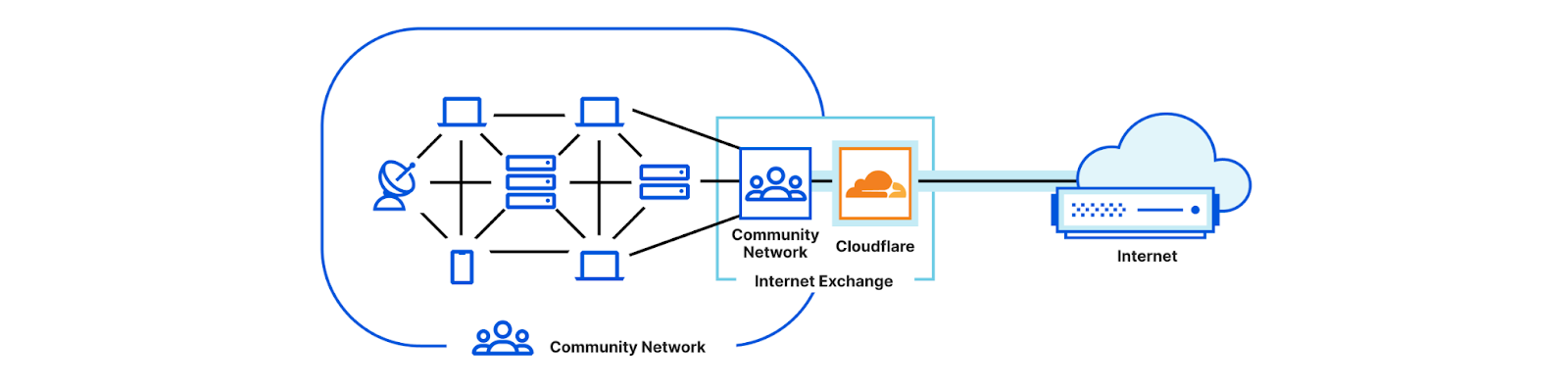
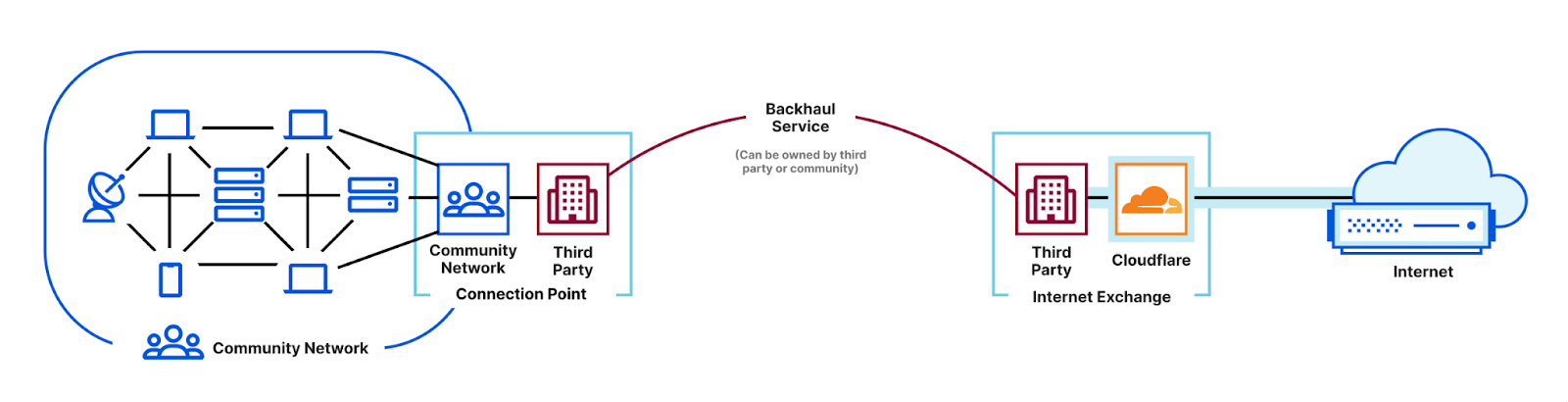
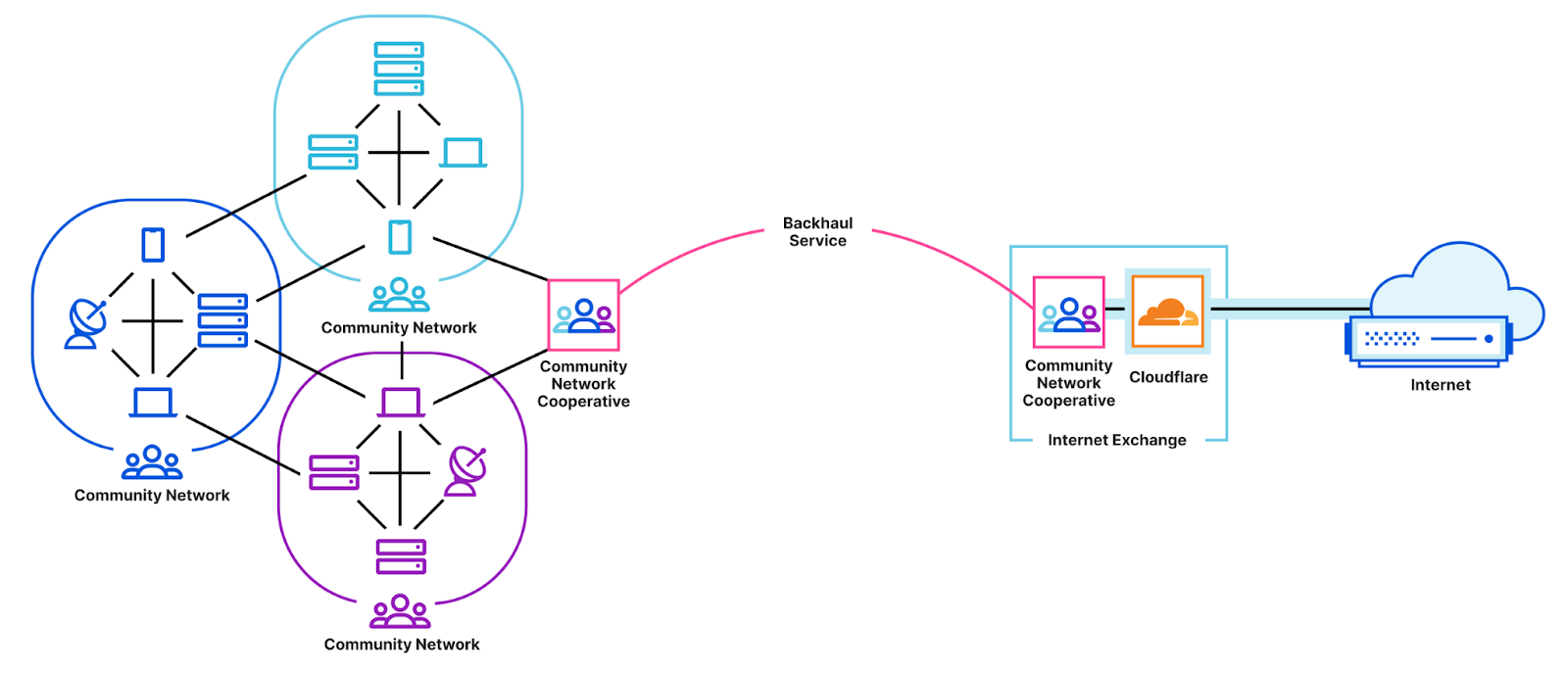
Post Syndicated from Marwan Fayed original https://blog.cloudflare.com/tricky-internet-measurement/
Measurement is critical to our understanding not just of the world and the universe, but also the systems we design and deploy. The Internet is no exception but the challenges of measuring the Internet are unique.
The Internet is remarkably opaque, which is counter-intuitive given its open and multi-stakeholder model. It’s opaque because ultimately the Internet joins many networks and services that are each owned and operated by unrelated entities, and that rarely share or report about their systems. Every network may carry and forward what other systems produce, but each system is entirely independent — which, to be honest, is the magic of the Internet. It’s in this opaque-yet-critical context that Internet measurement must exist as a scientific practice, with all the associated rigor, repeatability, and reproduction.
Measurement as a scientific practice can be exciting — for what it gets right as well as wrong. The following statement encapsulates some of the subtleties:
“5 out of 6 scientists say that Russian Roulette is safe.”
The statement is absurd! Laugh as we might, the statement is also logical. It’s trivially easy to design an experiment that leads to the above statement. However, the only way this experiment could succeed is if the “actor” — that is, whoever conducts the experiment — ignores every aspect of measurement science that makes the practice credible, as follows.
-
Methodology: a cycle consisting of data curation, modeling, and validation. Here, the experiment (data curation) could only succeed if each participant is prevented from seeing others’ injuries. More importantly, no measurement is needed because the actor can calculate probabilities with available numbers, without the experiment!
-
Ethics: the way we measure can have undue, undesirable consequences. A bare minimum principle is do no harm.
-
Representation: clear and complete statements or visualizations should be at least informative and ideally actionable; otherwise, they can be misleading. Say each participant answered with yes to the question, “are you safe?” They are answering a different question than “is the game safe?”
In this blog we look at each of the above aspects of measurement, describe how they manifest in the Internet space, and relate them to examples from work that will be featured throughout the week. Let’s first start with some background.
High quality measurements help to identify, understand, even explain our experiences, environments, and systems. However, observation in isolation, without context, can be perilous. The following is a time series from an internal graph of HTTP requests from Lviv, Ukraine, leading up to the evening of 28 February 2022:

On that day, traffic from the region increased by 3-4X. For context, the Russian incursion into Ukraine began four days earlier. The world was watching events closely. Cloudflare was no exception, helping both to report and to mitigate network effects.
Upon observing that abnormal spike, we at Cloudflare could have mistakenly reported the increase as a potential DoS attack. However, there were counter-indications. First, no attack was flagged by the DoS defense and mitigation systems. In addition, the profile was atypical of attack traffic, which tends to be either single source from a single location or multiple sources from multiple locations. In this instance the increase came from multiple source networks but in a single location (Lviv).
Cloudflare had the tools to avoid erroneous reporting and later correctly reported that the increase was due to a mass of people converging in Lviv, the city with the last train station on the westward journey out of Ukraine. But — and this is important in a measurement context — nothing visible from Cloudflare’s perspective could provide an explanation. In the end, an employee saw a report on BBC about the massive movement of people in that part of Ukraine, which enabled us to better explain the traffic shift.
This example is an important reminder to always look for alternative explanations. It also shows how observations alone can lead to wrong conclusions, due to missing information or unrecognized biases. But good numbers without bias can be misunderstood, too.
In the measurement context there is a vocabulary of common words with specific meanings that are useful to know before diving into practice and examples.
These describe the “how.” In an active measurement, an actor initiates some action designed to trigger a response. The response may be data, such as latency returned from a ping or a DNS answer in response to a query. The response may be an observable change in a mechanism or system triggered by an action, such as well-crafted probe packets that prompt reactions from and expose middleboxes.
In a passive measurement, the actor only observes. No action is taken. As a result, no response is triggered; the system and its behaviour are unaltered. Logs are typically compiled from passive observations, and Cloudflare’s own are no exception. The vast majority of data shown in Cloudflare Radar derives from those logs.
Each has its trade-offs. Active measurements are targeted and can be controlled. They are also exceptionally difficult (and often costly) to scale and, as a result, are only able to observe the parts of a system where they are deployed. Conversely, passive measurements tend to be lighter weight, but only succeed if the observer is at the right place at the right time.
Effectively, the two methods complement each other, and that makes them most powerful when orchestrated so that the knowledge from one feeds into the other. For example, in our own prior attempts to understand performance across CDNs, we interrogated the (passive) request logs to get insights, which helped inform later (active) pings using RIPE’s Atlas that we used to confirm our insights and results. In the opposite direction, our efforts to (passively) detect and understand connection failures was informed by, and arguably only possible because of, a large body of (active) measurements in the research community to understand wide-scale connection tampering.
For more on the interplay between active and passive, you can read about the experience of a researcher who was equipped to dig deep into Cloudflare’s vast troves of data because of insights from prior active measurements in the research community.
It is possible to gain insights about something without directly observing it. Consider, for example, the capacity of a path, better known as the bandwidth. The common method to directly observe bandwidth is to launch a speed test. It’s a simple test, but it has two problems.
The first is that it works by consuming as much of the bandwidth as it can (which creates an ethical dilemma we later revisit). The second is that it actually measures throughput from a sender to a receiver, which is the available bandwidth (or, alternately, the residual capacity) of the bottleneck link. If two speed tests share a bottleneck then each might observe throughput that is ½ of the actual bandwidth. The evidence is in the numbers, as seen below, where observations of a speed test range from 69-85Mbps — that’s a +/- range of nearly 20% from the median, and far from a fixed value!

There is instead a 25+ year-old indirect alternative to speed tests called the packet pair, or packet train. It works by first transmitting pairs of packets with no delay between them and recording their transmission times, then recording their arrival times. The change between transmission and arrival times of the two packets gives an indication of the bottleneck bandwidth. Repeat the packet pair probes and, with some statistical analysis, a good estimate of the true bottleneck bandwidth emerges. Instead of directly observing bandwidth by pushing and counting bytes over time, the packet pair technique uses the time between two packets to indirectly calculate — or infer — the metric.

Measurements are most powerful when they lead to reasonable predictions. Sometimes the predictions confirm our understanding of the world and systems we deploy into it. Occasionally, the predictions reveal something new. Either way, predictive measurements emerge by following a simple pattern: curate data, construct a model based on the data, then validate the model with (ideally) different data. Together, these create a measurement lifecycle.

Ideally a measurement exercise encompasses the lifecycle from beginning to end, but there can be extremely valuable contributions and advances within each in isolation. Individual high-quality datasets are so difficult to curate that each can be a valid contribution. Similarly, with modeling techniques, or tools for validation. Measurement spans expert domains, and benefits from diverse skill sets.
Let’s look at each step in order, beginning with data curation.
The most common and familiar measurement exercise — often synonymous with measurement — is data gathering and curation. Data on its own can be fascinating and useful; Cloudflare Radar is clear evidence of that! Simple counting in many contexts can help us relate to and place our environments in context.
Data gathering and curation consumes more energy, time, and resources than modeling or validation. The explanation is implied by the cyclical measurement pattern: validation requires a preceding model, and models are constructed using data. No data, no model, no validation, no insight nor prediction nor learning. The quality of each step in the cycle depends on the quality of the previous step — high-quality data is the linchpin in measurement practices. The Large Hadron Collider and the James Webb Telescope are great examples of how much we can, and need, to do — they operate relentlessly in pursuit of high-quality data. Similar “always-on” tools in the Internet measurement community are much less glamorous, but no less important. CAIDA and RIPE’s Atlas are just two examples of longstanding projects that gather telemetry and curate datasets.
Make no mistake: High-quality data gathering and curation is hard.
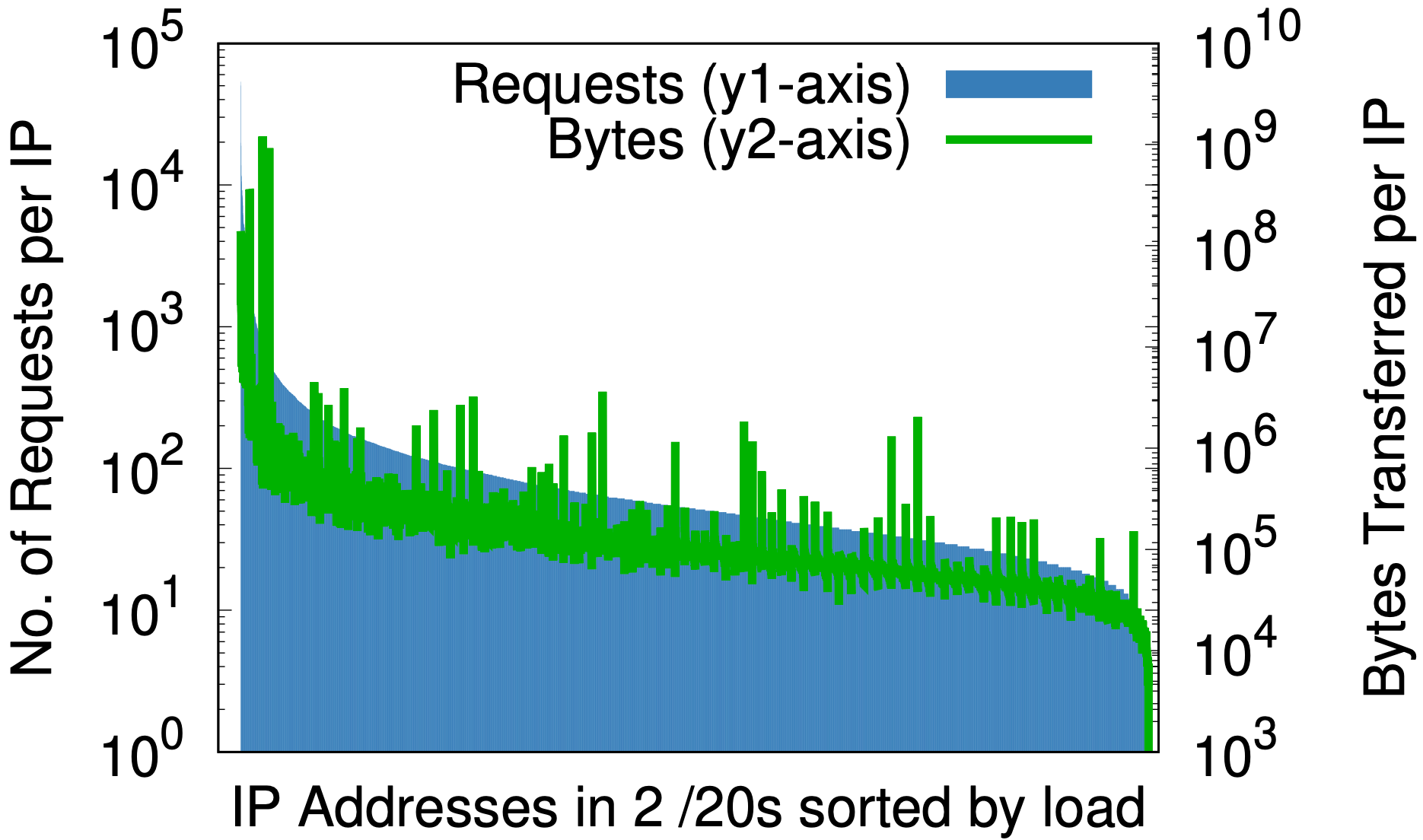
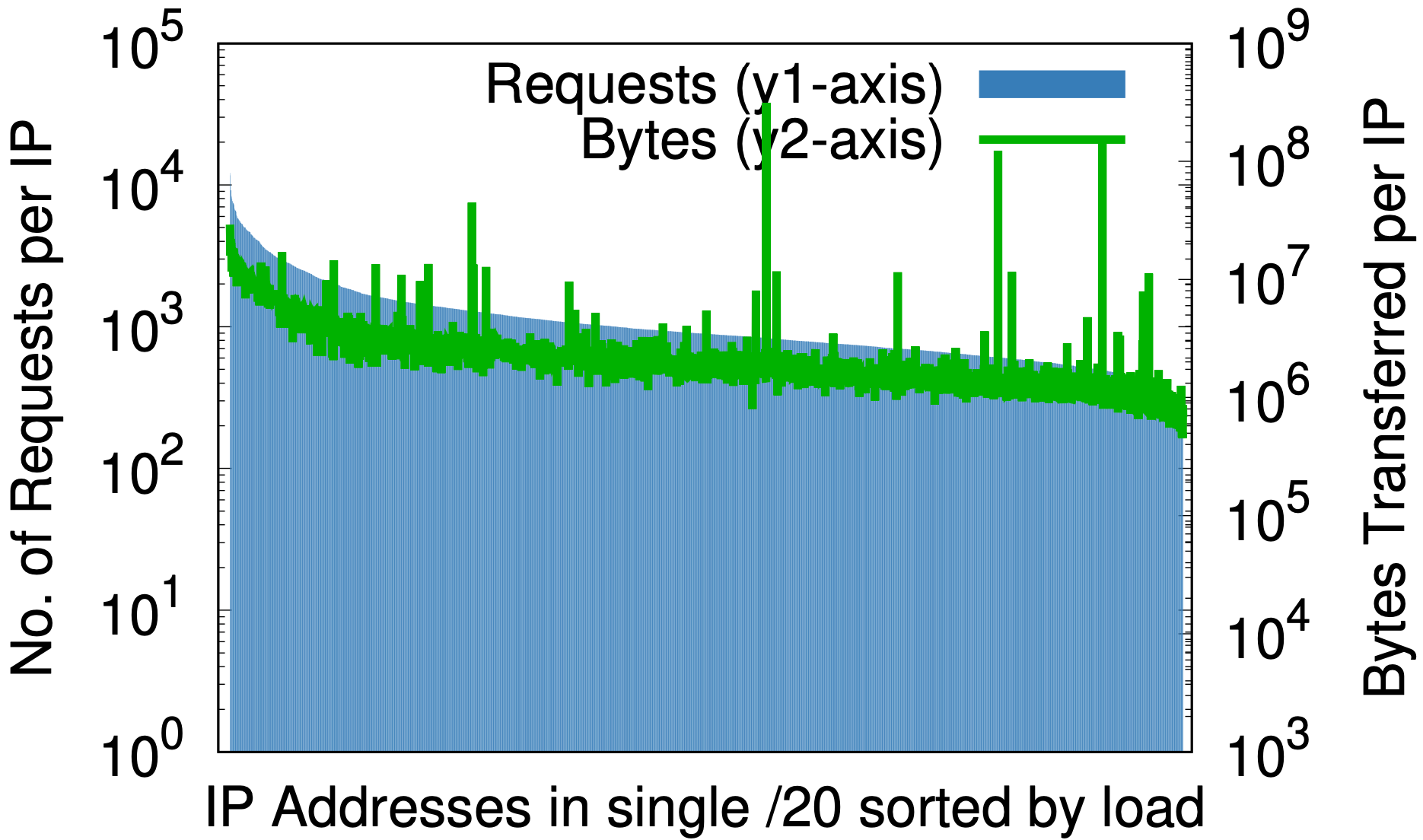
Luckily, “high-quality” does not mean perfect; it does mean representative. For example, if we’re counting distance or time, the accuracy must reflect the true value. Large populations can be reasonably studied using much smaller numbers of samples. For example, our global assessment of connection tampering revealed valuable insights with a sample of 1 in 10,000 (or 0.0001%). The low sampling rate works at Cloudflare in part because of the immense diversity of Cloudflare’s customers, which attracts traffic for all kinds of content and purposes. Later this week, we’ll share in a blog post how imperfect signals used to find a sample of around 180,000 carrier-grade NATs in Cloudflare’s request logs are “good enough” to identify more than 12,000,000 others that cannot be directly observed.
Another important, and arguably counterintuitive, misconception is that more data naturally reveals more detail and answers to more questions. As Ram Sundaran writes in a guest post, sometimes there is so much noise that finding answers in large datasets can seem like a small miracle.
Models may be conceptual, and describe aspects of an environment or system. The most useful can be expressed as simple statements about our understanding or our assumptions. In effect, they encapsulate a hypothesis that can be tested. For example, we might believe or assume that an ISP or network will typically prefer a direct no-cost peering path to a CDN over transit network paths that incur a cost, even when the direct path is longer. This forms a model that can be validated.

Predictive models push beyond our boundaries of understanding to help identify, explain, or understand aspects of systems that are not obvious or directly observable, or are difficult to ascertain. Predictive models often use statistical techniques to, for example, identify underlying stochastic processes or to create machine learning classifiers. A more common use of the statistical tools is to characterize the curated data itself. Remarkably powerful models can be simple probability distributions with means, medians, variance, and confidence indicators.
One aspect of the Internet that attracted a lot of attention was how networks on the Internet choose to connect to other networks. Understanding how the Internet forms and grows is crucial for simulation, but also helps to predict ways in which networks might fail. The equation below on the left comes from the Barabási–Albert (B-A) model, an early model that assumes preferential connectivity or, in more familiar terms, “rich get richer.”
In its simplest version, a new network in the BA model chooses to connect to an existing network with a probability that is proportional to the number of connections of the existing networks. Later models did away with ‘intelligent’ selection mechanisms. The equation below on the right is based on the sizes of networks, a more general mechanism similar to the way celestial bodies form in the universe.

Sometimes knowing which tool to use and when is a skill in itself. One such example is throwing ML and AI at problems that are tractable with mechanisms that are simpler and far more transparent. This guest blog, for example, explains that ML was ruled out to understand anomalous TCP behaviour because TCP is tightly specified, which suggested that a full enumeration of various packet sequences was possible—and proved correct.
An understanding of the domain is often critical to our ability to construct accurate models. Machine learning, for example, is a useful tool to help make sense of large unstructured data, but can be remarkably powerful with some domain expertise. Our work featured later this week on detection of multi-user IPs provides one such example. In particular, we sought to detect carrier-grade NAT devices (CGNATs). They are unique among large-scale multiuser IPs because, unlike VPNs and proxies, users neither choose to use CGNATs nor are aware of their existence.
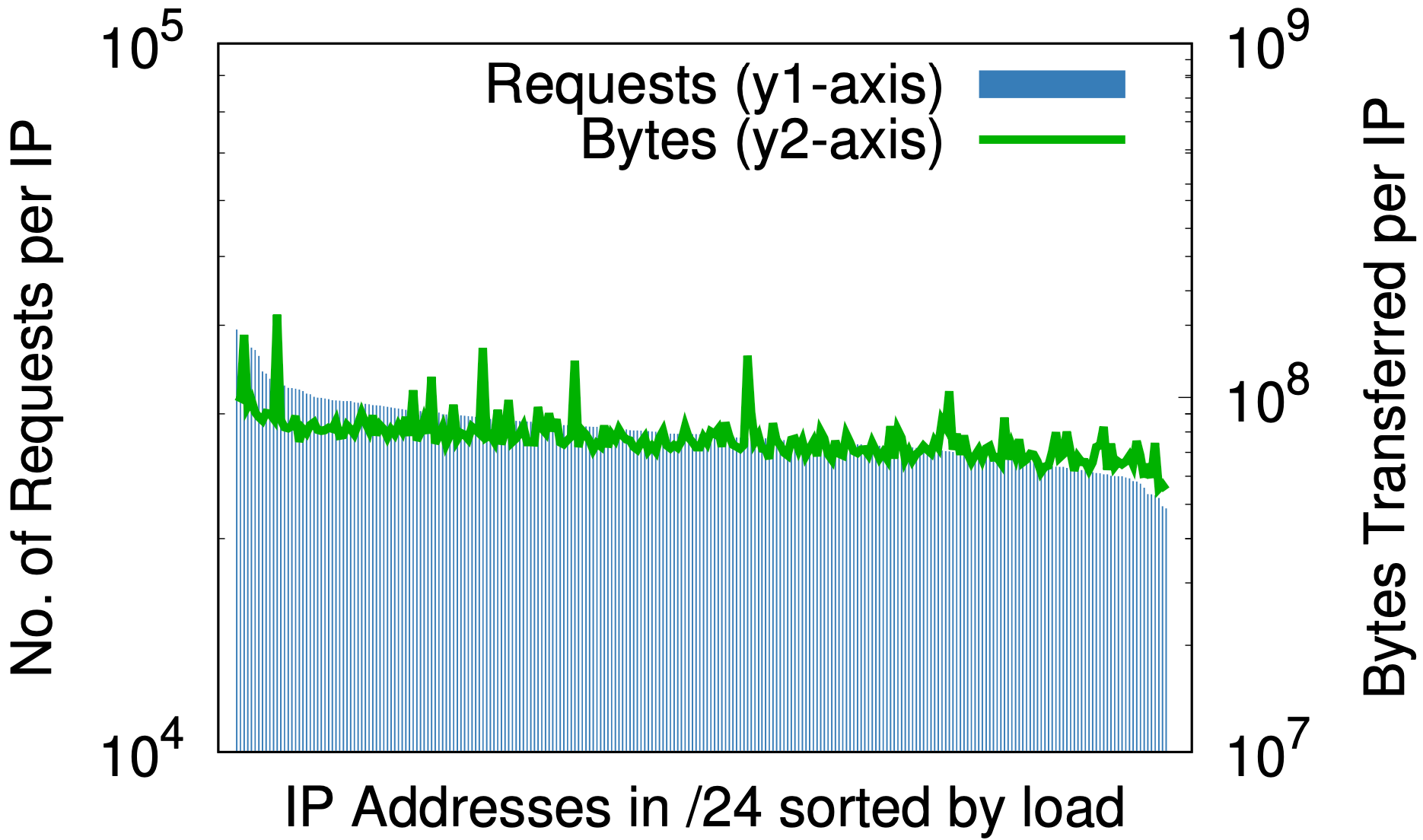
The ML models successfully identified multiuser IPs, but disambiguating CGNATs proved elusive until we applied domain knowledge. For example, CGNATs are typically deployed across a range of contiguous IPs (e.g. in a /24 block) and, as shown below, turns out to be a very important feature in the model.

The validation phase almost singularly determines the value of the whole measurement exercise, by testing the output of the model against data. If the model makes predictions that are reflected in the data, then the model has validity. Predictions that contrast or conflict with the validation data indicate that either the model is flawed or is biased by the curated data.
Validation is where great measurement can fall apart — primarily in one of two ways. First, just like in the initial data curation phase, validation data must be representative of the population. For example, it would be a mistake to curate data about traffic during the day, build a model about that data, and then validate using data about traffic at night. There is also no point in using QUIC data to validate measurements about, say, TCP (unless the measurement’s hypothesis is that they have attributes in common). Care must always be taken to ensure that measurement cannot be corrupted by the differences between validation and initial data.
Validation also risks being misleading when using the curated data, directly. Certainly this approach mitigates differences between datasets. However, the only conclusion that can be drawn when validating with the same data, is that the model reasonably describes the data —not whatever the data represents. Consider, for example, machine learning. At its core, machine learning is a measurement in so much as it follows the lifecycle: curate data, (feed it into a machine learning algorithm to) build a model, then validate the output against data. An early common practice in the machine learning community was to partition a single dataset into 70% for training and 30% for validation. This is a setup that leads to a higher likelihood of a positive evaluation of the model that is not warranted, and potentially misleading. The best case for an ML model trained on a dataset that amplifies or omits important characteristics is a model that reflects those biases — which becomes a potential source of algorithmic bias.
Naturally we have greater confidence in models that prove valid with unrelated data. The validation dataset can describe the same attributes from a different source, for example, models constructed from passive RTT log data and validated against active pings. Alternatively, models may be validated using entirely different data or signals, such as confirming connection tampering with distributions and header values that were ignored in the model’s construction.
The importance of ethics in network measurement is hard to overstate. It’s easy to perceive network measurement as risk-free, removed from and having little effect on humans—a perception far from truth. Recall the speed tests and the packet pair technique for bandwidth estimation described above. In a speed test, an actor estimates bandwidth by consuming all the available bottleneck capacity that may or may not be within the actor’s network. The cost of resource consumption might be borne by others, and certainly reduces the potential performance of the network for its users. The risks of that type of bandwidth measurement prompted the packet pair technique and its use of only a few pairs of packets and a little math to infer bandwidth—albeit with some orchestration between a sender and receiver.
Best practice in network measurement scrutinizes risks and effects before the measurement exercise. This might seem like a burden, but the ethical considerations often spark creativity and are the reasons that novel methodology emerge. Looking for alternatives to JavaScript injection is what prompted Cloudflare’s own efforts to estimate the performance of other CDNs using passive data. For more information, see “Ethical Considerations in Network Measurement Papers” published in the Communications of the ACM (2016).
Visualization and representation are invaluable at every stage of the measurement lifecycle. Representations should at least improve our understanding; ideally, they also make follow-up actions clear. Statements without context are poor representations. For example, “30% greater chance” sounds like a lot but has no value without a reference point—30% of 0.5% is likely less a concern than 30% of 20% chance.
One example of representation is Cloudflare’s “closeness” statement: Cloudflare is “approximately 50 ms from 95% of the Internet-connected population globally.” The statement encapsulates a “survey” of our logs: From among all connections from each IP address that connects to Cloudflare, half of the minimum-RTT is a “worst approximation” of the latency from the IP address to Cloudflare; in 95% of cases, the minRTT/2 is at or below 50ms.
Visualizations, meanwhile, can be so powerful as to lead to misleading conclusions — a notion that features prominently later this week in a blog post about routing resilience evaluations. One example on that subject appears below, with two bar charts that order individual US states by the number of interconnection facilities in each state, from most to least. On the left, states are ordered according to raw count facilities; the top-ranked state has more than 140 interconnection facilities. On the right, the raw counts are normalized (in this case divided by) the population of each state.

These representations demonstrate that our models are shaped, and can be misinformed, by how we evaluate data. In this case we have purposefully omitted the state names on the x-axis because they are a distraction. Instead, each bar is coloured to indicate whether it is above (green) or below (yellow) the median of facilities per person in the right-hand graph. What becomes immediately obvious is that the two states with the highest number of facilities fall below the median, i.e., they are in the bottom half of states when ordered by facilities per person.
Sometimes a visualization can be so powerful as to leave no doubt. The image below is a personal favourite, because it gives strong evidence that the data and models were correct. In this visualization, each column represents a single type of connection anomaly that we observed. Inside each column, the anomaly’s occurrence is divided proportionally into the country where the connection was initiated. As an example, look at the left-most column for SYN→∅ anomalies (a type of timeout). It shows that connections from China, India, Iran, and the United States dominated this specific anomaly type. Organizing the visualization this way put the data first, which helped mitigate any bias we might have had about explanations, underlying mechanisms, or locations.

By organizing the anomalies this way, the visualization immediately answered one question: “Are the failures expected behaviour?” If they were expected, or normal across the Internet, then the anomalies would appear in roughly similar proportions rather than so different. The visualization was a strong validation (but not the only one) of our approach and intuition—and opened up further avenues of investigation as a result.
Cloudflare continues to think deeply about new and novel ways to use available (passive) data, and welcomes ideas. Measurement helps us understand the Internet we all depend on, value, and love, and is a community-wide endeavour.
We encourage new entrants into the measurement space, and hope this blog serves as both an introduction to its challenges, and a map with which to evaluate measurement work published at Cloudflare or anywhere else.