Post Syndicated from Michael Tremante original https://blog.cloudflare.com/waf-content-scanning/


Let’s assume you manage a job advert site. On a daily basis job-seekers will be uploading their CVs, cover letters and other supplementary documents to your servers. What if someone tried to upload malware instead?
Today we’re making your security team job easier by providing a file content scanning engine integrated with our Web Application Firewall (WAF), so that malicious files being uploaded by end users get blocked before they reach application servers.
Enter WAF Content Scanning.
If you are an enterprise customer, reach out to your account team to get access.
Making content scanning easy
At Cloudflare, we pride ourselves on making our products very easy to use. WAF Content Scanning was built with that goal in mind. The main requirement to use the Cloudflare WAF is that application traffic is proxying via the Cloudflare network. Once that is done, turning on Content Scanning requires a single API call.
Once on, the WAF will automatically detect any content being uploaded, and when found, scan it and provide the results for you to use when writing WAF Custom Rules or reviewing security analytics dashboards.
The entire process runs inline with your HTTP traffic and requires no change to your application.
As of today, we scan files up to 1 MB. You can easily block files that exceed this size or perform other actions such as log the upload.
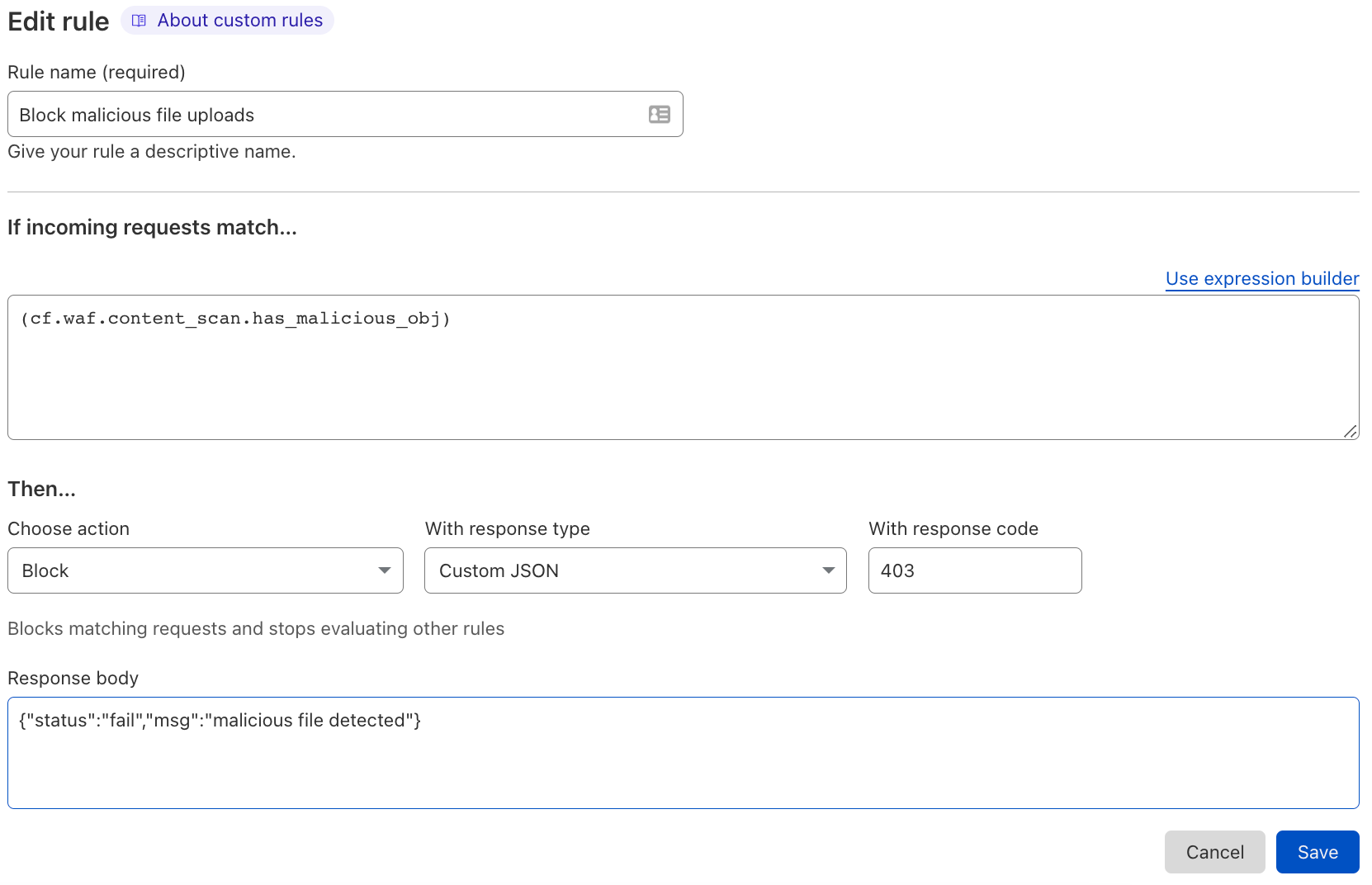
To block a malicious file, you could write a simple WAF Custom Rule like the following:
if: (cf.waf.content_scan.has_malicious_obj)
then: BLOCK
In the dashboard the rule would look like this:

Many other use cases can be achieved by leveraging the metadata exposed by the WAF Content Scanning engine. For example, let’s say you only wanted to allow PDF files to be uploaded on a given endpoint. You would achieve this by deploying the following WAF Custom Rule:
if: any(cf.waf.content_scan.obj_types[*] != "application/pdf") and http.request.uri.path eq "/upload"
then: BLOCK
This rule will, for any content file being uploaded to the /upload endpoint, block the HTTP request if at least one file is not a PDF.
More generally, let’s assume your application does not expect content to be uploaded at all. In this case, you can block any upload attempts with:
if: (cf.waf.content_scan.has_obj)
then: BLOCK
Another very common use case is supporting file upload endpoints that accept JSON content. In this instance files are normally embedded into a JSON payload after being base64-encoded. If your application has such an endpoint, you can provide additional metadata to the scanning engine to recognise the traffic by submitting a custom scan expression. Once submitted, files within JSON payloads will be parsed, decoded, and scanned automatically. In the event you want to issue a block action, you can use a JSON custom response type so that your web application front end can easily parse and display error messages:
The full list of fields exposed by the WAF Content Scanning engine can be found on our developer documentation.
The engine
Scanned content objects
A lot of time designing the system was spent defining what should be scanned. Defining this properly helps us ensure that we are not scanning unnecessary content reducing latency impact and CPU usage, and that there are no bypasses making the system complementary to existing WAF functionality.
The complexity stems from the fact that there is no clear definition of a “file” in HTTP terms. That’s why in this blog post and in the system design, we refer to “content object” instead.
At a high level, although this can loosely be defined as a “file”, not all “content objects” may end up being stored in the file system of an application server! Therefore, we need a definition that applies to HTTP. Additional complexity is given by the fact this is a security product, and attackers will always try to abuse HTTP to obfuscate/hide true intentions. So for example, although a Content-Type header may indicate that the request body is a jpeg image, it may actually be a pdf.
With the above in mind, a “content object” as of today, is any request payload that is detected by heuristics (so no referring to the Content-Type header) to be anything that is not text/html, text/x-shellscript, application/json or text/xml. All other content types are considered a content object.
Detecting via heuristics the content type of an HTTP request body is not enough, as content objects might be found within portions of the HTTP body or encoded following certain rules, such as when using multipart/form-data, which is the most common encoding used when creating standard HTML file input forms.
So when certain payload formats are found, additional parsing applies. As of today the engine will automatically parse and perform content type heuristics on individual components of the payload, when the payload is either encoded using multipart/form-data or multipart/mixed or a JSON string that may have “content objects” embedded in base64 format as defined by the customer
In these cases, we don’t scan the entire payload as a single content object, but we parse it following the relevant standard and apply scanning, if necessary, to the individual portions of the payload. That allows us to support scanning of more than one content object per request, such as an HTML form that has multiple file inputs. We plan to add additional automatic detections in the future on complex payloads moving forward.
In the event we end up finding a malicious match, but we were not able to detect the content type correctly, we will default to reporting a content type of application/octet-stream in the Cloudflare logs/dashboards.
Finally, it is worth noting that we explicitly avoid scanning anything that is plain text (HTML, JSON, XML etc.) as finding attack vectors in these payloads is already covered by the WAF, API Gateway and other web application security solutions already present in Cloudflare’s portfolio.
Local scans
At Cloudflare, we try to leverage our horizontal architecture to build scalable software. This means the underlying scanner is deployed on every server that handles customer HTTP/S traffic. The diagram below describes the setup:
Having each server perform the scanning locally helps ensure latency impact is reduced to a minimum to applicable HTTP requests. The actual scanning engine is the same one used by the Cloudflare Web Gateway, our forward proxy solution that among many other things, helps keep end user devices safe by blocking attempts to download malware.
Consequently, the scanning capabilities provided match those exposed by the Web Gateway AV scanning. The main difference as of today, is the maximum file size currently limited at 1 MB versus 15 MB in Web Gateway. We are working on increasing this to match the Web Gateway in the coming months.
Separating detection from mitigation
A new approach that we are adopting within our application security portfolio is the separation of detection from mitigation. The WAF Content Scanning features follow this approach, as once turned on, it simply enhances all available data and fields with scan results. The benefits here are twofold.
First, this allows us to provide visibility into your application traffic, without you having to deploy any mitigation. This automatically opens up a great use case: discovery. For large enterprise applications security teams may not be aware of which paths or endpoints might be expecting file uploads from the Internet. Using our WAF Content Scanning feature in conjunction with our new Security Analytics they can now filter on request traffic that has a file content object (a file being uploaded) to observe top N paths and hostnames, exposing such endpoints.

Second, as mentioned in the prior section, exposing the intelligence provided by Cloudflare as fields that can be used in our WAF Custom Rules allows us to provide a very flexible platform. As a plus, you don’t need to learn how to use a new feature, as you are likely already familiar with our WAF Custom Rule builder.
This is not a novel idea, and our Bot Management solution was the first to trial it with great success. Any customer who uses Bot Management today gains access to a bot score field that indicates the likelihood of a request coming from automation or a human. Customers use this field to deploy rules that block bots.
To that point, let’s assume you run a job applications site, and you do not wish for bots and crawlers to automatically submit job applications. You can now block file uploads coming from bots!
if: (cf.bot_management.score lt 10 and cf.waf.content_scan.has_obj)
then: BLOCK
And that’s the power we wish to provide at your fingertips.
Next steps
Our WAF Content Scanning is a new feature, and we have several improvements planned, including increasing the max content size scanned, exposing the “rewrite” action, so you can send malicious files to a quarantine server, and exposing better analytics that allow you to explore the data more easily without deploying rules. Stay tuned!