Post Syndicated from Michael Hamilton original https://aws.amazon.com/blogs/big-data/automate-alerting-and-reporting-for-aws-glue-job-resource-usage/
Data transformation plays a pivotal role in providing the necessary data insights for businesses in any organization, small and large. To gain these insights, customers often perform ETL (extract, transform, and load) jobs from their source systems and output an enriched dataset. Many organizations today are using AWS Glue to build ETL pipelines that bring data from disparate sources and store the data in repositories like a data lake, database, or data warehouse for further consumption. These organizations are looking for ways they can reduce cost across their IT environments and still be operationally performant and efficient.
Picture a scenario where you, the VP of Data and Analytics, are in charge of your data and analytics environments and workloads running on AWS where you manage a team of data engineers and analysts. This team is allowed to create AWS Glue for Spark jobs in development, test, and production environments. During testing, one of the jobs wasn’t configured to automatically scale its compute resources, resulting in jobs timing out, costing the organization more than anticipated. The next steps usually include completing an analysis of the jobs, looking at cost reports to see which account generated the spike in usage, going through logs to see when what happened with the job, and so on. After the ETL job has been corrected, you may want to implement monitoring and set standard alert thresholds for your AWS Glue environment.
This post will help organizations proactively monitor and cost optimize their AWS Glue environments by providing an easier path for teams to measure efficiency of their ETL jobs and align configuration details according to organizational requirements. Included is a solution you will be able to deploy that will notify your team via email about any Glue job that has been configured incorrectly. Additionally, a weekly report is generated and sent via email that aggregates resource usage and provides cost estimates per job.
AWS Glue cost considerations
AWS Glue for Apache Spark jobs are provisioned with a number of workers and a worker type. These jobs can be either G.1X, G.2X, G.4X, G.8X or Z.2X (Ray) worker types that map to data processing units (DPUs). DPUs include a certain amount of CPU, memory, and disk space. The following table contains more details.
| Worker Type | DPUs | vCPUs | Memory (GB) | Disk (GB) |
| G.1X | 1 | 4 | 16 | 64 |
| G.2X | 2 | 8 | 32 | 128 |
| G.4X | 4 | 16 | 64 | 256 |
| G.8X | 8 | 32 | 128 | 512 |
| Z.2X | 2 | 8 | 32 | 128 |
For example, if a job is provisioned with 10 workers as G.1X worker type, the job will have access to 40 vCPU and 160 GB of RAM to process data and double using G.2X. Over-provisioning workers can lead to increased cost, due to not all workers being utilized efficiently.
In April 2022, Auto Scaling for AWS Glue was released for AWS Glue version 3.0 and later, which includes AWS Glue for Apache Spark and streaming jobs. Enabling auto scaling on your Glue for Apache Spark jobs will allow you to only allocate workers as needed, up to the worker maximum you specify. We recommend enabling auto scaling for your AWS Glue 3.0 & 4.0 jobs because this feature will help reduce cost and optimize your ETL jobs.
Amazon CloudWatch metrics are also a great way to monitor your AWS Glue environment by creating alarms for certain metrics like average CPU or memory usage. To learn more about how to use CloudWatch metrics with AWS Glue, refer to Monitoring AWS Glue using Amazon CloudWatch metrics.
The following solution provides a simple way to set AWS Glue worker and job duration thresholds, configure monitoring, and receive emails for notifications on how your AWS Glue environment is performing. If a Glue job finishes and detects worker or job duration thresholds were exceeded, it will notify you after the job run has completed, failed, or timed out.
Solution overview
The following diagram illustrates the solution architecture.

When you deploy this application via AWS Serverless Application Model (AWS SAM), it will ask what AWS Glue worker and job duration thresholds you would like to set to monitor the AWS Glue for Apache Spark and AWS Glue for Ray jobs running in that account. The solution will use these values as the decision criteria when invoked. The following is a breakdown of each step in the architecture:
- Any AWS Glue for Apache Spark job that succeeds, fails, stops, or times out is sent to Amazon EventBridge.
- EventBridge picks up the event from AWS Glue and triggers an AWS Lambda function.
- The Lambda function processes the event and determines if the data and analytics team should be notified about the particular job run. The function performs the following tasks:
- The function sends an email using Amazon Simple Notification Service (Amazon SNS) if needed.
- If the AWS Glue job succeeded or was stopped without going over the worker or job duration thresholds, or is tagged to not be monitored, no alerts or notifications are sent.
- If the job succeeded but ran with a worker or job duration thresholds higher than allowed, or the job either failed or timed out, Amazon SNS sends a notification to the designated email with information about the AWS Glue job, run ID, and reason for alerting, along with a link to the specific run ID on the AWS Glue console.
- The function logs the job run information to Amazon DynamoDB for a weekly aggregated report delivered to email. The Dynamo table has Time to Live enabled for 7 days, which keeps the storage to minimum.
- The function sends an email using Amazon Simple Notification Service (Amazon SNS) if needed.
- Once a week, the data within DynamoDB is aggregated by a separate Lambda function with meaningful information like longest-running jobs, number of retries, failures, timeouts, cost analysis, and more.
- Amazon Simple Email Service (Amazon SES) is used to deliver the report because it can be better formatted than using Amazon SNS. The email is formatted via HTML output that provides tables for the aggregated job run data.
- The data and analytics team is notified about the ongoing job runs through Amazon SNS, and they receive the weekly aggregation report through Amazon SES.
Note that AWS Glue Python shell and streaming ETL jobs are not supported because they’re not in scope of this solution.
Prerequisites
You must have the following prerequisites:
- An AWS account to deploy the solution to
- Proper AWS Identity and Access Management (IAM) privileges to create the resources
- The AWS SAM CLI to build and deploy the solution button below, to run template on your AWS environment
Deploy the solution
This AWS SAM application provisions the following resources:
- Two EventBridge rules
- Two Lambda functions
- An SNS topic and subscription
- A DynamoDB table
- An SES subscription
- The required IAM roles and policies
To deploy the AWS SAM application, complete the following steps:
Clone the aws-samples GitHub repository:
git clone https://github.com/aws-samples/aws-glue-job-tracker.gitDeploy the AWS SAM application:
cd aws-glue-job-tracker
sam deploy --guided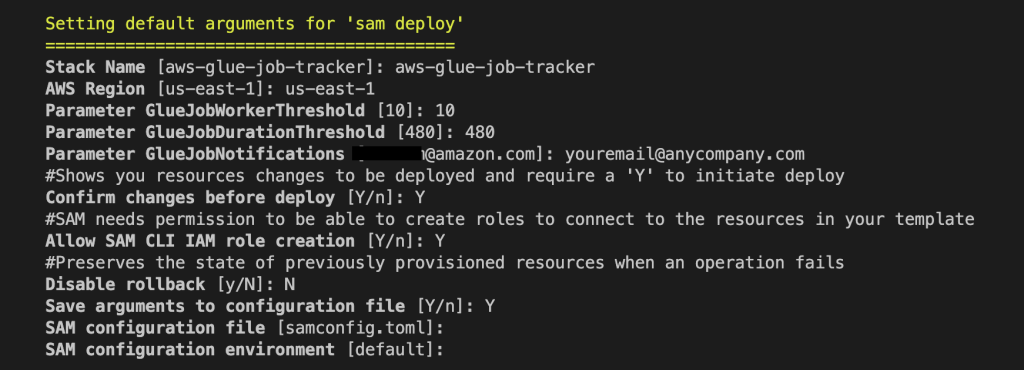
Provide the following parameters:
- GlueJobWorkerThreshold – Enter the maximum number of workers you want an AWS Glue job to be able to run with before sending threshold alert. The default is 10. An alert will be sent if a Glue job runs with higher workers than specified.
- GlueJobDurationThreshold – Enter the maximum duration in minutes you want an AWS Glue job to run before sending threshold alert. The default is 480 minutes (8 hours). An alert will be sent if a Glue job runs with higher job duration than specified.
- GlueJobNotifications – Enter an email or distribution list of those who need to be notified through Amazon SNS and Amazon SES. You can go to the SNS topic after the deployment is complete and add emails as needed.
To receive emails from Amazon SNS and Amazon SES, you must confirm your subscriptions. After the stack is deployed, check your email that was specified in the template and confirm by choosing the link in each message. When the application is successfully provisioned, it will begin monitoring your AWS Glue for Apache Spark job environment. The next time a job fails, times out, or exceeds a specified threshold, you will receive an email via Amazon SNS. For example, the following screenshot shows an SNS message about a job that succeeded but had a job duration threshold violation.

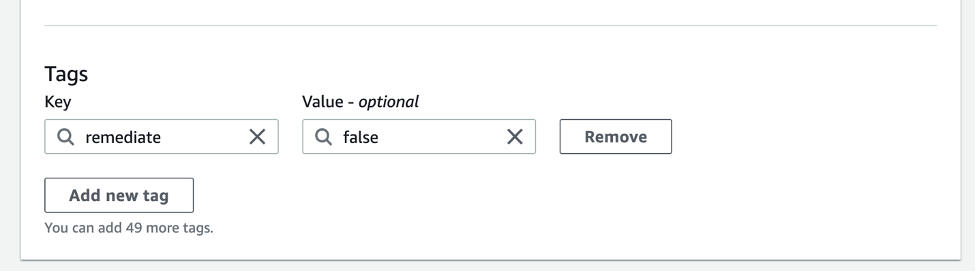
You might have jobs that need to run at a higher worker or job duration threshold, and you don’t want the solution to evaluate them. You can simply tag that job with the key/value of remediate and false. The step function will still be invoked, but will use the PASS state when it recognizes the tag. For more information on job tagging, refer to AWS tags in AWS Glue.
Configure weekly reporting
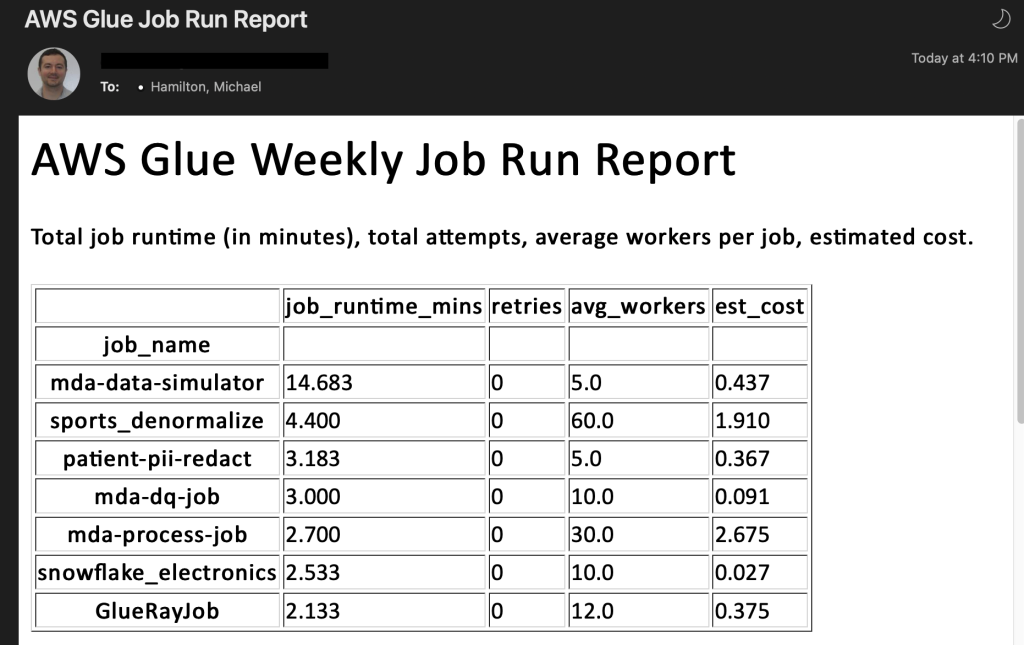
As mentioned previously, when an AWS Glue for Apache Spark job succeeds, fails, times out, or is stopped, EventBridge forwards this event to Lambda, where it logs specific information about each job run. Once a week, a separate Lambda function queries DynamoDB and aggregates your job runs to provide meaningful insights and recommendations about your AWS Glue for Apache Spark environment. This report is sent via email with a tabular structure as shown in the following screenshot. It’s meant for top-level visibility so you’re able to see your longest job runs over time, jobs that have had many retries, failures, and more. It also provides an overall cost calculation as an estimate of what each AWS Glue job will cost for that week. It should not be used as a guaranteed cost. If you would like to see exact cost per job, the AWS Cost and Usage Report is the best resource to use. The following screenshot shows one table (of five total) from the AWS Glue report function.
Clean up
If you don’t want to run the solution anymore, delete the AWS SAM application for each account that it was provisioned in. To delete your AWS SAM stack, run the following command from your project directory:
sam deleteConclusion
In this post, we discussed how you can monitor and cost-optimize your AWS Glue job configurations to comply with organizational standards and policy. This method can provide cost controls over AWS Glue jobs across your organization. Some other ways to help control the costs of your AWS Glue for Apache Spark jobs include the newly released AWS Glue Flex jobs and Auto Scaling. We also provided an AWS SAM application as a solution to deploy into your accounts. We encourage you to review the resources provided in this post to continue learning about AWS Glue. To learn more about monitoring and optimizing for cost using AWS Glue, please visit this recent blog. It goes in depth on all of the cost optimization options and includes a template that builds a CloudWatch dashboard for you with metrics about all of your Glue job runs.
About the authors
 Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working.
Michael Hamilton is a Sr Analytics Solutions Architect focusing on helping enterprise customers in the south east modernize and simplify their analytics workloads on AWS. He enjoys mountain biking and spending time with his wife and three children when not working.
 Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.
Angus Ferguson is a Solutions Architect at AWS who is passionate about meeting customers across the world, helping them solve their technical challenges. Angus specializes in Data & Analytics with a focus on customers in the financial services industry.