Post Syndicated from Sotaro Hikita original https://aws.amazon.com/blogs/big-data/accelerate-lightweight-analytics-using-pyiceberg-with-aws-lambda-and-an-aws-glue-iceberg-rest-endpoint/
For modern organizations built on data insights, effective data management is crucial for powering advanced analytics and machine learning (ML) activities. As data use cases become more complex, data engineering teams require sophisticated tooling to handle versioning, increasing data volumes, and schema changes across multiple data sources and applications.
Apache Iceberg has emerged as a popular choice for data lakes, offering ACID (Atomicity, Consistency, Isolation, Durability) transactions, schema evolution, and time travel capabilities. Iceberg tables can be accessed from various distributed data processing frameworks like Apache Spark and Trino, making it a flexible solution for diverse data processing needs. Among the available tools for working with Iceberg, PyIceberg stands out as a Python implementation that enables table access and management without requiring distributed compute resources.
In this post, we demonstrate how PyIceberg, integrated with the AWS Glue Data Catalog and AWS Lambda, provides a lightweight approach to harness Iceberg’s powerful features through intuitive Python interfaces. We show how this integration enables teams to start working with Iceberg tables with minimal setup and infrastructure dependencies.
PyIceberg’s key capabilities and advantages
One of PyIceberg’s primary advantages is its lightweight nature. Without requiring distributed computing frameworks, teams can perform table operations directly from Python applications, making it suitable for small to medium-scale data exploration and analysis with minimal learning curve. In addition, PyIceberg is integrated with Python data analysis libraries like Pandas and Polars, so data users can use their existing skills and workflows.
When using PyIceberg with the Data Catalog and Amazon Simple Storage Service (Amazon S3), data teams can store and manage their tables in a completely serverless environment. This means data teams can focus on analysis and insights rather than infrastructure management.
Furthermore, Iceberg tables managed through PyIceberg are compatible with AWS data analytics services. Although PyIceberg operates on a single node and has performance limitations with large data volumes, the same tables can be efficiently processed at scale using services such as Amazon Athena and AWS Glue. This enables teams to use PyIceberg for rapid development and testing, then transition to production workloads with larger-scale processing engines—while maintaining consistency in their data management approach.
Representative use case
The following are common scenarios where PyIceberg can be particularly useful:
- Data science experimentation and feature engineering – In data science, experiment reproducibility is crucial for maintaining reliable and efficient analyses and models. However, continuously updating organizational data makes it challenging to manage data snapshots for important business events, model training, and consistent reference. Data scientists can query historical snapshots through time travel capabilities and record important versions using tagging features. With PyIceberg, they can receive these benefits in their Python environment using familiar tools like Pandas. Thanks to Iceberg’s ACID capabilities, they can access consistent data even when tables are being actively updated.
- Serverless data processing with Lambda – Organizations often need to process data and maintain analytical tables efficiently without managing complex infrastructure. Using PyIceberg with Lambda, teams can build event-driven data processing and scheduled table updates through serverless functions. PyIceberg’s lightweight nature makes it well-suited for serverless environments, enabling simple data processing tasks like data validation, transformation, and ingestion. These tables remain accessible for both updates and analytics through various AWS services, allowing teams to build efficient data pipelines without managing servers or clusters.
Event-driven data ingestion and analysis with PyIceberg
In this section, we explore a practical example of using PyIceberg for data processing and analysis using NYC yellow taxi trip data. To simulate an event-driven data processing scenario, we use Lambda to insert sample data into an Iceberg table, representing how real-time taxi trip records might be processed. This example will demonstrate how PyIceberg can streamline workflows by combining efficient data ingestion with flexible analysis capabilities.
Imagine your team faces several requirements:
- The data processing solution needs to be cost-effective and maintainable, avoiding the complexity of managing distributed computing clusters for this moderately-sized dataset.
- Analysts need the ability to perform flexible queries and explorations using familiar Python tools. For example, they might need to compare historical snapshots with current data to analyze trends over time.
- The solution should have the ability to expand to be more scalable in the future.
To address these requirements, we implement a solution that combines Lambda for data processing with Jupyter notebooks for analysis, both powered by PyIceberg. This approach provides a lightweight yet robust architecture that maintains data consistency while enabling flexible analysis workflows. At the end of the walkthrough, we also query this data using Athena to demonstrate compatibility with multiple Iceberg-supporting tools and show how the architecture can scale.
We walk through the following high-level steps:
- Use Lambda to write sample NYC yellow taxi trip data to an Iceberg table on Amazon S3 using PyIceberg with an AWS Glue Iceberg REST endpoint. In a real-world scenario, this Lambda function would be triggered by an event from a queuing component like Amazon Simple Queue Service (Amazon SQS). For more details, see Using Lambda with Amazon SQS.
- Analyze table data in a Jupyter notebook using PyIceberg through the AWS Glue Iceberg REST endpoint.
- Query the data using Athena to demonstrate Iceberg’s flexibility.
The following diagram illustrates the architecture.

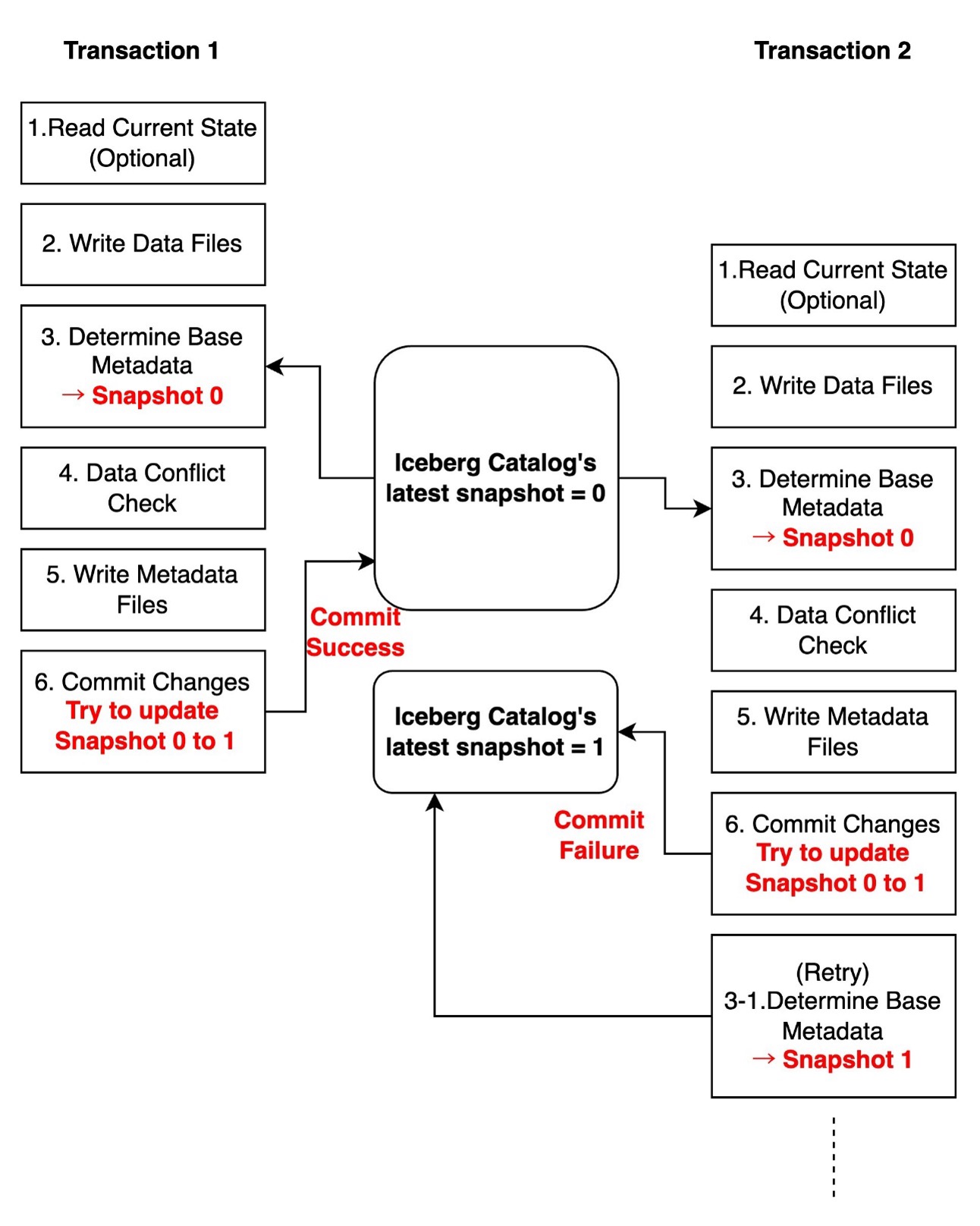
When implementing this architecture, it’s important to note that Lambda functions can have multiple concurrent invocations when triggered by events. This concurrent invocation might lead to transaction conflicts when writing to Iceberg tables. To handle this, you should implement an appropriate retry mechanism and carefully manage concurrency levels. If you’re using Amazon SQS as an event source, you can control concurrent invocations through the SQS event source’s maximum concurrency setting.
Prerequisites
The following prerequisites are necessary for this use case:
- An active AWS account that provides access to Lambda, AWS Glue, Amazon S3, Athena, and AWS CloudFormation.
- Permissions to create and deploy a CloudFormation stack. For more details, see Create CloudFormation StackSets with self-managed permissions.
- A user with full access to AWS CloudShell and its features. For more details, see Getting started with AWS CloudShell.
Set up resources with AWS CloudFormation
You can use the provided CloudFormation template to set up the following resources:
- An S3 bucket for metadata and data files of an Iceberg table
- An Amazon Elastic Container Registry (Amazon ECR) repository to store the container image for a Lambda function
- A Data Catalog database to store the table
- An Amazon SageMaker AI notebook instance for the Jupyter notebook environment
- An AWS Identity and Access Management (IAM) role for a Lambda function and SageMaker AI notebook instance
Complete the following steps to deploy the resources:
- Choose Launch stack.
![]()
- For Parameters,
pyiceberg_lambda_blog_databaseis set by default. You can also change the default value. If you change the database name, remember to replacepyiceberg_lambda_blog_databasewith your chosen name in all subsequent steps. Then, choose Next. - Choose Next.
- Select I acknowledge that AWS CloudFormation might create IAM resources with custom names.
- Choose Submit.
Build and run a Lambda function
Let’s build a Lambda function to process incoming records using PyIceberg. This function creates an Iceberg table called nyc_yellow_table in the database pyiceberg_lambda_blog_database in the Data Catalog if it doesn’t exist. It then generates sample NYC taxi trip data to simulate incoming records and inserts it into nyc_yellow_table.
Although we invoke this function manually in this example, in real-world scenarios, this Lambda function would be triggered by actual events, such as messages from Amazon SQS. When implementing real-world use cases, the function code must be modified to receive the event data and process it based on the requirements.
We deploy the function using container images as the deployment package. To create a Lambda function from a container image, build your image on CloudShell and push it to an ECR repository. Complete the following steps:
- Sign in to the AWS Management Console and launch CloudShell.
- Create a working directory.
- Download the Lambda script
lambda_function.py.
This script performs the following tasks:
- Creates an Iceberg table with the NYC taxi schema in the Data Catalog
- Generates a random NYC taxi dataset
- Inserts this data into the table
Let’s break down the essential parts of this Lambda function:
- Iceberg catalog configuration – The following code defines an Iceberg catalog that connects to the AWS Glue Iceberg REST endpoint:
- Table schema definition – The following code defines the Iceberg table schema for the NYC taxi dataset. The table includes:
- Schema columns defined in the
Schema - Partitioning by
vendoridandtpep_pickup_datetimeusing PartitionSpec - Day transform applied to
tpep_pickup_datetimefor daily record management - Sort ordering by
tpep_pickup_datetimeandtpep_dropoff_datetime
- Schema columns defined in the
When applying the day transform to timestamp columns, Iceberg automatically handles date-based partitioning hierarchically. This means a single day transform enables partition pruning at the year, month, and day levels without requiring explicit transforms for each level. For more details about Iceberg partitioning, see Partitioning.
- Data generation and insertion – The following code generates random data and inserts it into the table. This example demonstrates an append-only pattern, where new records are continuously added to track business events and transactions:
- Download the
Dockerfile. It defines the container image for your function code.
- Download the
requirements.txt. It defines the Python packages required for your function code.
At this point, your working directory should contain the following three files:
- Set the environment variables. Replace
<account_id>with your AWS account ID:
- Build the Docker image:
- Set a tag to the image:
- Log in to the ECR repository created by AWS CloudFormation:
- Push the image to the ECR repository:
- Create a Lambda function using the container image you pushed to Amazon ECR:
- Invoke the function at least five times to create multiple snapshots, which we will examine in the following sections. Note that we are invoking the function manually to simulate event-driven data ingestion. In real world scenarios, Lambda functions will be automatically invoked with event-driven fashion.
At this point, you have deployed and run the Lambda function. The function creates the nyc_yellow_table Iceberg table in the pyiceberg_lambda_blog_database database. It also generates and inserts sample data into this table. We will explore the records in the table in later steps.
For more detailed information about building Lambda functions with containers, see Create a Lambda function using a container image.
Explore the data with Jupyter using PyIceberg
In this section, we demonstrate how to access and analyze the data stored in Iceberg tables registered in the Data Catalog. Using a Jupyter notebook with PyIceberg, we access the taxi trip data created by our Lambda function and examine different snapshots as new records arrive. We also tag specific snapshots to retain important ones, and create new tables for further analysis.
Complete the following steps to open the notebook with Jupyter on the SageMaker AI notebook instance:
- On the SageMaker AI console, choose Notebooks in the navigation pane.
- Choose Open JupyterLab next to the notebook that you created using the CloudFormation template.

- Download the notebook and open it in a Jupyter environment on your SageMaker AI notebook.

- Open uploaded
pyiceberg_notebook.ipynb. - In the kernel selection dialog, leave the default option and choose Select.

From this point forward, you will work through the notebook by running cells in order.
Connecting Catalog and Scanning Tables
You can access the Iceberg table using PyIceberg. The following code connects to the AWS Glue Iceberg REST endpoint and loads the nyc_yellow_table table on the pyiceberg_lambda_blog_database database:
You can query full data from the Iceberg table as an Apache Arrow table and convert it to a Pandas DataFrame.

Working with Snapshots
One of the important features of Iceberg is snapshot-based version control. Snapshots are automatically created whenever data changes occur in the table. You can retrieve data from a specific snapshot, as shown in the following example.

You can compare the current data with historical data from any point in time based on snapshots. In this case, you are comparing the differences in data distribution between the latest table and a snapshot table:

Tagging snapshots
You can tag specific snapshots with an arbitrary name and query specific snapshots with that name later. This is useful when managing snapshots of important events.

In this example, you query a snapshot specifying the tag checkpointTag. Here, you are using the polars to create a new DataFrame by adding a new column called trip_duration based on existing columns tpep_dropoff_datetime and tpep_pickup_datetime columns:

Create a new table from the processed DataFrame with the trip_duration column. This step illustrates how to prepare data for potential future analysis. You can explicitly specify the snapshot of the data that the processed data is referring to by using a tag, even if the underlying table has been changed.
Let’s query this new table made from processed data with Athena to demonstrate the Iceberg table’s interoperability.
Query the data from Athena
- In the Athena query editor, you can query the table
pyiceberg_lambda_blog_database.processed_nyc_yellow_tablecreated from the notebook in the previous section:

By completing these steps, you’ve built a serverless data processing solution using PyIceberg with Lambda and an AWS Glue Iceberg REST endpoint. You’ve worked with PyIceberg to manage and analyze data using Python, including snapshot management and table operations. In addition, you ran the query using another engine, Athena, which shows the compatibility of the Iceberg table.
Clean up
To clean up the resources used in this post, complete the following steps:
- On the Amazon ECR console, navigate to the repository
pyiceberg-lambda-repositoryand delete all images contained in the repository. - On the CloudShell, delete working directory
pyiceberg_blog. - On the Amazon S3 console, navigate to the S3 bucket
pyiceberg-lambda-blog-<ACCOUNT_ID>-<REGION>, which you created using the CloudFormation template, and empty the bucket. - After you confirm the repository and the bucket are empty, delete the CloudFormation stack
pyiceberg-lambda-blog-stack. - Delete the Lambda function
pyiceberg-lambda-functionthat you created using the Docker image.
Conclusion
In this post, we demonstrated how using PyIceberg with the AWS Glue Data Catalog enables efficient, lightweight data workflows while maintaining robust data management capabilities. We showcased how teams can use Iceberg’s powerful features with minimal setup and infrastructure dependencies. This approach allows organizations to start working with Iceberg tables quickly, without the complexity of setting up and managing distributed computing resources.
This is particularly valuable for organizations looking to adopt Iceberg’s capabilities with a low barrier to entry. The lightweight nature of PyIceberg allows teams to begin working with Iceberg tables immediately, using familiar tools and requiring minimal additional learning. As data needs grow, the same Iceberg tables can be seamlessly accessed by AWS analytics services like Athena and AWS Glue, providing a clear path for future scalability.
To learn more about PyIceberg and AWS analytics services, we encourage you to explore the PyIceberg documentation and What is Apache Iceberg?
About the authors
 Sotaro Hikita is a Specialist Solutions Architect focused on analytics with AWS, working with big data technologies and open source software. Outside of work, he always seeks out good food and has recently become passionate about pizza.
Sotaro Hikita is a Specialist Solutions Architect focused on analytics with AWS, working with big data technologies and open source software. Outside of work, he always seeks out good food and has recently become passionate about pizza.
 Shuhei Fukami is a Specialist Solutions Architect focused on Analytics with AWS. He likes cooking in his spare time and has become obsessed with making pizza these days.
Shuhei Fukami is a Specialist Solutions Architect focused on Analytics with AWS. He likes cooking in his spare time and has become obsessed with making pizza these days.




 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.






 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.







 Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems.
Kyle Duong is a Senior Software Development Engineer on the AWS Glue and AWS Lake Formation team. He is passionate about building big data technologies and distributed systems. Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.












 Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes.
Kalaiselvi Kamaraj is a Senior Software Development Engineer with Amazon. She has worked on several projects within the Amazon Redshift query processing team and currently focusing on performance-related projects for Redshift data lakes.