Post Syndicated from Thom Wiggers original https://blog.cloudflare.com/post-quantum-formal-analysis/

An introduction to formal analysis and our proof of the security of KEMTLS

Good morning everyone, and welcome to another Post-Quantum–themed blog post! Today we’re going to look at something a little different. Rather than look into the past or future quantum we’re going to look as far back as the ‘80s and ‘90s, to try and get some perspective on how we can determine whether a protocol is or is not secure. Unsurprisingly, this question comes up all the time. Cryptographers like to build fancy new cryptosystems, but just because we, the authors, can’t break our own designs, it doesn’t mean they are secure: it just means we are not smart enough to break them.
One might at this point wonder why in a post-quantum themed blog post we are talking about security proofs. The reason is simple: the new algorithms that claim to be safe against quantum threats need proofs showing that they actually are safe. In this blog post, not only are we going to introduce how we go about proving a protocol is secure, we’re going to introduce the security proofs of KEMTLS, a version of TLS designed to be more secure against quantum computers, and give you a whistle-stop tour of the formal analysis we did of it.
Let’s go back for the moment to not being smart enough to break a cryptosystem. Saying “I tried very hard to break this, and couldn’t” isn’t a very satisfying answer, and so for many years cryptographers (and others) have been trying to find a better one. There are some obvious approaches to building confidence in your cryptosystem, for example you could try all previously known attacks, and see if the system breaks. This approach will probably weed out any simple flaws, but it doesn’t mean that some new attack won’t be found or even that some new twist on an old one won’t be discovered.
Another approach you can take is to offer a large prize to anyone who can break your new system; but to do that not only do you need a big prize that you can afford to give away if you’re wrong, you can’t be sure that everyone would prefer your prize to, for example, selling an attack to cybercriminals, or even to a government.
Simply trying hard, and inducing other people to do so too still felt unsatisfactory, so in the late ‘80s researchers started trying to use mathematical techniques to prove that their protocol was secure. Now, if you aren’t versed in theoretical computer science you might not even have a clear idea of what it even means to “prove” a protocol is secure, let alone how you might go about it, so let’s start at the very beginning.
A proof
First things first: let’s nail down what we mean by a proof. At its most general level, a mathematical proof starts with some assumptions, and by making logical inferences it builds towards a statement. If you can derive your target statement from your initial assumptions then you can be sure that, if your assumptions are right, then your final statement is true.
Euclid’s famous work, The Elements, a standard math textbook for over 2,000 years, is written in this style. Euclid gives five “postulates”, or assumptions, from which he can derive a huge portion of the geometry known in his day. Euclid’s first postulate, that you can draw a straight line between any two points, is never proven, but taken as read. You can take his first postulate, and his third, that you can draw a circle with any center and radius, and use it to prove his first proposition, that you can draw an equilateral triangle given any finite line. For the curious, you can find public-domain translations of Euclid’s work.
Whilst it’s fairly easy to intuit how such geometry proofs work, it’s not immediately clear how one could prove something as abstract as the security of a cryptographic protocol. Proofs of protocols operate in a similar way. We build a logical argument starting from a set of assumptions. Security proofs, however, can be much, much bigger than anything in The Elements (for example, our proof of the security properties of KEMTLS, which we will talk about later, is nearly 500,000 lines long) and the only reason we are able to do such complex proofs is that we have something of an advantage over Euclid. We have computers. Using a mix of human-guided theorem proving and automated algorithms we can prove incredibly complex things, such as the security of protocols as the one we will discuss.
Now we know that a proof is a set of logical steps built from a set of assumptions, let’s talk a bit about how security proofs work. First, we need to work out how to describe the protocol in terms that we can reason about. Over the years researchers have come up with many ways for describing computer processes mathematically, most famously Alan Turing defined a-machines, which we now know as Turing Machines, which describe a computer program in an algebraic form. A protocol is slightly more complex than a single program. A protocol can be seen as a number of computers running a set of computer programs that interact with each other.
We’re going to use a class of techniques called process algebras to describe the interacting processes of a protocol. At its most basic level, algebra is the art of generalizing a statement by replacing specific values with general symbols. In standard algebra, these specific values are numbers, so for example we can write (cos 37)² + (sin 37)² = 1, which is true, but we can generalize it to (cos θ)² + (sin θ)² = 1, replacing the specific value, 37, with the symbol θ.
Now you might be wondering why it’s useful to replace things with symbols. The answer is it lets us solve entire classes of problems instead of solving each individual instance. When it comes to security protocols, this is especially important. We can’t possibly try every possible set of inputs to a protocol and check nothing weird happens to one of them. In fact, one of the assumptions we’re going to make when we prove KEMTLS secure is that trying every possible value for some inputs is impossible1. By representing the protocol symbolically, we can write a proof that applies to all possible inputs of the protocol.
Let’s go back to algebra. A process algebra is similar to the kind of algebra you might have learnt in high school: we represent a computer program with symbols for the specific values. We also treat functions symbolically. Rather than try and compute what happens when we apply a function f to a value x, we just create a new symbol f(x). An algebra also provides rules for manipulating expressions. For example, in standard algebra we can transform y + 5 = x² - x into y = x² - x - 5. A process algebra is the same: it not only defines a language to describe interacting processes, it also defines rules for how we can manipulate those expressions.
We can use tools, such as the one we use called Tamarin, to help us do this reasoning. Every protocol has its own rules for what transformations are allowed. It is very useful to have a tool, like Tamarin, to which we can tell these rules and allow it to do all the work of symbol manipulation. Tamarin does far, far more than that, though.
A rule, that we tell Tamarin, might look like this:
rule Register_pk:
[ Fr(~ltkA) ]
--[ GenLtk($A, ~ltkA)]->
[ !Ltk($A, ~ltkA), !Pk($A, pk(~ltkA)), Out(pk(~ltkA)) ]
This rule is used to represent that a protocol participant has acquired a new public/private key pair. The rule has three parts:
- The first part lists the preconditions. In this case, there is only one: we take a
Fresh value called~ltkA, the “long-term key of A”. This precondition is always met, because Tamarin always allows us to generate fresh values. - The third part lists the postconditions (what we get back when we apply the rule). Rather than operating on an initial statement, as in high-school algebra, Tamarin instead operates on what we call a model of “bag of facts”. Instead of starting with
y + 5 = x² - x, we start with an empty “bag”, and from there, apply rules. These rules take facts out of the bag and put new ones in. In this case, we put in:!Ltk($A, ~ltkA)which represents the private portion of the key,~ltkA, and the name of the participant it was issued to,$A.!Pk($A, pk(~ltkA)), which represents the public portion of the key,pk(~ltkA), and the participant was issued to,$A.Out(pk(~ltkA)), which represents us publishing the public portion of the key,pk(~ltkA)to the network. Tamarin is based on the Dolev-Yao model, which assumes the attacker controls the network. Thus, this fact makes$A’s public key available to the attacker.
We can only apply a rule if the preconditions are met: the facts we need appear in the bag. By having rules for each step of the protocol, we can apply the rules in order and simulate a run of the protocol. But, as I’m sure you’ve noticed, we skipped the second part of the rule. The second part of the rule is where we list what we call actions.
We use actions to record what happened in a protocol run. In our example, we have the action GenLtk($A, ~ltkA). GenLtk means that a new Long-Term Key (LTK) has been Generated. Whenever we trigger the Register_pk rule, we note this with the two parameters:, $A, the party to whom the new key pair belongs; and ~ltkA, the private part of the generated key2.
If we simulate a single run of the protocol, we can record a list of all the actions executed and put them in a list. However, at any point in the protocol, there may be multiple rules that can be triggered. A list only captures a single run of a protocol, but we want to reason about all possible runs of the protocol. We can arrange our rules into a tree: every time we have multiple rules that could be executed, we give each one of them its own branch.
If we could write this entire tree, it would represent every possible run of the protocol. Because every possible run appears in this tree, if we can show that there are no “bad” runs on this tree, we can be sure that the protocol is “secure”. We put “bad” and “secure” in quotation marks here because we still haven’t actually defined what those terms actually mean.
But before we get to that, let’s quickly recap what we have so far. We have:
- A protocol we want to prove.
- A definition of protocol, as a number of computers running a set of computer programs that interact with each other.
- A technique, process algebras, to describe the interacting processes of the protocol: this technique provides us with symbols and rules for manipulating them.
- A tree that represents every possible run of the protocol.
We can reason about a protocol by looking at properties that our tree gives. As we are interested in cryptographic protocols, we would like to reason about its security. “Security” is a pretty abstract concept and its meaning changes in different contexts. In our case, to prove something is secure, we first have to say what our security goals are. One thing we might want to prove is, for example, that an attacker can never learn the encryption key of a session. We capture this idea with a reachability lemma.
A reachability lemma asks whether there is a path in the tree that leads to a specific state: can we “reach” this state? In this case, we ask: “can we reach a state where the attacker knows the session key?” If the answer is “no”, we are sure that our protocol has that property (an attacker never learns the session key), or at least that that property is true in our protocol model.
So, if we want to prove the security of a cryptographic protocol, we need to:
- Define the goals of the security that is being proven.
- Describe the protocol as an interacting process of symbols, rules, and expressions.
- Build a tree of all the steps the protocol can take.
- Check that the trees of protocol runs attain the goals of security we specified.
This process of creating a model of a program and writing rigorous proofs about that model is called “formal analysis”.
Writing formal proofs of protocol correctness has been very effective at finding and fixing all kinds of issues. During the design of TLS 1.3, for example, it uncovered a number of serious security flaws that were eventually fixed prior to standardization. However, something we need to be wary of with formal analysis is being over-reliant on its results. It’s very possible to be so taken with the rigour of the process and of its mathematical proofs, that the result gets overinterpreted. Not only can a mistake exist in a proof, even in a machine-checked one, the proof may not actually prove what you think it does. There are many examples of this: Needham-Schroeder had a proof of security written in the BAN logic, before Lowe found an attack on a case that the BAN logic did not cover.
In fact, the initial specification of the TLS 1.3 proof made the assumption that nobody uses the same certificate for both a client and a server, even though this is not explicitly disallowed in the specification. This gap led to the “Selfie” vulnerability where a client could be tricked into connecting to itself, potentially leading to resource exhaustion attacks.
Formal analysis of protocol designs also tells you nothing about whether a particular implementation correctly implements a protocol. In other blog posts, we will talk about this. Let’s now return to our core topic: the formal analysis of KEMTLS.
Proving KEMTLS’s security
Now that we have the needed notions, let’s get down to the nitty-gritty: we show you how we proved KEMTLS is secure. KEMTLS is a proposal to do authentication in TLS handshakes using key exchange (via key encapsulation mechanisms or KEMs). KEMTLS examines the trade-offs between post-quantum signature schemes and post-quantum key exchange, as we discussed in other blog posts.
The main idea of KEMTLS is the following: instead of using a signature to prove that you have access to the private key that corresponds to the (signing) public key in the certificate presented, we derive a shared secret encapsulated to a (KEM) public key. The party that presented the certificate can only derive (decapsulate) it from the resulting encapsulation (often also called the ciphertext) if they have access to the correct private key; and only then can they read encrypted traffic. A brief overview of how this looks in the “traditional arrows on paper” form is given below.
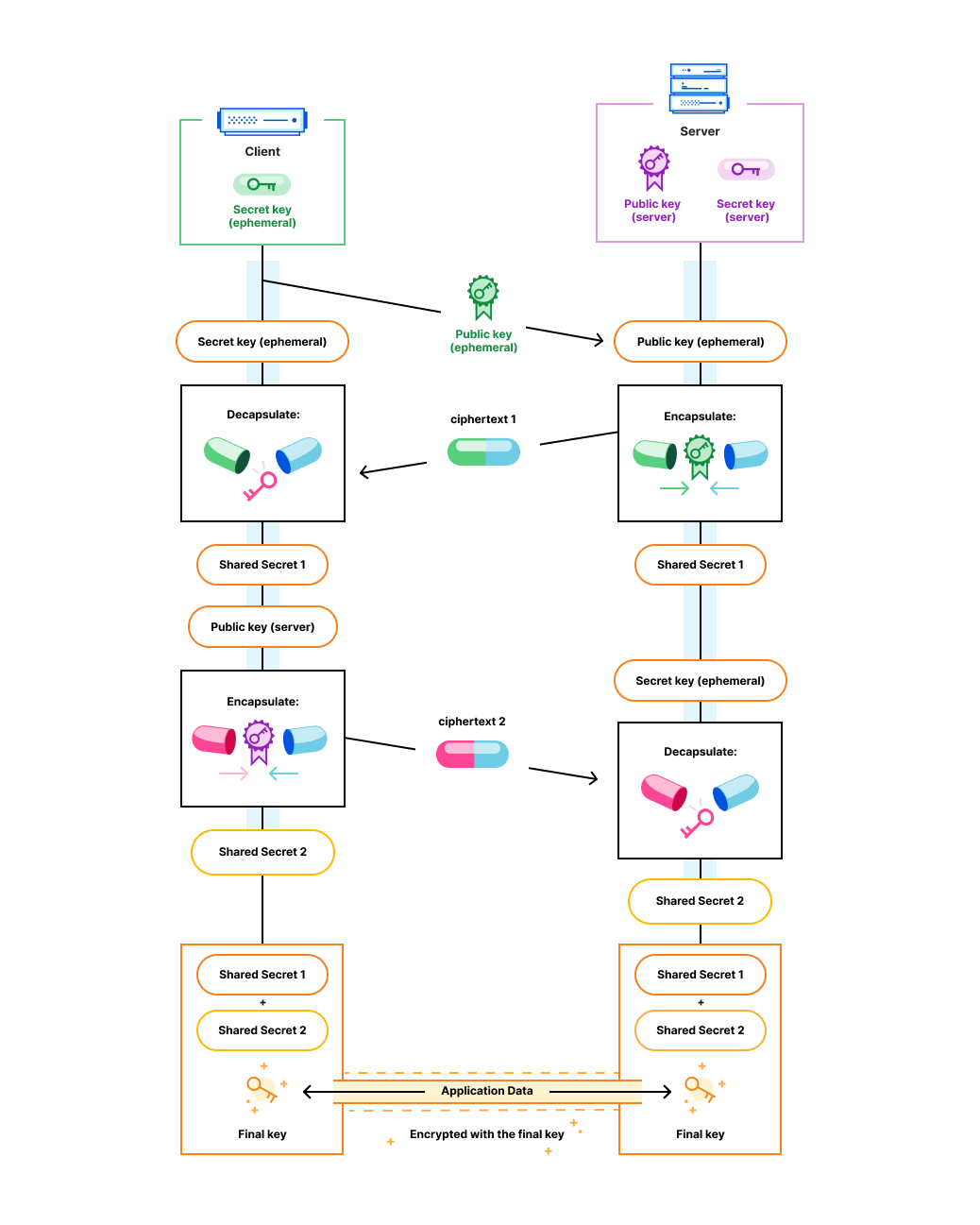
We want to show that the KEMTLS handshake is secure, no matter how an adversary might mess with, reorder, or even create new protocol messages. Symbolic analysis tools such as Tamarin or ProVerif are well suited to this task: as said, they allow us to consider every possible combination or manipulation of protocol messages, participants, and key information. We can then write lemmas about the behavior of the protocol.
Why prove it in Tamarin?
There exists a pen-and-paper proof of the KEMTLS handshake. You might ask: why should we still invest the effort of modeling it in a tool like Tamarin?
Pen-and-paper proofs are in theory fairly straightforward. However, they are very hard to get right. We need to carefully express the security properties of the protocol, and it is very easy to let assumptions lead you to write something that your model does not correctly cover. Verifying that a proof has been done correctly is also very difficult and requires almost as much careful attention as writing the proof itself. In fact, several mistakes in definitions of the properties of the model of the original KEMTLS proof were found, after the paper had been accepted and published at a top-tier security conference.
💡 For those familiar with these kinds of game-based proofs, another “war story”: while modeling the ephemeral key exchange, the authors of KEMTLS initially assumed all we needed was an IND-CPA secure KEM. After writing out all the simulations in pseudo code (which is not part of the proof or the paper otherwise!), it turned out that we needed an additional oracle to answer a single decapsulation query, resulting in requiring a weaker variant of IND-CCA security of our KEM (namely, IND-1CCA security). Using an “only” IND-CPA-secure KEM turned out to not be secure!
Part of the problem with pen-and-paper proofs is perhaps the human nature to read between the lines: we quickly figure out what is intended by a certain sentence, even if the intent is not strictly clarified. Computers do not allow that: to everyone’s familiar frustration whenever a computer has not done what you wanted, but just what you told it to do.
A benefit of computer code, though, is that all the effort is in writing the instructions. A carefully constructed model and proof result in an executable program: verifying should be as simple as being able to run it to the end. However, as always we need to:
- Be very careful that we have modeled the right thing and,
- Note that even the machine prover might have bugs: this second computer-assisted proof is a complement to, and not a replacement of, the pen-and-paper proof.
Another reason why computer proofs are interesting is because they give the ability to construct extensions. The “pre-distributed keys” extension of KEMTLS, for example, has been only proven on paper in isolation. Tamarin allows us to construct that extension in the same space as the main proof, which will help rule out any cross-functional attacks. With this, the complexity of the proof is increased exponentially, but Tamarin allows us to handle that just by using more computer power. Doing the same on paper requires very, very careful consideration.
One final reason we wanted to perform this computer analysis is because whilst the pen-and-paper proof was in the computational model, our computer analysis is in the symbolic model. Computational proofs attain “high resolution” proofs, giving very tight bounds on exactly how secure a protocol is. Symbolic models are “low resolution”: giving a binary yes/no answer on whether a protocol meets the security goals (with the assumption that the underlying cryptographic primitives are secure). This might sound like computational proofs are the best: their downside is that one has to simplify the model in other areas. The computational proof of KEMTLS, for example, does not model TLS message formats, which a symbolic model can.
Modeling KEMTLS in Tamarin
Before we can start making security claims and asking Tamarin to prove them, we first need to explain to Tamarin what KEMTLS is. As we mentioned earlier, Tamarin treats the world as a “bag of facts”. Keys, certificates, identities, and protocol messages are all facts. Tamarin can take those facts and apply rules to them to construct (or deconstruct) new facts. Executing steps in the KEMTLS protocol is, in a very literal sense, just another way to perform such transformations — and if everything is well-designed, the only “honest” way to reach the end state of the protocol.
We need to start by modeling the protocol. We were fortunate to be able to reuse the work of Cremers et al., who contributed their significant modeling talent to the TLS 1.3 standardization effort. They created a very complete model of the TLS 1.3 protocol, which showed that the protocol is generally secure. For more details, see their paper.
We modified the ephemeral key exchange by substituting the Diffie-Hellman operations in TLS 1.3 with the appropriate KEM operations. Similarly, we modified the messages that perform the certificate handling: instead of verifying a signature, we send back a KemEncapsulation message with the ciphertext. Let’s have a look at one of the changed rules. Don’t worry, it looks a bit scary, but we’re going to break it down for you. And also, don’t worry if you do not grasp all the details: we will cover the most necessary bits when they come up again, so you can also just skip to the next section “Modeling the adversary” instead.
rule client_recv_server_cert_emit_kex:
let
// … snip
ss = kemss($k, ~saseed)
ciphertext = kemencaps($k, ss, certpk)
// NOTE: the TLS model uses M4 preprocessor macros for notation
// We also made some edits for clarity
in
[
State(C2d, tid, $C, $S, PrevClientState),
In(senc{<'certificate', certpk>}hs_keys),
!Pk($S, certpk),
Fr(~saseed)
]
--[
C2d(tid),
KemEncap($k, certpk, ss)
]->
[
State(C3, tid, $C, $S, ClientState),
Out(senc{<'encaps', ciphertext>}hs_keyc)
]
This rule represents the client getting the server’s certificate and encapsulating a fresh key to it. It then sends the encapsulated key back to the server.
Note that the let … in part of the rule is used to assign expressions to variables. The real meat of the rule starts with the preconditions. As we can see, in this rule there are four preconditions that Tamarin needs to already have in its bag for this rule to be triggered:
- The first precondition is
State(C2d, …). This condition tells us that we have some client that has reached the stageC2d, which is what we call this stage in our representation. The remaining variables define the state of that client. - The second precondition is an
Inone. This is how Tamarin denotes messages received from the network. As we mentioned before, we assume that the network is controlled by the attacker. Until we can prove otherwise, we don’t know whether this message was created by the honest server, if it has been manipulated by the attacker, or even forged. The message contents,senc{<'certificate', certpk>}hs_keys, is symmetrically encrypted (senc{}) under the server’s handshake key (we’ve slightly edited this message for clarity, and removed various other bits to keep this at least somewhat readable, but you can see the whole definition in our model). - The third precondition states the public key of the server,
!Pk(S, certpk). This condition is preceded by a!symbol, which means that it’s a permanent fact to be consumed many times. Usually, once a fact is removed from the bag, it is gone; but permanent facts remain.Sis the name of the server, andcertpkis the KEM public key. - The fourth precondition states the fresh random value,
~saseed.
The postconditions of this rule are a little simpler. We have:
State(C3, …), which represents that the client (which was at the start of the rule in stateC2d) is now in stateC3.Out(senc{<'encaps', ciphertext>}hs_keyc), which represents the action of the client sending the encapsulated key to the network, encrypted under the client’s handshake key.
The four actions recorded in this rule are:
- First, we record that the client with thread id
tidreached the stateC2d. - Second and third, we record that the client was running the protocol with various intermediate values. We use the phrase “running with” to indicate that although the client believes these values to be the correct, it can’t yet be certain that they haven’t been tampered with, so the client hasn’t committed yet to them.
- Finally, we record the parameters we put into the KEM with the
KemEncapaction.
We modify and add such rules to the TLS 1.3 model, so we can run KEMTLS instead of TLS 1.3. For a sanity check, we need to make sure that the protocol can actually be executed: a protocol that can not run, can not leak your secrets. We use a reachability lemma to do that:
lemma exists_C2d:
exists-trace
"Ex tid #j. C2d(tid)@#j"
This was the first lemma that we asked Tamarin to prove. Because we’ve marked this lemma exists-trace, it does not need to hold in all traces, all runs of the protocol. It just needs one. This lemma asks if there exists a trace ( exists-trace), where there exists ( Ex ) a variable tid and a time #j (times are marked with #) at which action C2d(tid) is recorded. What this captures is that Tamarin could find a branch of the tree where the rule described above was triggered. Thus, we know that our model can be executed, at least as far as C2d.
Modeling the adversary
In the symbolic model, all cryptography is perfect: if the adversary does not have a particular key, they can not perform any deconstructions to, for example, decrypt a message or decapsulate a ciphertext. Although a proof with this default adversary would show the protocol to be secure against, for example, reordering or replaying messages, we want it to be secure against a slightly stronger adversary. Fortunately, we can model this adversary. Let’s see how.
Let’s take an example. We have a rule that honestly generates long-term keys (certificates) for participants:
rule Register_pk:
[ Fr(~ltkA) ]
--[ GenLtk($A, ~ltkA) ]->
[ !Ltk($A, ~ltkA),
!Pk($A, kempk($k, ~ltkA)),
Out(kempk($k, ~ltkA))
]
This rule is very similar to the one we saw at the beginning of this blog post, but we’ve tweaked it to generate KEM public keys. It goes as follows: it generates a fresh value, and registers it as the actor $A’s long-term private key symbol !Ltk and $A’s public key symbol !Pk that we use to model our certificate infrastructure. It also sends ( Out ) the public key to the network such that the adversary has access to it.
The adversary can not deconstruct symbols like Ltk without rules to do so. Thus, we provide the adversary with a special Reveal query, that takes the !Ltk fact and reveals the private key:
rule Reveal_Ltk:
[ !Ltk($A, ~ltkA) ] --[ RevLtk($A) ]-> [ Out(~ltkA) ]
Executing this rule registers the RevLtk($A) action, so that we know that $A’s certificate can no longer be trusted after RevLtk occurred.
Writing security lemmas
KEMTLS, like TLS, is a cryptographic handshake protocol. These protocols have the general goal to generate session keys that we can use to encrypt user’s traffic, preferably as quickly as possible. One thing we might want to prove is that these session keys are secret:
lemma secret_session_keys [/*snip*/]:
"All tid actor peer kw kr aas #i.
SessionKey(tid, actor, peer, <aas, 'auth'>, <kw, kr>)@#i &
not (Ex #r. RevLtk(peer)@#r & #r < #i) &
not (Ex tid3 esk #r. RevEKemSk(tid3, peer, esk)@#r & #r < #i) &
not (Ex tid4 esk #r. RevEKemSk(tid4, actor, esk)@#r & #r < #i)
==> not Ex #j. K(kr)@#j"
This lemma states that if the actor has completed the protocol and the attacker hasn’t used one of their special actions, then the attacker doesn’t know the actor’s read key, kr. We’ll go through the details of the lemma in a moment, but first let’s address some questions you might have about this proof statement.
The first question that might arise is: “If we are only secure in the case the attacker doesn’t use their special abilities then why bother modeling those abilities?” The answer has two parts:
- We do not restrict the attacker from using their abilities: they can compromise every key except the ones used by the participants in this session. If they managed to somehow make a different participant use the same ephemeral key, then this lemma wouldn’t hold, and we would not be able to prove it.
- We allow the attacker to compromise keys used in this session after the session has completed. This means that what we are proving is: an attacker who recorded this session in the past and now has access to the long-term keys (by using their shiny new quantum computer, for example) can’t decrypt what happened in the session. This property is also known as forward secrecy.
The second question you might ask is: “Why do we only care about the read key?”. We only care about the read key because this lemma is symmetric, it holds for all actors. When a client and server have established a TLS session, the client’s read key is the server’s write key and vice versa. Because this lemma applies symmetrically to the client and the server, we prove that the attacker doesn’t know either of those keys.
Let’s return now to the syntax of this lemma.
This first line of this lemma is a “For all” statement over seven variables, which means that we are trying to prove that no matter what values these seven variables hold, the rest of the statement is true. These variables are:
- the thread id
tid, - a protocol participant,
actor, - the person they think they’re talking to,
peer, - the final read and write keys,
krandkwrespectively, - the actor’s authentication status,
aas, - and a time
#i.
The next line of the lemma is about the SessionKey action. We record the SessionKey action when the client or the server thinks they have completed the protocol.
The next lines are about two attacker abilities: RevLtk, as discussed earlier; and RevEKemSk, which the attacker can use to reveal ephemeral secrets. The K(x) action means that the attacker learns (or rather, Knows) x. We, then, assert that if there does not Exist a RevEKemSk or RevLtk action on one of the keys used in the session, then there also does not exist a time when K(kr) (when the attacker learns the read key). Quod erat demonstrandum. Let’s run the proofs now.
Proving lemmas in Tamarin
Tamarin offers two methods to prove security lemmas: it has an autoprover that can try to find the solution for you, or you can do it manually. Tamarin sometimes has a hard time figuring out what is important for proving a particular security property, and so manual effort is sometimes unavoidable.
The manual prover interface allows you to select what goal Tamarin should pursue step by step. A proof quickly splits into separate branches: in the picture, you see that Tamarin has already been able to prove the branches that are green, leaving us to make a choice for case 1.
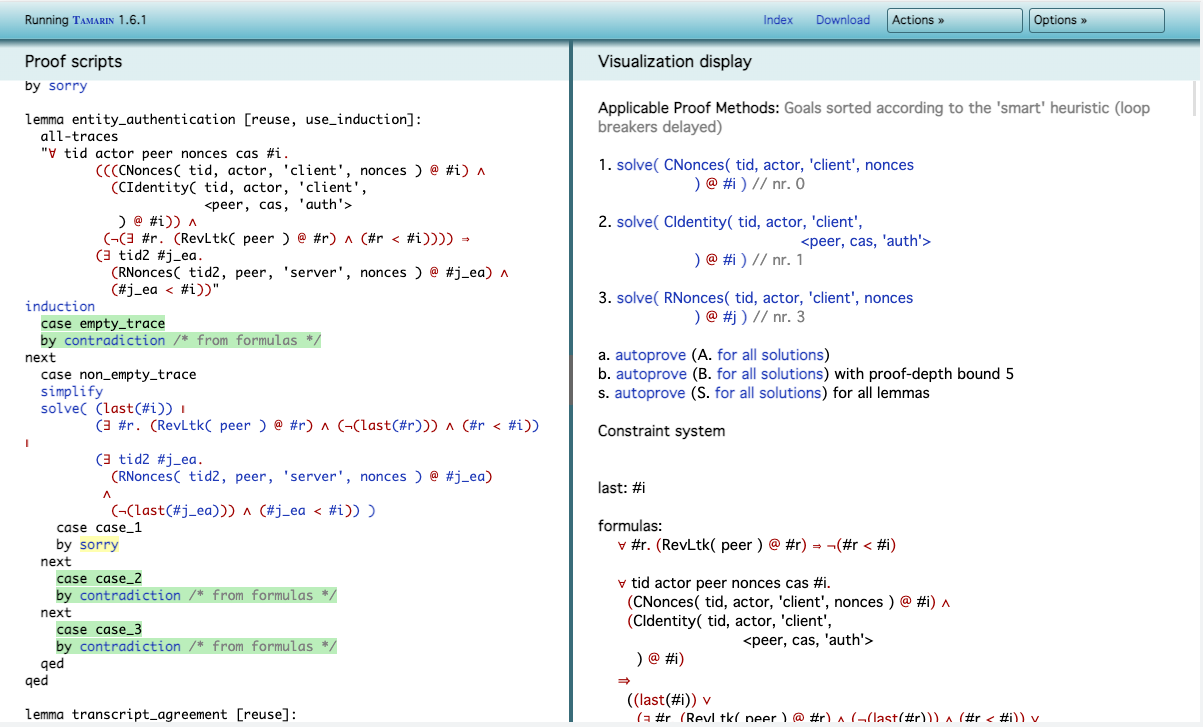
Sometimes whilst working in the manual interface, you realize that there are certain subgoals that Tamarin is trying to prove while working on a bigger lemma. By writing what we call a helper lemma we can give Tamarin a shortcut of sorts. Rather than trying to solve all the subgoals of one big lemma, we can split the proof into more digestible chunks. Tamarin can then later reuse these helper lemmas when trying to prove bigger lemmas; much like factoring out functions while programming. Sometimes this even allows us to make lemmas auto-provable. Other times we can extract the kinds of decisions we’re making and heuristics we’re manually applying into a separate “oracle” script: a script that interacts with Tamarin’s prover heuristics on our behalf. This can also automate proving tricky lemmas.
Once you realize how much easier certain things are to prove with helper lemmas, you can get a bit carried away. However, you quickly find that Tamarin is being “distracted” by one of the helper lemmas and starts going down long chains of irrelevant reasoning. When this happens, you can hide the helper lemma from the main lemma you’re trying to prove, and sometimes that allows the autoprover to figure out the rest.
Unfortunately, all these strategies require a lot of intuition that is very hard to obtain without spending a lot of time hands-on with Tamarin. Tamarin can sometimes be a bit unclear about what lemmas it’s trying to apply. We had to resort to tricks, like using unique, highly recognizable variable names in lemmas, such that we can reconstruct where a certain goal in the Tamarin interface is coming from.
While doing this work, auto-proving lemmas has been incredibly helpful. Each time you make a tiny change in either a lemma (or any of the lemmas that are reused by it) or in the whole model, you have to re-prove everything. If we needed to put in lots of manual effort each time, this project would be nowhere near done.
This was demonstrated by two bugs we found in one of the core lemmas of the TLS 1.3 model. It turned out that after completing the proof, some refactoring changes were made to the session_key_agreement lemma. These changes seemed innocent, but actually changed the meaning of the lemma, so that it didn’t make sense anymore (the original definition did cover the right security properties, so luckily this doesn’t cause a security problem). Unfortunately, this took a lot of our time to figure out. However, after a huge effort, we’ve done it. We have a proof that KEMTLS achieves its security goals.
Conclusions
Formal methods definitely have a place in the development of security protocols; the development process of TLS 1.3 has really demonstrated this. We think that any proposal for new security protocols should be accompanied by a machine-verified proof of its security properties. Furthermore, because many protocols are currently specified in natural language, formal specification languages should definitely be under consideration. Natural language is inherently ambiguous, and the inevitable differences in interpretation that come from that lead to all kinds of problems.
However, this work cannot be done by academics alone. Many protocols come out of industry who will need to do this for themselves. We would be the first to admit that the usability of these tools for non-experts is not all the way there yet — and industry and academia should collaborate on making these tools more accessible for everyone. We welcome and look forward to these collaborations in the future!
References
- “Why does cryptographic software fail?: a case study and open problems” by David Lazar, Haogang Chen, Xi Wang and Nickolai Zeldovich
- “SoK: Computer-Aided Cryptography” by Manuel Barbosa, Gilles Barthe, Karthik Bhargavan, Bruno Blanchet, Cas Cremers, Kevin Liao and Bryan Parno
- “Post-quantum TLS without handshake signatures” by Peter Schwabe and Douglas Stebila and Thom Wiggers(*)
- “More efficient post-quantum KEMTLS with pre-distributed public keys” by Peter Schwabe and Douglas Stebila and Thom Wiggers (*)
- “On computable numbers, with an application to the Entscheidungsproblem.” by Alan Turing
- “A comprehensive symbolic analysis of TLS 1.3.” by Cas Cremers, Marko Horvat, Jonathan Hoyland, Sam Scott, and Thyla van der Merwe (*)
- “A Logic of Authentication” by Michael Burrows, Martin Abadi, and Roger Michael Needham
* The authors of this blog post were authors on these papers
…..
1Of course, trying every value isn’t technically impossible, it’s just infeasible, so we make the simplifying assumption that it’s impossible, and just say our proof only applies if the attacker can’t just try every value. Other styles of proof that don’t make that assumption are possible, but we’re not going to go into them.
2For simplicity, this representation assumes that the public portion of a key pair can be derived from the private part, which may not be true in practice. Usually this simplification won’t affect the analysis.