Post Syndicated from Neeraja Rentachintala original https://aws.amazon.com/blogs/big-data/recap-of-amazon-redshift-key-product-announcements-in-2024/
Amazon Redshift, launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Today, Amazon Redshift is used by customers across all industries for a variety of use cases, including data warehouse migration and modernization, near real-time analytics, self-service analytics, data lake analytics, machine learning (ML), and data monetization.
Amazon Redshift made significant strides in 2024, rolling out over 100 features and enhancements. These improvements enhanced price-performance, enabled data lakehouse architectures by blurring the boundaries between data lakes and data warehouses, simplified ingestion and accelerated near real-time analytics, and incorporated generative AI capabilities to build natural language-based applications and boost user productivity.

Figure1: Summary of the features and enhancements in 2024
Let’s walk through some of the recent key launches, including the new announcements at AWS re:Invent 2024.
Industry-leading price-performance
Amazon Redshift offers up to three times better price-performance than alternative cloud data warehouses. Amazon Redshift scales linearly with the number of users and volume of data, making it an ideal solution for both growing businesses and enterprises. For example, dashboarding applications are a very common use case in Redshift customer environments where there is high concurrency and queries require quick, low-latency responses. In these scenarios, Amazon Redshift offers up to seven times better throughput per dollar than alternative cloud data warehouses, demonstrating its exceptional value and predictable costs.
Performance improvements
Over the past few months, we have introduced a number of performance improvements to Redshift. First query response times for dashboard queries have significantly improved by optimizing code execution and reducing compilation overhead. We have enhanced data sharing performance with improved metadata handling, resulting in data sharing first query execution that is up to four times faster when the data sharing producer’s data is being updated. We have enhanced autonomics algorithms to generate and implement smarter and quicker optimal data layout recommendations for distribution and sort keys, further optimizing performance. We have launched new RA3.large instances, a new smaller size RA3 node type, to offer better flexibility in price-performance and provide a cost-effective migration option for customers using DC2.large instances. Additionally, we have rolled out AWS Graviton in Serverless, offering up to 30% better price-performance, and expanded concurrency scaling to support more types of write queries, enabling an even greater ability to maintain consistent performance at scale. These improvements collectively reinforce Amazon Redshift’s focus as a leading cloud data warehouse solution, offering unparalleled performance and value to customers.
General availability of multi-data warehouse writes
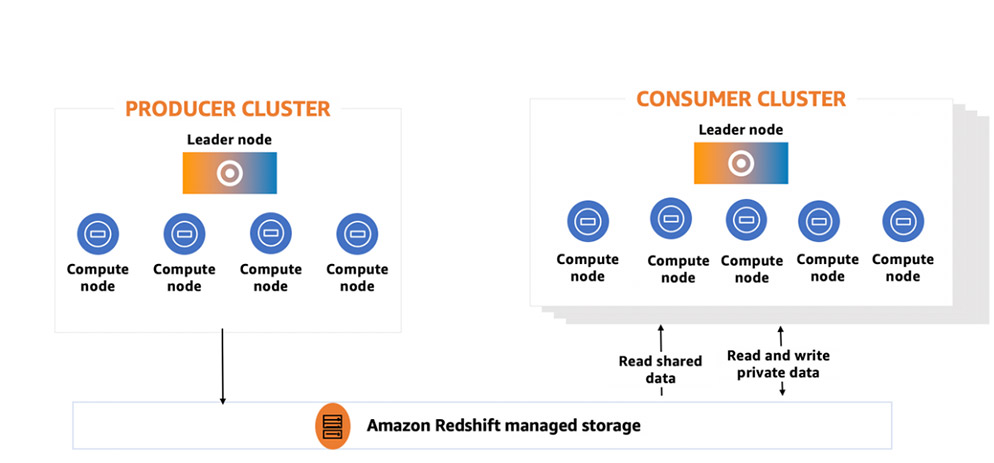
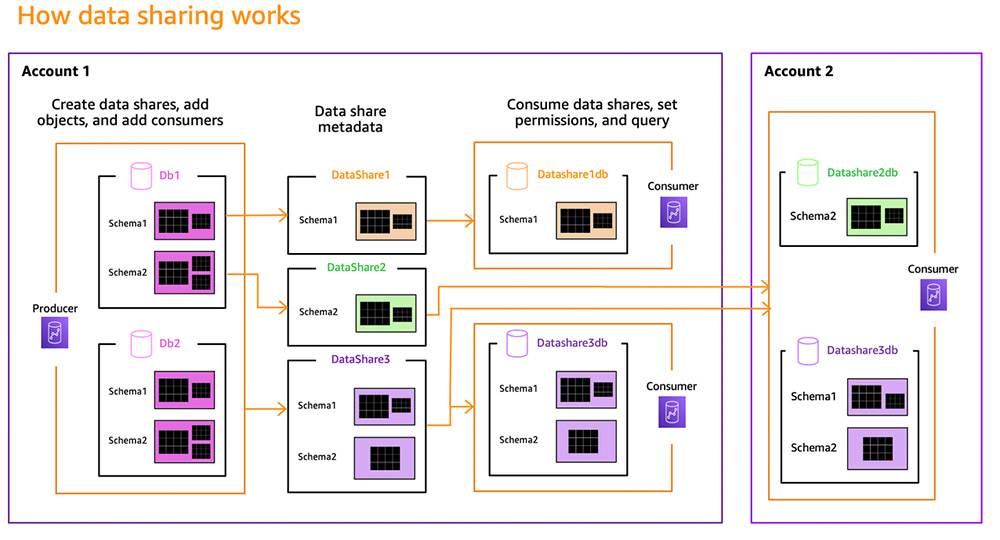
Amazon Redshift allows you to seamlessly scale with multi-cluster deployments. With the introduction of RA3 nodes with managed storage in 2019, customers obtained flexibility to scale and pay for compute and storage independently. Redshift data sharing, launched in 2020, enabled seamless cross-account and cross-Region data collaboration and live access without physically moving the data, while maintaining transactional consistency. This allowed customers to scale read analytics workloads and offered isolation to help maintain SLAs for business-critical applications. At re:Invent 2024, we announced the general availability of multi-data warehouse writes through data sharing for Amazon Redshift RA3 nodes and Serverless. You can now start writing to shared Redshift databases from multiple Redshift data warehouses in just a few clicks. The written data is available to all the data warehouses as soon as it’s committed. This allows your teams to flexibly scale write workloads such as extract, transform, and load (ETL) and data processing by adding compute resources of different types and sizes based on individual workloads’ price-performance requirements, as well as securely collaborate with other teams on live data for use cases such as customer 360.
General availability of AI-driven scaling and optimizations
The launch of Amazon Redshift Serverless in 2021 marked a significant shift, eliminating the need for cluster management while paying for what you use. Redshift Serverless and data sharing enabled customers to easily implement distributed multi-cluster architectures for scaling analytics workloads. In 2024, we launched Serverless in 10 more regions, improved functionality, and added support for a capacity configuration of 1024 RPUs, allowing you to bring larger workloads onto Redshift. Redshift Serverless is also now even more intelligent and dynamic with the new AI-driven scaling and optimization capabilities. As a customer, you choose whether you want to optimize your workloads for cost, performance, or keep it balanced, and that’s it. Redshift Serverless works behind the scenes to scale the compute up and down and deploys optimizations to meet and maintain the performance levels, even when workload demands change. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
Seamless Lakehouse architectures
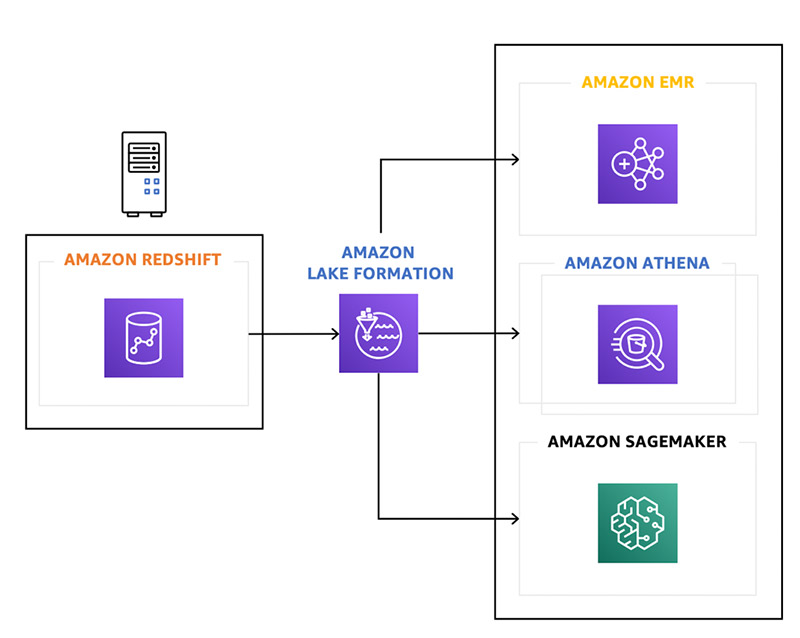
Lakehouse brings together flexibility and openness of data lakes with the performance and transactional capabilities of data warehouses. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data. At re:Invent 2024, we unveiled the next generation of Amazon SageMaker, a unified platform for data, analytics, and AI. This launch brings together widely adopted AWS ML and analytics capabilities, providing an integrated experience for analytics and AI with a re-imagined lakehouse and built-in governance.
General availability of Amazon SageMaker Lakehouse
Amazon SageMaker Lakehouse unifies your data across Amazon S3 data lakes and Redshift data warehouses, enabling you to build powerful analytics and AI/ML applications on a single copy of data. SageMaker Lakehouse provides the flexibility to access and query your data using Apache Iceberg open standards so that you can use your preferred AWS, open source, or third-party Iceberg-compatible engines and tools. SageMaker Lakehouse offers integrated access controls and fine-grained permissions that are consistently applied across all analytics engines and AI models and tools. Existing Redshift data warehouses can be made available through SageMaker Lakehouse in just a simple publish step, opening up all your data warehouse data with Iceberg REST API. You can also create new data lake tables using Redshift Managed Storage (RMS) as a native storage option. Check out the Amazon SageMaker Lakehouse: Accelerate analytics & AI presented at re:Invent 2024.
Preview of Amazon SageMaker Unified Studio
Amazon SageMaker Unified Studio is an integrated data and AI development environment that enables collaboration and helps teams build data products faster. SageMaker Unified Studio brings together functionality and tools from a mix of standalone studios, query editors, and visual tools available today in Amazon EMR, AWS Glue, Amazon Redshift, Amazon Bedrock, and the existing Amazon SageMaker Studio, into one unified experience. With SageMaker Unified Studio, various users such as developers, analysts, data scientists, and business stakeholders can seamlessly work together, share resources, perform analytics, and build and iterate on models, fostering a streamlined and efficient analytics and AI journey.
Amazon Redshift SQL analytics on Amazon S3 Tables
At re:Invent 2024, Amazon S3 introduced Amazon S3 Tables, a new bucket type that is purpose-built to store tabular data at scale with built-in Iceberg support. With table buckets, you can quickly create tables and set up table-level permissions to manage access to your data lake. Amazon Redshift introduced support for querying Iceberg data in data lakes last year, and now this capability is extended to seamlessly querying S3 Tables. S3 Tables customers create are also available as part of the Lakehouse for consumption by other AWS and third-party engines.
Data lake query performance
Amazon Redshift offers high-performance SQL capabilities on SageMaker Lakehouse, whether the data is in other Redshift warehouses or in open formats. We enhanced support for querying Apache Iceberg data and improved the performance of querying Iceberg up to threefold year-over-year. A number of optimizations contribute to these speed-ups in performance, including integration with AWS Glue Data Catalog statistics, improved data and metadata filtering, dynamic partition elimination, faster/parallel processing of Iceberg manifest files, and scanner improvements. In addition, Amazon Redshift now supports incremental refresh support for materialized views on data lake tables to eliminate the need for recomputing the materialized view when new data arrives, simplifying how you build interactive applications on S3 data lakes.
Simplified ingestion and near real-time analytics
In this section, we share the improvements regarding simplified ingestion and near real-time analytics that enable you to get faster insights over fresher data.
Zero-ETL integration with AWS databases and third-party enterprise applications
Amazon Redshift first launched zero-ETL integration between Amazon Aurora MySQL-Compatible Edition, enabling near real-time analytics on petabytes of transactional data from Aurora. This capability has since expanded to support Amazon Aurora PostgreSQL-Compatible Edition, Amazon Relational Database Service (Amazon RDS) for MySQL, and Amazon DynamoDB, and includes additional features such as data filtering to selectively extract tables and schemas using regular expressions, support for incremental and auto-refresh materialized views on replicated data, and configurable change data capture (CDC) refresh rates.
Building on this innovation, at re:Invent 2024, we launched support for zero-ETL integration with eight enterprise applications, specifically Salesforce, Zendesk, ServiceNow, SAP, Facebook Ads, Instagram Ads, Pardot, and Zoho CRM. With this new capability, you can efficiently extract and load valuable data from your customer support, relationship management, and Enterprise Resource Planning (ERP) applications directly into your Redshift data warehouse for analysis. This seamless integration eliminates the need for complex, custom ingestion pipelines for ingesting the data, accelerating time to insights.
General availability of auto-copy
Auto-copy simplifies data ingestion from Amazon S3 into Amazon Redshift. This new feature enables you to set up continuous file ingestion from your Amazon S3 prefix and automatically load new files to tables in your Redshift data warehouse without the need for additional tools or custom solutions.
Streaming ingestion from Confluent Managed Cloud and self-managed Apache Kafka clusters
Amazon Redshift now supports streaming ingestion from Confluent Managed Cloud and self-managed Apache Kafka clusters on Amazon EC2instances, expanding its capabilities beyond Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK). With this update, you can ingest data from a wider range of streaming sources directly into your Redshift data warehouses for near real-time analytics use cases such as fraud detection, logistics monitoring and clickstream analysis.
Generative AI capabilities
In this section, we share the improvements generative AI capabilities.
Amazon Q generative SQL for Amazon Redshift
We announced the general availability of Amazon Q generative SQL for Amazon Redshift feature in the Redshift Query Editor. Amazon Q generative SQL boosts productivity by allowing users to express queries in natural language and receive SQL code recommendations based on their intent, query patterns, and schema metadata. The conversational interface enables users to get insights faster without extensive knowledge of the database schema. It leverages generative AI to analyze user input, query history, and custom context like table/column descriptions and sample queries to provide more relevant and accurate SQL recommendations. This feature accelerates the query authoring process and reduces the time required to derive actionable data insights.
Amazon Redshift integration with Amazon Bedrock
We announced integration of Amazon Redshift with Amazon Bedrock, enabling you to invoke large language models (LLMs) from simple SQL commands on your data in Amazon Redshift. With this new feature, you can now effortlessly perform generative AI tasks such as language translation, text generation, summarization, customer classification, and sentiment analysis on your Redshift data using popular foundation models (FMs) like Anthropic’s Claude, Amazon Titan, Meta’s Llama 2, and Mistral AI. You can invoke these models using familiar SQL commands, making it simpler than ever to integrate generative AI capabilities into your data analytics workflows.
Amazon Redshift as a knowledge base in Amazon Bedrock
Amazon Bedrock Knowledge Bases now supports natural language querying to retrieve structured data from your Redshift data warehouses. Using advanced natural language processing, Amazon Bedrock Knowledge Bases can transform natural language queries into SQL queries, allowing users to retrieve data directly from the source without the need to move or preprocess the data. A retail analyst can now simply ask “What were my top 5 selling products last month?”, and Amazon Bedrock Knowledge Bases automatically translates that query into SQL, runs the query against Redshift, and returns the results—or even provides a summarized narrative response. To generate accurate SQL queries, Amazon Bedrock Knowledge Bases uses database schema, previous query history, and other contextual information that is provided about the data sources.
Launch summary
Following is the launch summary which provides the announcement links and reference blogs for the key announcements.
Industry-leading price-performance:
- Amazon Redshift launches RA3.large instances
- Amazon Redshift multi-data warehouse writes through data sharing is now generally available
- Announcing Amazon Redshift Serverless with AI-driven scaling and optimization
- Amazon Redshift Serverless higher base capacity of 1024 RPUs is now available in additional AWS regions
- Amazon Redshift Serverless is now available in the AWS GovCloud (US) Regions
- Amazon Redshift launches query profiler for enhanced query monitoring and diagnostics
- Amazon Redshift introduces query identifiers for improved query performance monitoring
Reference Blogs:
- Develop a business chargeback model within your organization using Amazon Redshift multi-warehouse writes
- Optimize your workloads with Amazon Redshift Serverless AI-driven scaling and optimization
- Simplify your query performance diagnostics in Amazon Redshift with Query profiler
- Achieve the best price-performance in Amazon Redshift with elastic histograms for selectivity estimation
Seamless Lakehouse architectures:
- AWS announces Amazon SageMaker Lakehouse
- Announcing the preview of Amazon SageMaker Unified Studio
- Amazon Redshift now supports incremental refresh on Materialized Views (MVs) for data lake tables
- Amazon Redshift announces generally availability for data sharing with data lake tables
- Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
- Amazon Redshift releases drivers for supporting single sign-on with AWS IAM Identity Center
Reference Blogs:
- The next generation of Amazon SageMaker: The center for all your data, analytics, and AI
- Simplify analytics and AI/ML with new Amazon SageMaker Lakehouse
- Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
- Integrate Identity Provider (IdP) with Amazon Redshift Query Editor V2 and SQL Client using AWS IAM Identity Center for seamless Single Sign-On
Simplified ingestion and near real-time analytics:
- Amazon Redshift announces support for Confluent Cloud and Apache Kafka
- Announcing general availability of auto-copy for Amazon Redshift
- Amazon SageMaker Lakehouse and Amazon Redshift support for zero-ETL integrations from eight applications
- Amazon Aurora PostgreSQL zero-ETL integration with Amazon Redshift now generally available
- AWS announces general availability of Amazon DynamoDB zero-ETL integration with Amazon Redshift
- Amazon Redshift now supports enhanced VPC routing warehouses in zero-ETL integration
- Amazon RDS for MySQL zero-ETL integration with Amazon Redshift is now generally available
Reference Blogs:
- Simplify data ingestion from Amazon S3 to Amazon Redshift using auto-copy
- Amazon SageMaker Lakehouse and Amazon Redshift supports zero-ETL integrations from applications
- Amazon Aurora PostgreSQL and Amazon DynamoDB zero-ETL integrations with Amazon Redshift now generally available
Generative AI:
- Announcing general availability (GA) of Amazon Q generative SQL for Amazon Redshift
- Amazon Redshift integration with Amazon Bedrock for generative AI
- Amazon Bedrock Knowledge Bases now supports structured data retrieval
Reference Blogs:
- Write queries faster with Amazon Q generative SQL for Amazon Redshift
- Integrate Amazon Bedrock with Amazon Redshift ML for generative AI applications
Conclusion
We continue to innovate and evolve Amazon Redshift to meet your evolving data analytics needs. We encourage you to try out the latest features and capabilities. Watch the Innovations in AWS analytics: Data warehousing and SQL analytics session from re:Invent 2024 for further details. If you need any support, reach out to us. We are happy to provide architectural and design guidance, as well as support for proof of concepts and implementation. It’s Day 1!
About the Author
 Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com
Neeraja Rentachintala is Director, Product Management with AWS Analytics, leading Amazon Redshift and Amazon SageMaker Lakehouse. Neeraja is a seasoned technology leader, bringing over 25 years of experience in product vision, strategy, and leadership roles in data products and platforms. She has delivered products in analytics, databases, data integration, application integration, AI/ML, and large-scale distributed systems across on-premises and the cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica, and Expedia.com

 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.




 Ippokratis Pandis is a senior principal engineer at AWS. Ippokratis leads initiatives in AWS analytics and data lakes, especially in Amazon Redshift. He holds a Ph.D. in electrical engineering from Carnegie Mellon University.
Ippokratis Pandis is a senior principal engineer at AWS. Ippokratis leads initiatives in AWS analytics and data lakes, especially in Amazon Redshift. He holds a Ph.D. in electrical engineering from Carnegie Mellon University. Naresh Chainani is a senior software development manager with Amazon Redshift, where he leads Query Processing, Query Performance, Distributed Systems, and Workload Management with a strong team. He is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
Naresh Chainani is a senior software development manager with Amazon Redshift, where he leads Query Processing, Query Performance, Distributed Systems, and Workload Management with a strong team. He is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.







 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com. Jenny Chen is a senior database engineer at Amazon Redshift focusing on all aspects of Redshift performance, like Query Processing, Concurrency, Distributed system, Storage, OS and many more. She works together with development team to ensure of delivering highest performance, scalable and easy-of-use database for customer. Prior to her career in cloud data warehouse, she has 10-year of experience in enterprise database DB2 for z/OS in IBM with focus on query optimization, query performance and system performance.
Jenny Chen is a senior database engineer at Amazon Redshift focusing on all aspects of Redshift performance, like Query Processing, Concurrency, Distributed system, Storage, OS and many more. She works together with development team to ensure of delivering highest performance, scalable and easy-of-use database for customer. Prior to her career in cloud data warehouse, she has 10-year of experience in enterprise database DB2 for z/OS in IBM with focus on query optimization, query performance and system performance. Suzhen Lin is a senior software development engineer on the Amazon Redshift transaction processing and storage team. Suzhen Lin has over 15 years of experiences in industry leading analytical database products including AWS Redshift, Gauss MPPDB, Azure SQL Data Warehouse and Teradata as senior architect and developer. Her experiences cover storage, transaction processing, query processing, memory/disk caching and etc in on-premise/cloud database management systems.
Suzhen Lin is a senior software development engineer on the Amazon Redshift transaction processing and storage team. Suzhen Lin has over 15 years of experiences in industry leading analytical database products including AWS Redshift, Gauss MPPDB, Azure SQL Data Warehouse and Teradata as senior architect and developer. Her experiences cover storage, transaction processing, query processing, memory/disk caching and etc in on-premise/cloud database management systems.