Post Syndicated from Manoj Gundawar original https://aws.amazon.com/blogs/big-data/how-viasat-scaled-their-big-data-applications-by-migrating-to-amazon-emr/
This post is co-written with Manoj Gundawar from Viasat.
Viasat is a satellite internet service provider based in Carlsbad, CA, with operations across the United States and worldwide. Viasat’s ambition is to be the first truly global, scalable, broadband service provider with a mission to deliver connections that can change the world. Viasat operates across three main business segments: satellite services, commercial networks, and government systems, providing high-speed satellite broadband services and secure networking systems.
In this post, we discuss how migrating our on-premises big data workloads to Amazon EMR helped us achieve a fully managed cloud-native solution and freed us from the constraints of our legacy on-premises solution, so we can focus on business innovation with a lower TCO.
Challenge with the legacy big data environment
Viasat’s big data application, Usage Data Mart, is a high-volume, low-latency Hadoop-based solution that ingests internet usage data from a multitude of source systems. It curates and aggregates with data from other sources, and provides the data in an optimized system to support high-volume access to reporting and web interfaces. This critical application processes over 1.3 billion internet usage records per day, sourced from various upstream systems. Viasat customer support representatives use this data through APIs and reports to assist end-users on any queries regarding their internet usage. Various internal teams and customers also use data for usage accounting, tracking, compliance, and billing purposes.
The Usage Data Mart was previously implemented in an on-premises footprint of over 40 nodes with three independent clusters all running a commercial distribution of Hadoop to process our big data work load. The legacy Hadoop environment required three times the data replication to achieve high availability, which resulted in a large infrastructure footprint. In this architecture, we had a data ingestion cluster to ingest data from a Kafka streaming service, MySQL, and Oracle databases. We had extract, transform, and load (ETL) jobs for each data source and data domains or models, and most of the ETL jobs filter, curate, canonicalize, and aggregate data (by specific keys) using MapReduce framework and load in HBase as well as in HDFS or Amazon Simple Storage Service (Amazon S3) in Apache Parquet format. We used HBase to provide on-demand query and aggregation of data via REST APIs that used HBase coprocessors to apply aggregation and other business logic. Our independent reporting cluster queried Parquet files on HDFS and Amazon S3 with Apache Drill to generate a few dozen periodic reports. We had separated HBase and ETL clusters from reporting clusters to avoid any resource contention.
Our legacy environment had challenges at various levels:
- Hardware – As the hardware aged, we encountered hardware failures on a regular basis. Expiring warranties on hardware and faulty component replacement increased operational risk. The burden of managing the hardware replacement and servers failing to restart after maintenance imposed a serious risk to the business, which made maintenance unpredictable and time-consuming.
- Software – Yearly software license renewal costs and engineering efforts involved with software version upgrades to keep it on a supported version added operational complexity. Moreover, the commercial Hadoop distribution that we were running reached end of life in 2020.
- Scaling – We needed to scale on-premises hardware to meet growing business needs during additional satellite launches that required forecasting and capacity planning. Delays in procurement and shipment of hardware affected project timelines. Finally, increasing data usage and customer adoption of this portal presented serious scaling challenges for Viasat.
How migration to Amazon EMR helped solve this challenge
Viasat evaluated a few alternatives to modernize big data applications and determined that Amazon EMR would be the right platform for our requirements. The separate compute and storage architecture of Amazon EMR helped us address our challenges. The following are some of the key benefits we realized with migration to AWS:
- Storage – Amazon EMR supports HBase on Amazon S3, where Amazon S3 is used as persistent storage for the HBase cluster and allows us to scale our compute needs independently of storage. It also allows us to easily decommission HBase clusters, test upgrades, and optimizes our total cost of ownership. For guidelines and best practices, see Migrating to Apache HBase on Amazon S3 on Amazon EMR.
- DNS records – Because it’s so easy for us to provision new HBase clusters, we needed a way to maintain DNS records to make the cluster easily accessible. We use a simple AWS Lambda function to update DNS records during EMR cluster boot up. The DNS records are stored in our custom DNS service and we use a custom API to update the records.
- Customization – Amazon EMR allows you to customize existing software on the cluster as well as install additional software. We use Apache Drill for reporting and, with EMR bootstrap actions, we were able to install Apache Drill on all the nodes of the reporting cluster to provide us with distributed reporting using Parquet files generated with a MapReduce job. Because our reporting uses different query patterns than the data in the HBase cluster, the Parquet files are written with a different partition optimized for reporting. We increased the default bucket size from approximately 8 MB to 16 MB and pointed Amazon EMR to private Amazon S3 endpoints to avoid traffic going through an external firewall, which increased performance.
The following diagram depicts the process we followed for migration to Amazon EMR.

Viasat successfully migrated our on-premises big data applications to Amazon EMR in May 2021, following a lift-and-shift approach to move the big data workload to the cloud with minimal changes. Although we have an experienced big data team, we used AWS Infrastructure Event Management (IEM) to support queries on fine-tuning the Amazon EMR infrastructure within the migration timeline.
The following diagram outlines our new architecture. With this new architecture, we can process the same workloads with 50% of the compute footprint and approximately 50% of the costs compared to our on-premises clusters and still meet our SLAs.
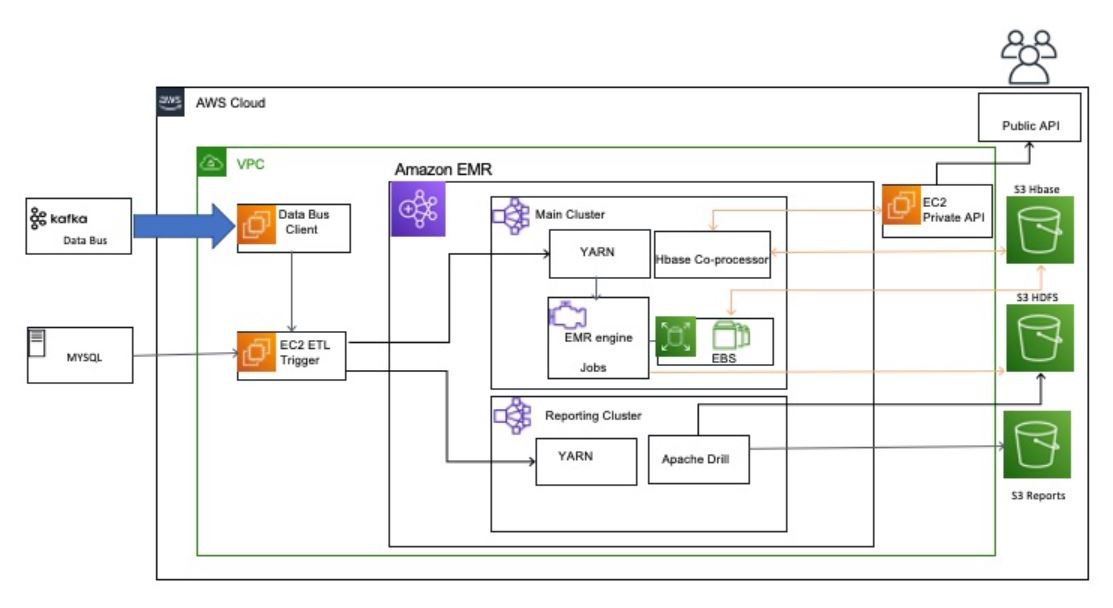
Conclusion
With the new data platform, we can ingest additional data sources so that our analysts and customer service teams can gain insights and improve customer experience. As Viasat is launching new satellites and growing business in multiple new countries, we’re looking to stand up this solution in new AWS Regions (closest to the host country) and scale it as needed.
Questions or feedback? Send an email to [email protected].
About the Authors
 Manoj Gundawar is a product owner at Viasat. He builds product roadmap, provides architecture guidance and manages full software development life cycle to build high quality product/software with minimal TCO. He is passionate about delighting the customers by providing innovating solutions, leveraging technology, agile methodology and continues improvement mindset.
Manoj Gundawar is a product owner at Viasat. He builds product roadmap, provides architecture guidance and manages full software development life cycle to build high quality product/software with minimal TCO. He is passionate about delighting the customers by providing innovating solutions, leveraging technology, agile methodology and continues improvement mindset.
 Archana Srinivasan is a Technical Account Manager within Enterprise Support at Amazon Web Services. Archana helps AWS customers leverage Enterprise Support entitlements to solve complex operational challenges and accelerate their cloud adoption.
Archana Srinivasan is a Technical Account Manager within Enterprise Support at Amazon Web Services. Archana helps AWS customers leverage Enterprise Support entitlements to solve complex operational challenges and accelerate their cloud adoption.
 Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern Big Data solutions. He is passionate about working with customers and helping them in their cloud journey. Kiran loves music, travel, food and watching football.
Kiran Guduguntla is a WW Go-to-Market Specialist for Amazon EMR at AWS. He works with AWS customers across the globe to strategize, build, develop and deploy modern Big Data solutions. He is passionate about working with customers and helping them in their cloud journey. Kiran loves music, travel, food and watching football.