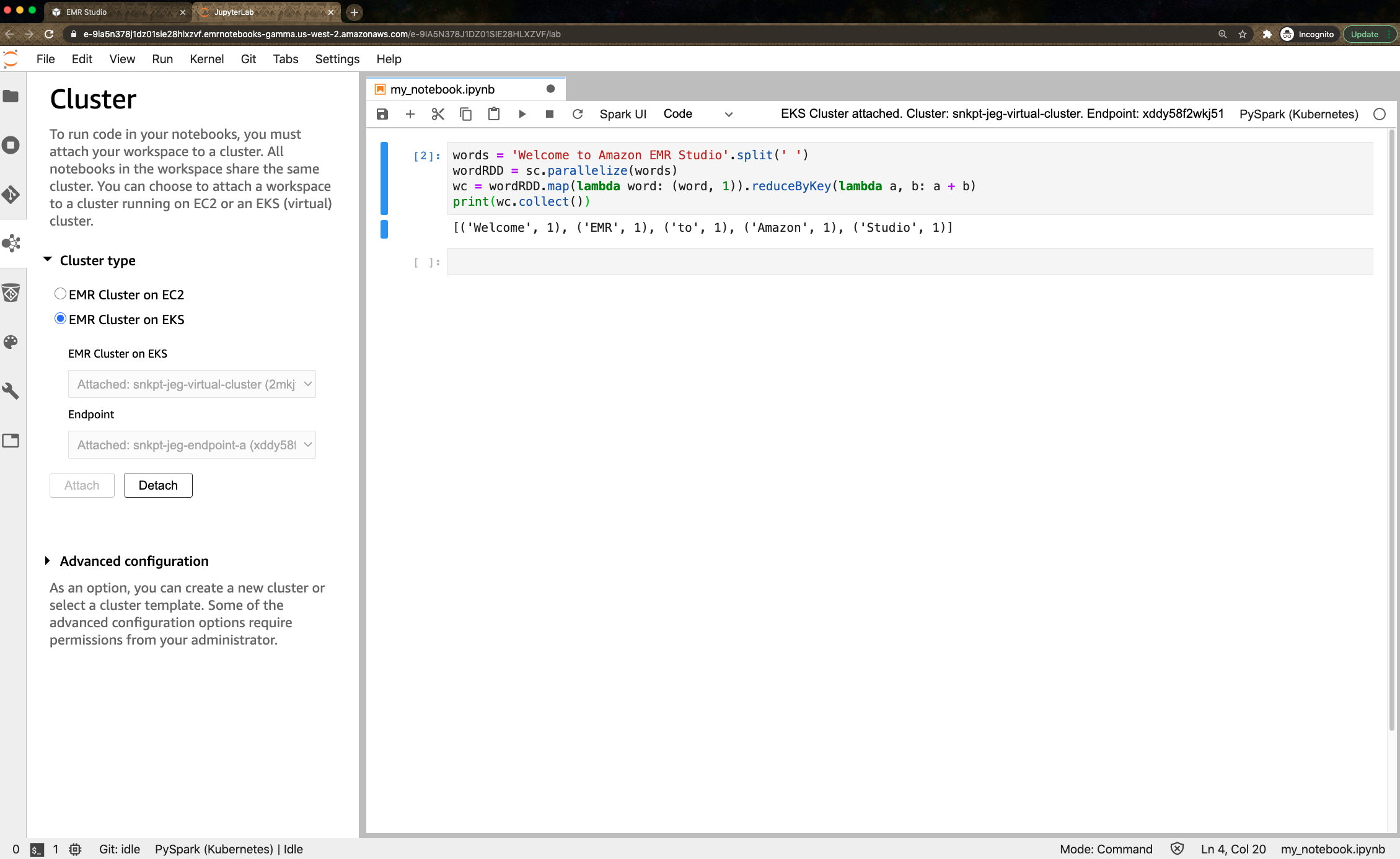
For EMR Studio preview, there is no additional cost when you create managed endpoints for virtual clusters. To learn more, visit the guide document.
Now Available
Amazon EMR on Amazon EKS is available in US East (N. Virginia), US West (Oregon), and Europe (Ireland) Regions. You can run EMR workloads in AWS Fargate for EKS removing the need to provision and manage infrastructure for pods as a serverless option.
To learn more, visit the documentation. Please send feedback to the AWS forum for Amazon EMR or through your usual AWS support contacts.
Learn all the details about Amazon EMR on Amazon EKS and get started today.
— Channy;