Post Syndicated from Felix Hanau original https://blog.cloudflare.com/brotli-compression-using-a-reduced-dictionary/
Brotli is a state of the art lossless compression format, supported by all major browsers. It is capable of achieving considerably better compression ratios than the ubiquitous gzip, and is rapidly gaining in popularity. Cloudflare uses the Google brotli library to dynamically compress web content whenever possible. In 2015, we took an in-depth look at how brotli works and its compression advantages.
One of the more interesting features of the brotli file format, in the context of textual web content compression, is the inclusion of a built-in static dictionary. The dictionary is quite large, and in addition to containing various strings in multiple languages, it also supports the option to apply multiple transformations to those words, increasing its versatility.
The open sourced brotli library, that implements an encoder and decoder for brotli, has 11 predefined quality levels for the encoder, with higher quality level demanding more CPU in exchange for a better compression ratio. The static dictionary feature is used to a limited extent starting with level 5, and to the full extent only at levels 10 and 11, due to the high CPU cost of this feature.
We improve on the limited dictionary use approach and add optimizations to improve the compression at levels 5 through 9 at a negligible performance impact when compressing web content.
Brotli Static Dictionary
Brotli primarily uses the LZ77 algorithm to compress its data. Our previous blog post about brotli provides an introduction.
To improve compression on text files and web content, brotli also includes a static, predefined dictionary. If a byte sequence cannot be matched with an earlier sequence using LZ77 the encoder will try to match the sequence with a reference to the static dictionary, possibly using one of the multiple transforms. For example, every HTML file contains the opening <html> tag that cannot be compressed with LZ77, as it is unique, but it is contained in the brotli static dictionary and will be replaced by a reference to it. The reference generally takes less space than the sequence itself, which decreases the compressed file size.
The dictionary contains 13,504 words in six languages, with lengths from 4 to 24 characters. To improve the compression of real-world text and web data, some dictionary words are common phrases (“The current”) or strings common in web content (‘type=”text/javascript”’). Unlike usual LZ77 compression, a word from the dictionary can only be matched as a whole. Starting a match in the middle of a dictionary word, ending it before the end of a word or even extending into the next word is not supported by the brotli format.
Instead, the dictionary supports 120 transforms of dictionary words to support a larger number of matches and find longer matches. The transforms include adding suffixes (“work” becomes “working”) adding prefixes (“book” => “ the book”) making the first character uppercase (“process” => “Process”) or converting the whole word to uppercase (“html” => “HTML”). In addition to transforms that make words longer or capitalize them, the cut transform allows a shortened match (“consistently” => “consistent”), which makes it possible to find even more matches.
Methods
With the transforms included, the static dictionary contains 1,633,984 different words – too many for exhaustive search, except when used with the slow brotli compression levels 10 and 11. When used at a lower compression level, brotli either disables the dictionary or only searches through a subset of roughly 5,500 words to find matches in an acceptable time frame. It also only considers matches at positions where no LZ77 match can be found and only uses the cut transform.
Our approach to the brotli dictionary uses a larger, but more specialized subset of the dictionary than the default, using more aggressive heuristics to improve the compression ratio with negligible cost to performance. In order to provide a more specialized dictionary, we provide the compressor with a content type hint from our servers, relying on the Content-Type header to tell the compressor if it should use a dictionary for HTML, JavaScript or CSS. The dictionaries can be furthermore refined by colocation language in the future.
Fast dictionary lookup
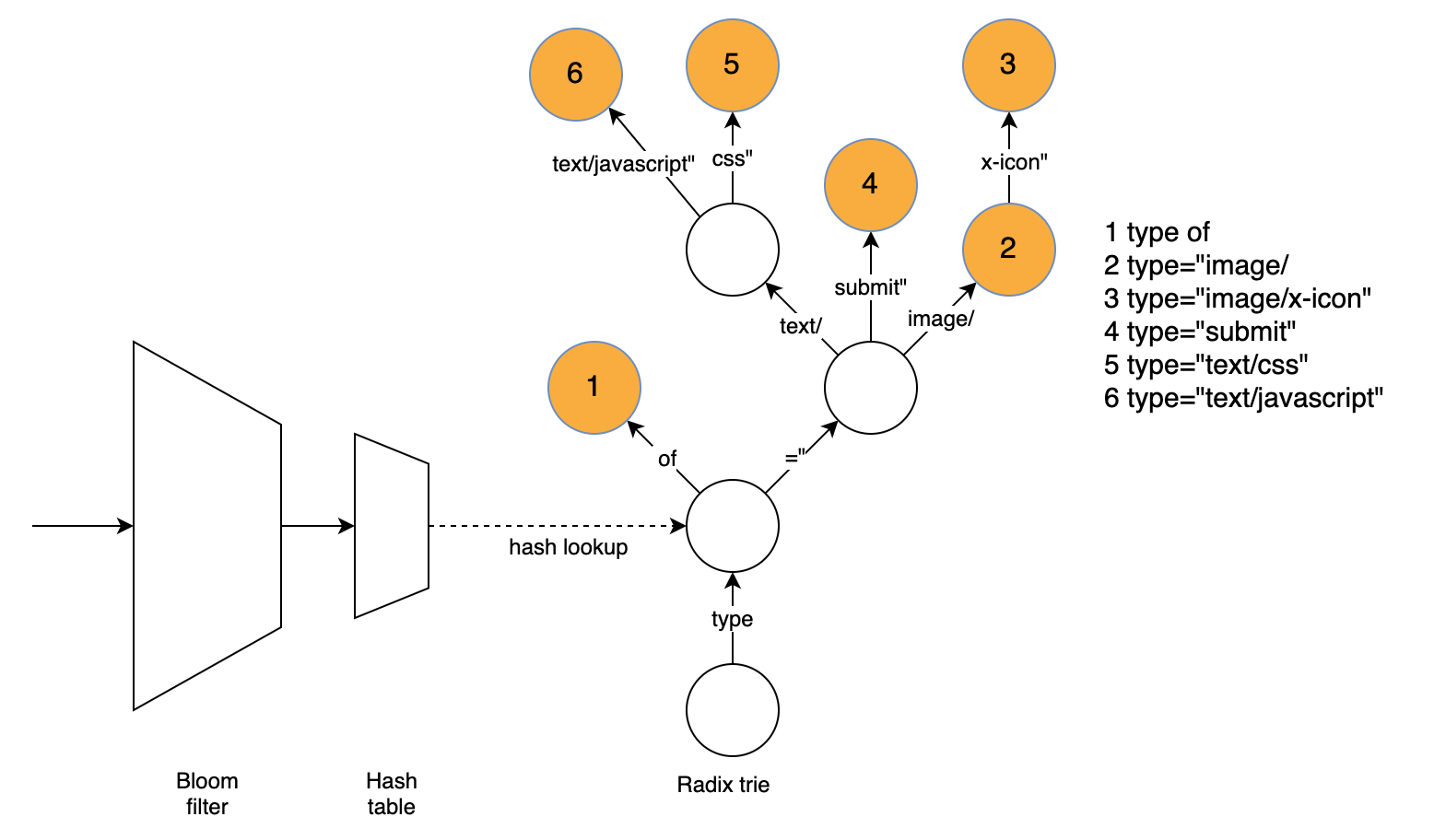
To improve compression without sacrificing performance, we needed a fast way to find matches if we want to search the dictionary more thoroughly than brotli does by default. Our approach uses three data structures to find a matching word directly. The radix trie is responsible for finding the word while the hash table and bloom filter are used to speed up the radix trie and quickly eliminate many words that can’t be matched using the dictionary.
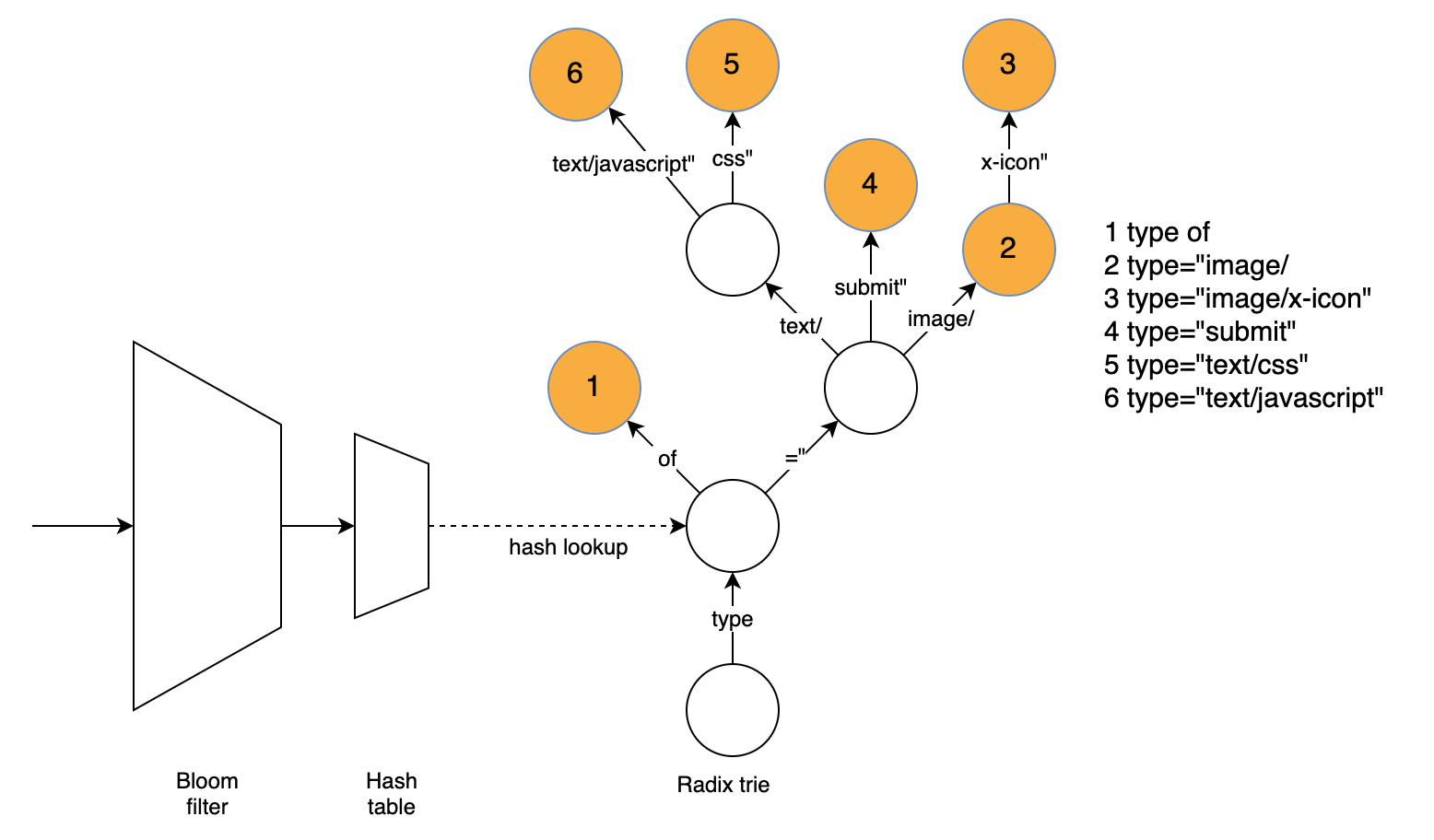
The radix trie easily finds the longest matching word without having to try matching several words. To find the match, we traverse the graph based on the text at the current position and remember the last node with a matching word. The radix trie supports compressed nodes (having more than one character as an edge label), which greatly reduces the number of nodes that need to be traversed for typical dictionary words.
The radix trie is slowed down by the large number of positions where we can’t find a match. An important finding is that most mismatching strings have a mismatching character in the first four bytes. Even for positions where a match exists, a lot of time is spent traversing nodes for the first four bytes since the nodes close to the tree root usually have many children.
Luckily, we can use a hash table to look up the node equivalent to four bytes, matching if it exists or reject the possibility of a match. We thus look up the first four bytes of the string, if there is a matching node we traverse the trie from there, which will be fast as each four-byte prefix usually only has a few corresponding dict words. If there is no matching node, there will not be a matching word at this position and we do not need to further consider it.
While the hash table is designed to reject mismatches quickly and avoid cache misses and high search costs in the trie, it still suffers from similar problems: We might search through several 4-byte prefixes with the hash value of the given position, only to learn that no match can be found. Additionally, hash lookups can be expensive due to cache misses.
To quickly reject words that do not match the dictionary, but might still cause cache misses, we use a k=1 bloom filter to quickly rule out most non-matching positions. In the k=1 case, the filter is simply a lookup table with one bit indicating whether any matching 4-byte prefixes exist for a given hash value. If the hash value for the given bit is 0, there won’t be a match. Since the bloom filter uses at most one bit for each four-byte prefix while the hash table requires 16 bytes, cache misses are much less likely. (The actual size of the structures is a bit different since there are many empty spaces in both structures and the bloom filter has twice as many elements to reject more non-matching positions.)
This is very useful for performance as a bloom filter lookup requires a single memory access. The bloom filter is designed to be fast and simple, but still rejects more than half of all non-matching positions and thus allows us to save a full hash lookup, which would often mean a cache miss.
Heuristics
To improve the compression ratio without sacrificing performance, we employed a number of heuristics:
Only search the dictionary at some positions
This is also done using the stock dictionary, but we search more aggressively. While the stock dictionary only considers positions where the LZ77 match finder did not find a match, we also consider positions that have a bad match according to the brotli cost model: LZ77 matches that are short or have a long distance between the current position and the reference usually only offer a small compression improvement, so it is worth trying to find a better match in the static dictionary.
Only consider the longest match and then transform it
Instead of finding and transforming all matches at a position, the radix trie only gives us the longest match which we then transform. This approach results in a vast performance improvement. In most cases, this results in finding the best match.
Only include some transforms
While all transformations can improve the compression ratio, we only included those that work well with the data structures. The suffix transforms can easily be applied after finding a non-transformed match. For the upper case transforms, we include both the non-transformed and the upper case version of a word in the radix trie. The prefix and cut transforms do not play well with the radix trie, therefore a cut of more than 1 byte and prefix transforms are not supported.
Generating the reduced dictionary
At low compression levels, brotli searches a subset of ~5,500 out of 13,504 words of the dictionary, negatively impacting compression. To store the entire dictionary, we would need to store ~31,700 words in the trie considering the upper case transformed output of ASCII sequences and ~11,000 four-byte prefixes in the hash. This would slow down hash table and radix trie, so we needed to find a different subset of the dictionary that works well for web content.
For this purpose, we used a large data set containing representative content. We made sure to use web content from several world regions to reflect language diversity and optimize compression. Based on this data set, we identified which words are most common and result in the largest compression improvement according to the brotli cost model. We only include the most useful words based on this calculation. Additionally, we remove some words if they slow down hash table lookups of other, more common words based on their hash value.
We have generated separate dictionaries for HTML, CSS and JavaScript content and use the MIME type to identify the right dictionary to use. The dictionaries we currently use include about 15-35% of the entire dictionary including uppercase transforms. Depending on the type of data and the desired compression/speed tradeoff, different options for the size of the dictionary can be useful. We have also developed code that automatically gathers statistics about matches and generates a reduced dictionary based on this, which makes it easy to extend this to other textual formats, perhaps data that is majority non-English or XML data and achieve better results for this type of data.
Results
We tested the reduced dictionary on a large data set of HTML, CSS and JavaScript files.
The improvement is especially big for small files as the LZ77 compression is less effective on them. Since the improvement on large files is a lot smaller, we only tested files up to 256KB. We used compression level 5, the same compression level we currently use for dynamic compression on our edge, and tested on a Intel Core i7-7820HQ CPU.
Compression improvement is defined as 1 – (compressed size using the reduced dictionary / compressed size without dictionary). This ratio is then averaged for each input size range. We also provide an average value weighted by file size. Our data set mirrors typical web traffic, covering a wide range of file sizes with small files being more common, which explains the large difference between the weighted and unweighted average.
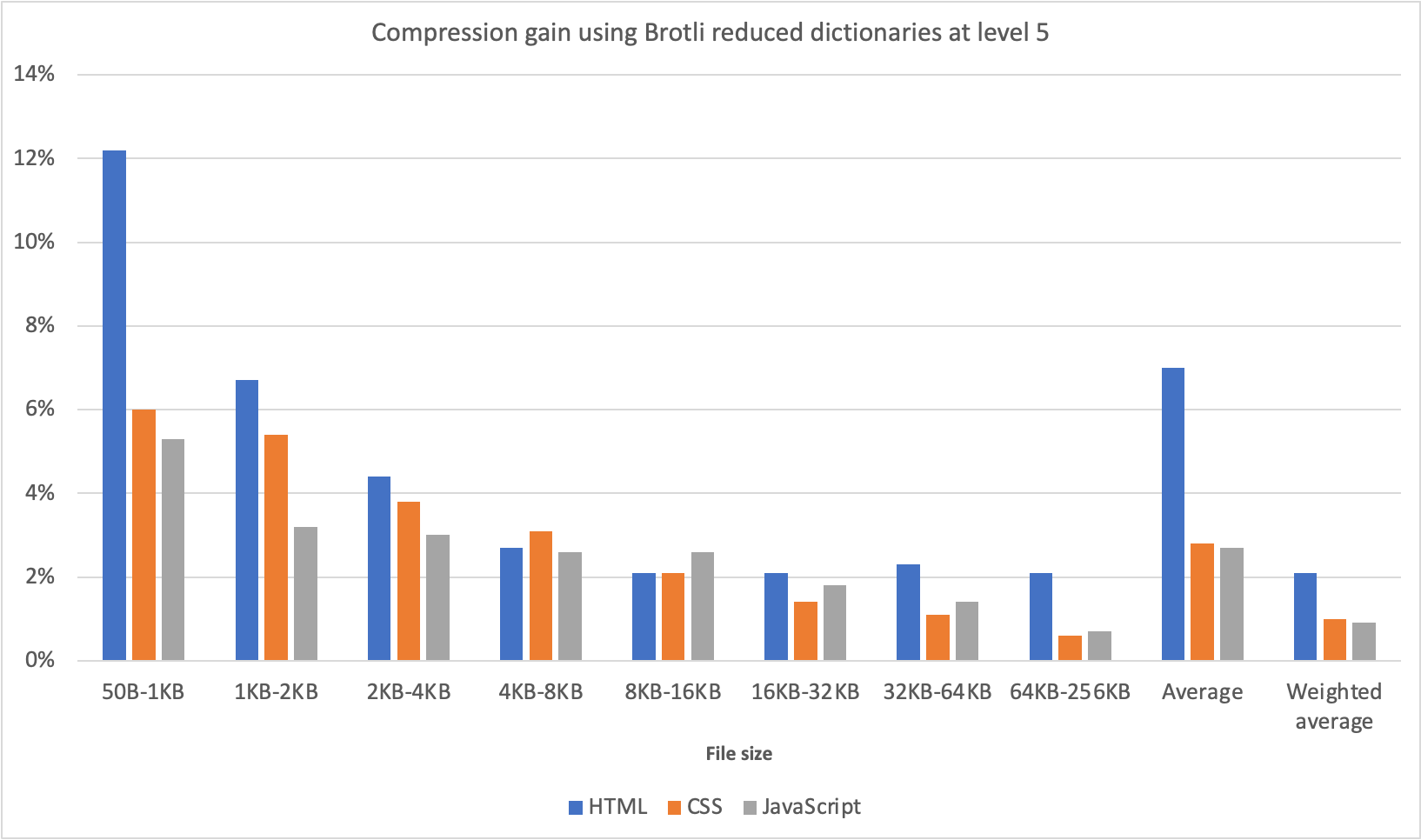
With the improved dictionary approach, we are now able to compress HTML, JavaScript and CSS files as well, or sometimes even better than using a higher compression level would allow us, all while using only 1% to 3% more CPU. For reference using compression level 6 over 5 would increase CPU usage by up to 12%.