Post Syndicated from Ezat Karimi original https://aws.amazon.com/blogs/big-data/build-a-multi-tenant-healthcare-system-with-amazon-opensearch-service/
Healthcare systems face significant challenges managing vast amounts of data while maintaining regulatory compliance, security, and performance. This post explores strategies for implementing a multi-tenant healthcare system using Amazon OpenSearch Service.
In this context, tenants are distinct healthcare entities, sharing a common platform while maintaining isolated data environments. Hospital departments (like emergency, radiology, or patient care), clinics, insurance providers, laboratories, and research institutions are examples of these tenants.
In this post, we address common multi-tenancy challenges and provide actionable solutions for security, tenant isolation, workload management, and cost optimization across diverse healthcare tenants.
Understanding multi-tenant healthcare systems
Tenants in healthcare systems are diverse and have distinct requirements. For example, emergency departments need round-the-clock high availability with subsecond response times for patient care, along with strict access controls for sensitive trauma data. Research departments run complex, resource-intensive queries that are less time-sensitive but require robust anonymization protocols to maintain HIPAA compliance when working with patient data. Outpatient clinics operate during business hours with predictable usage patterns and moderate performance requirements. Administrative systems focus on financial data with scheduled batch processing and require access to billing information and insurance details only. Specialty departments like radiology and cardiology have unique requirements specific to the tasks they perform. For example, radiology requires high storage capacity and bandwidth for large medical imaging files, along with specialized indexing for metadata searches.
Understanding tenant requirements is essential for designing an effective multi-tenant architecture that balances resource sharing with appropriate isolation while maintaining regulatory compliance.
Isolation models
OpenSearch’s hierarchical structure consists of four main levels. At the top level is the domain, which contains one or more nodes that store and search data. Within the domain, indexes contain documents and define how they are stored and searched. Documents are individual records or data entries stored within an index, and each document consists of fields, which are individual data elements with specific data types and values.
Indexes include mappings and settings. Mappings define the schema of documents within an index, specifying field names and their data types. Settings configure various operational aspects of an index, such as the number of primary shards and replica shards.
The isolation model in a multi-tenant OpenSearch system can be at domain, index, or document level. The model you select for your multi-tenant healthcare system impacts security, performance, and cost. For healthcare organizations, as depicted in the following diagram, a hybrid approach typically works best, matching isolation levels to tenant requirements.
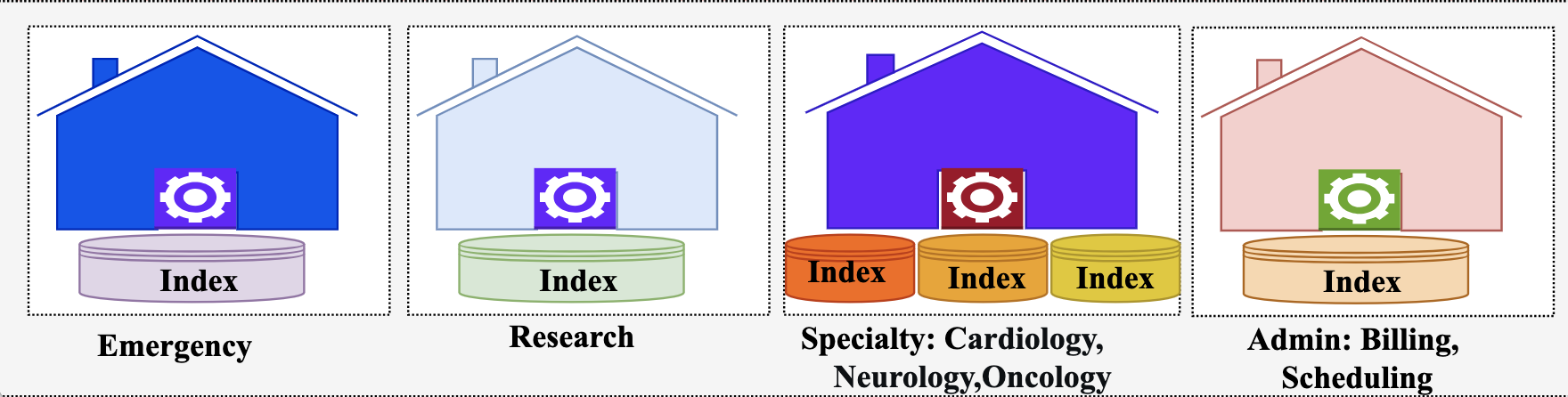
Multi-Tenancy Isolation Models
For emergency units, consider domain-based isolation, providing maximum separation by deploying separate OpenSearch domains for each tenant. Although it’s more expensive, it reduces resource contention and provides consistent performance for critical systems. This isolation simplifies compliance by physically separating sensitive patient data.
Similarly, for clinical research tenants, consider domain-based isolation despite its higher cost. Given the resource-intensive nature of research workloads—particularly genomics and population health analytics that process terabytes of data with complex algorithms—separate domains prevent these demanding operations from impacting other tenants.
For specialty departments like cardiology or radiology, where workload patterns are similar but data access patterns are distinct, index-based isolation is a good fit. These departments share a domain but maintain separate indexes. This approach provides strong logical separation while allowing more efficient resource utilization.
For administrative departments where data is less sensitive, a document-based isolation is sufficient, and multiple tenants can share the same indexes.
Data modeling
Effective data modeling is crucial for maintaining performance and manageability in a multi-tenant healthcare system. Implement a consistent index naming convention that incorporates tenant identifiers, data categories, and time periods like {tenant-id}-{data-type}-{time-period}. Tenant-id identifies the entity, for example, cardiology. Examples of the indexes are cardiology-ecg-202505 or radiology-mri-202505. This structured approach simplifies data management, access control, and lifecycle policies.
Consider data access patterns when designing your index strategy. For example, for time-series data like vital signs or telemetry readings, time-based indexes with appropriate rotation policies will improve performance and simplify data lifecycle management.
For shared indexes using document-based isolation, make sure tenant identifiers are consistently applied and indexed for efficient tenant-based filtering.
Tenant management
Effective tenant management prevents resource contention and provides consistent performance across your healthcare system. Implement a hybrid isolation model using a tenant tiering framework based on criticality. The following table outlines the tiering framework.
| Tier | Tenant Type | SLA | Resources | Operational Limits | Behavior |
| Tier-1 Critical |
Emergency departments ICU/Critical care Operating rooms |
24/7 SLA 99.99% Sub-second response RPO: Near zero RTO: Less than 15 minutes |
Guaranteed 50% CPU, 50% memory Dedicated hot nodes 2 replicas minimum |
100 concurrent requests 20 MB request size 30-second timeout No throttling |
Priority query routing Preemptive scaling Automatic failover |
| Tier-2 Urgent |
Inpatient units Specialty departments Radiology/imaging |
24/7 SLA with 99.9% availability Less than 2-second response time RPO: Less than 15 minutes RTO: Less than 1 hour |
Guaranteed 30% CPU, 30% memory Shared hot nodes 1–2 replicas |
50 concurrent requests 15 MB request size 60-second timeout Limited throttling during peak |
High-priority query routing Automatic scaling Automated recovery |
| Tier-3 Standard |
Outpatient clinics Primary care Pharmacy Laboratory |
Business hours SLA (8 AM – 8 PM) 99.5% availability Less than 5-second response time RPO: Less than 1 hour RTO: Less than 4 hours |
Guaranteed 15% CPU, 15% memory Shared nodes 1 replica |
25 concurrent requests 10 MB request size 120-second timeout Moderate throttling |
Standard query routing Fair thread allocation Manual scaling Business hours optimization |
| Tier-4 Research |
Clinical research Genomics Population health |
Best-effort SLA, up to 99% availability Less than 30-second response time RPO: Less than 24 hours RTO: Less than 24 hours |
Guaranteed 5% CPU, 10% memory Burst capacity during off-hours 0–1 replicas |
10 concurrent requests 50 MB request size 300-second timeout Aggressive throttling during pea |
Compute optimized instances Large heap size Research-specific plugins |
| Tier-5 Admin |
Billing/finance HR systems Inventory management |
Business hours SLA (9 AM – 5 PM) 99% availability Less than 10-second response time RPO: Less than 24 hours RTO: Less than 48 hours |
No guaranteed resources Burstable capacity UltraWarm for historical 1 replica |
5 concurrent requests 5 MB request size 180-second timeout Aggressive throttling |
Lowest priority query routing Batch processing preferred Off-hours scheduling Cost-optimized storage |
Workload management
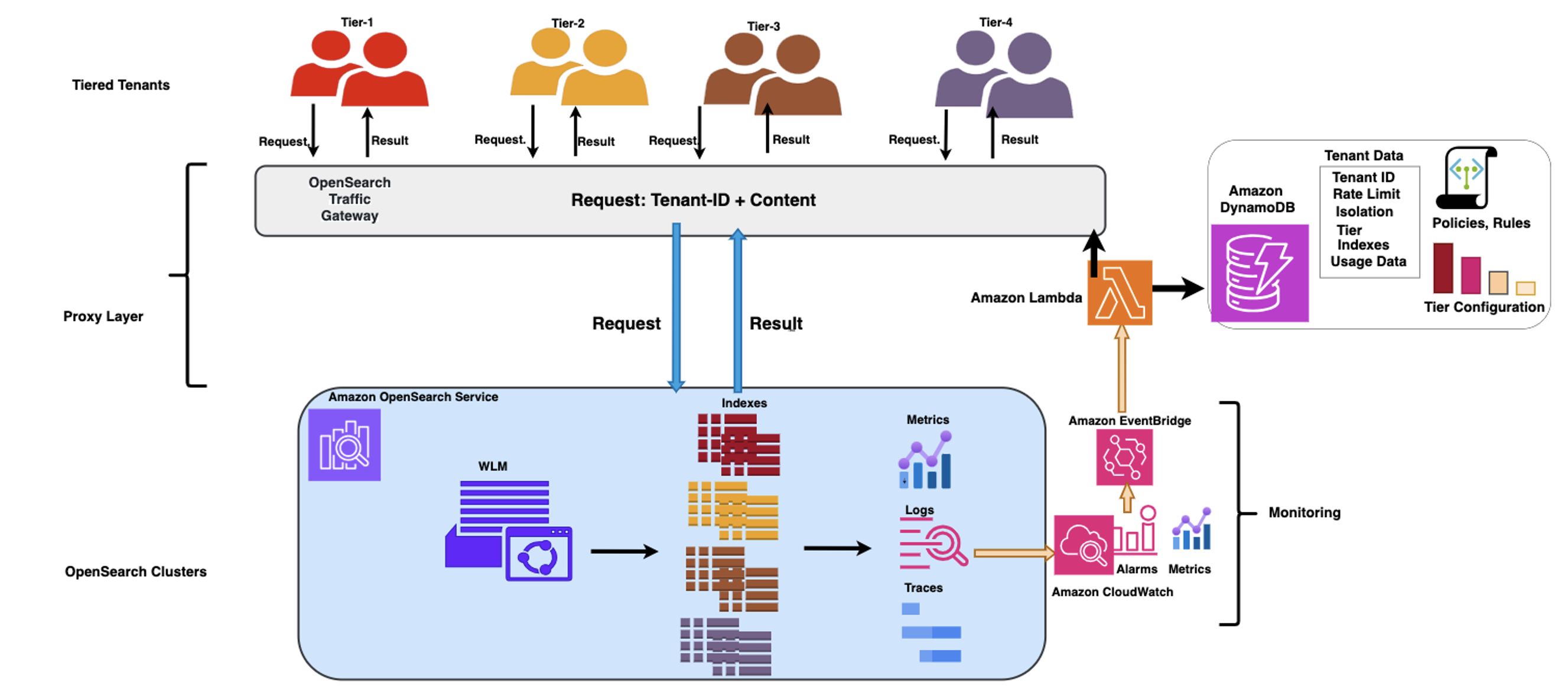
When you use OpenSearch Service for multi-tenancy, you must balance your tenants’ workloads to make sure you deliver the resources needed for each to ingest, store, and query their data effectively. A multi-layered workload management framework with a rule-based proxy and OpenSearch Service workload management can effectively address these challenges. For details, see this blog post: Workload management in OpenSearch-based multi-tenant centralized logging platforms.
Security framework
Healthcare data requires protection due to its sensitive nature and regulatory requirements. The OpenSearch Service security framework is specifically adaptable to healthcare’s strict security requirements. This framework combines multiple layers of access control, captured in the following diagram.
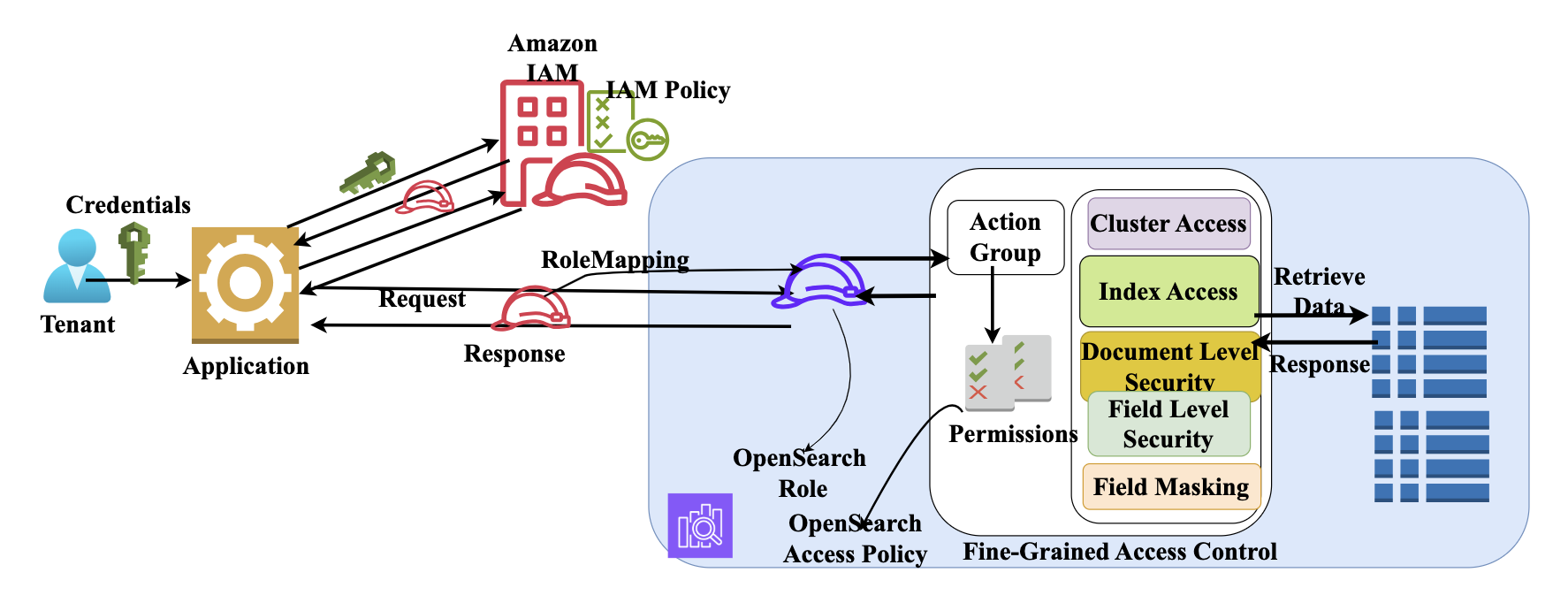
Multi-tenancy fine-grained access control in Amazon OpenSearch Service
An important step in this framework is role mapping, where AWS Identity and Access Management (IAM) roles are mapped to OpenSearch roles for role-based access control (RBAC). For example, emergency departments can implement the ED-Physician role with access to patient history across departments, and the ED-Staff role with access to vital sign and medication data. You can map emergency department roles to OpenSearch roles.
With document-level security (DLS), you can limit emergency department staff to active emergency patients only while restricting access to discharged patient data only to the providers who treat them. With field-level security (FLS), you can allow access to medical fields while masking billing and insurance data. You can also provide attribute-based access control (ABAC) policies to allow access based on patient status.
For research departments, you can create Clinical-Researcher roles with read-only access to datasets. Integrate academic roles to research roles to make sure researchers only access data for studies they’re authorized to conduct. For DLS, implement filters to make sure researchers only access approved documents. Use FLS to anonymize HIPAA identifiers. For research departments, ABAC should evaluate the study phase and researcher’s location.
For outpatient care, you can define Medical-Provider roles with full access to assigned patients’ records and Medical-Assistant roles limited to documenting vitals and preliminary information. For DLS, limit access to patient’s physicians only. For FLS, restrict access to medical data only, while limiting nurses to demographic, vital signs, and medication fields. Implement time-aware ABAC policies that restrict access to patient records outside of business hours unless the provider is on-call.
For administrative departments, you can implement Financial roles with access to charge codes and insurance information but no clinical data. For DLS, make sure financial staff only access billing documents. FLS provides access to billing codes, dates of service, and insurance fields while masking clinical content.
For specialty departments, you can create technician roles like Radiologist and apply DLS filters restricting access to the data to these roles and referring physician. FLS allows technicians to see clinical history and previous findings specific to their specialty.
Enable comprehensive audit logging to track access to protected health information. Configure these logs to capture user identity, accessed data, timestamp, and access context. These audit trails are essential for regulatory compliance and security investigations.
Managing data lifecycle for compliance
Index State Management (ISM) capabilities combined with OpenSearch Service storage tiering enable an elaborate approach to data lifecycle management that can be tailored to diverse tenant needs. ISM provides a robust way to automate the lifecycle of indexes by defining policies that dictate transitions between Hot, UltraWarm, and Cold storage tiers based on criteria like index age or size. This automation can extend to the archive tier by creating snapshots, which are stored in Amazon Simple Storage Service (Amazon S3) and can be further transitioned to Amazon S3 Glacier or Glacier Deep Archive for long-term, cost-effective archiving of data that is rarely accessed.
Frame your ISM policy along the following guidelines:
Keep critical patient data in hot storage for 180 days to support immediate access. Transition to warm storage for the next 12 months, then move to cold storage for years 2–7. After 7 years, archive records.
For research data benefits, use project-based lifecycle policies rather than strictly time-based transitions. Maintain research datasets in hot storage during active project phases, regardless of data age. When projects conclude, transition data to warm storage for 12 months. Move to cold storage for the following 5–10 years based on research significance. Afterward, archive records.
For outpatient clinic data, keep recent patient records in hot storage for 90 days, aligning index rollover with typical follow-up windows. Transition to warm storage for months 4–18, coinciding with common annual visit patterns. Move to cold storage for years 2–7. Archive after 7 years.
For administrative data, maintain current fiscal year data in hot storage with automated transitions at year-end boundaries. Move previous fiscal year data to warm storage for 18 months to support auditing and reporting. Transition to cold storage for years 3–7. Archive financial records after 7 years.
For the specialty department data, keep recent metadata in hot storage for 90 days while moving large files, like images, to warm storage after 30 days. Transition complete records to cold storage after 18 months. Archive after 7 years.
Cost management and optimization
Healthcare organizations must balance performance requirements with budget constraints. Effective cost management strategies are essential for sustainable operations.
Implement comprehensive tagging strategies that mirror your index naming conventions to create a unified approach to resource management and cost tracking. Like the index naming convention, design your tags to identify the tenant, application, and data type (for example, “tenant=cardiology” or “application=ecg“). These tags, combined with AWS Cost Explorer, provide visibility into expenses across organizational boundaries.
Develop cost allocation mechanisms that fairly distribute expenses across different tenants. Consider implementing tiered pricing structures based on data volume, query complexity, and service-level guarantees. This approach aligns costs with value and encourages efficient resource utilization.
Optimize your infrastructure based on tenant-specific metrics and usage patterns. Monitor document counts, indexing rates, and query patterns to right-size your clusters and node types. Use different instance types for different workloads—for example, use compute-optimized instances for query-intensive applications.
Use OpenSearch Service storage tiering to optimize costs. UltraWarm provides significant cost savings for infrequently accessed data while maintaining reasonable query performance. Cold storage offers even greater savings for data that’s rarely accessed but must be retained for compliance purposes.
Conclusion
Building a multi-tenant healthcare system on OpenSearch Service requires careful planning and implementation. By addressing tenant isolation, security, data lifecycle management, workload control, and cost optimization, you can create a platform that delivers improved operational efficiency while maintaining strict compliance with healthcare regulations.
About the Authors
 Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
Ezat Karimi is a Senior Solutions Architect at AWS, based in Austin, TX. Ezat specializes in designing and delivering modernization solutions and strategies for database applications. Working closely with multiple AWS teams, Ezat helps customers migrate their database workloads to the AWS Cloud.
 Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have vector, search, and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor’s of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.