Post Syndicated from Amr Ragab original https://aws.amazon.com/blogs/architecture/field-notes-automating-data-ingestion-and-labeling-for-autonomous-vehicle-development/
This post was co-written by Amr Ragab, AWS Sr. Solutions Architect, EC2 Engineering and Anant Nawalgaria, former AWS Professional Services EMEA.
One of the most common needs we have heard from customers in Autonomous Vehicle (AV) development, is to launch a hybrid deployment environment at scale. As vehicle fleets are deployed across the globe, they are capturing real-time telemetry and sensory data. A data lake is created to process the data, and then iterating that dataset improves machine learning models for L3+ development. These datasets can include 4K60Hz camera video captures, LIDAR, RADAR and car telemetry data. The first step is to create the data gravity on which the compute and labeling portions will operate.
Architecture Overview
In this blog, we explain how to build the components in the following architecture, which takes an input dataset of 4K camera data, and performs event-driven video processing. This also includes anonymizing the dataset with face and license plate blurring using AWS Batch.

Figure 1 – Architecture for Automating Data Ingestion and Labeling for Autonomous Vehicle Development
The output is a cleaned dataset which is processed in an Amazon SageMaker Ground Truth workflow. You can visualize the results in a SageMaker Jupyter notebook.
You can transfer data from on-premises to AWS with both online transfer using AWS Storage Gateway, AWS Transfer Family, or AWS DataSync via AWS DirectConnect, as well as offline using AWS Snowball. Whether you use an online or offline approach, a fully automated processing workflow can still be initiated.
Description of the Dataset
The dataset we acquired was a driving sample in the N. Virginia/Washington DC metro area, as shown in the following map.

Figure 2 – Map of the area in which the driving sample was taken.
This path was chosen because of several different driving patterns including city, suburban, highway and unique driving characteristics.
We captured a 4K-60Hz video as well telemetry data from the CAN bus and finally GPS coordinates. The telemetry data from the CAN bus and GPS coordinates were streamed in real time over 4G/5G mobile network through the Amazon Kinesis service. Reach out to your AWS account team if you are interested in exploring connected car applications.
Video Processing Workflow and Manifest Creation
We walk you through the process for the video processing workflow and manifest creation.
- The first step in the workflow is to take the 4K video file and split it into frames. Some additional processing is done to perform color and lens correction but that is specific to the camera used in this blog.
- The next step is to use the ML-based anonymizer application which processes incoming video frames and applies face and license plate blurring on the dataset.
- It uses the excellent work from Understand.ai and is available on Github via the Apache 2.0 License.
- We then take the processed data and create a manifest.json file which is uploaded to a S3 bucket.
- The S3 bucket then becomes the source for the SageMaker Ground Truth workflow.
- Ancillary steps also include applying a lifecycle policy to Amazon S3 to transfer the raw video file to Amazon S3 Glacier. The video is then reconstructed from the processed frames. The docker image contains the following enablement stack:
Ubuntu 18.04 – nvcr.io/nvidia/cuda
AWS command line utility
FFMPEG
Understand.ai anonymizer GitHub
SageMaker Ground Truth Labeling and Analysis
To preparing image metadata, we use Amazon Rekognition. Any extra information, such as other objects were added to the image using Amazon Rekognition, and following is the Lambda code for it.

Figure 3 -Lambda code to add additional objects to the image using Amazon Rekognition.
Before starting the analysis, let’s create some helper functions using the following code:


Compute Summary Statistics
First, let’s compute some summary statistics for a set of labeling jobs. For example, we might want to make a high-level comparison between two labeling jobs performed with different settings. Here, we’ll calculate the number of annotations and the mean confidence score for two jobs. We know that the first job was run with three workers per task, and the second was run with five workers per task.

We can determine that the mean confidence of the whole job was 40%. Now, let us do the querying on the dataN.
Example 1:
Objective: All images with at least 5 cars annotations with confidence score of at least 80%.
Query: select * from s3object s where s.”demo-full-dataset-2″ is not null and ‘Car’ in s.”demo-full-dataset-2-metadata”.”class-map”.* and size(s.”demo-full-dataset-2″.”annotations”) >= 5 and min(s.”demo-full-dataset-2-metadata”.objects[*].”confidence”) >= 0.8 limit 20
Code:

Results:

Example 2:
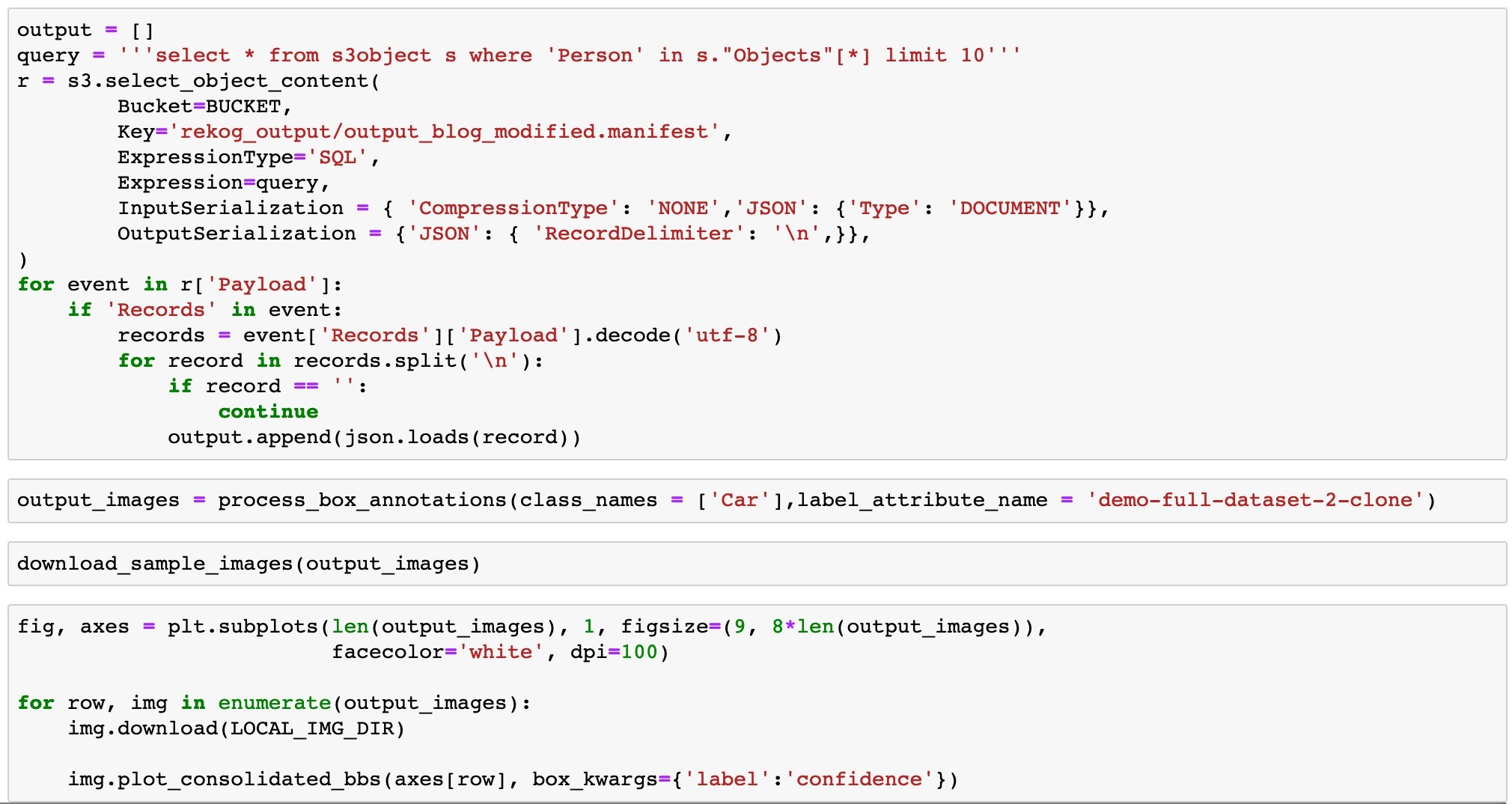
Objective: Identify all images with at least one Person in them.
Query: select * from s3object s where ‘Person’ in s.”Objects”[*] limit 10.
Code:
Results:


Example 3:
Objective: Identify all images with at least some text in them (for example, on signboards)
Query: select * from s3object s where CHAR_LENGTH(s.Text)>0 and s.Text limit 10
Code:

Results:


Conclusion
In this blog, we showed an architecture to automate data ingestion and Ground Truth labeling for autonomous vehicle development. We initiated a workflow to process a data lake to anonymize the individual video frames and then prepare the dataset for Ground Truth labeling. The ground truth labeling UI was offered to a globally distributed workforce which labeled our images at scale. If you are developing an autonomous vehicle/robotics platform, contact your AWS account team for more information.
Recommended Reading:
Field Notes: Building an Autonomous Driving and ADAS Data Lake on AWS