Post Syndicated from Roy Hasson original https://aws.amazon.com/blogs/big-data/make-data-available-for-analysis-in-seconds-with-upsolver-low-code-data-pipelines-amazon-redshift-streaming-ingestion-and-amazon-redshift-serverless/
Amazon Redshift is the most widely used cloud data warehouse. Amazon Redshift makes it easy and cost-effective to perform analytics on vast amounts of data. Amazon Redshift launched Streaming Ingestion for Amazon Kinesis Data Streams, which enables you to load data into Amazon Redshift with low latency and without having to stage the data in Amazon Simple Storage Service (Amazon S3). This new capability enables you to build reports and dashboards and perform analytics using fresh and current data, without needing to manage custom code that periodically loads new data.
Upsolver is an AWS Advanced Technology Partner that enables you to ingest data from a wide range of sources, transform it, and load the results into your target of choice, such as Kinesis Data Streams and Amazon Redshift. Data analysts, engineers, and data scientists define their transformation logic using SQL, and Upsolver automates the deployment, scheduling, and maintenance of the data pipeline. It’s pipeline ops simplified!
There are multiple ways to stream data to Amazon Redshift and in this post we will cover two options that Upsolver can help you with: First, we show you how to configure Upsolver to stream events to Kinesis Data Streams that are consumed by Amazon Redshift using Streaming Ingestion. Second, we demonstrate how to write event data to your data lake and consume it using Amazon Redshift Serverless so you can go from raw events to analytics-ready datasets in minutes.
Prerequisites
Before you get started, you need to install Upsolver. You can sign up for Upsolver and deploy it directly into your VPC to securely access Kinesis Data Streams and Amazon Redshift.
Configure Upsolver to stream events to Kinesis Data Streams
The following diagram represents the architecture to write events to Kinesis Data Streams and Amazon Redshift.

To implement this solution, you complete the following high-level steps:
- Configure the source Kinesis data stream.
- Execute the data pipeline.
- Create an Amazon Redshift external schema and materialized view.
Configure the source Kinesis data stream
For the purpose of this post, you create an Amazon S3 data source that contains sample retail data in JSON format. Upsolver ingests this data as a stream; as new objects arrive, they’re automatically ingested and streamed to the destination.
- On the Upsolver console, choose Data Sources in the navigation sidebar.
- Choose New.
- Choose Amazon S3 as your data source.
- For Bucket, you can use the bucket with the public dataset or a bucket with your own data.
- Choose Continue to create the data source.

- Create a data stream in Kinesis Data Streams, as shown in the following screenshot.

This is the output stream Upsolver uses to write events that are consumed by Amazon Redshift.

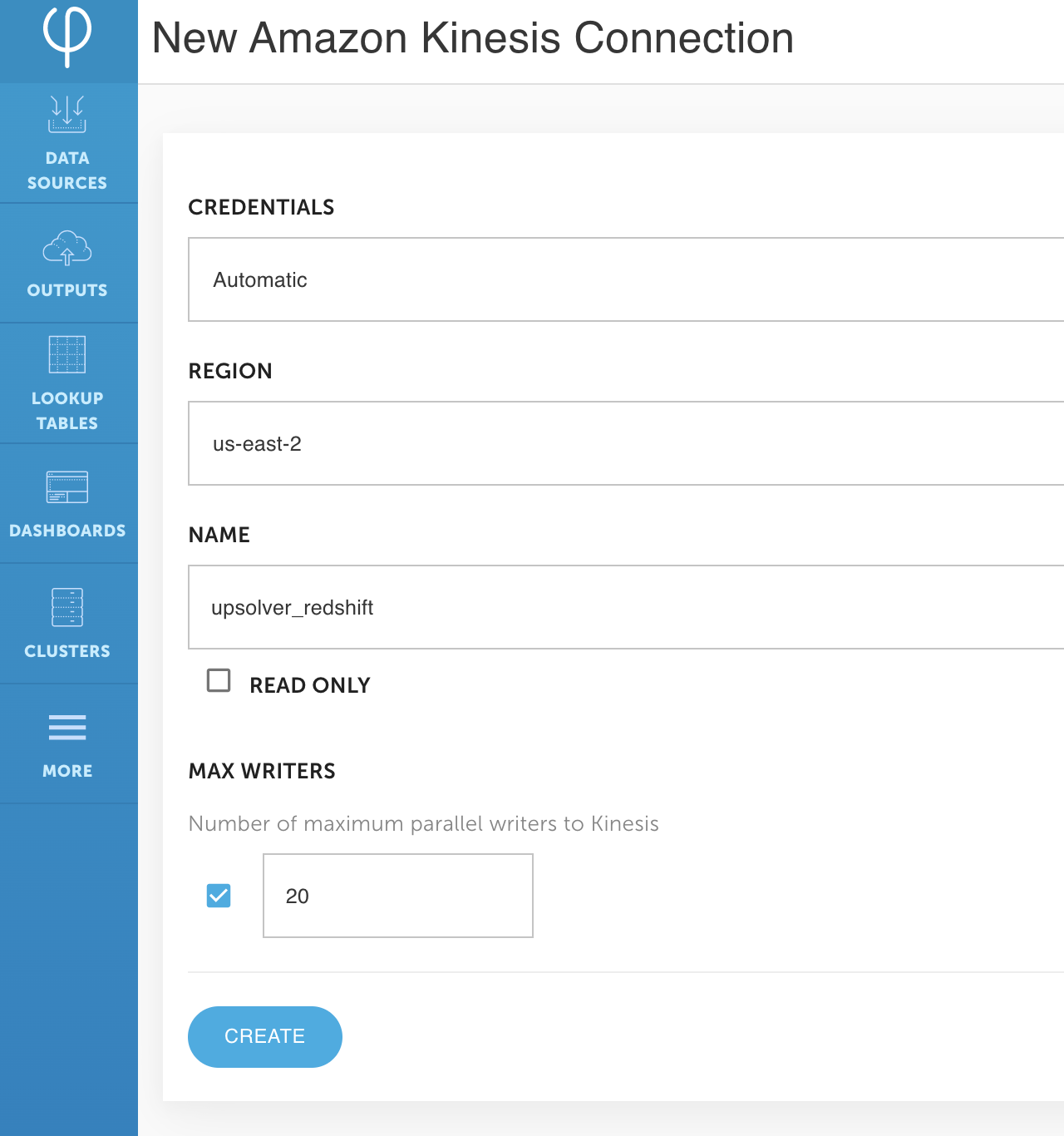
Next, you create a Kinesis connection in Upsolver. Creating a connection enables you to define the authentication method Upsolver uses—for example, an AWS Identity and Access Management (IAM) access key and secret key or an IAM role.
- On the Upsolver console, choose More in the navigation sidebar.
- Choose Connections.
- Choose New Connection.
- Choose Amazon Kinesis.
- For Region, enter your AWS Region.
- For Name, enter a name for your connection (for this post, we name it
upsolver_redshift). - Choose Create.

Before you can consume the events in Amazon Redshift, you must write them to the output Kinesis data stream.
- On the Upsolver console, navigate to Outputs and choose Kinesis.
- For Data Sources, choose the Kinesis data source you created in the previous step.
- Depending on the structure of your event data, you have two choices:
- If the event data you’re writing to the output doesn’t contain any nested fields, select Tabular. Upsolver automatically flattens nested data for you.
- To write your data in a nested format, select Hierarchical.
- Because we’re working with Kinesis Data Streams, select Hierarchical.


Execute the data pipeline
Now that the stream is connected from the source to an output, you must select which fields of the source event you wish to pass through. You can also choose to apply transformations to your data—for example, adding correct timestamps, masking sensitive values, and adding computed fields. For more information, refer to Quick guide: SQL data transformation.
After adding the columns you want to include in the output and applying transformations, choose Run to start the data pipeline. As new events arrive in the source, Upsolver automatically transforms them and forwards the results to the output stream. There is no need to schedule or orchestrate the pipeline; it’s always on.

Create an Amazon Redshift external schema and materialized view
First, create an IAM role with the appropriate permissions (for more information, refer to Streaming ingestion). Now you can use the Amazon Redshift query editor, AWS Command Line Interface (AWS CLI), or API to run the following SQL statements.
- Create an external schema that is backed by Kinesis Data Streams. The following command requires you to include the IAM role you created earlier:
- Create a materialized view that allows you to run a SELECT statement against the event data that Upsolver produces:
- Instruct Amazon Redshift to materialize the results to a table called
mv_orders: - You can now run queries against your streaming data, such as the following:

Use Upsolver to write data to a data lake and query it with Amazon Redshift Serverless
The following diagram represents the architecture to write events to your data lake and query the data with Amazon Redshift.

To implement this solution, you complete the following high-level steps:
- Configure the source Kinesis data stream.
- Connect to the AWS Glue Data Catalog and update the metadata.
- Query the data lake.
Configure the source Kinesis data stream
We already completed this step earlier in the post, so you don’t need to do anything different.
Connect to the AWS Glue Data Catalog and update the metadata
To update the metadata, complete the following steps:
- On the Upsolver console, choose More in the navigation sidebar.
- Choose Connections.
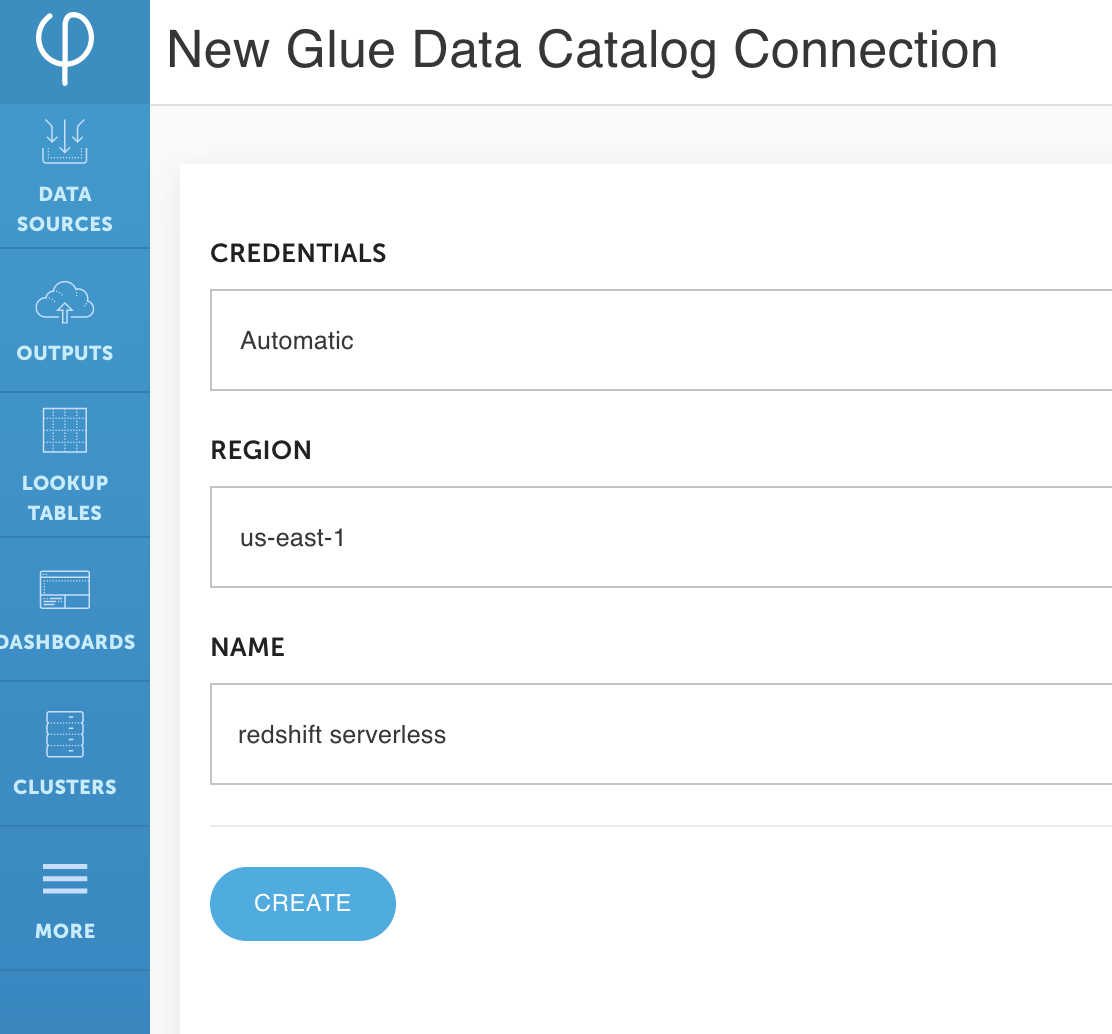
- Choose the AWS Glue Data Catalog connection.
- For Region, enter your Region.
- For Name, enter a name (for this post, we call it
redshift serverless). - Choose Create.

- Create a Redshift Spectrum output, following the same steps from earlier in this post.
- Select Tabular as we’re writing output in table-formatted data to Amazon Redshift.

- Map the data source fields to the Redshift Spectrum output.
- Choose Run.

- On the Amazon Redshift console, create an Amazon Redshift Serverless endpoint.
- Make sure you associate your Upsolver role to Amazon Redshift Serverless.
- When the endpoint launches, open the new Amazon Redshift query editor to create an external schema that points to the AWS Glue Data Catalog (see the following screenshot).


This enables you to run queries against data stored in your data lake.

Query the data lake
Now that your Upsolver data is being automatically written and maintained in your data lake, you can query it using your preferred tool and the Amazon Redshift query editor, as shown in the following screenshot.

Conclusion
In this post, you learned how to use Upsolver to stream event data into Amazon Redshift using streaming ingestion for Kinesis Data Streams. You also learned how you can use Upsolver to write the stream to your data lake and query it using Amazon Redshift Serverless.
Upsolver makes it easy to build data pipelines using SQL and automates the complexity of pipeline management, scaling, and maintenance. Upsolver and Amazon Redshift enable you to quickly and easily analyze data in real time.
If you have any questions, or wish to discuss this integration or explore other use cases, start the conversation in our Upsolver Community Slack channel.
About the Authors
 Roy Hasson is the Head of Product at Upsolver. He works with customers globally to simplify how they build, manage and deploy data pipelines to deliver high quality data as a product. Previously, Roy was a Product Manager for AWS Glue and AWS Lake Formation.
Roy Hasson is the Head of Product at Upsolver. He works with customers globally to simplify how they build, manage and deploy data pipelines to deliver high quality data as a product. Previously, Roy was a Product Manager for AWS Glue and AWS Lake Formation.
 Mei Long is a Product Manager at Upsolver. She is on a mission to make data accessible, usable and manageable in the cloud. Previously, Mei played an instrumental role working with the teams that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes projects.
Mei Long is a Product Manager at Upsolver. She is on a mission to make data accessible, usable and manageable in the cloud. Previously, Mei played an instrumental role working with the teams that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes projects.
 Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.
Maneesh Sharma is a Senior Database Engineer at AWS with more than a decade of experience designing and implementing large-scale data warehouse and analytics solutions. He collaborates with various Amazon Redshift Partners and customers to drive better integration.