Post Syndicated from Biswanath Mukherjee original https://aws.amazon.com/blogs/compute/orchestrating-big-data-processing-with-aws-step-functions-distributed-map/
Developers seek to process and enrich semi-structured big data datasets with durably orchestrated network-based workflows. For example, during quarterly earnings season, finance organizations run thousands of market simulations simultaneously to provide timely insights for scenario planning or risk management—these workloads require coordination between raw datasets and on-premise servers to provide the latest market information.
AWS Step Functions is a visual workflow service capable of orchestrating over 14,000 API actions from over 220 AWS services to build distributed applications. Now, Step Functions Distributed Map streamlines big data dataset transformation by processing Amazon Athena data manifest and Parquet files directly. Using its Distributed Map feature, you can process large scale datasets by running concurrent iterations across data entries in parallel. In Distributed mode, the Map state processes the items in the dataset in iterations called child workflow executions. You can specify the number of child workflow executions that can run in parallel. Each child workflow execution has its own, separate execution history from that of the parent workflow. By default, Step Functions runs 10,000 parallel child workflow executions in parallel.
Distributed Map can process AWS Athena data manifest and Parquet files directly, eliminating the need for custom pre-processing. You also now have visibility into your Distributed Map usage with new Amazon CloudWatch metrics: Approximate Open Map Runs Count, Open Map Run Limit, and Approximate Map Runs Backlog Size.
In this post, you’ll learn how to use AWS Step Functions Distributed Map to process Athena data manifest and Parquet files through a step-by-step demonstration.
This post is part of a series of post about AWS Step Functions Distributed Map:
|
Use case: IoT sensor data processing
You’ll build a sample application that demonstrates processing IoT sensor data in Parquet format using Step Functions Distributed Map. These Parquet data files and a manifest file containing the list of the data files are exported from Athena. The data temperature, humidity, and lbattery level from different devices. The following table shows sample of sensor data:
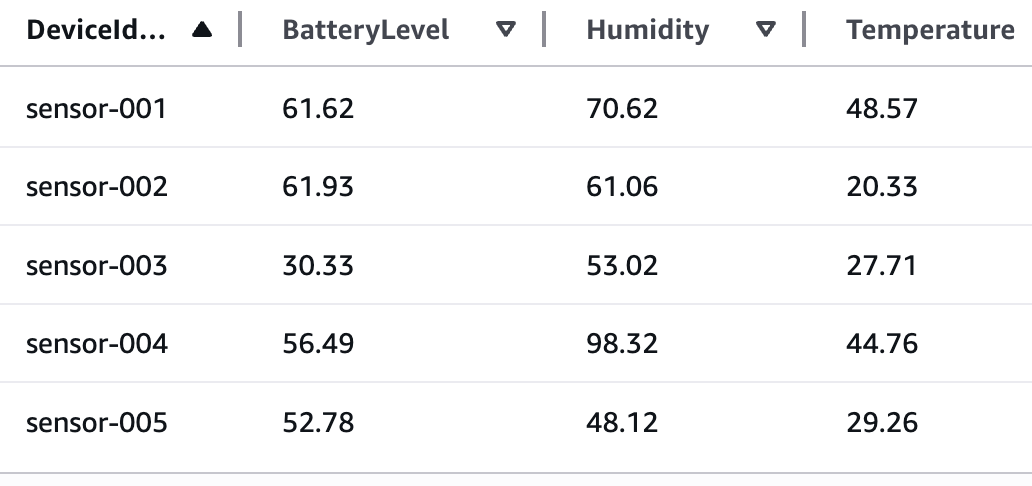
Example IoT sensor data
Your objective is to use the Athena data manifest file, get the list of Parquet files, and iterate over the data in the files to detect anomalies and also stream the processed data through Amazon Kinesis Data Firehose to an Amazon S3 bucket for further analytics using Athena queries. Following is the criteria to detect anomaly:
- Low battery conditions: less than 20%
- Humidity anomalies: more than 95% or less than 5%
- Temperature spikes: more than 35°C or less than -10°C
The following diagram represents the AWS Step Functions state machine:
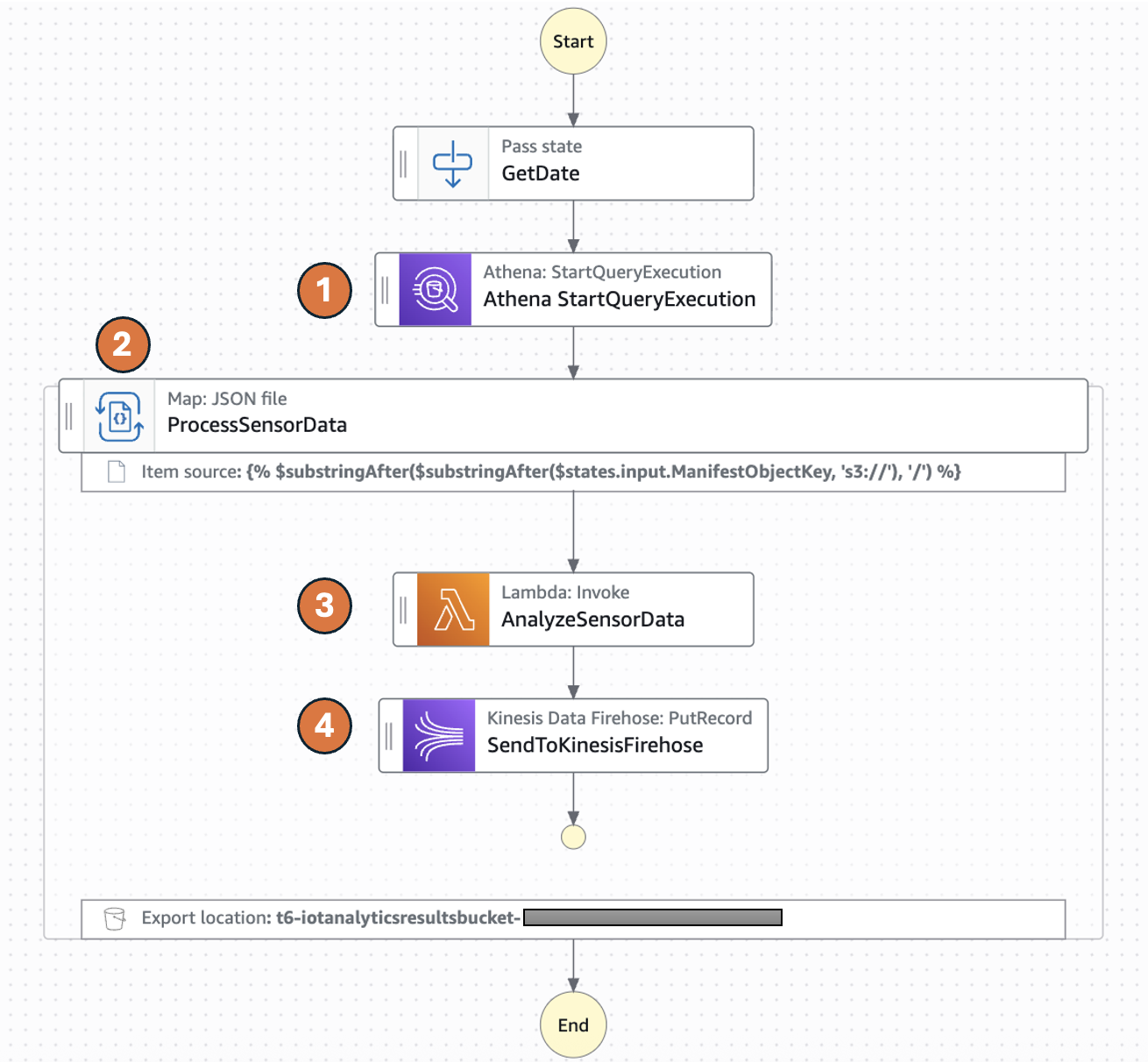
Parquet files processing workflow
- The Distributed Map runs an Athena query which generates Parquet data files and an Athena manifest file (csv). The manifest file contains the list of Parquet data files.
- Distributed Map processes these Parquet data files in parallel using child workflow executions. You can control the number of child workflow executions that can run in parallel using MaxConcurrency parameter. See Step Functions service quotas to learn more about concurrency limits.
- Each child workflow execution invokes an AWS Lambda function to process the respective Parquet file. The Lambda function processes individual sensor readings and detects anomalies according to the preceeding logic and returns a processed sensor data summary response.
- The child workflow sends the summary response record to Amazon Kinesis firehose stream which stores the results in a specified Amazon S3 results bucket.
The following Athena Start QueryExecution state runs an UNLOAD query to generate data files in Parquet format and a manifest file in CSV. The output will be stored in the S3 bucket specified in the UNLOAD query and the manifest file will be stored in the S3 bucket configured for the Athena workgroup.
The following ItemReader is configured to use a manifest type of “ATHENA_DATA” with “PARQUET” data input.
Additional supported InputType options are CSV and JSONL. All objects referenced in a single manifest file must have the same InputType format. You specify the Amazon S3 bucket location of Athena manifest CSV file under Arguments.
The context object contains information in a JSON structure about your state machine and execution. Your workflows can reference the context object in a JSONata expression with $states.context.
Within a Map state, the Context object includes the following data:
For each Map state iteration, Index contains the index number for the array item that is being currently processed, Key is available only when iterating over JSON objects, Value contains the array item being processed, and Source contains one of the following:
- For state input, the value will be : STATE_DATA
- For Amazon S3 LIST_OBJECTS_V2 with Transformation=NONE, the value will show the S3 URI for the bucket. For example: S3://amzn-s3-demo-bucket.
- For all the other input types, the value will be the Amazon S3 URI. For example: S3://amzn-s3-demo-bucket/object-key.
Using this newly introduced Source field in the context object, you can connect the child executions with the source object.
Prerequisites
- Access to an AWS account through the AWS Management Console and the AWS Command Line Interface (AWS CLI). The AWS Identity and Access Management (IAM) user that you use must have permissions to make the necessary AWS service calls and manage AWS resources mentioned in this post. While providing permissions to the IAM user, follow the principle of least-privilege.
- AWS CLI installed and configured. If you are using long-term credentials like access keys, follow manage access keys for IAM users and secure access keys for best practices.
- Git Installed
- AWS Serverless Application Model (AWS SAM) installed
- Python 3.13+ installed
Set up the state machine and sample data
Run the following steps to deploy the Step Functions state machine.
- Clone the GitHub repository in a new folder and navigate to the project root folder.
- Run the following command to install required Python dependencies for the Lambda function.
- Build the application.
- Deploy the application
- Enter the following details:
- Stack name: The CloudFormation stack name (for example, sfn-parquet-file-processor)
- AWS Region: A supported AWS Region (for example, us-east-1)
- Keep rest of the components to default values.
Note the outputs from the AWS SAM deploy. You will use them in the subsequent steps.
- Run the following command to generate sample data in csv format and upload it to an S3 bucket. Replace
<IoTDataBucketName>with the value fromsam deployouptut.
Create the Athena database and tables
Before you can run queries, you must set up an Athena database and table for your data.
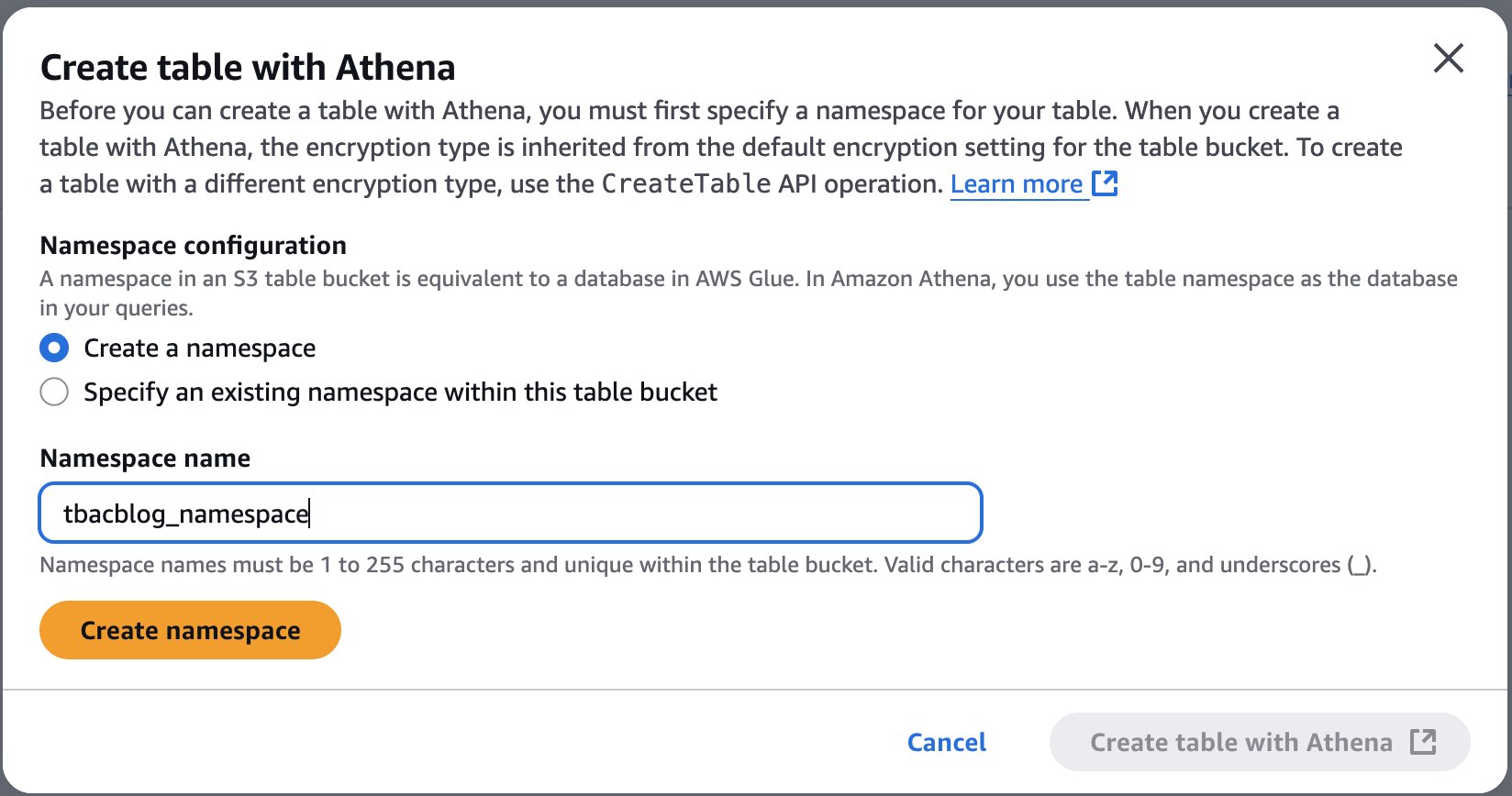
- From Amazon Athena console, navigate to workgoups, select the workgroup named “primary”. Select Edit from Actions. In the query result configuration section, select the options as follows:
- Management of query results – select customer managed
- Location of query results – enter s3://<IoTDataBucketName>. Replace
<IoTDataBucketName>with the value fromsam deployoutput. - Choose Save to save the changes to the workgroup
- Select Query editor tab and run the following commands to create database and tables
- Create an Athena table in database iotsensordata that references the S3 bucket containing the raw sensor data. In this case it will be
<IoTDataBucketName>. Replace<IoTDataBucketName>with the value fromsam deployoutput. - Create an Athena table in database iotsensordata that references the S3 bucket having the analytics results streamed from Kinesis Data Firehose. Replace
<IoTAnalyticsResultsBucket>with value fromsam deployoutput. And replace<year>with the current year (e.g 2025).
Start your state machine
Now that you have data ready and Athena set up for queries, start your state machine to retrieve and process the data.
- Run the following command to start execution of the Step Functions. Replace the
<StateMachineArn>and<IoTDataBucketName>with the value from sam deploy output..The Step Functions state machine has the Athena
StartQueryExecutionstate which has anUNLOADquery that generates the sensor data files in a parquet format and a manifest file in CSV format. The manifest will have 5 rows referencing the 5 parquet files. The state machine will process these 5 parquet files in one map run. - Run the following command to get the details of the execution. Replace the
executionArnfrom the previous command. - After you see the status
SUCCEEDED, run the following command from Athena query editor to check the processed output from Kinesis Data Firehose that was streamed to S3 bucket referenced by the Athena table created in step 4 of the preceding section.
If any of the sensor data exceeds the thresholds, the healthstatus attribute will be set to “anomalies_detected”. The workflow produced a summary table of metadata which you can now query for reporting.
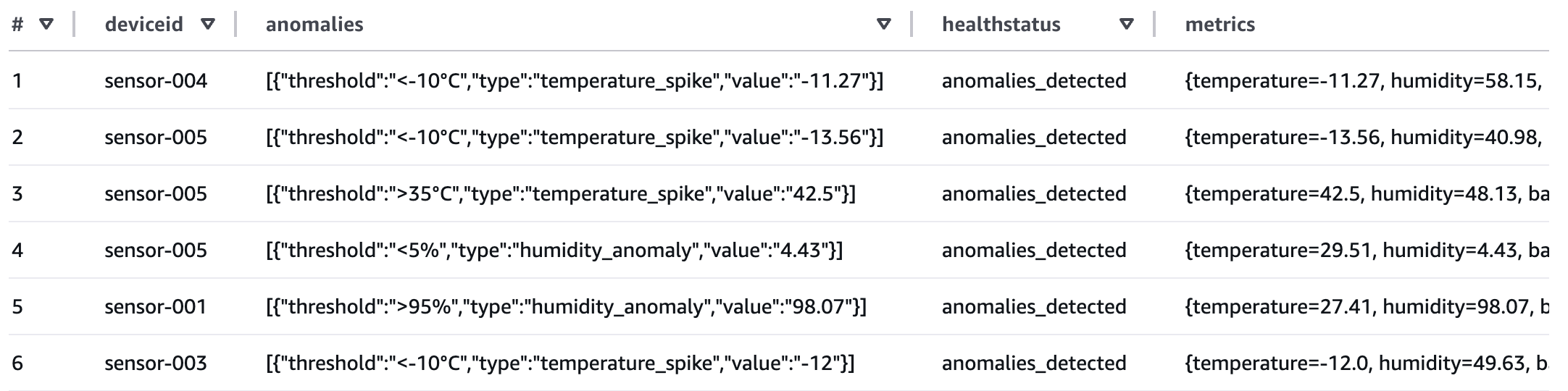
Review workflow performance
Using the following observability metrics, you can review key performance behavior of your data processing workflow.
The AWS/States namespace includes the following new metrics for all Step Functions Map Runs.
OpenMapRunLimit: This is the maximum number of open Map Runs allowed in the AWS account. The default value is 1,000 runs and is a hard limit. For more information, see Quotas related to accounts.ApproximateOpenMapRunCount: This metric tracks the approximate number of Map Runs currently in progress within an account. Configuring an alarm on this metric using the Maximum statistic with a threshold of 900 or higher can help you take proactive action before reaching theOpenMapRunLimitof 1,000. This metric enables operational teams to implement preventive measures, such as staggering new executions or optimizing workflow concurrency, to maintain system stability and prevent backlog accumulation.ApproximateMapRunBacklogSize: This metric shows up when theApproximateOpenMapRunCounthas reached 1,000 and there are backlogged Map Runs waiting to be executed. Backlogged Map Runs wait at the MapRunStarted event until the total number of open Map Runs is less than the quota.
The following graph shows an example of these new metrics. Use the maximum statistic to visualize these metrics. ApproximateMapRunBacklogSize metrics appear after accounts start getting throttled on the OpenMapRunLimit limit. The OpenMapRun (orange line) is the account hard limit of 1,000 shown as a static line. The ApproximateOpenMapRunCount (violet line) is the current number of active OpenMap runs. The ApproximateMapRunBacklogSize (green line) indicates the map runs waiting in backlog to be processed. When the ApproximateOpenMapRunCount is lower than 1000 (OpenMapRun limit) there are no map runs in backlog. However, when the count reaches the OpenMapRun limit, the backlog of map runs starts to build up. After the active runs complete, the backlog will start to drain out and new runs will begin execution.
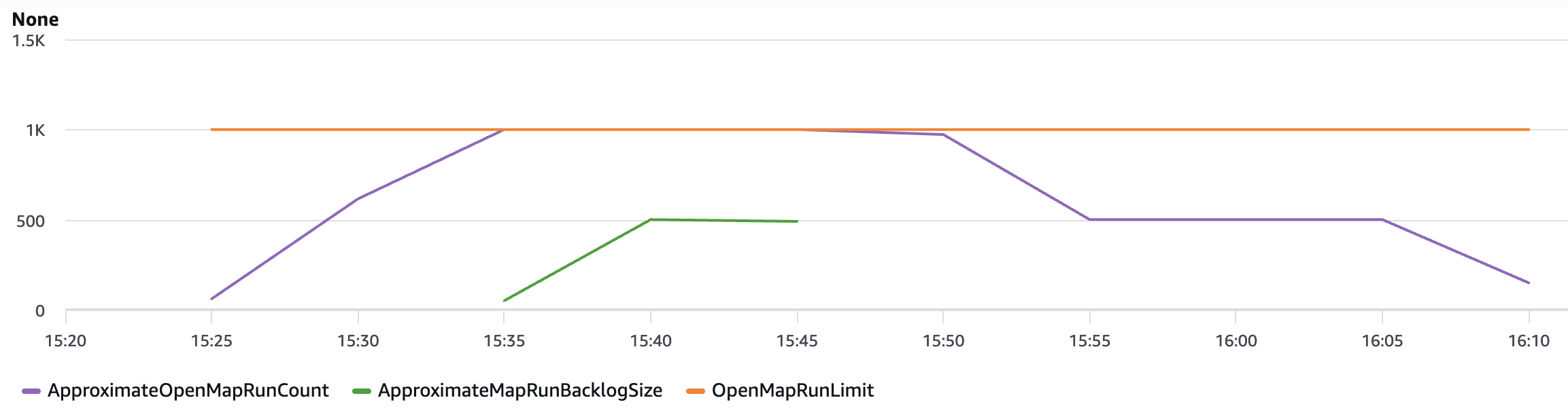
Graphed metrics from Amazon CloudWatch
Clean up
To avoid costs, remove all resources created for this post once you’re done. From the Athena query editor, run the following commands:
Run the following commands from the AWS CLI after replacing the <placeholder> variable to delete the resources you deployed for this post’s solution:
Conclusion
With this update, Distributed Map now supports additional data inputs, so you can orchestrate large-scale analytics and ETL workflows. You can now process Amazon Athena data manifest and Parquet files directly, eliminating the need for custom pre-processing. You also now have visibility into your Distributed Map usage with the following metrics: Approximate Open Map Runs Count, Open Map Run Limit, and Approximate Map Runs Backlog Size.
New input sources for Distributed Map are available in all commercial AWS Regions where AWS Step Functions is available. For a complete list of AWS Regions where Step Functions is available, see the AWS Region Table. The improved observability of your Distributed Map usage with new metrics is available in all AWS Regions. To get started, you can use the Distributed Map mode today in the AWS Step Functions console. To learn more, visit the Step Functions developer guide.
For more serverless learning resources, visit Serverless Land.
 Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager with Amazon SageMaker Lakehouse . Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that help customers improve how they manage, secure, and access data. Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community.
Srividya Parthasarathy is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with the product team and customers to build robust features and solutions for their analytical data platform. She enjoys building data mesh solutions and sharing them with the community. Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.
Aarthi Srinivasan is a Senior Big Data Architect with Amazon SageMaker Lakehouse. She works with AWS customers and partners to architect lakehouse solutions, enhance product features, and establish best practices for data governance.



































 Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy.
Pratik Patel is Sr. Technical Account Manager and streaming analytics specialist. He works with AWS customers and provides ongoing support and technical guidance to help plan and build solutions using best practices and proactively keep customers’ AWS environments operationally healthy. Amar is a seasoned Data Analytics specialist at AWS UK, who helps AWS customers to deliver large-scale data solutions. With deep expertise in AWS analytics and machine learning services, he enables organizations to drive data-driven transformation and innovation. He is passionate about building high-impact solutions and actively engages with the tech community to share knowledge and best practices in data analytics.
Amar is a seasoned Data Analytics specialist at AWS UK, who helps AWS customers to deliver large-scale data solutions. With deep expertise in AWS analytics and machine learning services, he enables organizations to drive data-driven transformation and innovation. He is passionate about building high-impact solutions and actively engages with the tech community to share knowledge and best practices in data analytics. Priyanka Chaudhary is a Senior Solutions Architect and data analytics specialist. She works with AWS customers as their trusted advisor, providing technical guidance and support in building Well-Architected, innovative industry solutions.
Priyanka Chaudhary is a Senior Solutions Architect and data analytics specialist. She works with AWS customers as their trusted advisor, providing technical guidance and support in building Well-Architected, innovative industry solutions.





 Shubham Purwar is an AWS Analytics Specialist Solution Architect. He helps organizations unlock the full potential of their data by designing and implementing scalable, secure, and high-performance analytics solutions on the AWS platform. With deep expertise in AWS analytics services, he collaborates with customers to uncover their distinct business requirements and create customized solutions that deliver actionable insights and drive business growth. In his free time, Shubham loves to spend time with his family and travel around the world.
Shubham Purwar is an AWS Analytics Specialist Solution Architect. He helps organizations unlock the full potential of their data by designing and implementing scalable, secure, and high-performance analytics solutions on the AWS platform. With deep expertise in AWS analytics services, he collaborates with customers to uncover their distinct business requirements and create customized solutions that deliver actionable insights and drive business growth. In his free time, Shubham loves to spend time with his family and travel around the world. Nitin Kumar is a Cloud Engineer (ETL) at AWS, specialized in AWS Glue. With a decade of experience, he excels in aiding customers with their big data workloads, focusing on data processing and analytics. He is committed to helping customers overcome ETL challenges and develop scalable data processing and analytics pipelines on AWS. In his free time, he likes to watch movies and spend time with his family.
Nitin Kumar is a Cloud Engineer (ETL) at AWS, specialized in AWS Glue. With a decade of experience, he excels in aiding customers with their big data workloads, focusing on data processing and analytics. He is committed to helping customers overcome ETL challenges and develop scalable data processing and analytics pipelines on AWS. In his free time, he likes to watch movies and spend time with his family. Prashanthi Chinthala is a Cloud Engineer (DIST) at AWS. She helps customers overcome EMR challenges and develop scalable data processing and analytics pipelines on AWS.
Prashanthi Chinthala is a Cloud Engineer (DIST) at AWS. She helps customers overcome EMR challenges and develop scalable data processing and analytics pipelines on AWS.










 Shuhei Fukami is a Specialist Solutions Architect focused on Analytics with AWS. He likes cooking in his spare time and has become obsessed with making pizza these days.
Shuhei Fukami is a Specialist Solutions Architect focused on Analytics with AWS. He likes cooking in his spare time and has become obsessed with making pizza these days.




















 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.


















 Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga. Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 13 years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking. Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture. Amit Ghodke is an Analytics Specialist Solutions Architect based out of Austin. He has worked with databases, data warehouses and analytical applications for the past 16 years. He loves to help customers implement analytical solutions at scale to derive maximum business value.
Amit Ghodke is an Analytics Specialist Solutions Architect based out of Austin. He has worked with databases, data warehouses and analytical applications for the past 16 years. He loves to help customers implement analytical solutions at scale to derive maximum business value.






 Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through
Navnit Shukla serves as an AWS Specialist Solutions Architect with a focus on Analytics. He possesses a strong enthusiasm for assisting clients in discovering valuable insights from their data. Through his expertise, he constructs innovative solutions that empower businesses to arrive at informed, data-driven choices. Notably, Navnit Shukla is the accomplished author of the book titled Data Wrangling on AWS. He can be reached through  Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to data analytics and artificial intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on data and AI. Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions.
Amit Singh currently serves as a Senior Solutions Architect at AWS, specializing in analytics and IoT technologies. With extensive expertise in designing and implementing large-scale distributed systems, Amit is passionate about empowering clients to drive innovation and achieve business transformation through AWS solutions. Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Technical Product Manager at AWS. Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products that enable customers to improve how they manage, secure, and access data.

 Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform.
Momota Sasaki is an Engineering Manager at DeSC Healthcare, a subsidiary of DeNA. He joined DeNA in 2021 and was seconded to DeSC Healthcare. Since then, he has been consistently involved in the healthcare business, leading and promoting the development and operation of the data platform. Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms.
Kaito Tawara is a Data Engineer at DeSC Healthcare, a subsidiary of DeNA, focusing on improving healthcare data platforms. After gaining experience in backend development for web systems and data science, he transitioned to data engineering. He joined DeNA in 2023 and was seconded to DeSC Healthcare. Currently, he works remotely from Nagoya-city, contributing to the enhancement of healthcare data platforms. Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.
Shota Sato is an Analytics Specialist Solution Architect at AWS Japan, focusing on data analytics solutions powered by AWS for digital native business customers.












 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services. He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services. He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home. Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.












 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike. Giovanni Matteo Fumarola is the Senior Manager for EMR Spark and Iceberg group. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013.
Giovanni Matteo Fumarola is the Senior Manager for EMR Spark and Iceberg group. He is an Apache Hadoop Committer and PMC member. He has been focusing in the big data analytics space since 2013. Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores.
Narayanan Venkateswaran is an Engineer in the AWS EMR group. He works on developing Hive in EMR. He has over 17 years of work experience in the industry across several companies including Sun Microsystems, Microsoft, Amazon and Oracle. Narayanan also holds a PhD in databases with focus on horizontal scalability in relational stores. Karthik Prabhakar is a Senior Analytics Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey.
Karthik Prabhakar is a Senior Analytics Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey.






 Stefano Sandonà is a Senior Big Data Specialist Solution Architect at AWS. Passionate about data, distributed systems, and security, he helps customers worldwide architect high-performance, efficient, and secure data platforms.
Stefano Sandonà is a Senior Big Data Specialist Solution Architect at AWS. Passionate about data, distributed systems, and security, he helps customers worldwide architect high-performance, efficient, and secure data platforms. Francesco Marelli is a Principal Solutions Architect at AWS. He specializes in the design, implementation, and optimization of large-scale data platforms. Francesco leads the AWS Solution Architect (SA) analytics team in Italy. He loves sharing his professional knowledge and is a frequent speaker at AWS events. Francesco is also passionate about music.
Francesco Marelli is a Principal Solutions Architect at AWS. He specializes in the design, implementation, and optimization of large-scale data platforms. Francesco leads the AWS Solution Architect (SA) analytics team in Italy. He loves sharing his professional knowledge and is a frequent speaker at AWS events. Francesco is also passionate about music.






























