Post Syndicated from Luke Edwards original https://blog.cloudflare.com/production-saas-intro/


The Cloudflare documentation is a great resource when learning concepts, reviewing API usage notes, or when you’re in need of a concise snippet to illustrate those APIs or concepts. But, as comprehensive as it is, new users to the Cloudflare Workers platform must bridge a large gap to go from the introductory example snippets to a real, production-ready application. While some of this may be specific to Workers (as with any platform), developers everywhere are figuring out how applications should be built in a serverless world. Building large serverless applications entails a learning curve journey, regardless of a developer’s experience level.
At Cloudflare, we’re intimately aware of this because we also had to go through the same transition. Our engineers are world-class and expertfully design and craft products that compliment the distributed paradigm… but experts aren’t born overnight! We have been there, and we want to help jumpstart and aid others’ understanding.
With this in mind, we decided to do something unique to the industry: we are developing an example feature-complete SaaS application that will be built entirely on the Cloudflare stack. It is and will continue to be completely free, open-sourced on GitHub, and developed in public. This will be an incredible time as it can be used as a template for launching your own SaaS applications, too! In fact, you can clone the GitHub repository, update a few service tokens, and deploy the pre-built application to your own Cloudflare account within minutes!
Of course, examples and templates are great, but technologies and best practices never stop evolving. Cloudflare is no exception and is constantly iterating and introducing new products and product features. By extension, this requires the SaaS application to be a living example that evolves alongside the Workers platform — and this is part of our commitment.
|| Don’t miss out! Watch the project on GitHub to track its development progress and stay current with our latest changes and recommendations.
Application Overview
Now, aside from actually building the application, we needed to find a balance between picking an example SaaS application that is both complex enough to serve as a convincing case study and simple — or self-contained — enough so that developers can quickly dive in, follow the source, and understand the components involved and the reasons why and/or how they are used.
Ultimately we decided to build an example content management system (CMS) which, as an application archetype, has also transformed over the years. Traditionally, a CMS operated on rented hardware, which was home to a long-lived server that handled incoming requests and queried an SQL-like database in order to retrieve the requested content, render it to an HTML page, and repeat the process over and over again. WordPress was — and still is — a very common example of this approach.
Naturally, this application architecture was improved over the years: layers of caching were introduced, database schemas were redesigned to minimize the number of rows processed, and some frameworks began to skip the database entirely, preferring a build-step to render all content upfront as static HTML pages. (This is now known as “static-site generation” and is still a very popular approach.)
Today, in the serverless era, there are a number of “headless CMS” options available. These are made “headless” because they are not monolithic web servers that render HTML for each request. Instead, they offer API endpoints that will return the content as raw JSON data. This allows web developers to build completely custom templates for their website using whatever tools and/or frameworks they prefer. This approach grants an enormous amount of flexibility to the developer without losing the ability to organize their content, image assets, etc. WordPress, the seasoned veteran, is one of few that is able to offer a headless and a “headful” mode. Other headless choices, like Sanity.io and Contentful, are also quite popular.
The CMS application model is a great case study for our open-source example. One of the primary tenets of an edge-first design is that content should be made available as close as physically possible to the users asking for it. And the serverless architecture means that there’s no longer — or should not be — a single point of failure. These both directly benefit the CMS archetype and, when implemented, will yield clear performance gains.
Current Progress
Before diving into the roadmap and explaining how this project will progress, it’s important to call out that this project has already been — and will continue to be — an ongoing effort! Today, you can find the project on GitHub and inspect the work that’s already been completed. As of now, the application already combines Workers, Workers KV, Cloudflare for SaaS, and Rate Limiting with Pages and Durable Objects additions to come in later milestones.
Phase 1 (see below) is nearing completion and, when finished, will mark the end of a very significant milestone. A new update to this blog post series will be issued, covering the highlights and technical overview of the project so far. This is important and immediately useful because on its own, Phase 1 qualifies for a successful, full-stack application.
Development Milestones
The CMS application will progress in milestones. We have already released the project and will continue to build upon it in accordance with the roadmap (below). GitHub stargazers will be able to keep tabs on its progress, or at the very least, only subscribe to updates for the milestones they’re interested in following.
Each milestone is a sizable checkpoint on its own. As you’ll see below, the project roadmap is planned in a way such that each phase adds a considerable amount of new features and/or integrates with a new Cloudflare product. At every point, the application will remain functional and maintain a live, interactive demo to immediately demonstrate the latest functionality to passersby.
This format is chosen because it’s how real applications — and real products — are developed. Our goal is to ensure that the GitHub repository is never out of date. And, because of the development structure, one may always traverse the list of past milestones to review the changes that were necessary to migrate X or how product Y was integrated.
|| Note: Visit the GitHub milestones to view more details and to subscribe for updates. There is so much more than can be listed here.
Phase 1 – JSON API
The project must begin with some API endpoints to start managing and manipulating data. Using Workers and Workers KV, the work within this milestone will focus on building a robust JSON API that handles the core functionality that the rest of the application will need.
There is no HTML, CSS, or client-side JavaScript involved in this phase. Instead, work here should focus solely on the data: how it’s accessed, how models relate to one another, and how best to structure and store these relationships within Workers KV. For example, individuals should be able to create and manage workspaces that belong to their personal user accounts or to the organization(s) that they belong to.
Additionally, when creating content, the document should be validated against an existing schema that the document was assigned. This feature is critical in any CMS platform that plans to handle thousands of documents within a workspace. Without it, there’s very little confidence that your contents’ JSON representation is consistently structured.
A number of other features are planned — subscription management and invoicing through Stripe, sending transactional emails through SendGrid, and assigning vanity domains to workspaces through Cloudflare for SaaS. Finally, of course, the standard house-keeping tasks will be set up. This includes continuous integration (CI) with API testing and automated, continuous deployments (CD).
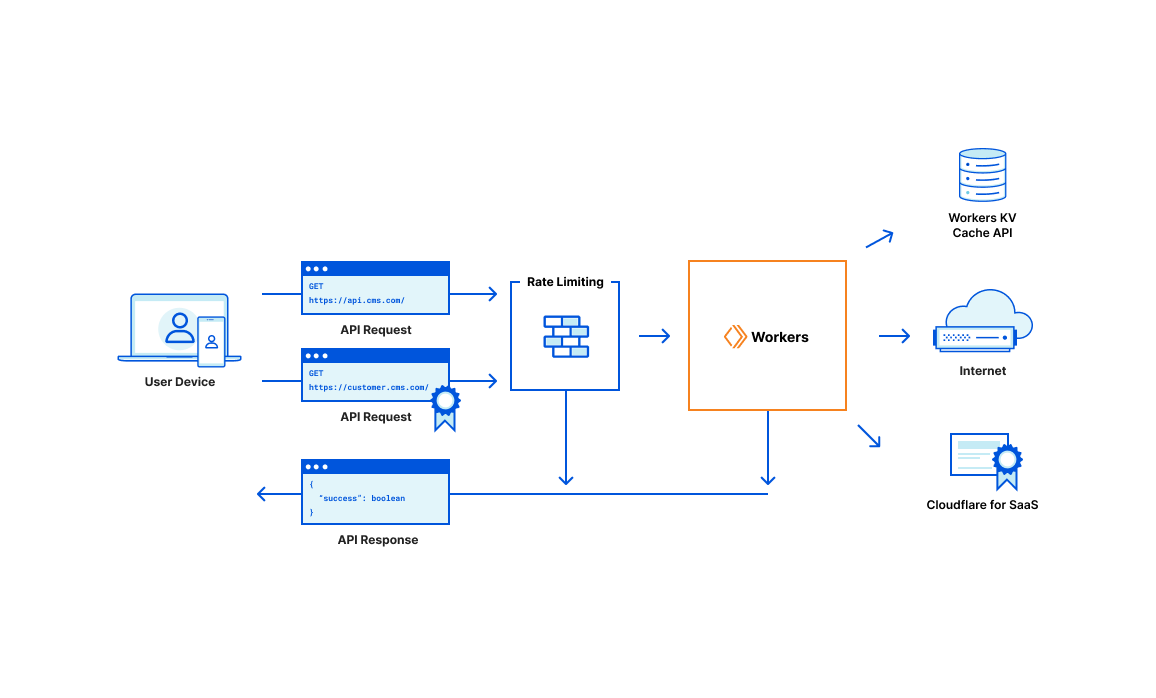
By the end of this phase, the project will exist as a collection of API endpoints that, on its own, is a complete application. While it may only be accessible through curl commands — or any other preferred method for manually constructing HTTP requests, the completion of Phase 1 already qualifies the project as a full-stack application and could serve a real-world SaaS product.
Additionally, the repository will include all the best practices for writing tests, automating deployments, and organizing the source in a way for long-term growth and maintenance. And, because we started with the JSON API, the project is immediately useful and capable of integrating with your existing build tools and frameworks. In other words, stargazers could deploy the project to their own accounts as their own personalized Headless CMS. Perhaps some of you will build Gatsby or Eleventy plugins — if you do, please let us know!
Phase 2 — Dashboard UI
As fun as curl may be, most people prefer some form of visual interface they can interact with. This phase will be all about assembling a frontend to serve as the CMS application’s dashboard.
We will use Svelte, a JavaScript framework for building user interfaces. While not everyone may enjoy or agree with this decision, the templating syntax resembles standard HTML markup, which will allow non-frontend developers to follow along and gauge what’s going on.
Svelte will be paired with Tailwind CSS for the design system. Tailwind is a very popular, utility-first CSS framework that allows developers to compose styles through predefined, reusable HTML ”class” names.
The result will be a single-page application (SPA) and will be hosted on Cloudflare Pages. This means that, out of the box, the dashboard will be able to take advantage of Access-protected preview deployments, instant rollbacks, automated deployments, comprehensive analytics, and more.
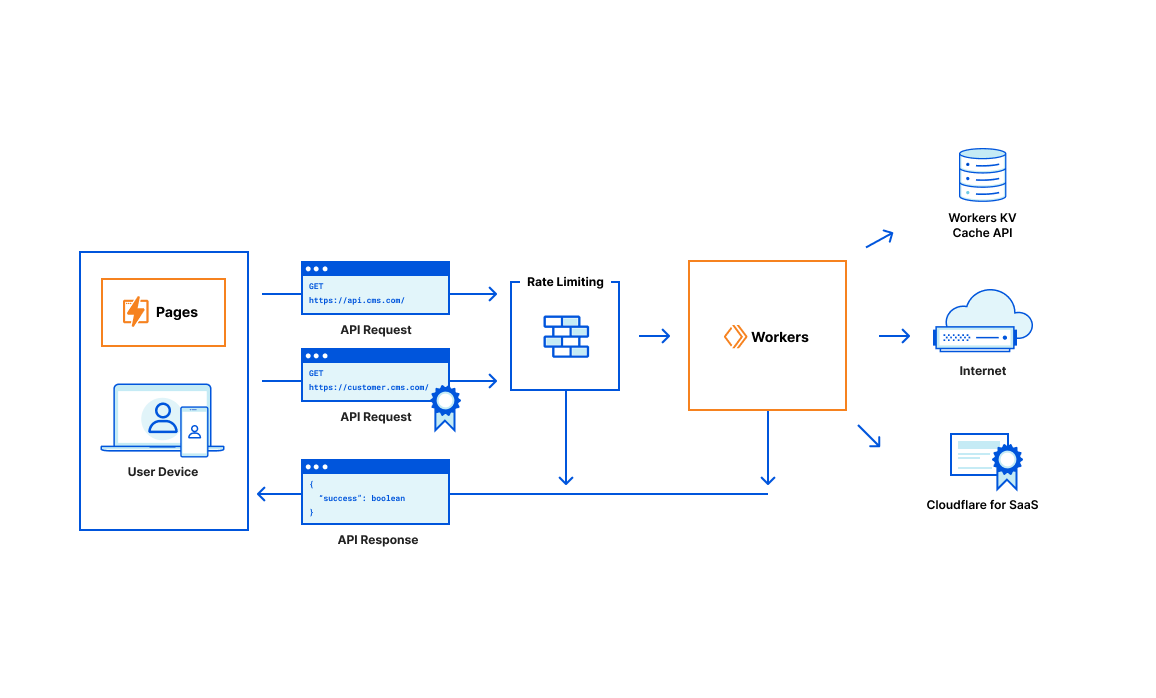
Finally, now that Pages integrates with Workers directly, the JSON API from Phase 1 will migrate into a new repository structure. While this may seem like an innocent refactor, it actually unlocks an incredible set of features for the JSON API: Access-protected preview deployments, instant rollbacks, and automated deployments. Yes — these are the same Pages features mentioned above! This is amazing because it means that our API is continuously and atomically versioned, allowing its development to continue safely alongside the client dashboard that depends on it. In other words, there is zero risk of the API and the dashboard diverging, which would have allowed their expectations of one another to misalign. Instant rollbacks will also apply to the API since the entire application operates as a single Pages unit.
The previous phase will have built the core SaaS product functionality, but completing this phase will make it feel like a real-world product that can be launched and used on a daily basis. In fact, the end of Phase 2 marks the application as a possible contender in the Headless CMS service space.
Phase 3 — Article Edge-Rendering
The previous phases are focused on assembling a minimum viable Headless CMS product, but Phase 3 looks to grow outside this archetypal box. This will happen by allowing the application to render HTML web pages by injecting the JSON content into predefined templates.
Like WordPress, the CMS application should allow its users to choose whether they want to continue using the “headless” feature or enlist the complete template engine. Should they opt for HTML output, the Cloudflare project will only include a few premade templates that a user may select from — but, of course, this can be customized in your own projects.
Even though this phase reintroduces the monolithic CMS archetype, it’s a significantly safer, faster, and more resilient architecture than the single, all-in-one server of yesteryear. The CMS contents will still be distributed around the world, close to the customers’ readers — but now, the content can be rendered from anywhere in the world at extremely low latencies, too.
Phase 4 — Feature Upgrades
At this stage, the application is — for the most part — complete. It’s functional, looks nice, performs well globally, and can be used in two very distinct ways.
In the context of a real SaaS product, development begins to shift towards adding new features that excite users or towards maintenance health of the project. For example, Phase 4 will utilize Durable Objects to introduce a document editor that allows multiple users to edit the same document in a real-time, collaborative environment.
It’s also very likely that Cloudflare R2 Storage will be introduced as a backend for media assets, allowing users to upload and manage images within a workspace. Or perhaps we decide to use Cloudflare Images for this and R2 is used for importing and exporting content backups.
As you may expect, this milestone is full of unknowns, but that’s because the future holds unlimited possibilities. The project will continue to evolve and expand with Cloudflare and with time.
Of course, if you have ideas or suggestions for features, start a discussion with us on GitHub. We would love to hear from you!
Next Steps
This was the introductory post of (what will be) an ongoing series. When each milestone is completed, we will publish a new post in this series with a retrospective and with technical walkthroughs of key aspects from that chapter’s work.
We’re at the beginning of an exciting journey, and we hope you’re as interested as we are!
You can show your support by starring or following the project on GitHub. All releases, discussions, and milestone tracking will reside within the repository. The next generation of SaaS applications will be built on Cloudflare — subscribe and dive in early!