Post Syndicated from Sam Mokhtari original https://aws.amazon.com/blogs/big-data/integrate-aws-glue-schema-registry-with-the-aws-glue-data-catalog-to-enable-effective-schema-enforcement-in-streaming-analytics-use-cases/
Metadata is an integral part of data management and governance. The AWS Glue Data Catalog can provide a uniform repository to store and share metadata. The main purpose of the Data Catalog is to provide a central metadata store where disparate systems can store, discover, and use that metadata to query and process the data.
Another important aspect of data governance is serving and managing the relationship between data stores and external clients, which are the producers and consumers of data. As the data evolves, especially in streaming use cases, we need a central framework that provides a contract between producers and consumers to enable schema evolution and improved governance. The AWS Glue Schema Registry provides a centralized framework to help manage and enforce schemas on data streaming applications using convenient integrations with Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Kinesis Data Streams, Apache Flink and Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda.
In this post, we demonstrate how to integrate Schema Registry with the Data Catalog to enable efficient schema enforcement in streaming analytics use cases.
Stream analytics on AWS
There are many different scenarios where customers want to run stream analytics on AWS while managing the schema evolution effectively. To manage the end-to-end stream analytics life cycle, there are many different applications involved for data production, processing, analytics, routing, and consumption. It can be quite hard to manage changes across different applications for stream analytics use cases. Adding/removing a data field across different stream analytics applications can lead to data quality issues or downstream application failures if it is not managed appropriately.
For example, a large grocery store may want to send orders information using Amazon KDS to it’s backend systems. While sending the order information, customer may want to make some data transformations or run analytics on it. The orders may be routed to different targets depending upon the type of orders and it may be integrated with many backend applications which expect order stream data in specific format. But the order details schema can change due to many different reasons such as new business requirements, technical changes, source system upgrades or something else.
The changes are inevitable but customers want a mechanism to manage these changes effectively while running their stream analytics workloads. To support stream analytics use cases on AWS and enforce schema and governance, customers can make use of AWS Glue Schema Registry along with AWS Stream analytics services.
You can use Amazon Kinesis Data Firehose data transformation to ingest data from Kinesis Data Streams, run a simple data transformation on a batch of records via a Lambda function, and deliver the transformed records to destinations such as Amazon Simple Storage Service (Amazon S3), Amazon Redshift, Amazon OpenSearch Service, Splunk, Datadog, NewRelic, Dynatrace, Sumologic, LogicMonitor, MongoDB, and an HTTP endpoint. The Lambda function transforms the current batch of records with no information or state from previous batches.
Lambda function also has the stream analytics capability for Amazon Kinesis Data Analytics and Amazon DynamoDB. This feature enables data aggregation and state management across multiple function invocations. This capability uses a tumbling window, which is a fixed-size, non-overlapping time interval of up to 15 minutes. When you apply a tumbling window to a stream, records in the stream are grouped by window and sent to the processing Lambda function. The function returns a state value that is passed to the next tumbling window.
Kinesis Data Analytics provides SQL-based stream analytics against streaming data. This service also enables you to use an Apache Flink application to process stream data. Data can be ingested from Kinesis Data Streams and Kinesis Data Firehose while supporting Kinesis Data Firehose (Amazon S3, Amazon Redshift, Amazon OpenSearch Service, and Splunk), Lambda, and Kinesis Data Streams as destinations.
Finally, you can use the AWS Glue streaming extract, transform, and load (ETL) capability as a serverless method to consume data from Kinesis and Apache Kafka or Amazon MSK. The job aggregates, transforms, and enriches the data using Spark streaming, then continuously loads the results into Amazon S3-based data lakes, data warehouses, DynamoDB, JDBC, and more.
Managing stream metadata and schema evolution is becoming more important for stream analytics use cases. To enable these on AWS, the Data Catalog and Schema Registry allow you to centrally control and discover schemas. Before the release of schema referencing in the Data Catalog, you relied on managing schema evolution separately in the Data Catalog and Schema Registry, which usually leads to inconsistencies between these two. With the new release of the Data Catalog and Schema Registry integration, you can now reference schemas stored in the schema registry when creating or updating AWS Glue tables in the Data Catalog. This helps avoid inconsistency between the schema registry and Data Catalog, which results in end-to-end data quality enforcement.
In this post, we walk you through a streaming ETL example in AWS Glue to better showcase how this integration can help. This example includes reading streaming data from Kinesis Data Streams, schema discovery with Schema Registry, using the Data Catalog to store the metadata, and writing out the results to an Amazon S3 as a sink.
Solution overview
The following high-level architecture diagram shows the components to integrate Schema Registry and the Data Catalog to run streaming ETL jobs. In this architecture, Schema Registry helps centrally track and evolve Kinesis Data Streams schemas.
At a high level, we use the Amazon Kinesis Data Generator (KDG) to stream data to a Kinesis data stream, use AWS Glue to run streaming ETL, and use Amazon Athena to query the data.
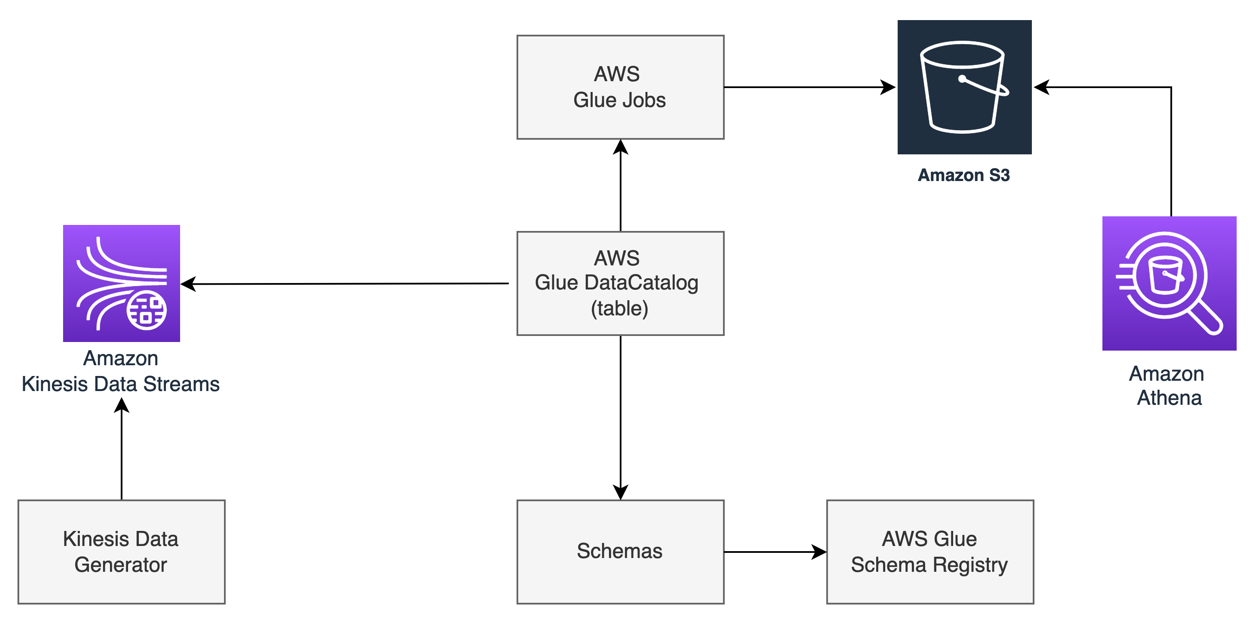
In the following sections, we walk you through the steps to build this architecture.
Create a Kinesis data stream
To set up a Kinesis data stream, complete the following steps:
- On the Kinesis console, choose Data streams.
- Choose Create data stream.
- Give the stream a name, such as
ventilator_gsr_stream. - Complete stream creation.
Configure Kinesis Data Generator to generate sample data
You can use the KDG with the ventilator template available on the GitHub repo to generate sample data. The following diagram shows the template on the KDG console.
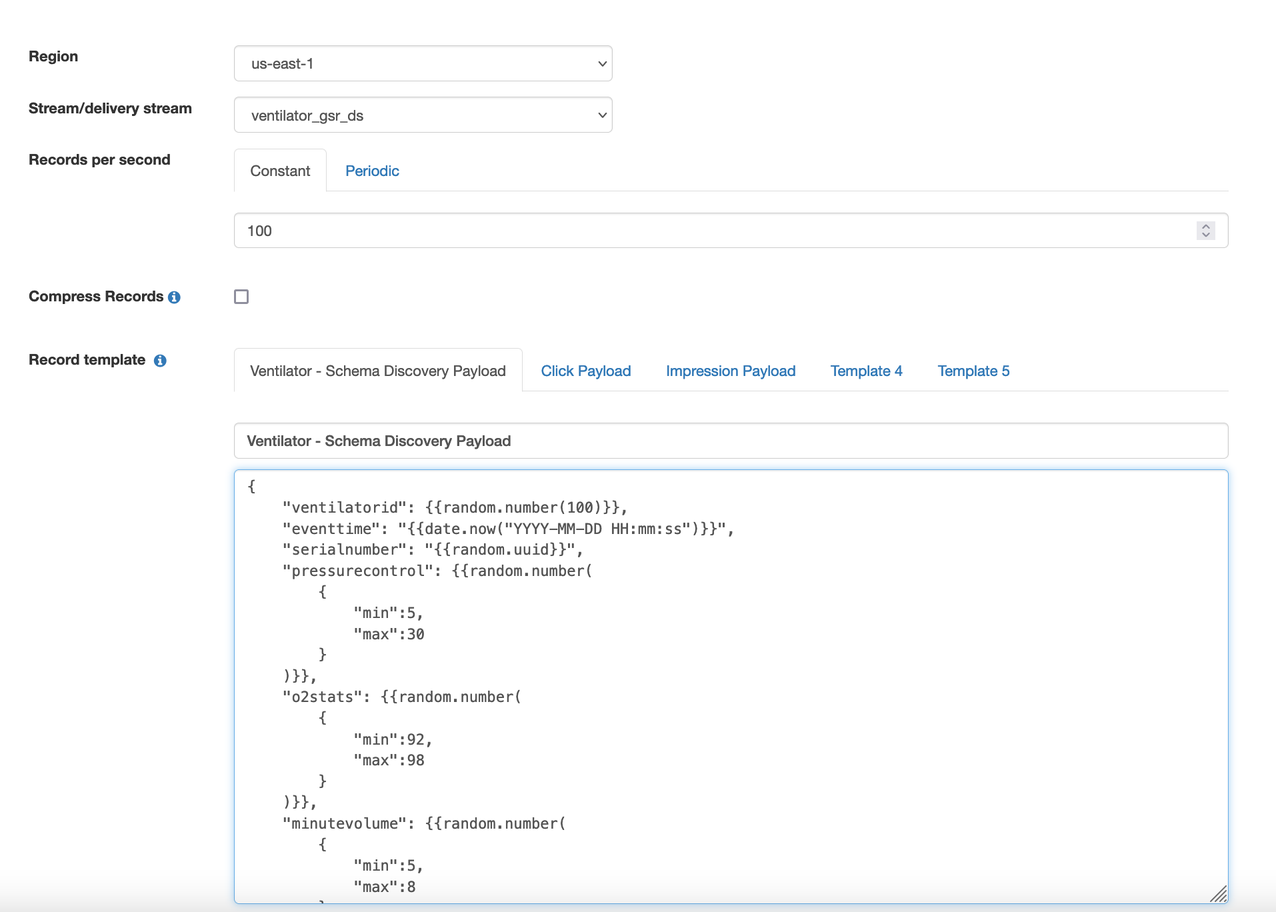
Add a new AWS Glue schema registry
To add a new schema registry, complete the following steps:
- On the AWS Glue console, under Data catalog in the navigation pane, choose Schema registries.
- Choose Add registry.
- For Registry name, enter a name (for example,
MyDemoSchemaReg). - For Description, enter an optional description for the registry.
- Choose Add registry.
Add a schema to the schema registry
To add a new schema, complete the following steps:
- On the AWS Glue console, under Schema registries in the navigation pane, choose Schemas.
- Choose Add schema.
- Provide the schema name (
ventilatorstream_schema_gsr) and attach the schema to the schema registry defined in the previous step. - AWS Glue schemas currently support Avro or JSON formats; for this post, select JSON.
- Use the default Compatibility mode and provide the necessary tags as per your tagging strategy.
Compatibility modes allow you to control how schemas can or cannot evolve over time. These modes form the contract between applications producing and consuming data. When a new version of a schema is submitted to the registry, the compatibility rule applied to the schema name is used to determine if the new version can be accepted. For more information on different compatibility modes, refer to Schema Versioning and Compatibility.
- Enter the following sample JSON:
- Choose Create schema and version.
Create a new Data Catalog table
To add a new table in the Data Catalog, complete the following steps:
- On the AWS Glue Console, under Data Catalog in the navigation pane, choose Tables.
- Choose Add table.
- Select Add tables from existing schema.
- Enter the table name and choose the database.
- Select the source type as Kinesis and choose a data stream in your own account.
- Choose the respective Region and choose the stream
ventilator_gsr_stream. - Choose the
MyDemoSchemaRegregistry created earlier and the schema (ventilatorstream_schema_gsr) with its respective version.
You should be able to preview the schema.
- Choose Next and then choose Finish to create your table.


Create the AWS Glue job
To create your AWS Glue job, complete the following steps:
- On the AWS Glue Studio console, choose Jobs in the navigation pane.
- Select Visual with a source and target.
- Under Source, select Amazon Kinesis and under Target, select Amazon S3.
- Choose Create.
- Choose Data source.
- Configure the job properties such as name, AWS Identity and Access Management (IAM) role, type, and AWS version.
For the IAM role, specify a role that is used for authorization to resources used to run the job and access data stores. Because streaming jobs require connecting to sources and sinks, you need to make sure that the IAM role has permissions to read from Kinesis Data Streams and write to Amazon S3.
- For This job runs, select A new script authored by you.
- Under Advanced properties, keep Job bookmark disabled.
- For Log Filtering, select Standard filter and Spark UI.
- Under Monitoring options, enable Job metrics and Continuous logging with Standard filter.
- Enable the Spark UI and provide the S3 bucket path to store the Spark event logs.
- For Job parameters, enter the following key-values:
- –output_path – The S3 path where the final aggregations are persisted
- –aws_region – The Region where you run the job
- Leave Connections empty and choose Save job and edit script.
- Use the following code for the AWS Glue job (update the values for
database,table_name, andcheckpointLocation):
Our AWS Glue job is ready to read the data from the Kinesis data stream and send it to Amazon S3 in Parquet format.
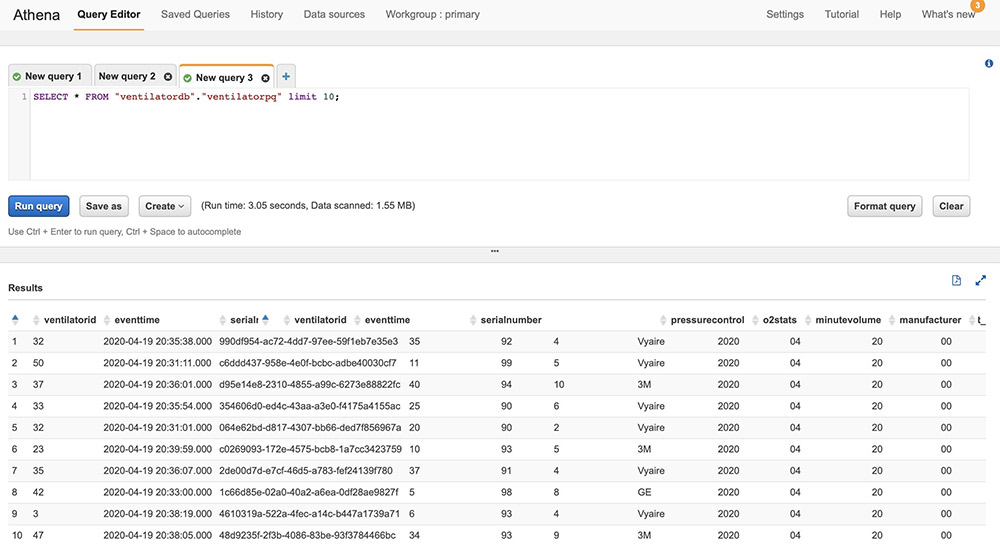
Query the data using Athena
The processed streaming data is written in Parquet format to Amazon S3. Run an AWS Glue crawler on the Amazon S3 location where the streaming data is written; the crawler updates the Data Catalog. You can then run queries using Athena to start driving relevant insights from the data.
Clean up
It’s always a good practice to clean up all the resources created as part of this post to avoid any undue cost. To clean up your resources, delete the AWS Glue database, tables, crawlers, jobs, service role, and S3 buckets.
Additionally, be sure to clean up all other AWS resources that you created using AWS CloudFormation. You can delete these resources on the AWS CloudFormation console by deleting the stack used for the Kinesis Data Generator.
Conclusion
This post demonstrated the importance of centrally managing metadata and schema evolution in stream analytics use cases. It also described how the integration of the Data Catalog and Schema Registry can help you achieve this on AWS. We used a streaming ETL example in AWS Glue to better showcase how this integration can help to enforce end-to-end data quality.
To learn more and get started, you can check out AWS Glue Data Catalog and AWS Glue Schema Registry.
About the Authors
 Dr. Sam Mokhtari is a Senior Solutions Architect at AWS. His main area of depth is data and analytics, and he has published more than 30 influential articles in this field. He is also a respected data and analytics advisor, and has led several large-scale implementation projects across different industries, including energy, health, telecom, and transport.
Dr. Sam Mokhtari is a Senior Solutions Architect at AWS. His main area of depth is data and analytics, and he has published more than 30 influential articles in this field. He is also a respected data and analytics advisor, and has led several large-scale implementation projects across different industries, including energy, health, telecom, and transport.
 Amar Surjit is a Sr. Solutions Architect based in the UK who has been working in IT for over 20 years designing and implementing global solutions for enterprise customers. He is passionate about streaming technologies and enjoys working with customers globally to design and build streaming architectures and drive value by analyzing their streaming data.
Amar Surjit is a Sr. Solutions Architect based in the UK who has been working in IT for over 20 years designing and implementing global solutions for enterprise customers. He is passionate about streaming technologies and enjoys working with customers globally to design and build streaming architectures and drive value by analyzing their streaming data.