Post Syndicated from Landon Dalke original https://blog.rapid7.com/2023/12/04/method-to-an-old-consultants-madness-with-site-design/

If it’s your first time purchasing and setting up InsightVM – or if you are a seasoned veteran – I highly recommend a ‘less is more’ strategy with site design. After many thousands of health checks performed by security consultants for InsightVM customers, the biggest challenge most consultants agree on is site designs with too many sites not healthy. When you have too many sites, it also means you have too many scan schedules, which are the most complex elements of a deployment. Simplifying your site structure and scan schedules will allow you to better optimize your scan templates, leading to faster scanning and fewer potential issues from overlapping scans.
Weekly scanning cadence is the best practice.
The main goal is to use sites to bring data into the database as efficiently as possible and not to use sites to organize assets (data). For data organization, you will want to exclusively use Dynamic Asset Groups (DAGs) or Query Builder, then use these DAGs as your organized scope point for all reporting and remediation projects. Using Dynamic Asset Groups for all data organization will reduce the need for sites and their respective scan schedules, making for a much smoother, automatable, maintenance-free site experience.
For example, if you have a group of locations accessible by the same scan engine:
Site A, managed by the Desktop team using IP scope 10.10.16.0/20
Site B, managed by the Server team using 10.25.10/23
Site C, managed by the Linux team using 10.40.20.0/22
Instead of creating three separate sites for each location, which would require three separate schedule points, it would be better to put all three ranges in a single site (as long as they are using the same scan engine and same scan template), then create three Dynamic Asset Groups based on IP Address: ‘is in the range of’ filtering. This way, we can still use the DAGs to scope the reports and a single combined site with a single scan schedule. Example DAG:
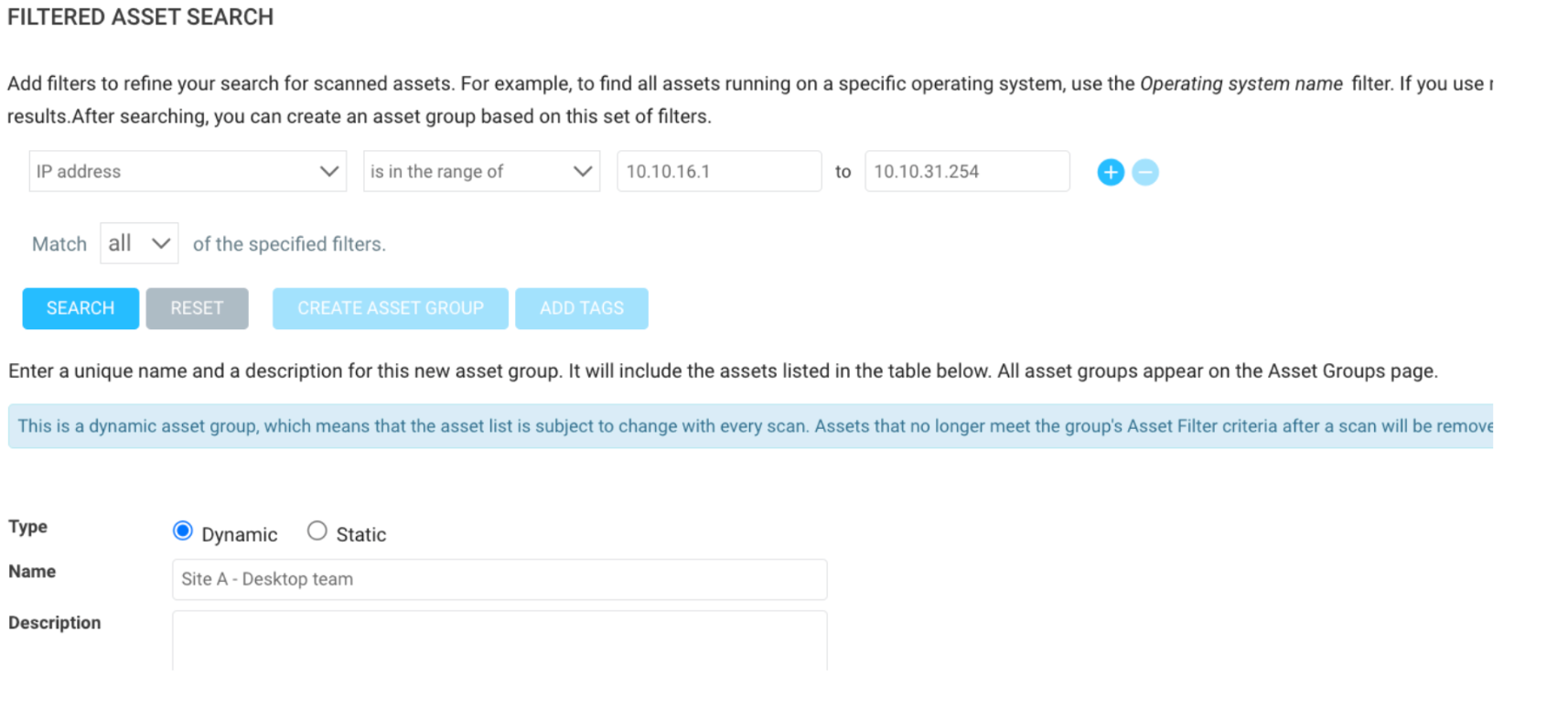
Another reason why this is important is that over the last 10 years, scanning has become extremely fast and is way more efficient when it comes to bulk scanning. For example, 10 years ago, InsightVM (or Nexpose at the time) could only scan 10 assets at the same time using a 16GB Linux scan engine, whereas today, with the same scan engine, InsightVM can scan 400 assets at the same time. Nmap has also significantly increased in speed; it used to take a week to scan a class A network range, but now it should take less than a day, if not half a day. More information about scan template tuning can be found on this Scan template tuning blog.
Depending on your deployment size, it is okay to have more than one site per scan engine; the above is a guideline – not a policy – for a much easier-to-maintain experience. Just keep these recommendations in mind when creating your sites. Also, keep in mind that you’ll eventually want to get into Policy scanning. For that, you’ll need to account for at least 10 more policy-based sites, unless you use agent-based policy scanning. Keeping your site design simple will allow for adding these additional sites in the future without really feeling like it’s adding to the complexity. Check out my Policy Scanning blog for more insight into Policy scanning techniques:
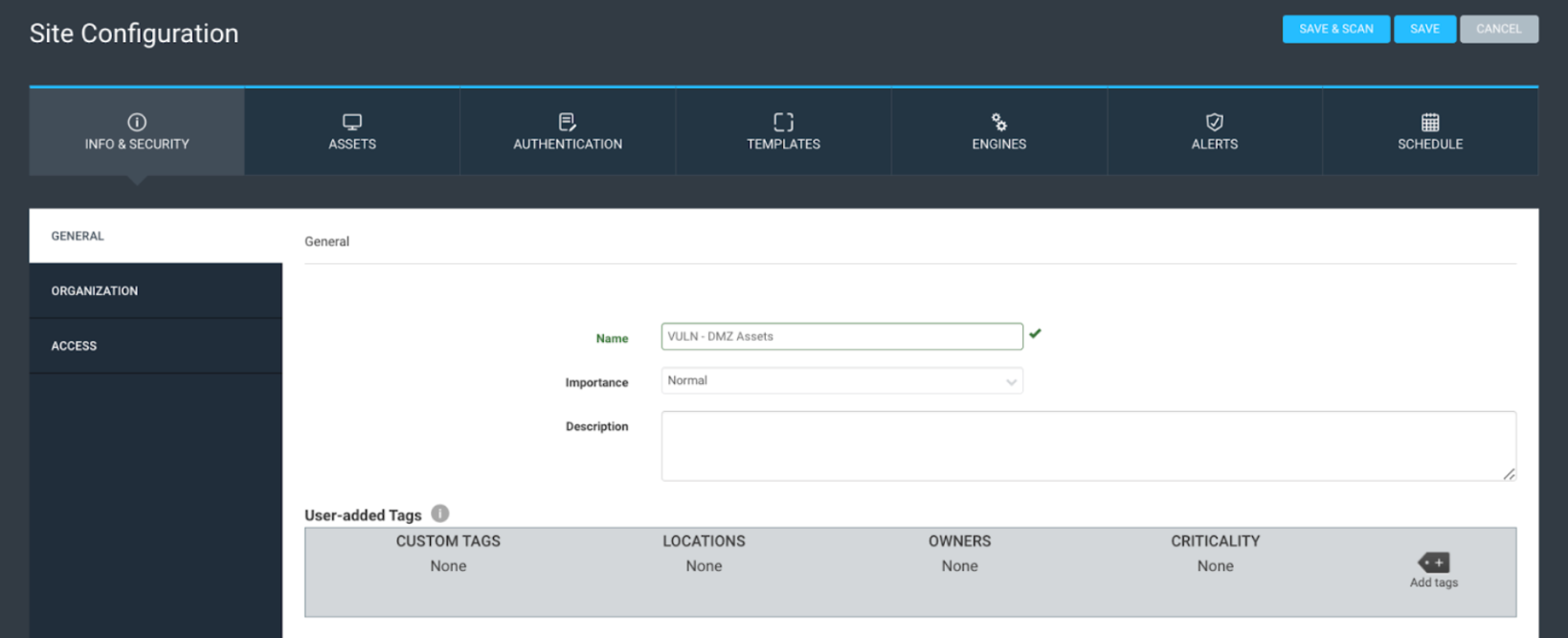
Next, let’s quickly walk through a site and its components. The first tab is the ‘Info and Security’ tab. It contains the site name, description, importance, tagging options, organization options, and access options. Most companies only set a name on this page. I generally don’t recommend using tags with sites and only tagging DAGs. The ‘importance’ option is essentially obsolete, and the organization and access are optional. The only requirement in this section is the site Name.
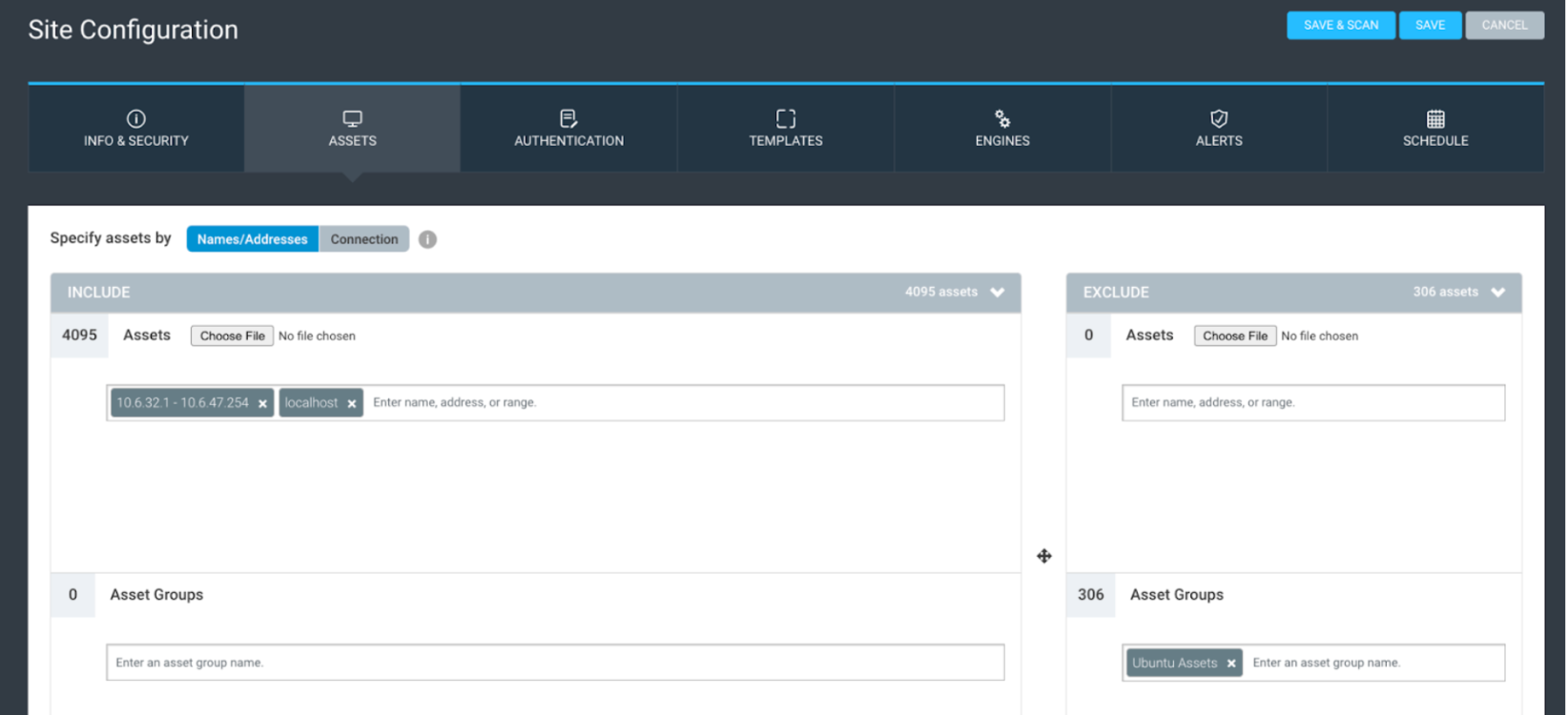
The Assets tab is next, where you can add your site scope and exclusions. Assets can be added using IP address ranges, CIDR (slash notation), or hostname. If you have a large CSV of assets, you can copy them all and paste them in, and the tool should account for them. You can also use DAGs to scope and exclude assets. There are many fun strategies for scoping sites via DAGs, such as running a discovery scan against your IP ranges, populating the DAGs with the results, and vulnerability scanning those specific assets.
The last part of the assets tab is the connection option, where you can add dynamic scope elements to convert the site into a dynamic site. You can find additional information regarding dynamic site scoping here.
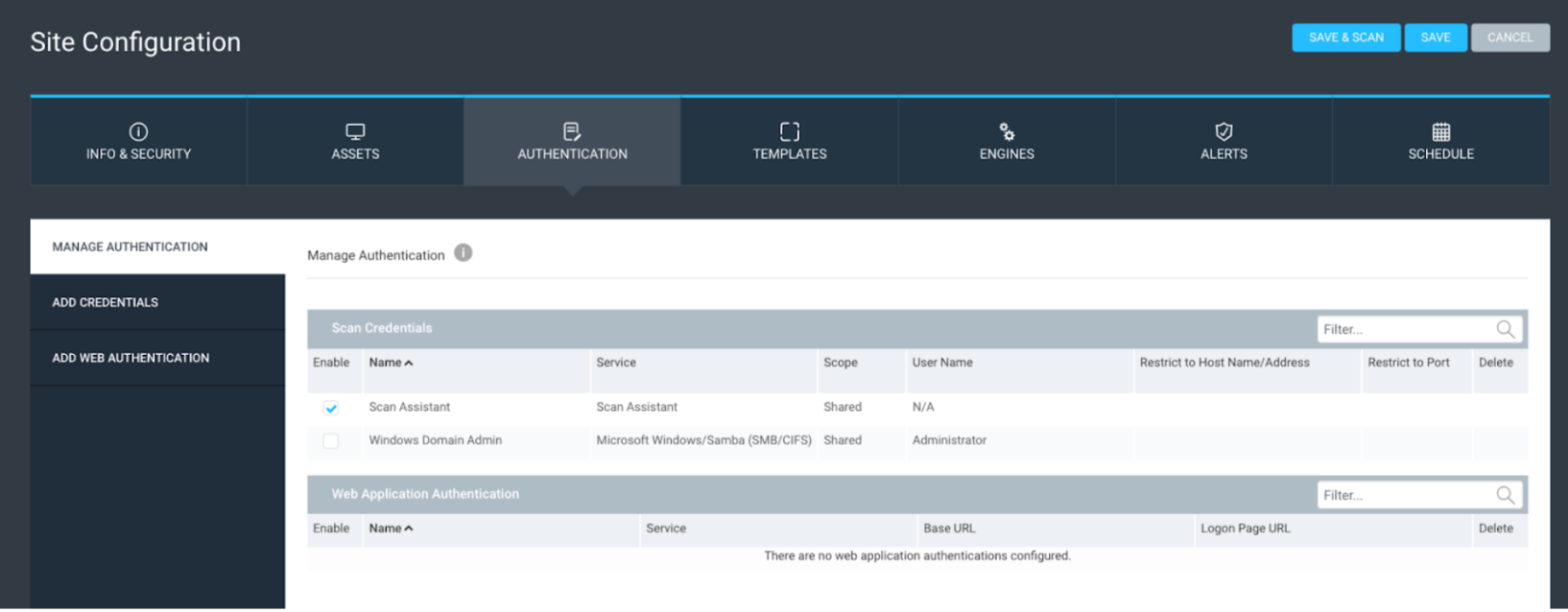
The authentication tab should only validate that you have the correct shared credentials for the site scope. You should always use shared credentials over credentials created within the site.
For the scan template section, I recommend using either the ‘full audit without web spider,’ discovery scan, or a custom-built scan template using recommendations from the scan template blog mentioned above.
In the scan engine tab, select the scan engine or pool you plan to use. Do not use the local scan engine if you’re scanning more than 1500 assets across all sites.
Mostly, I don’t use or recommend using site alerts. If you set up alerts based on vulnerability results, you could end up spamming your email. Two primary use cases for alerts are alerting based on the scan status of ‘failed’ or ‘paused’ or if you want additional alerting when scanning public-facing assets. You can read this blog for additional information on configuring public-facing scanning.
Next, we have schedules. For the most part, schedules are pretty easy to figure out; just note the “frequency” is context-sensitive based on what you choose for a start date. Also, note that sub-scheduling can be used to hide complexity within the schedule. I do not recommend using this option; if you do, only use it sparingly. This setting can add additional complexity, potentially causing problems for other system users if they’re not aware it is configured. You can also set a scan duration, which is a nice feature if you end up with too many sites. It lets you control how long the scan runs before pausing or stopping. If your site design is simple enough, for example, seven total sites for seven days of the week, one site can be scheduled for each day, and there would be no need for a scan duration to be set. Just let the scan run as long as it needs.
Site-level blackouts can also be used, although they’re rarely configured. 10 years ago, it was a great feature if you could only scan in a small window each day, and you wanted to continue scanning the next day in that same scan window. However, scanning is so fast these days that it is almost never used anymore.
Lastly, a weekly scanning cadence is a recommended best practice. Daily scanning is unnecessary and creates a ton of excess data – filling your hard drive – and monthly scanning is too far between scans, leading to reduced network visibility. Weekly scanning also allows you to set a smaller asset data retention interval of 30 days, or 4 times your scan cycle, before deleting assets with ‘last scan dates’ older than 30 days. Data retention can be set up in the Maintenance section of the Administration page, which you can read about here.
I am a big advocate of the phrase ‘Complexity is the enemy of security’; complexity is the biggest thing I recommend avoiding with your site design. Whether scanning a thousand assets or a hundred thousand, keep your sites set as close as possible to a 1:1 with your scan engines. Try to keep sites for data collection, not data organization. If you can use DAGs for your data organization, they can be easily used in the query builder, where they can be leveraged to scope dashboards and even projects. Here is a link with more information reporting workflows.
In the end, creating Sites can be easier than creating DAGs. If, however, you put in the extra effort upfront to create DAGs for all of your data organization and keep Sites simple, it will pay off big time. You’ll experience fewer schedules, less maintenance, and hopefully a reduction of that overwhelming feeling seen with so many customers when they have more than 100 sites in their InsightVM deployment.
Additional Reading: https://www.rapid7.com/blog/post/2022/09/12/insightvm-best-practices-to-improve-your-console/












