Post Syndicated from Yogi Barot original https://aws.amazon.com/blogs/architecture/field-notes-building-a-multi-region-architecture-for-sql-server-using-fci-and-distributed-availability-groups/
A multiple-Region architecture for Microsoft SQL Server is often a topic of interest that comes up when working with our customers. The main reasons customers adopt a multiple-Region architecture approach for SQL Server deployments are:
- Business continuity and disaster recovery (DR)
- Geographically distributed customer base, and improved latency for end users
We will explain the architecture patterns that you can follow to effectively design a highly available SQL Server deployment, which spans two or more AWS Regions. You will also learn how to use the multiple-Region approach to scale out the read workloads, and improve the latency for your globally distributed end users.
This blog post explores SQL Server DR architecture using SQL Server Failover Cluster with Amazon FSx for Windows File Server, for primary site and secondary DR site, and describes how to set up a multiple-Region Always On distributed availability group.
Architecture overview
The architecture diagram in Figure 1 depicts two SQL Server clusters (multiple Availability Zones) in two separate Regions, and uses distributed availability group for replication and DR. This will also serve as the reference architecture for this solution.
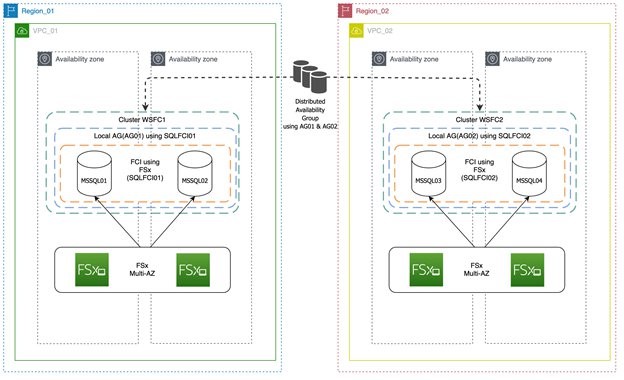
Figure 1. Two SQL Server clusters (multiple Availability Zones) in two separate Regions
In Figure 1, there are two separate clusters in different Regions. The primary cluster in Region_01 is initially configured with SQL Server Failover Cluster Instance (FCI) using Amazon FSx for its shared storage. Always On is enabled on both nodes, and is configured to use FCI SQL Network Name (SQLFCI01) as the single replica for local Availability Group (AG01). Region_02 has an identical configuration to Region_01, but with different hostnames, listeners, and SQL Network Name to avoid possible collisions.
Highlighted in Figure 1, the Always On distributed availability group is then configured to use both listener endpoints (AG01 and AG02). Depending on what type of authentication infrastructure you have, you can either use certificates (no domain and trust dependency), or just AWS Directory Service for Microsoft Active Directory authentication to build the local mirroring endpoint that will be used by the distributed availability group.
With Amazon FSx, you get a fully managed shared file storage solution, that automatically replicates the underlying storage synchronously across multiple Availability Zones. Amazon FSx provides high availability with automatic failure detection, and automatic failover if there are any hardware or storage issues. The service fully supports continuously available shares, a feature that allows SQL Server uninterrupted access to shared file data.
There is an asynchronous replication setup using a distributed availability group from Region A to Region B. In this type of configuration, because there is only one availability group replica, it also serves as the forwarder for the local FCI cluster. The concept of a forwarder is new, and it’s one of the core functionalities for the distributed availability group. Because Windows Failover Cluster1 and Windows Failover Cluster2 are standalone and independent clusters, don’t need to open a large set of ports, thus minimizing security risk.
In this solution, because FCI is our primary high availability solution, users and applications should then connect through FCI SQL Server Network Name with the latest supported drivers and key parameters (such as, MultiSubNetFailover=True – if supported) to facilitate the failover and make sure that the applications seamlessly connect to the new replica without any errors or timeouts.
Prerequisites
- Two SQL Server clusters configured with FCI. Learn more about how to set up SQL Server FCI with FSx.
- VPC peering and transit gateway are configured for the VPCs (where the SQL Server clusters reside) involved in the solution.
- VPC peering – Learn more about setting up Inter-Region VPC Peering.
- Transit gateway – Similar to VPC peering. Learn how to Use an AWS Transit Gateway to Simplify Your Network Architecture and Scaling VPN throughput using AWS Transit Gateway.
- Networking and security are properly configured to work across the peering connection and transit gateway.
Walkthrough
Following are the steps required to configure SQL Server DR using SQL Server Failover Cluster with Amazon FSx for Windows File Server for primary site and secondary DR site. We also show how to set up a multiple-Region Always On distributed availability group.
Assumed Variables
Region_01:
WSFC Cluster Name: SQLCluster1
FCI Virtual Network Name: SQLFCI01
Local Availability Group: SQLAG01
Region_02:
WSFC Cluster Name: SQLCluster2
FCI Virtual Network Name: SQLFCI02
Local Availability Group: SQLAG02
- Make sure to configure network connectivity between your clusters. In this solution, we are using two VPCs in two separate Regions.
- VPC peering is configured to enable network traffic on both VPCs.
- The domain controller (AWS Managed Microsoft AD) on both VPCs are configured with forest trust and conditional forwarding (this enables DNS resolution between the two VPCs).
- Create a local availability group, using FCI SQL Network Name as the replica. Because we will be setting up a domain-independent distributed availability group between the two clusters, we will be setting up certificates to authenticate between the two separate clusters.
-
Create master key and endpoint for SQLCluster1
use master
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>'
GO
CREATE CERTIFICATE [SQLAG01-Cert]
with SUBJECT = 'SQLAG01 Endpoint Cert'
GO
BACKUP CERTIFICATE [SQLAG01-Cert]
TO FILE = N'\\<FileShare>\SQLAG01-Cert.crt'
GO
CREATE ENDPOINT [SQLAG01-Endpoint]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022
)
FOR DATABASE_MIRRORING
(
AUTHENTICATION = CERTIFICATE [SQLAG01-Cert],
ROLE = ALL,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO-
Create master key and endpoint for SQLCluster2
use master
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>'
GO
CREATE CERTIFICATE [SQLAG02-Cert]
with SUBJECT = 'SQLAG02 Endpoint Cert'
GO
BACKUP CERTIFICATE [SQLAG02-Cert]
TO FILE = N'\\<Fileshare>\SQLAG02-Cert.crt'
GO
CREATE ENDPOINT [SQLAG02-Endpoint]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022
)
FOR DATABASE_MIRRORING
(
AUTHENTICATION = CERTIFICATE [SQLAG02-Cert],
ROLE = ALL,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
-
- Make sure to place all exported certificates in a location that you can easily access from each FCI instance.
- Create a SQL Server login and user in the master database on each FCI instance.
-
Create database login in SQLCluster1
use master
CREATE LOGIN [SQLAG02_DAG] WITH PASSWORD = '<password>'
GO
CREATE USER [SQLAG02_DAG] FOR LOGIN [SQLAG02_DAG]
GO
CREATE CERTIFICATE [SQLAG02-Cert]
AUTHORIZATION [SQLAG02_DAG]
FROM FILE = N'\\<Fileshare>\SQLAG02-Cert.crt'
GO-
Create database login in SQLCluster2
use master
CREATE LOGIN [SQLAG01_DAG] WITH PASSWORD = '<password>'
GO
CREATE USER [SQLAG01_DAG] FOR LOGIN [SQLAG01_DAG]
GO
CREATE CERTIFICATE [SQLAG01-Cert]
AUTHORIZATION [SQLAG01_DAG]
FROM FILE = N'\\<Fileshare>\SQLAG01-Cert.crt'
GO-
- Now grant the newly created user endpoint access to the local mirroring endpoint in each FCI instance.
-
Grant permission on endpoint – SQLCluster1
GRANT CONNECT ON ENDPOINT::[SQLAG01-Endpoint] TO [SQLAG02_DAG]
GO-
Grant permission on endpoint – SQLCluster2
GRANT CONNECT ON ENDPOINT::[SQLAG02-Endpoint] TO [SQLAG01_DAG]
GO- Create distributed Always On availability group on SQLCluster1
Next, create the distributed availability group on the primary cluster.
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLAG01' WITH
(
LISTENER_URL = 'tcp://SQLFCI01.DEMOSQL.COM:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG02' WITH
(
LISTENER_URL = 'tcp://SQLFCI02.SQLDEMO.COM:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
); -
- Note that we are using the SQL Network Name of the FCI cluster as our listener URL.
- Now, join our secondary WSFC FCI cluster to the distributed availability group.
-
Join secondary cluster on SQLCluster2 to distributed availability group
ALTER AVAILABILITY GROUP [SQLFCIDAG]
JOIN
AVAILABILITY GROUP ON
'SQLAG01' WITH
(
LISTENER_URL = 'tcp://SQLFCI01.DEMOSQL.COM:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG02' WITH
(
LISTENER_URL = 'tcp://SQLFCI02.SQLDEMO.COM:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO -
- After you run the join script, you should be able to see the database from the primary FCI cluster’s local availability group populate the secondary FCI cluster.
- To do a distributed availability group failover, it is best practice to synchronize both clusters first.
-
Synchronize primary cluster
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLAG01'
WITH
(
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
'SQLAG02'
WITH
(
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
);-
- You can verify synchronization lag and verify state displays as “SYNCHRONIZED”:
SELECT ag.name
, drs.database_id
, db_name(drs.database_id) as database_name
, drs.group_id
, drs.replica_id
, drs.synchronization_state_desc
, drs.last_hardened_lsn
FROM sys.dm_hadr_database_replica_states drs
INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;-
Perform failover at primary cluster
After everything is ready, perform failover by first changing the DAG role on the global primary.
ALTER AVAILABILITY GROUP [SQLFCIDAG] SET (ROLE = SECONDARY);-
Perform failover at secondary cluster
After which, initiate the actual failover by running this script on the secondary cluster.
ALTER AVAILABILITY GROUP [SQLFCIDAG] FORCE_FAILOVER_ALLOW_DATA_LOSS;-
Change sync mode on primary and secondary clusters
Then make sure to change Sync mode on both clusters back to Asynchronous:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLAG01'
WITH
(
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT
),
'SQLAG02'
WITH
(
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT
);Conclusion
A multiple-Region strategy for your mission critical SQL Server deployments is key for business continuity and disaster recovery. This blog post focused on how to achieve that optimally by using distributed availability groups. You also learned about other benefits such as read scale outs by using distributed availability groups.
To learn more, check out Simplify your Microsoft SQL Server high availability deployments using Amazon FSx for Windows File Server.