Post Syndicated from Shailesh Chauhan original https://aws.amazon.com/blogs/big-data/iterate-confidently-on-amazon-quicksight-datasets-with-new-dataset-versions-capability/
Amazon QuickSight allows data owners and authors to create and model their data in QuickSight using datasets, which contain logical and semantic information about the data. Datasets can be created from a single or multiple data sources, and can be shared across the organization with strong controls around data access (object/row/column level security) and metadata included, and can be programmatically created or modified. QuickSight now supports dataset versioning, which allows dataset owners to see how a dataset has progressed, preview a version, or revert back to a stable working version in case something goes wrong. Dataset Versions gives you the confidence to experiment with your content, knowing that your older versions are available and you can easily revert back to it, if needed. For more details, see Dataset Versions.
In this post, we look at a use case of an author editing a dataset and how QuickSight makes it easy to iterate on your dataset definitions.
What is Dataset Versions?
Previously, changes made to a dataset weren’t tracked. Dataset authors would often make a change that would break the underlying dashboards, and they were often worried about the changes made to the dataset definitions. Dataset authors spent time figuring out how to fix the dataset, which could take significant time.
With Dataset Versions, each publish event associated with the dataset is tracked. Dataset authors can review previous versions of the dataset and how dataset has progressed. Each time someone publishes a dataset, QuickSight creates a new version, which becomes the active version. It makes the previous version the most recent version in the version list. With Dataset Versions, authors can restore back to a previous version if they encounter any issue with the current version.
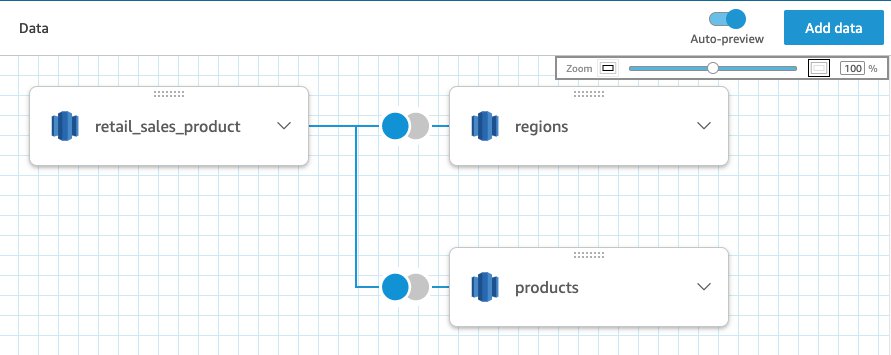
To help you understand versions better, let’s take the following scenario. Imagine you have a dataset and have iterated on it by making changes over time. You have multiple dashboards based on this dataset. You just added a new table called regions to this dataset. QuickSight saves a new version, and dashboards dependent on it the dataset break due to the addition of this table. You realize that you added the wrong table—you were supposed to add the stateandcity table instead. Let’s see how the Dataset Versions feature comes to your rescue.
Access versions
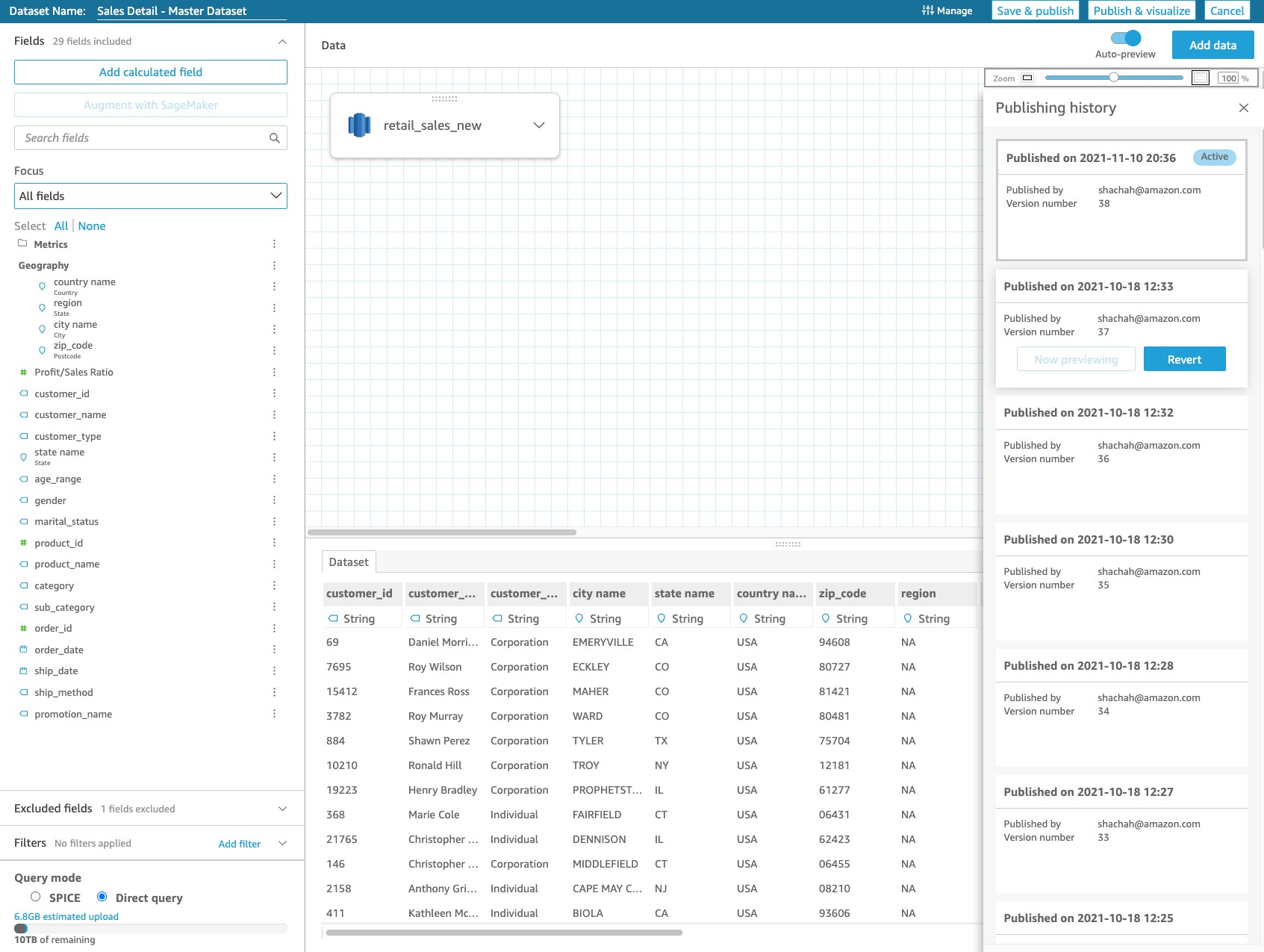
To access your dataset versions, choose the Manage menu and Publishing History on the data prep page of the dataset.

A panel opens on the right for you to see all the versions. In the following screenshot, the current active version of the dataset is version 38—published on November 10, 2021. This is the version that is breaking your dependent dashboards.
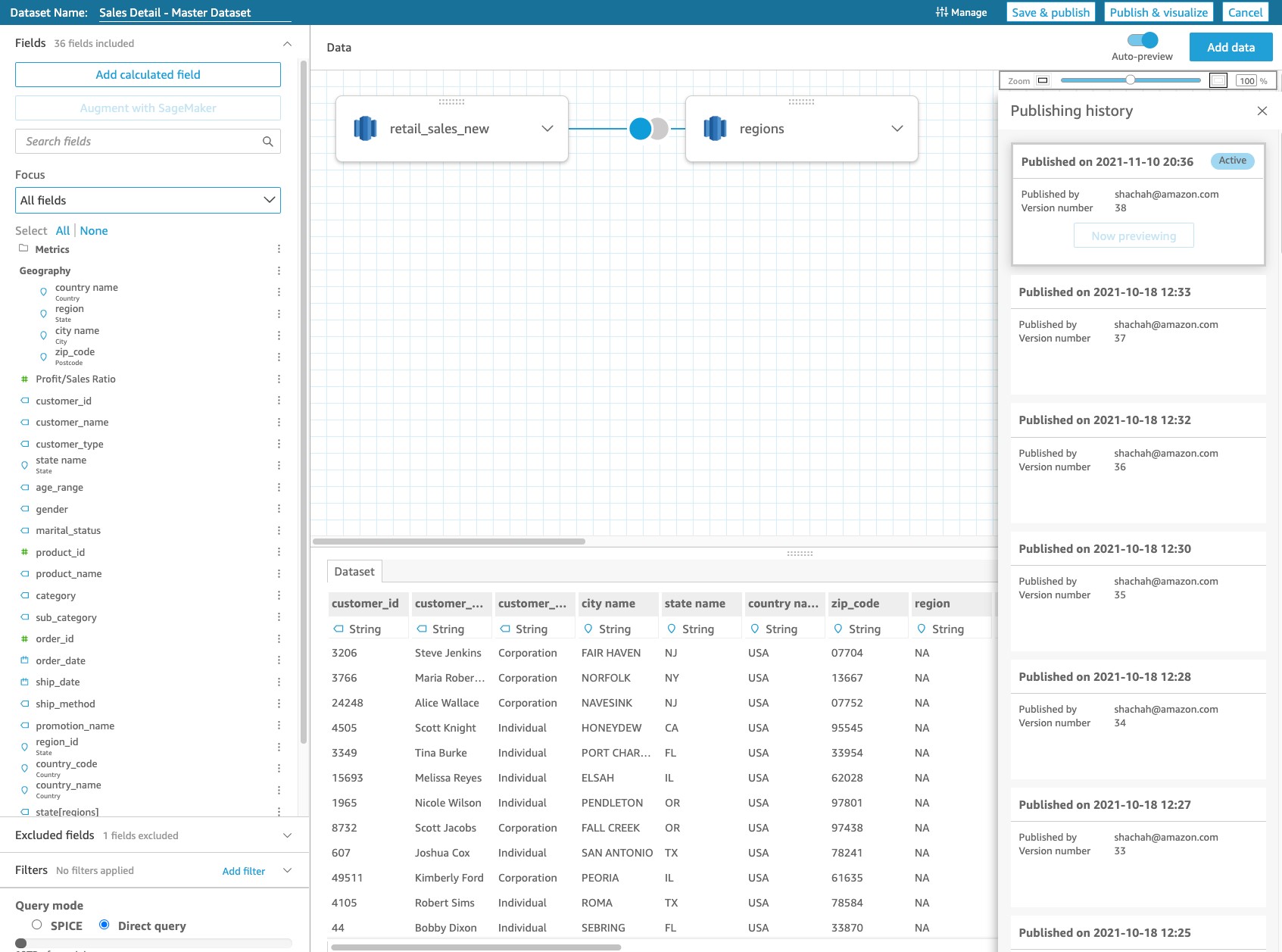
See publishing history
As you make changes to the dataset and publish the changes, QuickSight creates a timeline of all the publishes. You see the publishing history with all the events tracked as a tile. You can choose the tile to preview a particular version and see the respective dataset definition at that time. You know that the dataset was working fine on October 18, 2021 (the previous version), and you choose Preview to verify the dataset definition.
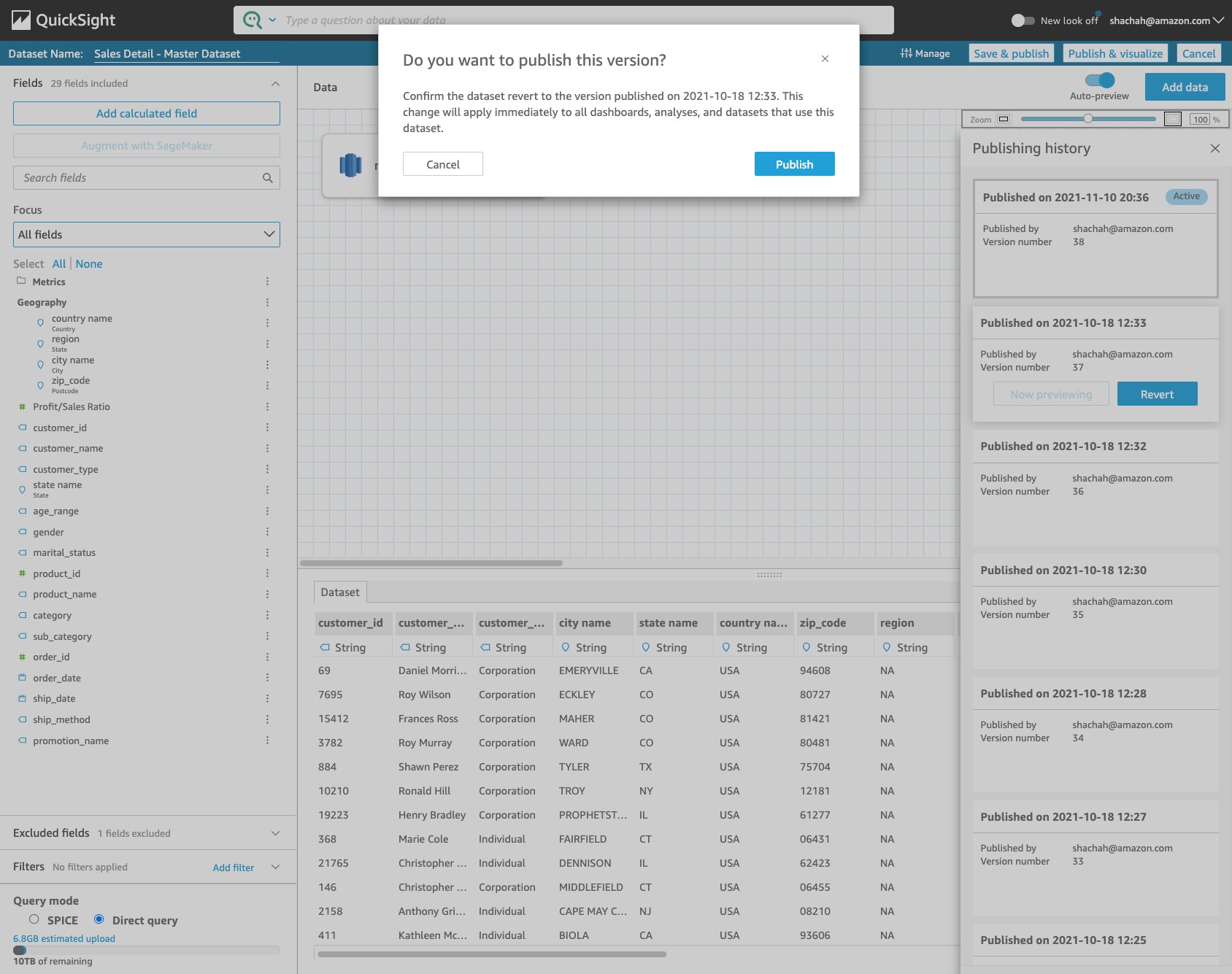
Revert back
After you confirm the dataset definition, choose Revert to go back the previous stable version (published on October 18, 2021). QuickSight asks you to confirm, and you choose Publish. The dataset reverts back to the old working definition and the dependent dashboards are fixed.
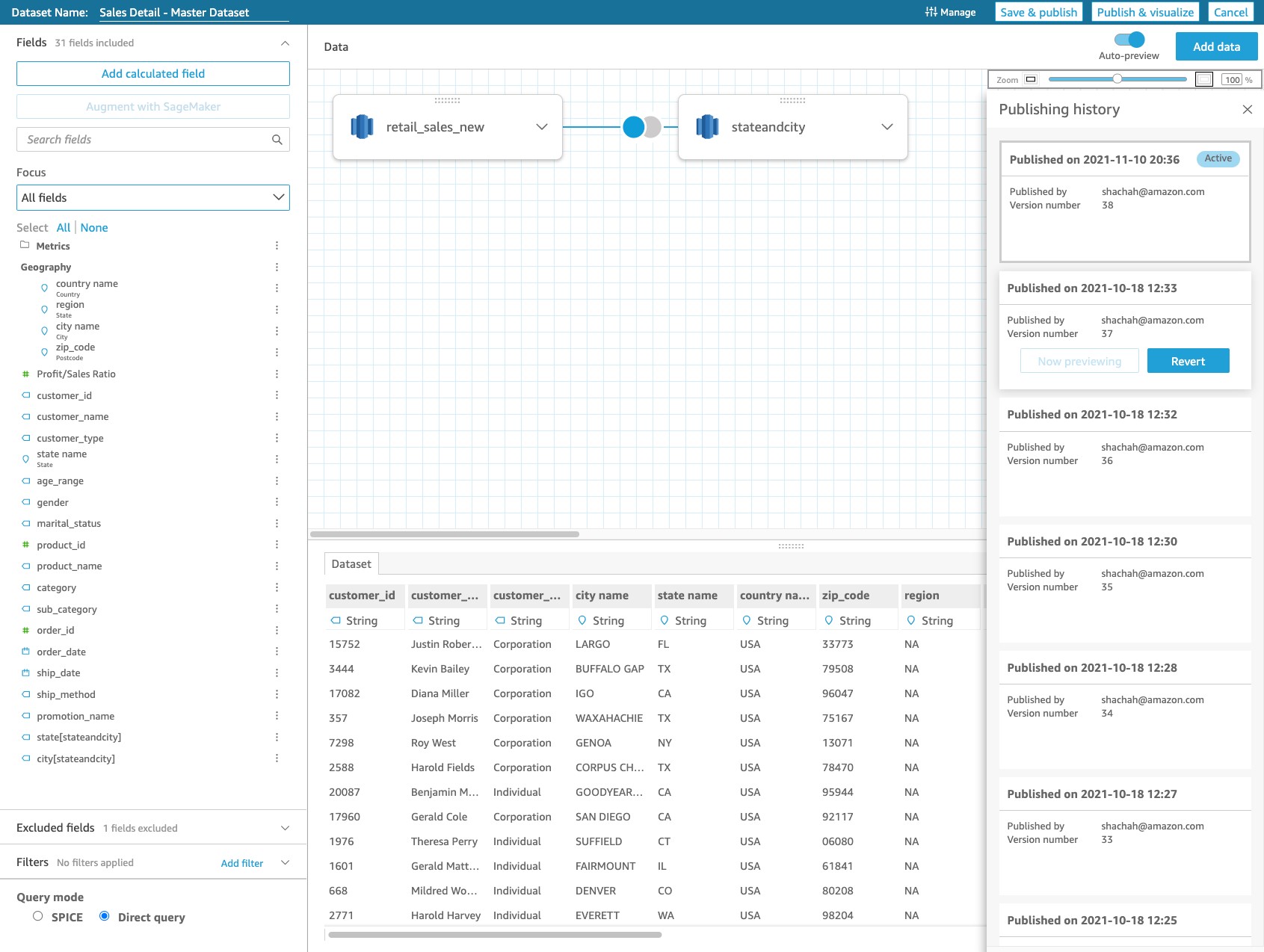
Start a new version
Alternatively, as you’re previewing the previously published good version (version 37, published October 18, 2021), you can start fresh from that version. The previous version just had the retail_sales_new table, and you can add the correct table stateandcity to the dataset definition. When you choose Publish, a new version (version 39) is created, and all the dashboards have this new working version, thereby fixing them.
Conclusion
This post showed how the new Dataset Versions feature in QuickSight helps you easily iterate on your datasets, showing you how a dataset has progressed over time and allowing you to revert back to a specific version. Dataset Versions gives you the freedom to experiment with your content, knowing that your older versions are available and you can revert back to them, if required. Dataset Versions is now generally available in QuickSight Standard and Enterprise Editions in all QuickSight Regions. For further details, visit see Dataset Versions.
About the Authors
 Shailesh Chauhan is a product manager for Amazon QuickSight, AWS’s cloud-native, fully managed SaaS BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from the ground up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with a great mind and big heart.
Shailesh Chauhan is a product manager for Amazon QuickSight, AWS’s cloud-native, fully managed SaaS BI service. Before QuickSight, Shailesh was global product lead at Uber for all data applications built from the ground up. Earlier, he was a founding team member at ThoughtSpot, where he created world’s first analytics search engine. Shailesh is passionate about building meaningful and impactful products from scratch. He looks forward to helping customers while working with people with a great mind and big heart.
 Mayank Jain is a Software Development Manager at Amazon QuickSight. He leads the data preparation team that delivers an enterprise-ready platform to transform, define and organize data. Before QuickSight, he was Senior Software Engineer at Microsoft Bing where he developed core search experiences. Mayank is passionate about solving complex problems with simplistic user experience that can empower customer to be more productive.
Mayank Jain is a Software Development Manager at Amazon QuickSight. He leads the data preparation team that delivers an enterprise-ready platform to transform, define and organize data. Before QuickSight, he was Senior Software Engineer at Microsoft Bing where he developed core search experiences. Mayank is passionate about solving complex problems with simplistic user experience that can empower customer to be more productive.