Post Syndicated from Nick Wood original https://blog.cloudflare.com/building-software-at-cloudflare/


Cloudflare provides a broad range of products — ranging from security, to performance and serverless compute — which are used by millions of Internet properties worldwide. Often, these products are built by multiple teams in close collaboration and delivering them can be a complex task. So ever wondered how we do so consistently and safely at scale?
Software delivery consists of all the activities to get working software into the hands of customers. It’s usual to talk about software delivery with reference to a model, or framework. These provide the scaffolding for most modern software delivery models, although in order to minimise operational friction it’s usual for a company to tailor their approach to suit their business context and culture.
For example, a company that designs the autopilot systems for passenger aircraft will require very strict tolerances, as a failure could cost hundreds of lives. They would want a different process to a cutting edge tech startup, who may value time to market over system uptime or stability.
Before outlining the approach we use at Cloudflare it’s worth quickly running through a couple of commonly used delivery models.
The Waterfall Approach
Waterfall has its foundations (pun intended) in construction and manufacturing. It breaks a project up into phases and presumes that each phase is completed before the next begins. Each phase “cascades” into the next bit like a waterfall, hence the name.
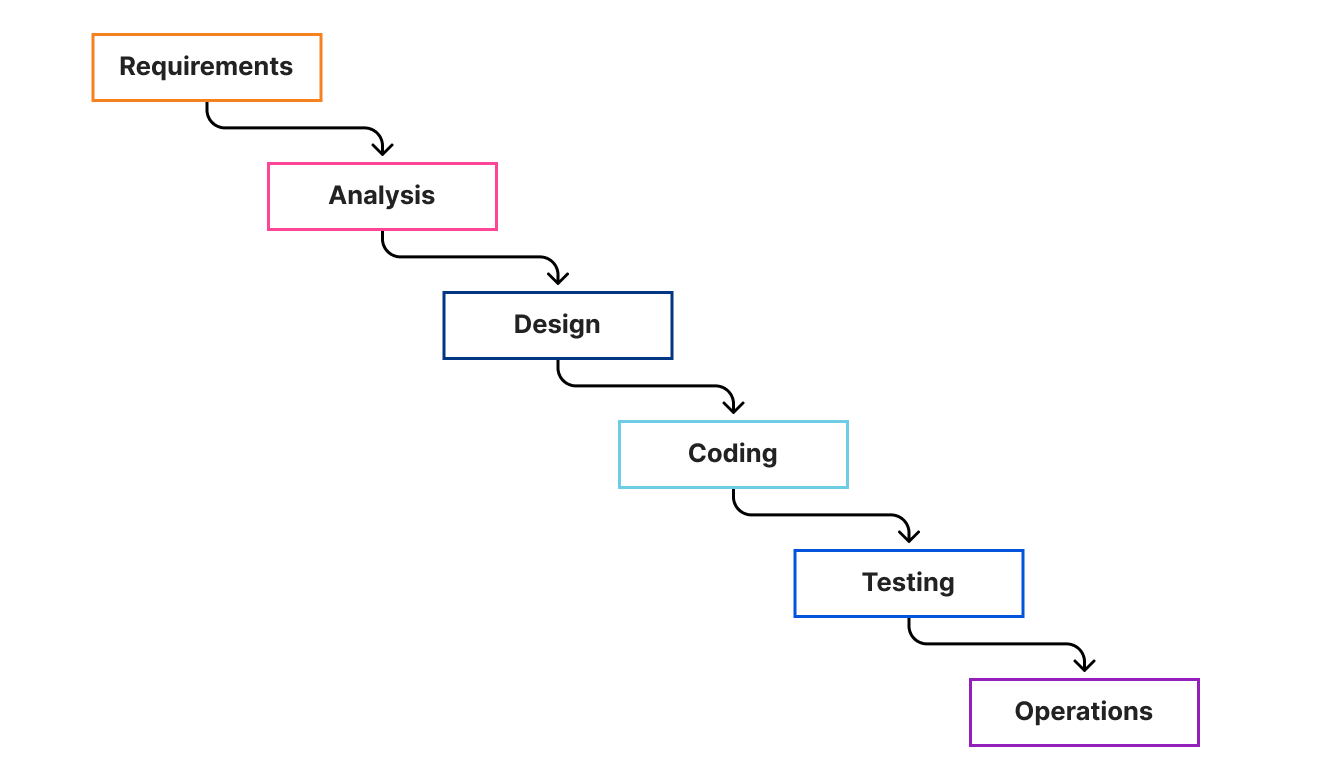
The main criticism of waterfall approaches arises when flaws are discovered downstream, which may necessitate a return to earlier phases — though this can be managed through governance processes that allows for adjusting scope, budgets or timelines.
More recently there are a number of modified waterfall models which have been developed as a response to its perceived inflexibility. Some notable examples are the Rational Unified Process (RUP), which encourages iteration within phases, and Sashimi which provides partial overlap between phases.
Despite falling out of favour in recent years, waterfall still has a place in modern technology companies. It tends to be reserved for projects where the scope and requirements can be defined upfront and are unlikely to change. At Cloudflare, we use it for infrastructure rollouts, for example. It also has a place in very large projects with complex dependencies to manage.
Agile Approaches
Agile isn’t a single well-defined process, rather a family of approaches which share similar philosophies — those of the agile manifesto. Implementations vary, but most agile flavours tend to share a number of common traits:
- Short release cycles, such that regular feedback (ideally from real users) can be incorporated.
- Teams maintain a prioritized to-do list of upcoming work (often called a ‘backlog’), with the most valuable items are at the top.
- Teams should be self-organizing, and work at a sustainable pace.
- A philosophy of Continuous Improvement, where teams seek to improve their ways of working over time.
Continuous improvement is very much the heart of agile, meaning these approaches are less about nailing down “the correct process” and focus more on regular reflection and change. This means variances between any two teams is expected, and encouraged.
Agile approaches can be divided into two main branches — iterative and flow-based. Scrum is probably the most prevalent of the iterative agile methods. In Scrum a team aims to build shippable increments of code at regular intervals called sprints (or “iterations”). Flow-based approaches on the other hand (such as Kanban) instead pick up new items from their backlog on an ad hoc basis. They use a number of techniques to try and minimise work in progress across the team.
The main differences between the two branches can be typified by looking at two example teams:
- The “Green” Team has a set of products they support and wants to update them regularly, production issues for them are rare and there is very little ad-hoc work. An iterative approach allows them to make long term plans whilst also being able to incorporate feedback from users with some regularity.
- The “Blue” Team meanwhile is an operational team, where a big part of their role is to monitor production systems and investigate issues as they arise. For them, a flow based approach is much more appropriate, so they can update their plans on the fly as new items arise.
Which approach does Cloudflare follow?
Cloudflare comprises dozens of globally distributed engineering teams each with their own unique challenges and contexts. A team usually has an Engineering Manager, a Product Manager and less than 10 engineers, who all focus on a singular product or mission. The DDoS team for example is one such team.
A team that supports a newly released product will likely want to rapidly incorporate feedback from customers, whereas a team that manages shared internal platforms will prize platform stability over speed of innovation. There is a spectrum of different contexts within Cloudflare which makes it impossible to define a single software delivery method for all teams to follow.
Instead, we take a more nuanced approach where we allow teams to decide which methodology they wish to follow within the team, whilst also defining a number of high-level concepts and language that are common to all teams. In other words, we are more concerned with macro-management than micro-management.
“SHIP”s and “Epic”s
At the highest level, our unit of work is called a “SHIP” — this is a change to a service or product which we intend to ship to customers, hence the name. All live SHIPs are published on our internal roadmap, called our “SHIP-board”. Transparency and collaboration are part of our DNA at Cloudflare, so for us, it’s important that anyone in Cloudflare can view the SHIP-board.
Individual SHIPs are sized such that they can be comfortably delivered within a month or two, though we have a strong preference towards shorter timescales. We’d much rather deliver three small feature sets monthly than one big launch every quarter.
A single SHIP might need work from multiple teams in order for customers to use it. We manage this by ensuring there is an EPIC within the SHIP for each team contributing. To prevent circular dependencies, a SHIP can’t contain another SHIP. SHIPs are owned by their Product Manager, and EPICs are usually owned by an Engineering Manager. We also allow for EPICs to be created that don’t deliver against SHIPs — this is where technical improvement initiatives are typically managed.
Below the level of EPICs we don’t enforce any strict delivery model on teams, though teams will usually link their contributory work to the EPIC for ease of tracking. Teams are free to use whichever delivery framework they wish.
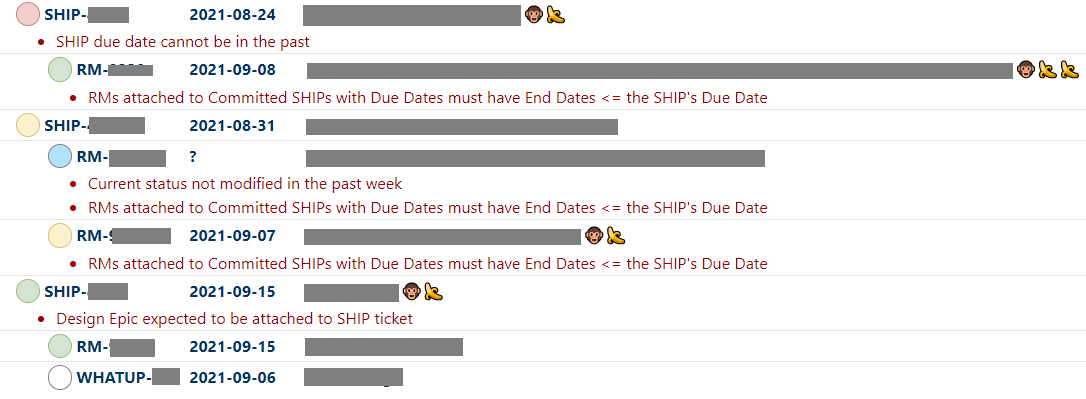
Within the Product Engineering organisation, all Product Managers and Engineering managers meet weekly to discuss progress and blockers of their live SHIPs/EPICs. Due to the number of people involved, this is a very rapid fire meeting facilitated by our automated “SHIP-board”. This has a built-in linter to highlight potential issues, to be updated prior to the meeting. We run through each team one by one, starting with the team with the most outstanding lints.
There’s also a few icons which let us visualise the status of a SHIP or EPIC at a glance. For example, a monkey means the target date for an item moved in the last week. Bananas count the total number of times the date has “slipped”, i.e. changed. A typical fragment of the SHIP-board is shown below.
Planning
Planning takes place every quarter. This lets us deliver aggressively, without having to change plans too frequently. It also forces us to make conscious choices about what to include and exclude from a SHIP so that extraneous work is minimised.
About a month before quarter-end, product managers will begin to compile the SHIPs that would deliver the most value to customers. They’ll work with their engineering teams to understand how the work might be done, and what work is required of other teams (e.g. the UI team might need to build a frontend whilst another team builds the API).
The team will likely estimate the work at this stage (though the exact mechanism is left up to them). Where work is required of other teams we’ll also begin to reach out to them, so they can factor it into their work for the quarter, and estimate their effort too. It’s also important at this stage to understand what kind of dependency this is — do we need one piece to fully complete before the other, or can they be done in parallel and integrated towards the end? Usually the latter.
The final aspect of planned work are unlinked EPICs — these are things that don’t necessarily contribute meaningfully to a SHIP, but the team would still like to get them completed. Examples of this are performance improvements, or changes/fixes to backend tooling.
We deliver continuously through the quarter to avoid a scramble of deployment at once, and our target dates will reflect that. We also allow anything delivered in the first two weeks of the following quarter to still count as being on-time — stability of the network is more important than hitting arbitrary dates.
We also take a fairly pragmatic approach towards target dates. A natural part of software delivery is that as we begin to explore the solution space we may uncover additional complexity. As long as we can justify a change of date it’s perfectly acceptable to amend the dates of SHIPs/EPICs to reflect the latest information. The exception to this is where we’ve made an external commitment to deliver something, so changing the delivery dates is subject to greater scrutiny.
Keeping us safe
You might think that letting teams set their own process might lead to chaos, but in my experience the opposite is true. By allowing teams to define their own methods we are empowering them to make better decisions and understand their own context within Cloudflare. We explicitly define the interfaces we use between teams, and that allows teams the flexibility to do what works best for them.
We don’t go as far as to say “there are no rules”. Last quarter Cloudflare blocked an average of 87 billion cyber threats each day, and in July 2021 we blocked the largest DDoS attack ever recorded. If we have an outage, our customers feel it, and we feel it too. To manage this we have strict, though simple, rules governing how code reaches our data centers. For example, we mandate a minimum number of reviews for each piece of code, and our deployments are phased so that changes are tested on a subset of live traffic, so any issues can be localised.
The main takeaway is to find the right balance between freedom and rules, and appreciate that this may vary for different teams within the organisation. Enforcing an unnecessarily strict process can cause a lot of friction in teams, and that’s a shortcut to losing great people. Our ideal process is one that minimises red tape, such that our team can focus on the hard job of protecting our customers.
P.S. — we’re hiring!
Do you want to come and work on advanced technologies where every code push impacts millions of Internet properties? Join our team!