Post Syndicated from Bukhtawar Khan original https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/
Amazon OpenSearch Service recently introduced the OpenSearch Optimized Instance family (OR1), which delivers up to 30% price-performance improvement over existing memory optimized instances in internal benchmarks, and uses Amazon Simple Storage Service (Amazon S3) to provide 11 9s of durability. With this new instance family, OpenSearch Service uses OpenSearch innovation and AWS technologies to reimagine how data is indexed and stored in the cloud.
Today, customers widely use OpenSearch Service for operational analytics because of its ability to ingest high volumes of data while also providing rich and interactive analytics. In order to provide these benefits, OpenSearch is designed as a high-scale distributed system with multiple independent instances indexing data and processing requests. As your operational analytics data velocity and volume of data grows, bottlenecks may emerge. To sustainably support high indexing volume and provide durability, we built the OR1 instance family.
In this post, we discuss how the reimagined data flow works with OR1 instances and how it can provide high indexing throughput and durability using a new physical replication protocol. We also dive deep into some of the challenges we solved to maintain correctness and data integrity.
Designing for high throughput with 11 9s of durability
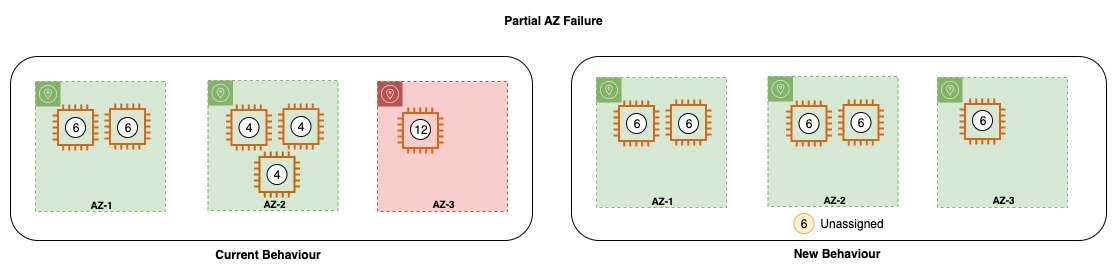
OpenSearch Service manages tens of thousands of OpenSearch clusters. We’ve gained insights into typical cluster configurations that customers use to meet high throughput and durability goals. To achieve higher throughput, customers often choose to drop replica copies to save on the replication latency; however, this configuration results in sacrificing availability and durability. Other customers require high durability and as a result need to maintain multiple replica copies, resulting in higher operating costs for them.
The OpenSearch Optimized Instance family provides additional durability while also keeping costs lower by storing a copy of the data on Amazon S3. With OR1 instances, you can configure multiple replica copies for high read availability while maintaining indexing throughput.
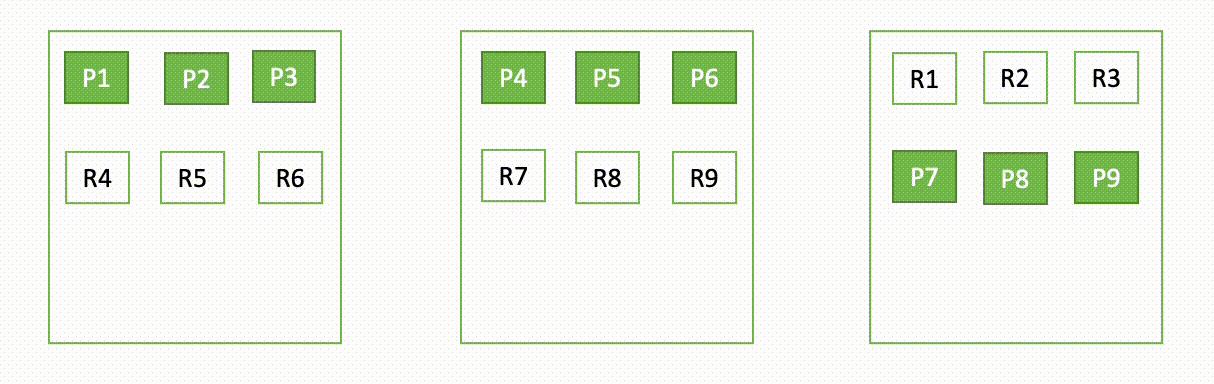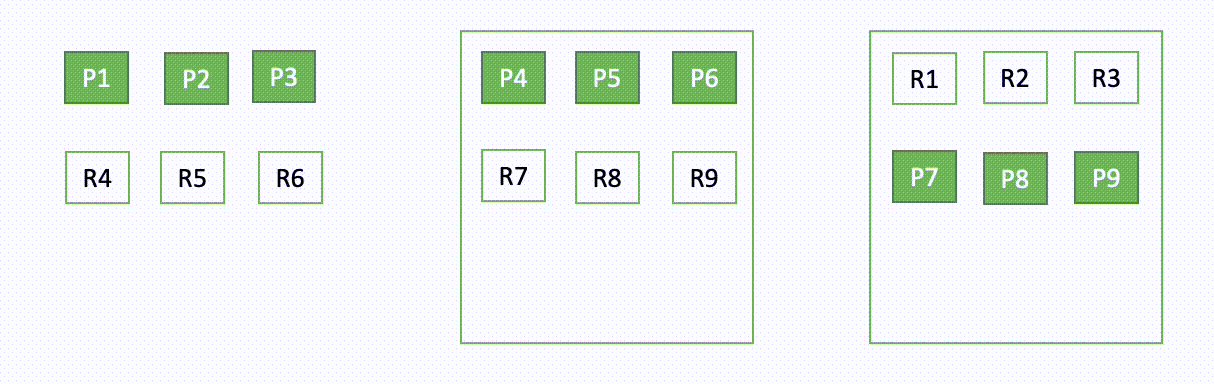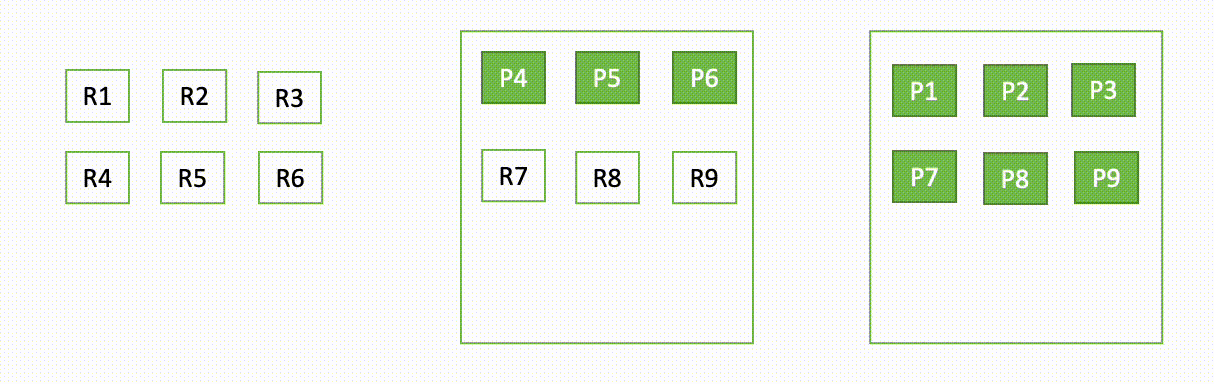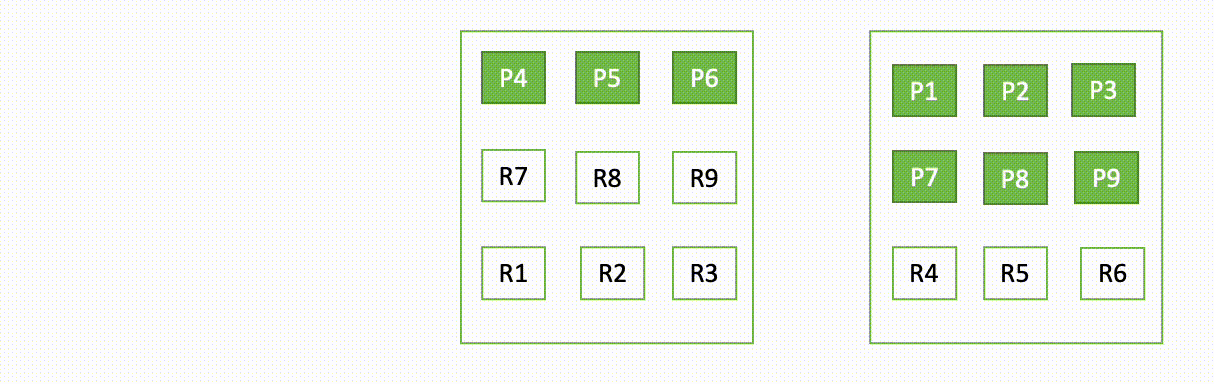
The following diagram illustrates an indexing flow involving a metadata update in OR1

During indexing operations, individual documents are indexed into Lucene and also appended to a write-ahead log also known as a translog. Before sending back an acknowledgement to the client, all translog operations are persisted to the remote data store backed by Amazon S3. If any replica copies are configured, the primary copy performs checks to detect the possibility of multiple writers (control flow) on all replica copies for correctness reasons.
The following diagram illustrates the segment generation and replication flow in OR1 instances

Periodically, as new segment files are created, the OR1 copy those segments to Amazon S3. When the transfer is complete, the primary publishes new checkpoints to all replica copies, notifying them of a new segment being available for download. The replica copies subsequently download newer segments and make them searchable. This model decouples the data flow that happens using Amazon S3 and the control flow (checkpoint publication and term validation) that happens over inter-node transport communication.
The following diagram illustrates the recovery flow in OR1 instances

OR1 instances persist not only the data, but the cluster metadata like index mappings, templates, and settings in Amazon S3. This makes sure that in the event of a cluster-manager quorum loss, which is a common failure mode in non-dedicated cluster-manager setups, OpenSearch can reliably recover the last acknowledged metadata.
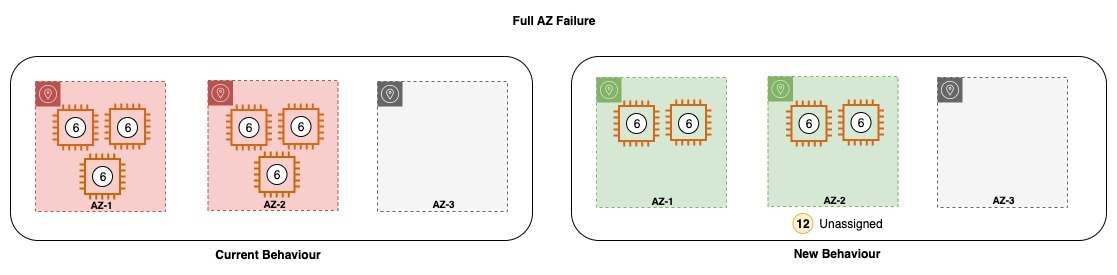
In the event of an infrastructure failure, an OpenSearch domain can end up losing one or more nodes. In such an event, the new instance family guarantees recovery of both the cluster metadata and the index data up to the latest acknowledged operation. As new replacement nodes join the cluster, the internal cluster recovery mechanism bootstraps the new set of nodes and then recovers the latest cluster metadata from the remote cluster metadata store. After the cluster metadata is recovered, the recovery mechanism starts to hydrate the missing segment data and translog from Amazon S3. Then all uncommitted translog operations, up to the last acknowledged operation, are replayed to reinstate the lost copy.
The new design doesn’t modify the way searches work. Queries are processed normally by either the primary or replica shard for each shard in the index. You may see longer delays (in the 10-second range) before all copies are consistent to a particular point in time because the data replication is using Amazon S3.
A key advantage of this architecture is that it serves as a foundational building block for future innovations, like separation of readers and writers, and helps segregate compute and storage layers.
How redefining the replication strategy boosts the indexing throughput
OpenSearch supports two replication strategies: logical (document) and physical (segment) replication. In the case of logical replication, the data is indexed on all the copies independently, leading to redundant computation on the cluster. The OR1 instances use the new physical replication model, where data is indexed only on the primary copy and additional copies are created by copying data from the primary. With a high number of replica copies, the node hosting the primary copy requires significant network bandwidth, replicating the segment to all the copies. The new OR1 instances solve this problem by durably persisting the segment to Amazon S3, which is configured as a remote storage option. They also help with scaling replicas without bottlenecking on primary.
After the segments are uploaded to Amazon S3, the primary sends out a checkpoint request, notifying all replicas to download the new segments. The replica copies then need to download the incremental segments. Because this process frees up compute resources on replicas, which is otherwise required to redundantly index data and network overhead incurred on primaries to replicate data, the cluster is able to churn more throughput. In the event the replicas aren’t able to process the newly created segments, due to overload or slow network paths, the replicas beyond a point are marked as failed to prevent them from returning stale results.
Why high durability is a good idea, but hard to do well
Although all committed segments are durably persisted to Amazon S3 whenever they get created, one of key challenges in achieving high durability is synchronously writing all uncommitted operations to a write-ahead log on Amazon S3, before acknowledging back the request to the client, without sacrificing throughput. The new semantics introduce additional network latency for individual requests, but the way we’ve made sure there is no impact to throughput is by batching and draining requests on a single thread for up to a specified interval, while making sure other threads continue to index requests. As a result, you can drive higher throughput with more concurrent client connections by optimally batching your bulk payloads.
Other challenges in designing a highly durable system include enforcing data integrity and correctness at all times. Although some events like network partitions are rare, they can break the correctness of the system and therefore the system needs to be prepared to deal with these failure modes. Therefore, while switching to the new segment replication protocol, we also introduced a few other protocol changes, like detecting multiple writers on each replica. The protocol makes sure that an isolated writer can’t acknowledge a write request, while another newly promoted primary, based on the cluster-manager quorum, is concurrently accepting newer writes.
The new instance family automatically detects the loss of a primary shard while recovering data, and performs extensive checks on network reachability before the data can be re-hydrated from Amazon S3 and the cluster is brought back to a healthy state.
For data integrity, all files are extensively checksummed to make sure we are able to detect and prevent network or file system corruption that may result in data being unreadable. Furthermore, all files including metadata are designed to be immutable, providing additional safety against corruptions and versioned to prevent accidental mutating changes.
Reimagining how data flows
The OR1 instances hydrate copies directly from Amazon S3 in order to perform recovery of lost shards during an infrastructure failure. By using Amazon S3, we are able to free up the primary node’s network bandwidth, disk throughput, and compute, and therefore provide a more seamless in-place scaling and blue/green deployment experience by orchestrating the entire process with minimal primary node coordination.
OpenSearch Service provides automatic data backups called snapshots at hourly intervals, which means in case of accidental modifications to data, you have the option to go back to a previous point in time state. However, with the new OpenSearch instance family, we’ve discussed that the data is already durably persisted on Amazon S3. So how do snapshots work when we already have the data present on Amazon S3?
With the new instance family, snapshots serve as checkpoints, referencing the already present segment data as it exists at a point in time. This makes snapshots more lightweight and faster because they don’t need to re-upload any additional data. Instead, they upload metadata files that capture the view of the segments at that point in time, which we call shallow snapshots. The benefit of shallow snapshots extends to all operations, namely creation, deletion, and cloning of snapshots. You still have the option to snapshot an independent copy with manual snapshots for other administrative operations.
Summary
OpenSearch is an open source, community-driven software. Most of the foundational changes including the replication model, remote-backed storage, and remote cluster metadata have been contributed to open source; in fact, we follow an open source first development model.
Efforts to improve throughput and reliability is a never-ending cycle as we continue to learn and improve. The new OpenSearch optimized instances serve as a foundational building block, paving the way for future innovations. We are excited to continue our efforts in improving reliability and performance and to see what new and existing solutions builders can create using OpenSearch Service. We hope this leads to a deeper understanding of the new OpenSearch instance family, how this offering achieves high durability and better throughput, and how it can help you configure clusters based on the needs of your business.
If you’re excited to contribute to OpenSearch, open up a GitHub issue and let us know your thoughts. We would also love to hear about your success stories achieving high throughput and durability on OpenSearch Service. If you have other questions, please leave a comment.
About the Authors
 Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
Bukhtawar Khan is a Principal Engineer working on Amazon OpenSearch Service. He is interested in building distributed and autonomous systems. He is a maintainer and an active contributor to OpenSearch.
 Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
Gaurav Bafna is a Senior Software Engineer working on OpenSearch at Amazon Web Services. He is fascinated about solving problems in distributed systems. He is a maintainer and an active contributor to OpenSearch.
 Sachin Kale is a senior software development engineer at AWS working on OpenSearch.
Sachin Kale is a senior software development engineer at AWS working on OpenSearch.
 Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.
Rohin Bhargava is a Sr. Product Manager with the Amazon OpenSearch Service team. His passion at AWS is to help customers find the correct mix of AWS services to achieve success for their business goals.
 Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.
Ranjith Ramachandra is a Senior Engineering Manager working on Amazon OpenSearch Service. He is passionate about highly scalable distributed systems, high performance and resilient systems.