Post Syndicated from Mitesh Patel original https://aws.amazon.com/blogs/big-data/guide-to-adopting-amazon-sagemaker-unified-studio-from-atpcos-journey/
This blog post is co-written with Raj Samineni from ATPCO.
Launched at AWS re:Invent 2024, the next generation of Amazon SageMaker is expediting innovation for organizations such as ATPCO through a unified data management and tooling experience for analytics and AI use cases. This comprehensive service provides both technical and business users with Amazon SageMaker Unified Studio, a single data and AI development environment to discover the data and put it to work using familiar AWS tools. SageMaker Unified Studio offers a single governed environment to complete end-to-end development workflows, including data analysis, data processing, model training, generative AI application building, and more. It simplifies the creation of analytics and AI applications, fast-tracking the journey from raw data to actionable insights through its integrated data and tooling environment.
ATPCO is the backbone of modern airline retailing, helping airlines and third-party channels deliver the right offers to customers at the right time. ATPCO’s vision is to be the platform driving innovation in airline retailing while remaining a trusted partner to the airline ecosystem. ATPCO aims to support data-driven decision-making by making high-quality data discoverable by every business unit, with the appropriate governance on who can access what, and required tooling to support their needs. ATPCO addressed data governance challenges using Amazon DataZone. SageMaker Unified Studio, built on the same architecture as Amazon DataZone, offers additional capabilities, so users can complete various tasks such as building data pipelines using AWS Glue and Amazon EMR, or conducting analyses using Amazon Athena and Amazon Redshift query editor across diverse datasets, all within a single, unified environment.
In this post, we walk you through the challenges ATPCO addresses for their business using SageMaker Unified Studio. We start with the admin flow, a one-time setup process that lays the foundation for non-admin users in preparation for a company-wide rollout. When onboarding users from different business units to SageMaker Unified Studio, it’s crucial to make sure they have immediate access to their data sources such as Amazon Simple Storage Service (Amazon S3), AWS Glue Data Catalog, and Redshift tables as well as tools like Amazon EMR, AWS Glue, and Amazon Redshift that they already use. This helps users become productive swiftly and use the full potential of SageMaker Unified Studio. Next, we walk you through the developer flow, detailing how non-admin users can use SageMaker Unified Studio to access their data and act on it using their choice of tools.
“SageMaker Unified Studio has transformed how our teams access and collaborate on data. It’s the first time business and technical users can work together in a single, intuitive environment—no more tool switching or fragmented workflows.”
–Rajesh Samineni, Director of Data Engineering at ATPCO
ATPCO’s challenges
The implementation of SageMaker Unified Studio at ATPCO has been instrumental in addressing several critical challenges and unlocking new use cases across various business units within the organization. By building on the foundation laid by Amazon DataZone, ATPCO is helping users self-serve insights and fostering a culture of shared understanding and reusability of data assets, leading to more informed decision-making and a robust data culture.
SageMaker Unified Studio helped address the following challenges:
- Data silos and discoverability – Analysts often struggled to locate the right data sources, verify data freshness, and maintain consistent definitions across different departments. By offering a single entry point for searching and subscribing to curated datasets, SageMaker Unified Studio minimizes these barriers. Integrated tools for data exploration, querying, and visualization, along with contextual metadata and lineage, builds trust in the data, making it straightforward for users to find and use the information they need.
- Manual data handling – Teams relied heavily on manual exports and custom reports to gather insights, leading to inefficiencies and delays in decision-making. SageMaker Unified Studio helps users across departments, including product, sales, operations, and analytics, self-serve insights without manual intervention. This accelerates the decision-making process and helps teams focus on strategic initiatives rather than data collection.
Solution overview
The following diagram illustrates ATPCO’s architecture for SageMaker Unified Studio.
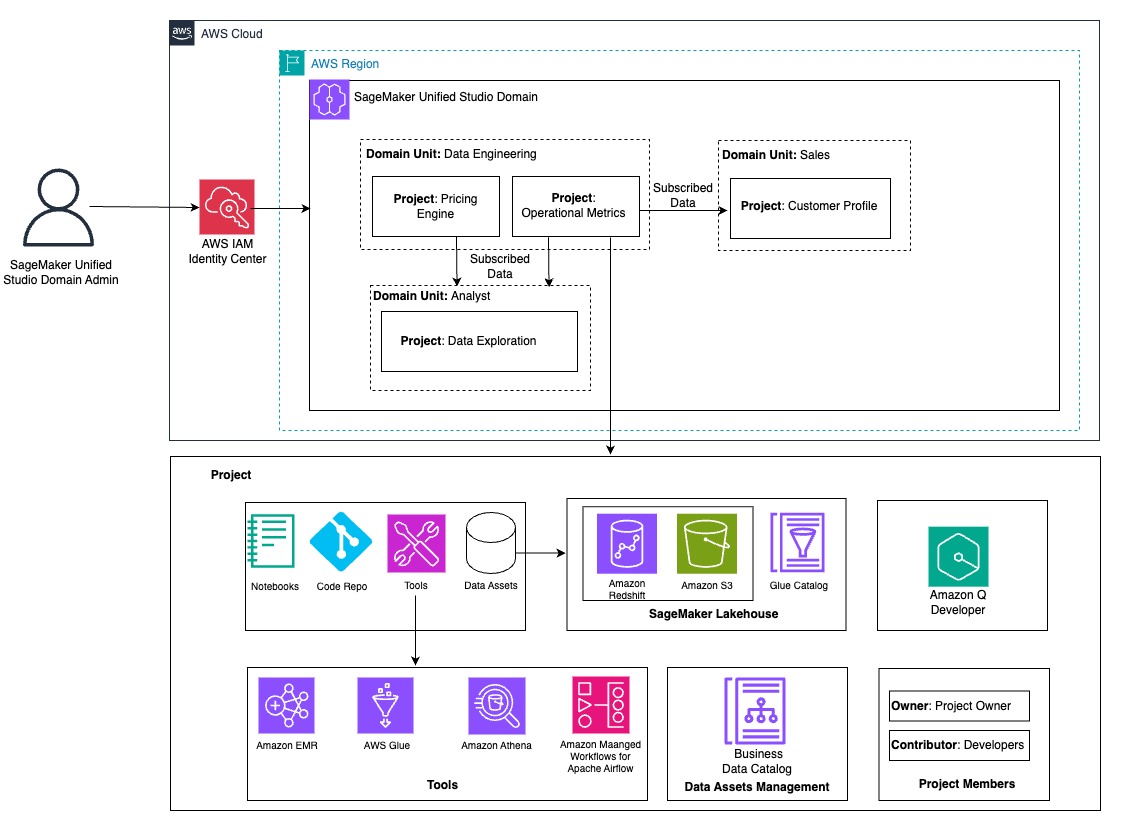
The following sections walk you through the steps that ATPCO went through to prepare the SageMaker Unified Studio environment for use by different personas in engineering and business units.
Prerequisites
If you’re new to SageMaker Unified Studio, you should first become familiar with concepts such as domains, domain units, projects, project profiles, blueprints, lakehouses, and catalogs before continuing with this post. For a company-wide rollout of SageMaker Unified Studio, it’s important to understand the foundation setup required as an admin user. For more information about the role of a SageMaker Unified Studio admin user and steps required to set up a SageMaker Unified Studio domain,refer to Foundational blocks of Amazon SageMaker Unified Studio: An admin’s guide to implement unified access to all your data, analytics, andAI. As an admin user, start with domain units and projects based on the need of different business units for the data and tooling.
Create domain units and set up projects with required tools
As an admin or root domain owner, you begin with the design of domain units and projects to organize different teams and users to their respective domain units. When non-admin users log in to the SageMaker Unified Studio portal, they should have seamless access to necessary AWS resources. These resources include the required tools and data sources to perform their job. Providing users access to these resources is critical for the successful adoption and utilization of SageMaker Unified Studio in your organization. ATPCO created separate domain units for engineering teams and non-engineering business units, as shown in the preceding architecture diagram. It only shows few examples. In reality, they have more domain units to meet their business needs, which we discuss in the following sections.
Data engineering domain
This domain unit has the Operational Metrics project, managed by the data engineering team, which supports a key backbone of visibility across the organization: understanding how ATPCO’s products perform in real time. Data engineers bring together signals from infrastructure, application logs, API monitoring, and internal systems to build aggregated, curated datasets that track latency, availability, adoption, and reliability. These operational metrics are published using SageMaker Unified Studio for consumption by other domains. Rather than fielding one-off requests or maintaining bespoke dashboards for different stakeholders, the engineering team now:
- Builds reusable data assets that can be subscribed to one time and reused by many
- Creates unified views of system health that are automatically updated and versioned
- Supports other teams such as Product, Sales, and analysts with quick access to performance indicators in a format aligned with their needs
SageMaker Unified Studio becomes the center for operational intelligence, reducing duplication and making sure data engineers can focus on scale and automation rather than ticket-based support.
Analyst domain
The Data Exploration project in this domain unit serves the entire ATPCO community. Its purpose is to make available datasets regardless of their owning domain easily discoverable and ready for analysis. Previously, analysts struggled with locating the right data source, verifying its freshness, or aligning on consistent definitions. With SageMaker Unified Studio, those barriers are removed. The project provides:
- A single entry point where users can search and subscribe to curated datasets
- Integrated tools for exploration, query, and visualization
- Contextual metadata and lineage to build trust in the data
Users in product, strategy, operations, or analytics can self-serve insights without waiting on manual exports or custom reports.
Sales domain
The Customer Profile project in this domain unit helps the Sales team understand which customers are actively engaging with ATPCO’s products, how they are using them, and where there might be opportunities to strengthen relationships. By using SageMaker Unified Studio, Sales team members can access the following:
- Customer data sourced from CRM systems, including interaction history, product adoption, and support engagement
- Operational metrics from the Data Engineering team, revealing which features are being used, how often, and whether the customer is experiencing reliability issues
With this combined insight, the Sales team can accomplish the following:
- Identify high-value accounts for follow-up based on recent usage
- Detect drop-off in engagement or technical issues before a customer raises a concern
- Tailor outreach and proposals using objective data, not assumptions
All of this happens within SageMaker Unified Studio, reducing the time spent on manual data gathering and enabling more strategic, proactive customer engagement.
Onboard data sources to domain units and projects
Now that domain units and projects are created for different business units, the next step is to onboard existing Amazon S3 data sources, Data Catalog tables, and database tables available in Amazon Redshift. After logging in, users have access to the required data and tools. This required the ATPCO team to build the inventory to see which team has access to what data sources and what level of permissions are needed. For example, the Data Engineering team needs access to raw, processed and curated S3 buckets for building data processing jobs. They must also read and write to the Data Catalog, and prepare and write curated and aggregated data to the Redshift tables. The following sections guide you through configuring these various data sources within SageMaker Unified Studio, making sure users can access the data sources to continue their work in SageMaker Unified Studio.
Configure existing Amazon S3 data sources into SageMaker Unified Studio
To use an existing S3 bucket in SageMaker Unified Studio, configure an S3 bucket policy that allows the appropriate actions for the project AWS Identity and Access Management (IAM) role.
The Data Engineering team that owns the data processing pipeline must grant access to raw, processed, and curated S3 buckets to the data engineering project role. To learn more about using existing S3 buckets, refer to Access your existing data and resources through Amazon SageMaker Unified Studio, Part 2: Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
Configure an existing Data Catalog into SageMaker Unified Studio
The next generation of SageMaker is built on a lakehouse architecture, which streamlines cataloging and managing permissions on data from multiple sources. Built on the Data Catalog and AWS Lake Formation, it organizes data through catalogs that can be accessed through an open, Apache Iceberg REST API to help enforce secure access to data with consistent, fine-grained access controls. SageMaker Lakehouse organizes data access through two types of catalogs: federated catalogs andmanaged catalogs (shown in the following figure). A catalog is a logical container that organizes objects from a data store, such as schemas, tables, views, or materialized views from Amazon Redshift. The following diagram illustrates this architecture.
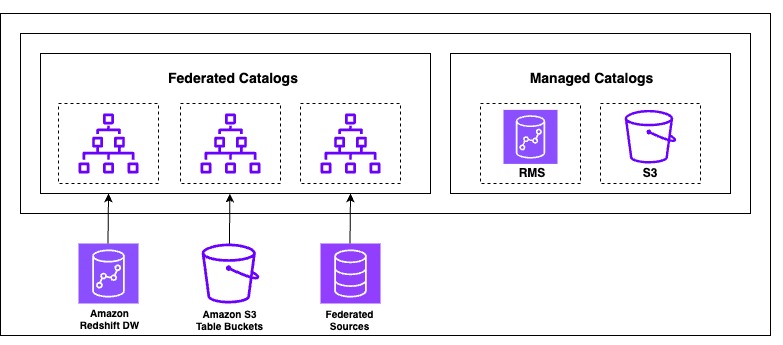
ATPCO built a data lake on Amazon S3 using the Data Catalog and implemented data governance and fine-grained access control using Lake Formation. When developer users log in to SageMaker Unified Studio, they need access to the Data Catalog tables owned by their respective team. Existing Data Catalog databases are made available in SageMaker Lakehouse as a federated catalog because they’re created outside of SageMaker Lakehouse and not managed by it.
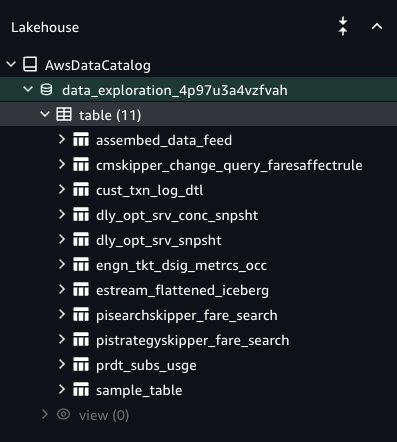
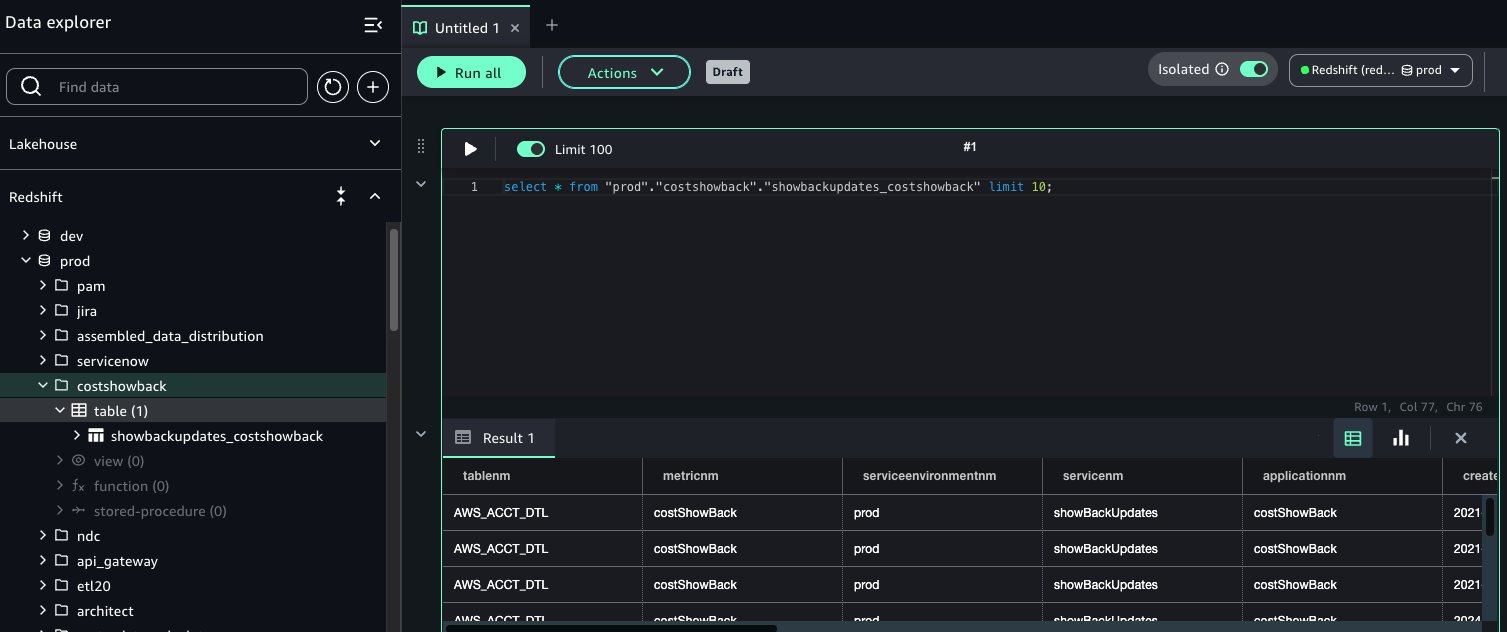
To access an existing Data Catalog, you must provide explicit permissions to SageMaker Unified Studio to be able to access the Data Catalog databases and tables. For more details, see Configure Lake Formation permissions for Amazon SageMaker Unified Studio. To onboard Data Catalog tables to SageMaker Lakehouse in SageMaker Unified Studio, the Lake Formation admin must grant access to specific Data Catalog database tables to the SageMaker Unified Studio project role. For more details, refer to Access your existing data and resources through Amazon SageMaker Unified Studio, Part 1: AWS Glue Data Catalog and Amazon Redshift. The Lake Formation permission model is the prerequisite to grant access to SageMaker Unified Studio. If Lake Formation is not the permission model for the Data Catalog, then you must register the S3 path and delegate the permission model to Lake Formation before it can be granted to the SageMaker Unified Studio project role. After you complete these steps, users of the project can access the Data Catalog database and are granted tables under the AwsDataCatalog namespace, and your tables will be visible in the Data Explorer (see the following screenshot). Your data is now ready for tagging, searching, enrichment, and data analysis.
Configure Redshift data into SageMaker Unified Studio
ATPCO relies on Amazon Redshift as their enterprise data warehouse and stores their aggregated data for insights and dashboarding. Users can combine the data from Amazon Redshift and SageMaker Lakehouse for unified data analysis in SageMaker Unified Studio without leaving SageMaker Unified Studio. For more information about how to add existing Redshift data sources, refer to Access your existing data and resources through Amazon SageMaker Unified Studio, Part 1: AWS Glue Data Catalog and Amazon Redshift.
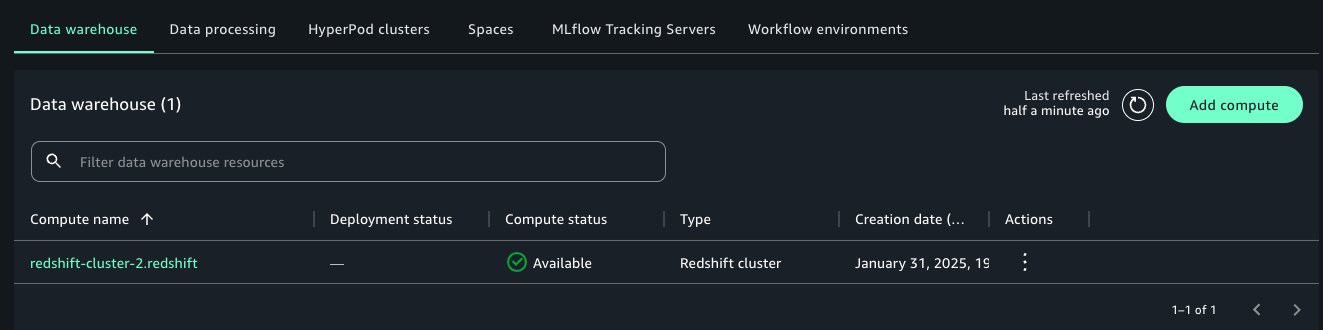
After it’s connected, the Amazon Redshift compute engine becomes visible in the Data Explorer of your project. Project users can perform the following actions:
- Write and run SQL queries directly against Amazon Redshift
- Explore Redshift schemas and tables
- Use Redshift tables to define SageMaker Unified Studio data sources
- Combine Redshift data with metadata tagging, glossary linking, and publishing
This doesn’t require copying or duplicating data. You’re using the data exactly where it lives in your Redshift cluster while benefiting from the collaborative features of SageMaker Unified Studio. Adding compute makes the data within the warehouse available to query inside the SageMaker Unified Studio query editor.
Onboard users to their respective domain units and projects
Now that as an admin you have created the environments for different business units, your next step is to add domain owner users to the respective domain units. First, you must add domain and project owners’ users for them to get access to the SageMaker Unified Studio domain portal.
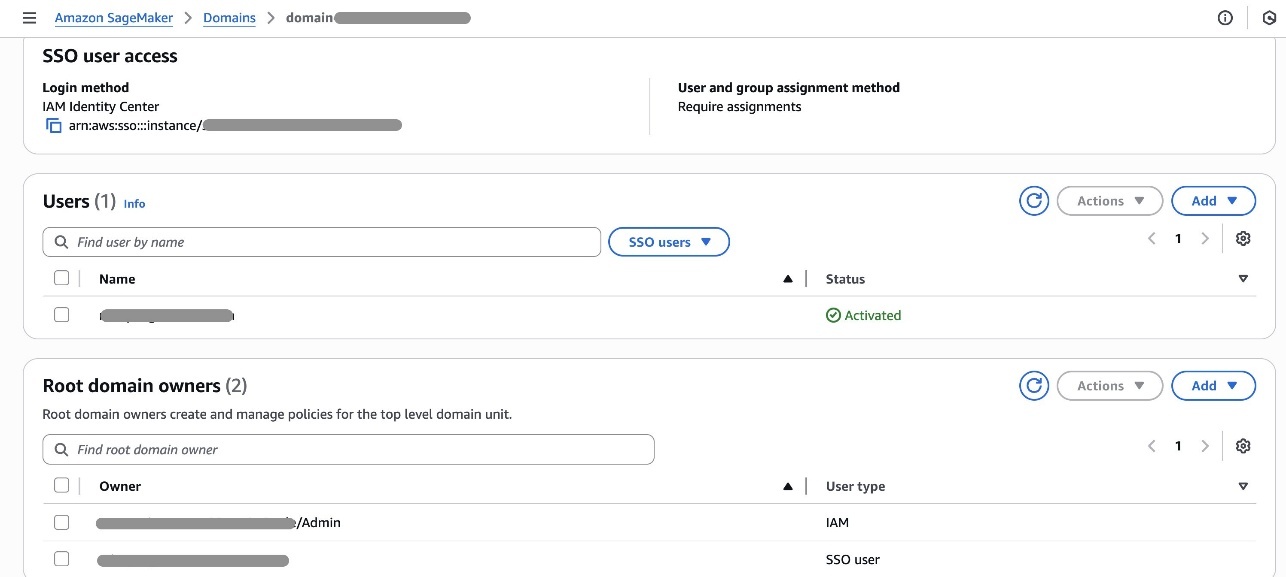
Domain units make it possible to organize your assets and other domain entities under specific business units and teams. Domain unit owners can create policies such as membership, domain, and project creation.
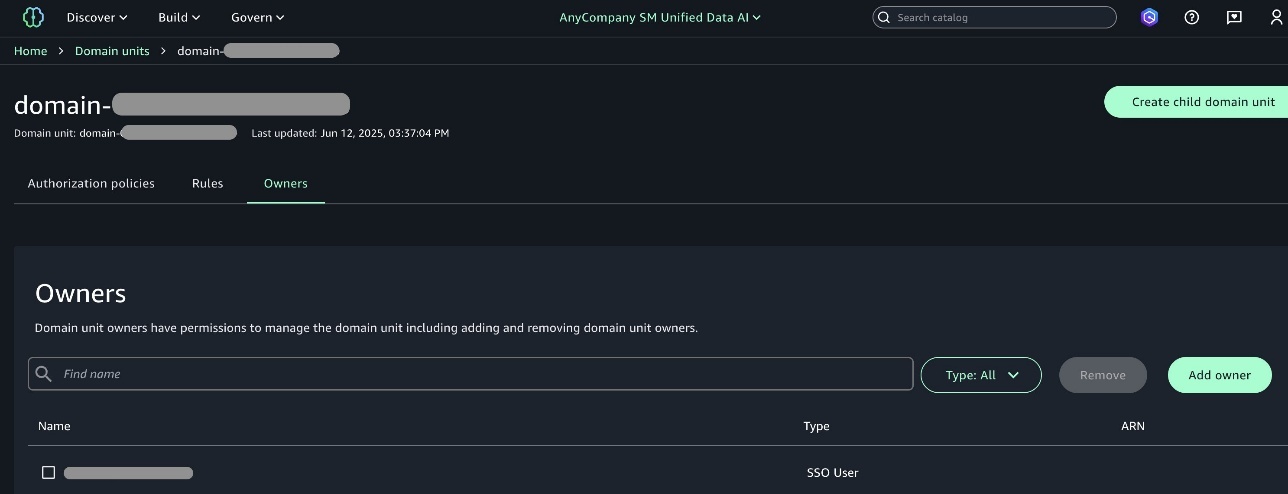
Domain unit owners can add one of the members as owner of the project so that when the owner user logs in, they can add other users of their team as an owner or contributor to the project. This helps other users get access to the projects when they login to SageMaker Unified Studio.
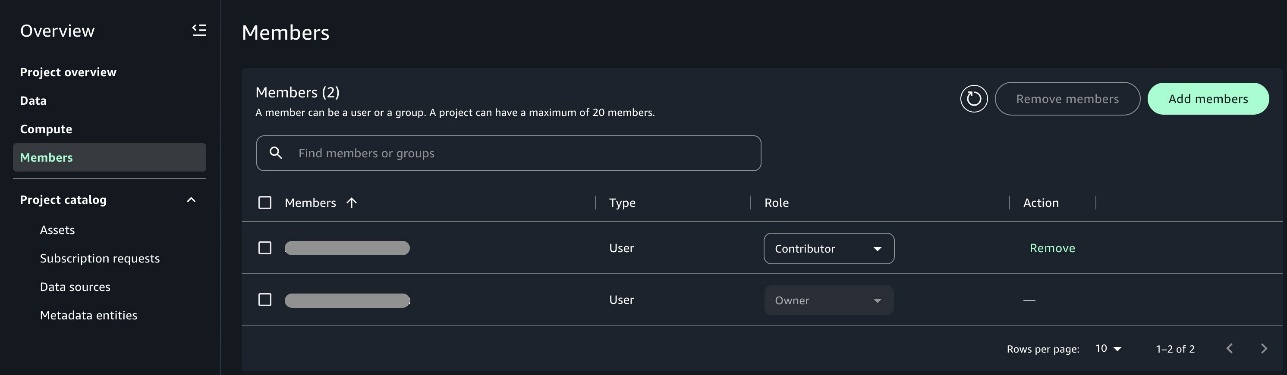
Use the SageMaker Unified Studio environment
After the admin completes the required setup for different business units and onboardsproject members, users can log in to the portal and start using the preconfigured SageMaker Unified Studio environment. Users have access to respective data sources and tools as shown in the following developer flow diagram.
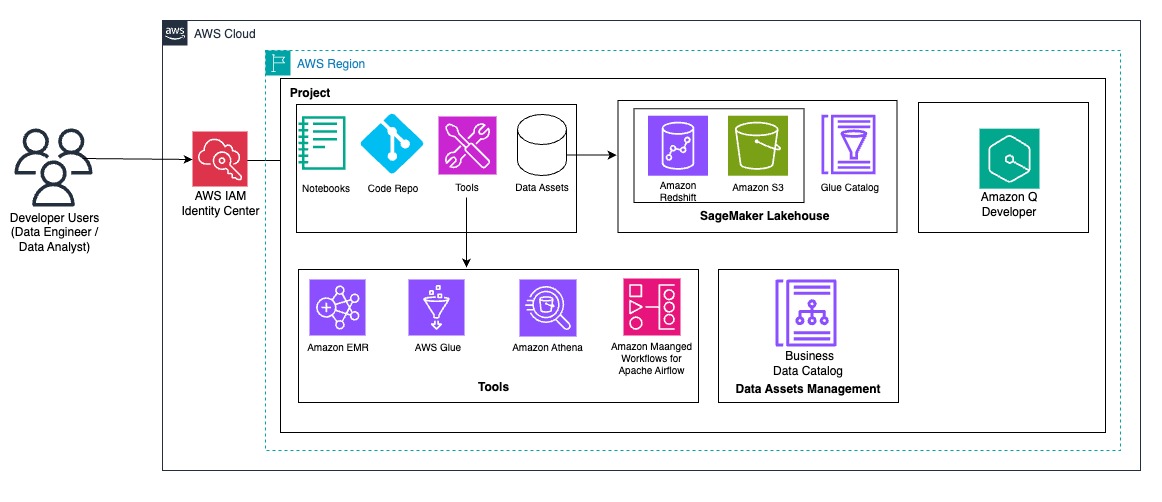
At ATPCO, developers must often combine data from various sources to perform extract, transform, and load (ETL) processes efficiently. In this section, we demonstrate how developers can benefit from the SageMaker unified lakehouse environment by seamlessly integrating data from both Amazon Redshift and the Data Catalog. Using PySpark within SageMaker Unified Studio notebooks, we read transactional data from Amazon Redshift and enrich it with metadata stored in AWS Glue backed S3 tables such as warehouse or product attributes. This integrated view supports complex transformations and aggregations across disparate sources without needing to move or duplicate data. By using native connectors and Spark’s distributed processing, users can join, filter, and analyze multi-source datasets efficiently and write the results back to Amazon Redshift for downstream analytics or dashboarding, all within a single, interactive lakehouse interface.
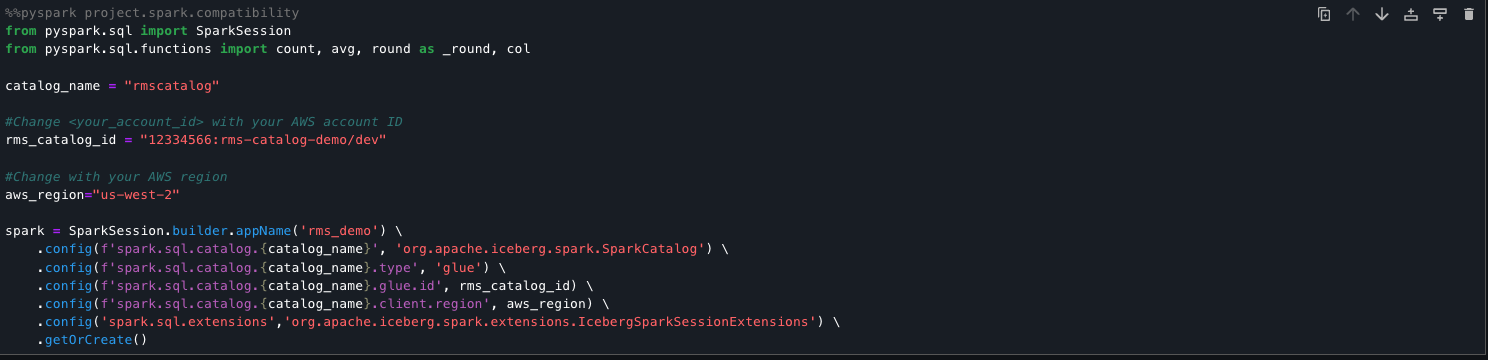
The following code snippet sets up a Spark session to directly query Amazon Redshift managed storage tables using the lakehouse architecture. It registers an AWS Glue backed Iceberg catalog (rmscatalog) that points to a specific Redshift lakehouse catalog and database, allowing Spark to read from and write to Redshift Iceberg tables. By enabling Iceberg extensions and linking the catalog to AWS Glue and Lake Formation, this setup provides seamless, scalable access to Amazon Redshift managed data using standard Spark SQL.
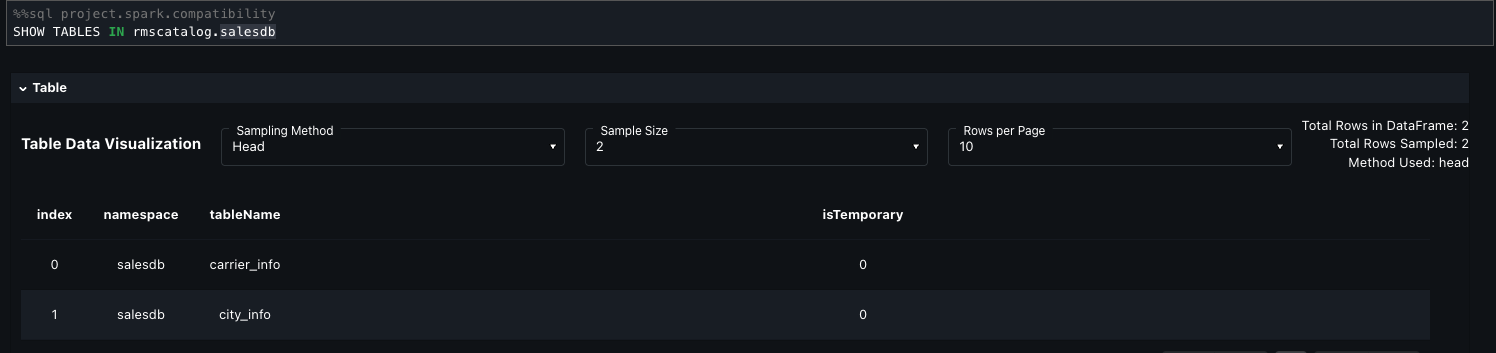
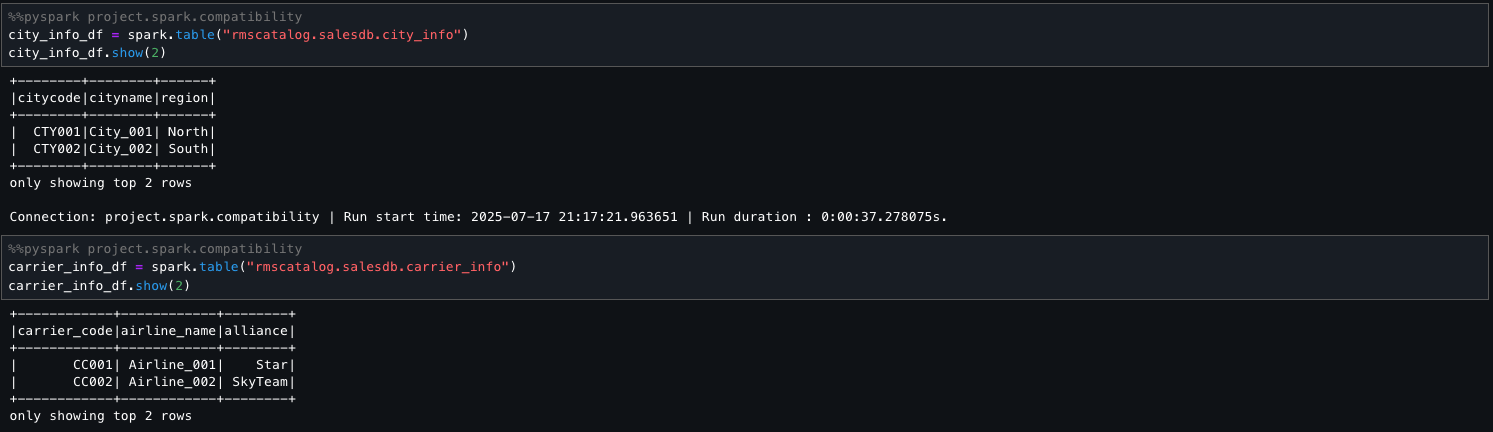
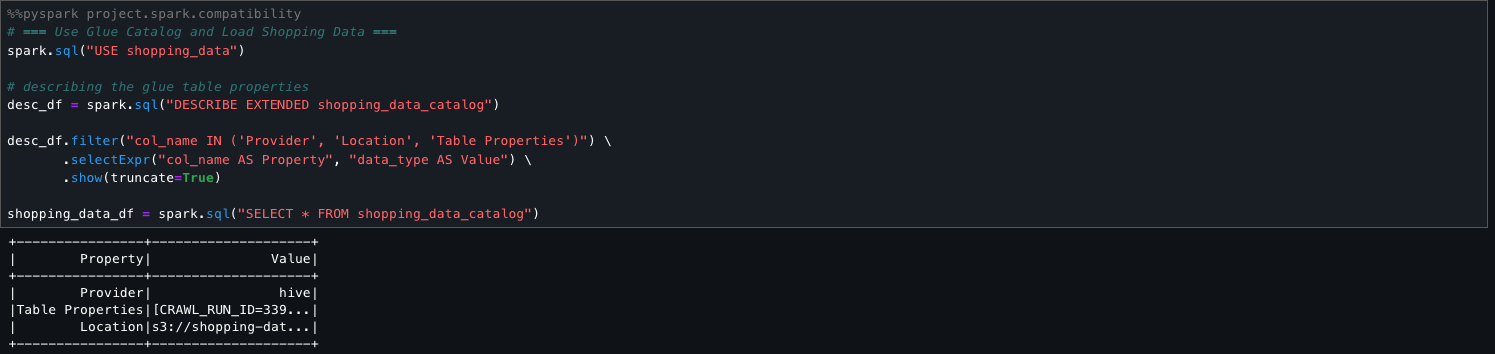
The following step sets the active AWS Glue database to shopping_data and retrieves metadata for the shopping_data_catalog table using DESCRIBE EXTENDED. It filters for key properties like Provider, Location, and Table Properties to understand the table’s storage and configuration. Finally, it loads the entire table into a Spark DataFrame (shopping_data_df) for downstream processing.
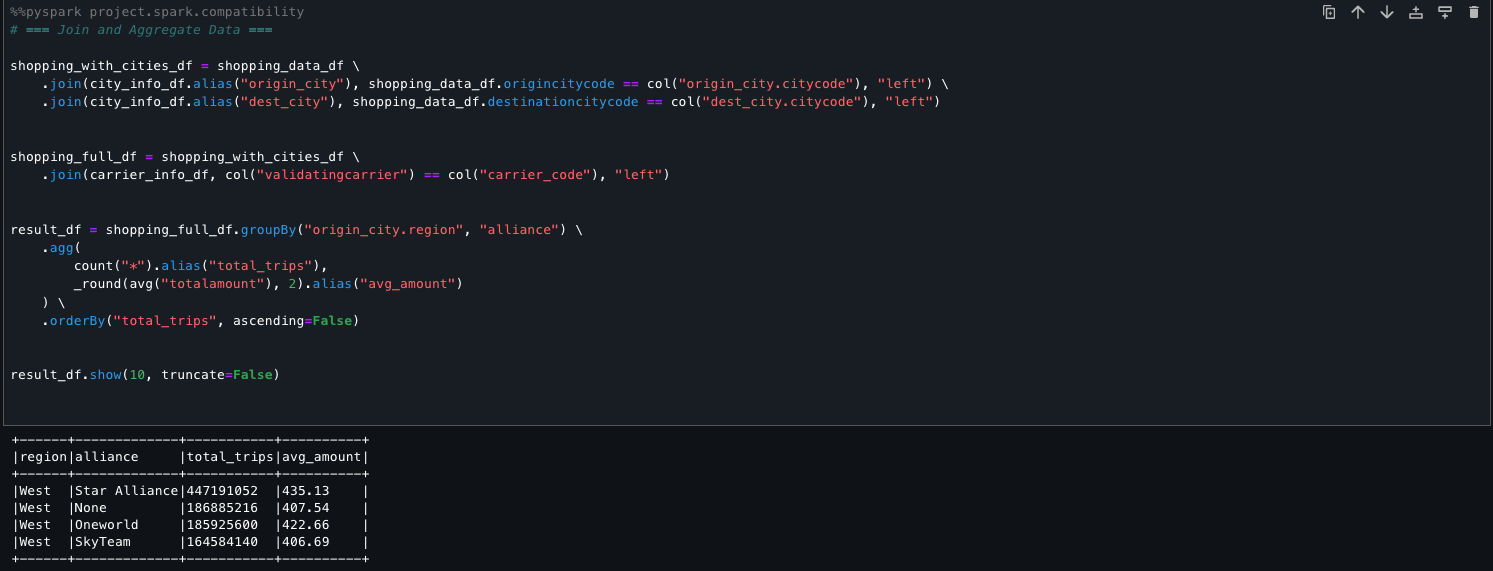
The following code shows how you can seamlessly combine and aggregate two disparate data sources, Amazon Redshift and the Data Catalog, within SageMaker Unified Studio. Using PySpark, we perform transformations and derive meaningful summaries across the unified view. This facilitates streamlined analysis and reporting without the need for complex data movement or duplication.
After the job runs, it writes the transformed dataset directly into a Data Catalog table that is Iceberg-compatible. This integration makes sure the data is stored in Amazon S3 with ACID transaction support, and also registered and tracked in the Data Catalog for unified governance, schema discovery, and downstream query access. The Iceberg table format organizes the data into Parquet files under a data/ directory and maintains rich versioned metadata in a metadata/ folder, supporting features like schema evolution, time travel, and partition pruning. This design facilitates scalable, reliable, and SQL-compatible analytics on modern data lakes.

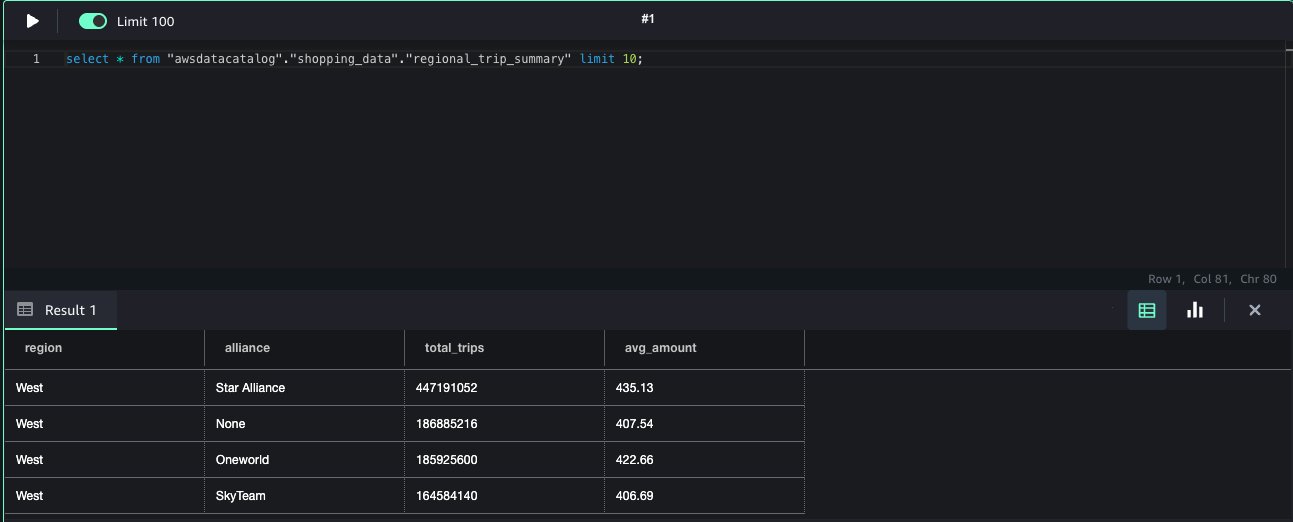
The table becomes immediately available for querying through the Athena query editor, providing interactive access to fresh, transactional data without additional ingestion steps or manual registration.This approach streamlines the end-to-end data flow, from processing in Spark to interactive querying in Athena within the modern SageMaker Lakehouse environment.
Conclusion
This post walked you through the steps to prepare a SageMaker Unified Studio environment for a company-wide rollout, using APTCO’s journey as an example. We covered the domain design and admin flow, which is a one-time setup to prepare the SageMaker Unified Studio environment for different teams in the organization who requires different levels of access to the data and tools. After the admin flow, we demonstrated the developer flow and how to use tools like a Jupyter notebook and SQL editor to use the data across different sources such as Amazon S3, the Data Catalog, and Redshift assets to perform a unified analysis.
Try out this solution and get started with SageMaker Unified Studio and modernize with the next generation of SageMaker. To learn more about SageMaker Unified Studio and how to get started, refer to the Amazon SageMaker Unified Studio Administrator Guide, and the latest AWS Big Data Blog posts.
About the authors
 Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS.
Mitesh Patel is a Principal Solutions Architect at AWS. His passion is helping customers harness the power of Analytics, Machine Learning, AI & GenAI to drive business growth. He engages with customers to create innovative solutions on AWS.
 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
 Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
Raj Samineni is the Director of Data Engineering at ATPCO, leading the creation of advanced cloud-based data platforms. His work ensures robust, scalable solutions that support the airline industry’s strategic transformational objectives. By leveraging machine learning and AI, Raj drives innovation and data culture, positioning ATPCO at the forefront of technological advancement.
 Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.
Saurabh Rawat is a Solution Architect at AWS with 13 years of experience working with enterprise data systems. He has designed and delivered large-scale, cloud-native solutions for customers across industries, with a focus on data engineering, analytics, and well-architected architectures. Over his career, he has helped organizations modernize their data platforms, optimize for performance, and cost, and adopt best practices for scalability and security. Outside of work, he is a passionate musician and enjoys playing with his band.





















 Mitesh Patel is a Principal Solutions Architect at AWS with specialization in data analytics and machine learning. He is passionate about helping customers building scalable, secure and cost effective cloud native solutions in AWS to drive the business growth. He lives in DC Metro area with his wife and two kids.
Mitesh Patel is a Principal Solutions Architect at AWS with specialization in data analytics and machine learning. He is passionate about helping customers building scalable, secure and cost effective cloud native solutions in AWS to drive the business growth. He lives in DC Metro area with his wife and two kids. Sumitha AP is a Sr. Solutions Architect at AWS. She works with customers and help them attain their business objectives by designing secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS.
Sumitha AP is a Sr. Solutions Architect at AWS. She works with customers and help them attain their business objectives by designing secure, scalable, reliable, and cost-effective solutions in the AWS Cloud. She has a focus on data and analytics and provides guidance on building analytics solutions on AWS. Deepti Venuturumilli is a Sr. Solutions Architect in AWS. She works with commercial segment customers and AWS partners to accelerate customers’ business outcomes by providing expertise in AWS services and modernize their workloads. She focuses on data analytics workloads and setting up modern data strategy on AWS.
Deepti Venuturumilli is a Sr. Solutions Architect in AWS. She works with commercial segment customers and AWS partners to accelerate customers’ business outcomes by providing expertise in AWS services and modernize their workloads. She focuses on data analytics workloads and setting up modern data strategy on AWS. Deepthi Paruchuri is an AWS Solutions Architect based in NYC. She works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.
Deepthi Paruchuri is an AWS Solutions Architect based in NYC. She works closely with customers to build cloud adoption strategy and solve their business needs by designing secure, scalable, and cost-effective solutions in the AWS cloud.