Post Syndicated from Shailesh Chauhan original https://aws.amazon.com/blogs/big-data/create-and-reuse-governed-datasets-in-amazon-quicksight-with-new-dataset-as-a-source-feature/
Amazon QuickSight is a fast, cloud-powered, business intelligence (BI) service that makes it easy to deliver insights to everyone in your organization. QuickSight recently introduced Dataset-as-a-Source, a new feature that allows data owners to create authoritative datasets that can then be reused and further extended by thousands of users across the enterprise. This post walks through an example of how QuickSight makes it easy to create datasets that are reusable and easy to govern, with Dataset-as-a-source.
Introducing Dataset-as-a-Source
Dataset-as-a-Source allows QuickSight authors and data owners to create authoritative datasets, as a single source of truth, that either use the QuickSight SPICE in-memory engine, or directly query the underlying database. These datasets may contain data from a single table from a single database, or a combination of data across multiple data sources, including flat files, software as a service (SaaS) sources, databases, and data warehouses. Data owners with a deep understanding of the data can predefine metrics and calculations in the dataset with metadata that makes it easy for authors to understand and consume this data.
After you create these authoritative datasets, you can share them with authors who want to consume this data – either directly on a per-user or group basis, or using shared folders in QuickSight. Authors can now simply use these datasets for their dashboard creation activities, or choose to further augment these datasets by adding additional calculated fields or joining them with other data that is relevant to them. Any updates made by the data owner to the authoritative dataset automatically cascades to the downstream datasets created by individual authors using those datasets. This provides the organization with a secure, governed, and effortless data sharing process that can scale to thousands of authors as needed, without any server setup or data silos on client desktops.
Dataset-as-a-Source example use case
This example use case uses the Amazon Customer Reviews Data. It is public data stored in the us-east-1 Region. You have the following three tables:
- product_reviews – Customer reviews for a specific product
- customer – Customer profile data
- customer_address – Customer address information
The following diagram shows the relationship of the three tables.
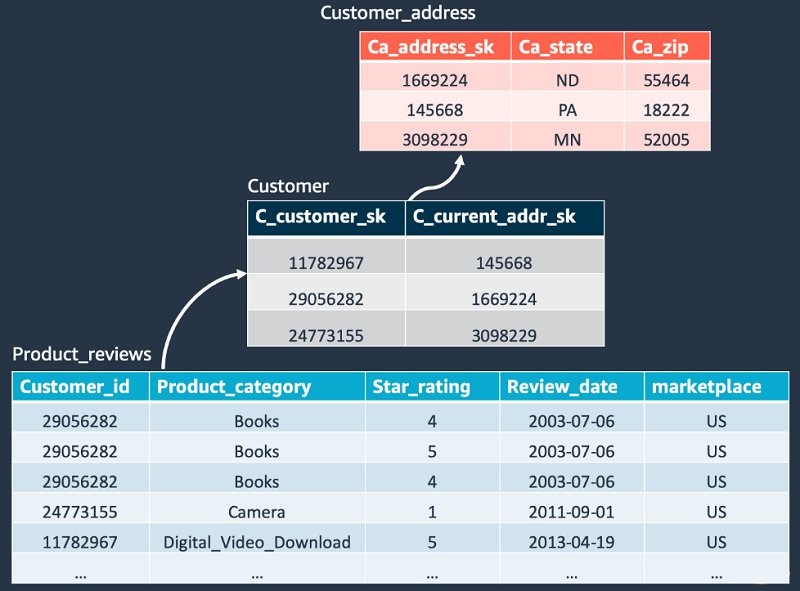
In the following sections, we explain the process of using Dataset-as-a-Source using the tables from the preceding schema.
Create central datasets
Let’s say you’re part of the central data engineering team that has access to the preceding data with three tables in a database. Your team serves over 100 business analysts across 10 different teams in eight countries, namely the Coupons team, Outbound Marketing team, Mobile Platform team, and Recommendations team. Analysts on each team want to analyze product and customer data along with data specific to their teams.
Rather than manually creating and maintaining several unconnected datasets for each team, your team created a central dataset. You created the central Product and Customer dataset by joining the three tables in a schema. Dashboard performance and query costs are optimized for large central dataset with Dynamic Querying. Dynamic Querying enables direct query datasets that contain joined tables to run more efficiently. Joins are applied dynamically so that only the subset of tables needed to render a visual are used in the join. Your team also created a key metric (calculated field): Average Rating. All of these teams use the Average Rating metric as a base to analyze their own business line. Its definition is: Average Rating = Sum(Star_rating) / Unique_Count(Start_rating).
Reuse and join with other datasets
Individual teams reused the central Product and Customer dataset and joined it with the data of their own, to create their own datasets. For example, the Marketing team wanted to understand how their team helped improving the product ratings. Therefore, they combined the central Product and Customer dataset with campaign data to create a new dataset: Marketing – Product & Customer Rating. Similarly, the Mobile Platform team combined mobile data with the Product and Customer dataset to understand rating impact on mobile.
With Dataset-as-a-Source, you can centralize data management while allowing each team to customize the data for their own needs, all while syncing updates to the data, such as updates to metric definitions, and maintaining dataset definitions like column names, descriptions, and field folders. Additionally, if these are SPICE datasets, the newly created datasets are created with SPICE as a source, so you don’t reach to the datasource every time a dataset is created or refreshed.
Govern central datasets
You and the central team defined business metrics like Average Rating in the central dataset. With Dataset-as-a-Source, individual teams can use the central dataset without having to redo the work of recreating the field themselves, while extending it with data representing their specific business needs. All teams are able to use a uniform Average Rating metric definition.
Suppose you now want to make a change to the Average Rating definition because of a business operation change. You want to exclude Digital_Video_Download from the product category, and need to provide an updated definition to each team. To make modifications, you have to modify just the central dataset, and the associated datasets get the updates automatically. This saves you time and prevents errors in business metric definitions.
Conclusion
Creating datasets from existing datasets using Dataset-as-a-Source helps you with the following:
- Dataset governance – Data engineers can easily scale to the needs of multiple teams within their organization by developing and maintaining a few general-purpose datasets that describe the organization’s main data models—without compromising on query performance.
- Data source management reduction – Analysts spend considerable amounts of time and effort requesting access to databases, managing database credentials, finding the right tables, and managing data refresh schedules. Building new datasets from existing datasets means that analysts don’t have to start from scratch with raw data from databases. They can start with pre-curated data, while also ensuring that on the data source side, optimizations such as workload management can be put in place to ensure optimal performance of backend stores.
- Metrics accuracy – Creating datasets from existing datasets allows data engineers to centrally define and maintain critical data definitions, such as sales growth and net marginal return, across their company’s many organizations. It also allows them to distribute changes to those definitions, and gives their analysts the ability to get started with visualizing the right data more quickly and reliably.
- Dataset customization and flexibility – Creating datasets from existing datasets gives analysts more flexibility to customize datasets for their own business needs without worrying about disrupting data for other teams.
This post showed how QuickSight’s Dataset-as-a-Source can help your data management workflows. This feature greatly improves governance and reusability of the datasets. Dataset-as-a-Source is now generally available in Amazon QuickSight Standard and Enterprise Editions in all QuickSight regions. For further details, visit here.
About the Author
 Shailesh Chauhan is product managing Amazon QuickSight, AWS’ cloud-native, fully managed BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from ground-up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with great mind and big heart.
Shailesh Chauhan is product managing Amazon QuickSight, AWS’ cloud-native, fully managed BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from ground-up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with great mind and big heart.