Post Syndicated from Reagan Russell original https://blog.cloudflare.com/2021-innovations-weeks/


One of the things that makes Cloudflare unique is our Innovation Weeks. Rather than having one large conference annually, we have multiple Innovation Weeks throughout the year to highlight new product announcements, beta products opening up to general availability, and share how our customers are using Cloudflare to help build a better Internet.
Internally, these weeks generate a lot of energy and excitement as well, as they provide an opportunity for teams from across Cloudflare to work together on product delivery and celebrate company-wide successes. In 2021, we had seven Cloudflare Innovation Weeks. As we start planning our 2022 Innovation Weeks, we are reflecting back on the highlights from each of these weeks.

Security Week March 21-26, 2021
Patrick Donahue
Security Week kicked off Cloudflare’s 2021 Innovation Weeks with a series of foundational security announcements. The Internet wasn’t built with security in mind, but the products and partnerships announced this week continued Cloudflare’s core mission of helping build a better Internet—one that companies of all sizes can plug into and be protected by default from the types of attacks that have historically resulted in loss of data, computing resources, and customer confidence.
At the start of the week, we took on the task of replacing MPLS, the core network technology that many organizations use to connect their offices and data centers, with a more secure and cost-effective alternative. Next, we tackled the biggest risk to everyday users of the web by opening our remote browser isolation technology to teams of all sizes and protecting against malicious code injection. Following those announcements, we inverted the slow, network chokepoint model of data loss prevention by building zero trust controls over data directly into every aspect of the Cloudflare One suite. And to round out the week, we democratized access to bot-fighting technology previously only available to the largest enterprises while also deepening our solutions for novel threats facing APIs.
View all Security Week 2021 Blog Posts
View all Security Week 2021 Cloudflare TV Series

Developer Week April 11-17, 2021
Alyson Cabral
With Developer Week, we had one focus – to make developers’ lives easier. Our announcements included Cloudflare Pages being made generally available, Introducing Web Socket Support in Workers, Workers Unbound, Free Tunnels, Partnering with Nvidia to bring AI to the Edge and many more announcements throughout the week. In addition to the announcements, we also launched our first ever Developer Challenge series. Each day, a new challenge was announced to encourage developers from across the globe to level up their skills by trying new features and approaches. Solutions were revealed the following day, with the bonus round solution wrapping up the week. To keep up to date on the next round of challenges, join our Cloudflare Developer community.
View all Developer Week 2021 Blog Posts
View all Developer Week 2021 Cloudflare TV Series

Impact Week July 26-31, 2021
Patrick Day
During our first Impact Week, we reflected on how we are achieving Cloudflare’s mission–helping build a better Internet– and why we continue to prioritize projects that give back to the Internet. Impact Week highlighted some of the things we are doing as a company around environmental, social and governance initiatives. We launched Project Pangea, a free program to provide secure, reliable access to the Internet for community networks that support under-served communities. We also shared how we are committed to helping build a green Internet through efficiency, renewable energy, and providing developers a choice to run their workloads in the most energy efficient data centers. In addition, we published our first human rights policy in order to better serve our mission and core values.
View all Impact Week 2021 Blog Posts
View all Impact Week 2021 Cloudflare TV Series

Speed Week Sept 12-17, 2021
Marc Lamik
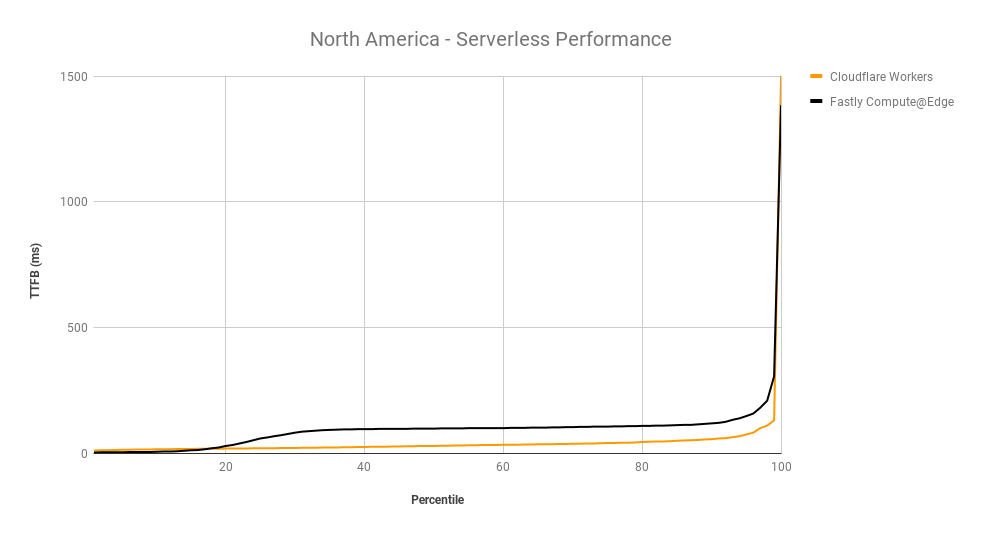
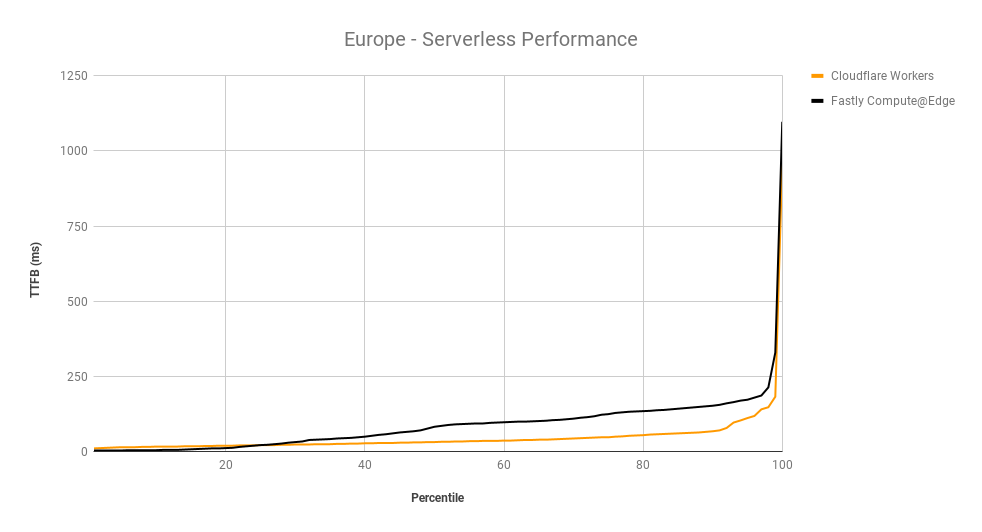
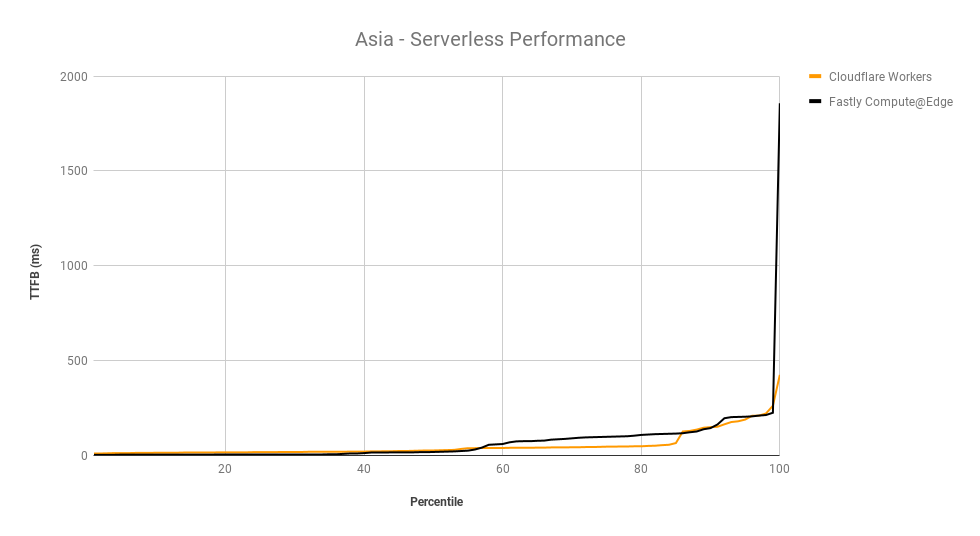
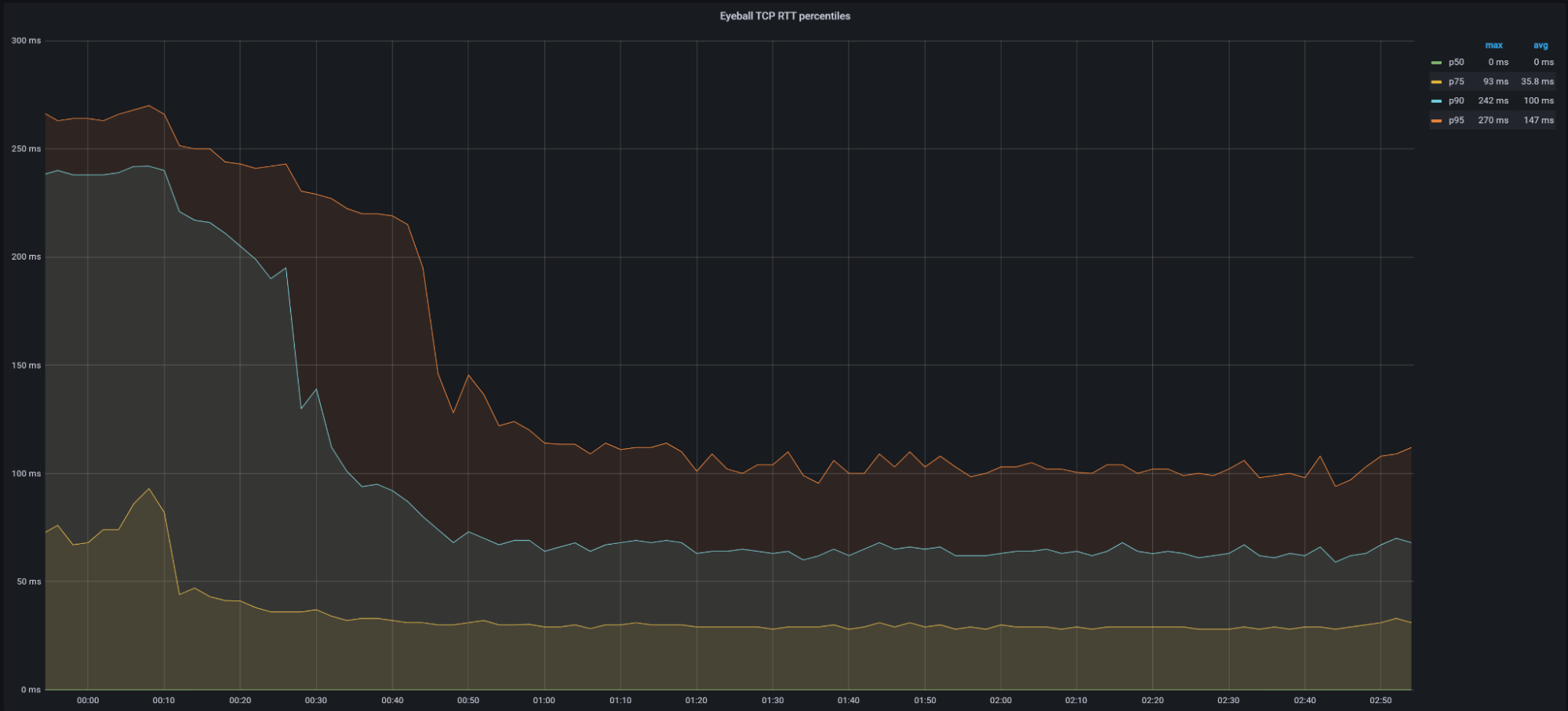
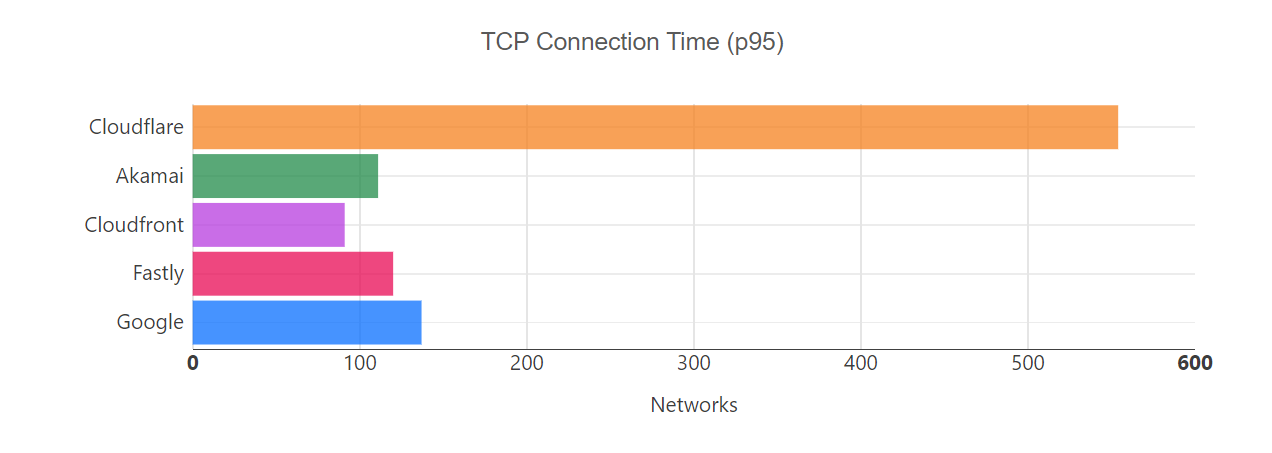
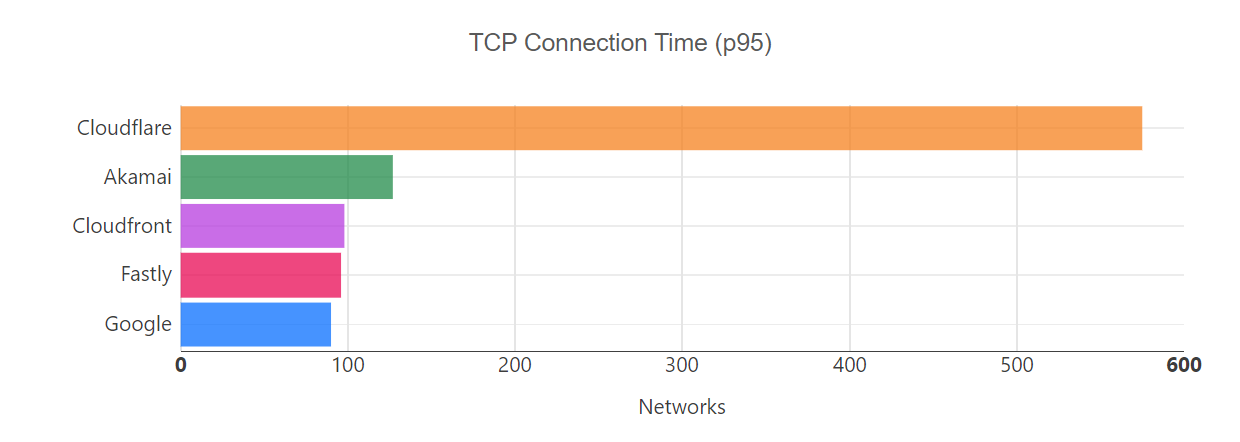
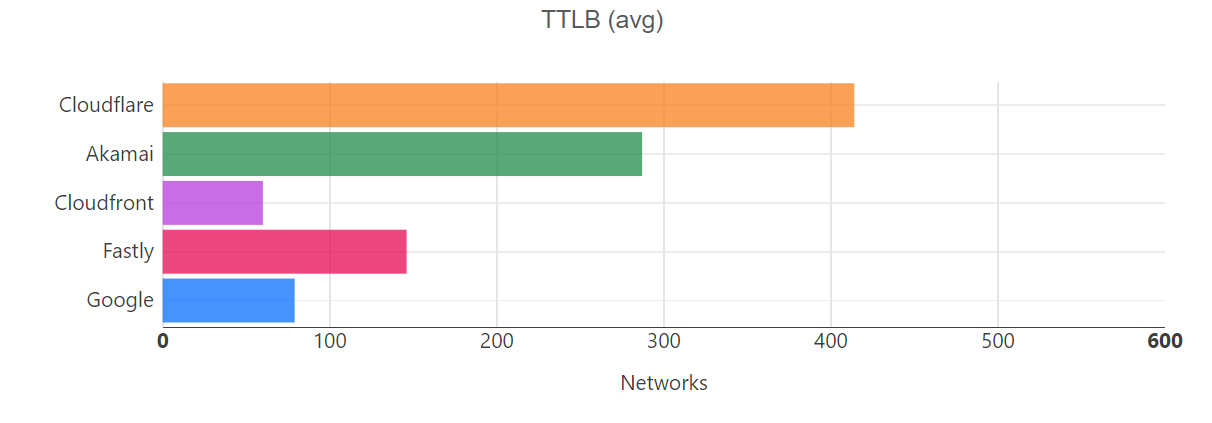
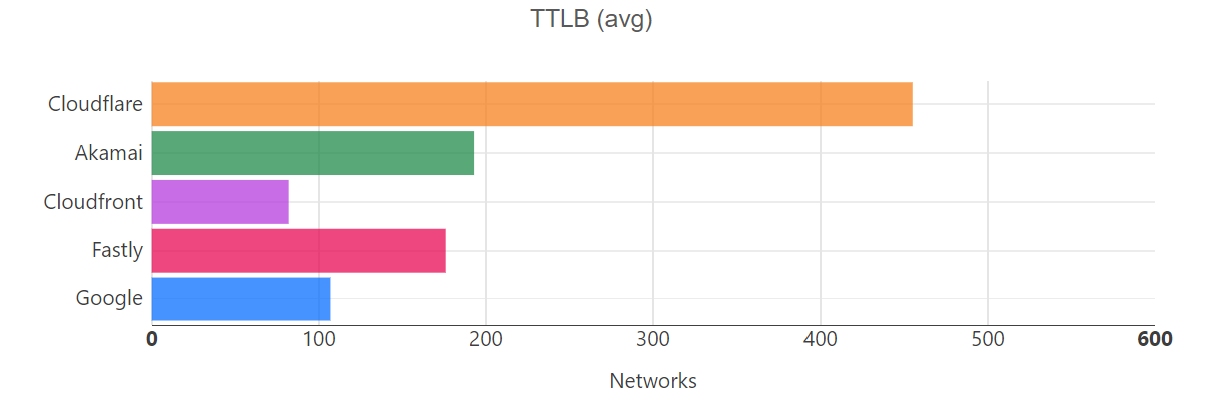
Helping make the Internet faster is one of Cloudflare’s core priorities. During Speed Week we shared how fast Cloudflare’s Network is as well as the amazing performance of Workers and Pages’ lightning fast speed. We expanded the size of Cloudflare’s network, so it’s closer to more people than ever.
We launched two amazing performance features with Signed Exchanges reducing load times and increasing SEO rankings with one click as well as Early Hints which can reduce loading times by 30%.
As part of Speed week, we also announced Cloudflare Images which stores, resizes, optimizes and serves images so that all of our customers can build a scalable, affordable image pipeline.
View all Speed Week 2021 Blog Posts
View all Speed Week 2021 Cloudflare TV Series

Cloudflare Birthday Week Sept 26-Oct 1, 2021
Dane Knecht and Jennifer Taylor
This is the week in which we celebrate Cloudflare’s birthday. We launched the company 11 years ago: September 27, 2010. It has been our tradition, since our first birthday, to use this week to launch innovative products that we think of as our gift back to the Internet. In 2021, we announced Cloudflare R2, our object-based storage with no egress fees, tackled solutions to Email Spoofing and Phishing, shared how we are expanding our network into office buildings as well as many more product announcements and Cloudflare TV executive fireside chats and product discussions.
View all Birthday Week Blog Posts
View all Birthday Week Cloudflare TV Series

Full Stack Week Nov 14-19, 2021
Rita Kozlov
During Full Stack Week, we brought the vision of the Network is the Computer to life — allowing developers to build their entire application on our network, soup to nuts. Over the course of the week, we made a series of announcements, each providing another critical piece of the puzzle, necessary to build a full stack application.
We started with the foundation — data, announcing the general availability of Durable Objects, and ability to connect to databases, alongside partnerships with MongoDB and Prisma. Cloudflare Pages, our Jamstack platform also took a step deeper down the stack by introducing support for seamless deployment of functions. We want development on our platform to be an enjoyable experience, so we announced the new version of wrangler, our CLI, and Services, a better way for teams to build applications. And while we want developers to have fun, we also want them to be able to monetize their efforts, which they now can do using the Stripe SDK on Workers.
View all Full Stack Week 2021 Blog Posts
View all Full Stack Week Cloudflare TV Series

CIO Week Dec 5-10, 2021
Annika Garbers
To wrap up the year, we demonstrated how Cloudflare One, our Zero Trust Network-as-a-Service, is helping Chief Information Officers transform their corporate networks. We launched new capabilities in Cloudflare One to help customers replace their hardware firewalls and a chance to win a trip to Oahu in the process, a Log Storage platform built on Cloudflare R2, a new premium DNS offering, and Cloudflare Security Center, which helps customers map their attack surface and mitigate potential security risks with just a few clicks. We also announced our acquisition of Zaraz to boost website speed and security without sacrificing privacy, as well as new partnerships with Microsoft and leading cyber insurance providers, among many other exciting announcements throughout the week.
View all CIO Week 2021 Blog Posts
View all CIO Week 2021 Cloudflare TV Series