Post Syndicated from Tomohiro Tanaka original https://aws.amazon.com/blogs/big-data/introducing-apache-iceberg-materialized-views-in-aws-glue-data-catalog/
Hundreds of thousands of customers build artificial intelligence and machine learning (AI/ML) and analytics applications on AWS, frequently transforming data through multiple stages for improved query performance—from raw data to processed datasets to final analytical tables. Data engineers must solve complex problems, including detecting what data has changed in base tables, writing and maintaining transformation logic, scheduling and orchestrating workflows across dependencies, provisioning and managing compute infrastructure, and troubleshooting failures while monitoring pipeline health. Consider an ecommerce company where data engineers need to continuously merge clickstream logs with orders data for analytics. Each transformation requires building robust change detection mechanisms, writing complex joins and aggregations, coordinating multiple workflow steps, scaling compute resources appropriately, and maintaining operational oversight—all while supporting data quality and pipeline reliability. This complexity demands months of dedicated engineering effort and ongoing maintenance, making data transformation costly and time-intensive for organizations seeking to unlock insights from their data.
To address those challenges, AWS announced a new materialized view capability for Apache Iceberg tables in the AWS Glue Data Catalog. The new materialized view capability simplifies data pipelines and accelerates data lake query performance. A materialized view is a managed table in the AWS Glue Data Catalog that stores pre-computed results of a query in Iceberg format that is incrementally updated to reflect changes to the underlying datasets. This alleviates the need to build and maintain complex data pipelines to generate transformed datasets and accelerate query performance. Apache Spark engines across Amazon Athena, Amazon EMR, and AWS Glue support the new materialized views and intelligently rewrite queries to use materialized views that speed up performance while reducing compute costs.
In this post, we show you how Iceberg materialized view works and how to get started.
How Iceberg materialized views work
Iceberg materialized views offer a simple, managed solution built on familiar SQL syntax. Instead of building complex pipelines, you can create materialized views using standard SQL queries from Spark, transforming data with aggregates, filters, and joins without writing custom data pipelines. Change detection, incremental updates, and monitoring source tables are automatically handled in the AWS Glue Data Catalog and refreshing materialized views as new data arrive, alleviating the need for manual pipeline orchestration. Data transformations run on fully managed compute infrastructure, removing the burden of provisioning, scaling, or maintaining servers.
The resulting pre-computed data is stored as Iceberg tables in an Amazon Simple Storage Service (Amazon S3) general purpose bucket, or Amazon S3 Tables buckets within the your account, making transformed data immediately accessible to multiple query engines, including Athena, Amazon Redshift, and AWS optimized Spark runtime. Spark engines across Athena, Amazon EMR, and AWS Glue support an automatic query rewrite functionality that intelligently uses materialized views, delivering automatic performance improvement for data processing jobs or interactive notebook queries.
In the following sections, we walk through the steps to create, query, and refresh materialized views.
Pre-requisite
To follow along with this post, you must have an AWS account.
To run the instruction on Amazon EMR, complete the following steps to configure the cluster:
- Launch an Amazon EMR cluster 7.12.0 or higher.
- SSH login to the primary node of your Amazon EMR cluster, and run the following command to start a Spark application with required configurations:
To run the instruction on AWS Glue for Spark, complete the following steps to configure the job:
- Create an AWS Glue version 5.1 job or higher.
- Configure a job parameter
- Key:
--conf - Value:
spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
- Key:
- Configure your job with the following script:
- Run the following queries using Spark SQL to set up a base table. In AWS Glue, you can run them through
spark.sql("QUERY STATEMENT").
In the subsequent sections, we create a materialized view with this base table.
If you want to store your materialized views in Amazon S3 Tables instead of a general Amazon S3 bucket, refer to Appendix 1 at the end of this post for the configuration details.
Create a materialized view
To create a materialized view, run the following command:
After you create a materialized view, AWS Spark’s in-memory metadata cache needs time to populate with information about the new materialized view. During this cache population period, queries against the base table will run normally without using the materialized view. After the cache is fully populated (typically within tens of seconds), Spark automatically detects that the materialized view can satisfy the query and rewrites it to use the pre-computed materialized view instead, improving performance.
To see this behavior, run the following EXPLAIN command immediately after creating the materialized view:
The following output shows the initial result before cache population:
In this initial execution plan, Spark scans the base_tbl directly (BatchScan glue_catalog.iceberg_mv.base_tbl) and runs aggregations (COUNT and SUM) on the raw data. This is the behavior before the materialized view metadata cache is populated.
After waiting approximately tens of seconds for the metadata cache population, run the same EXPLAIN command again. The following output shows the primary differences in the query optimization plan after cache population:
After the cache is populated, Spark now scans the materialized view (BatchScan glue_catalog.iceberg_mv.mv) instead of the base table. The query has been automatically rewritten to read from the pre-computed aggregated data in the materialized view. The output specifically shows the aggregation functions now simply sum the pre-computed values (sum(mv_order_count) and sum(mv_total_amount)) rather than recalculating COUNT and SUM from raw data.
Create a materialized view with scheduling automatic refresh
By default, a newly created materialized view contains the initial query results. It’s not automatically updated when the underlying base table data changes. To keep your materialized view synchronized with the base table data, you can configure automatic refresh schedules. To enable automatic refresh, use the REFRESH EVERY clause when creating the materialized view. This clause accepts a time interval and unit, so you can specify how frequently the materialized view is updated.
The following example creates a materialized view that automatically refreshes every 24 hours:
You can configure the refresh interval using any of the following time units: SECONDS, MINUTES, HOURS, or DAYS. Choose an appropriate interval based on your data freshness requirements and query patterns.
If you prefer more control over when your materialized view updates, or need to refresh it outside of the scheduled intervals, you can trigger manual refreshes at any time. We provide detailed instructions on manual refresh options, including full and incremental refresh, later in this post.
Query a materialized view
To query a materialized view on your Amazon EMR cluster and retrieve its aggregated data, you can use a standard SELECT statement:
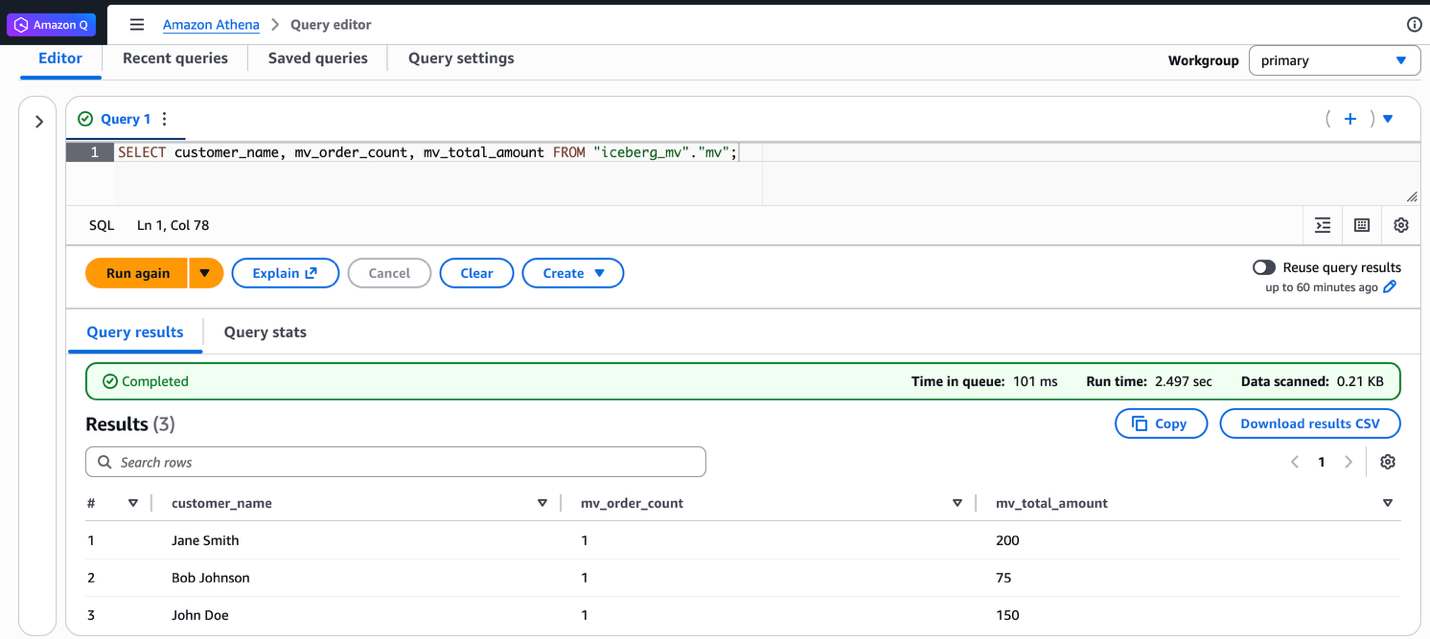
This query retrieves all rows from the materialized view. The output shows the aggregated customer order counts and total amounts. The result displays three customers with their respective metrics:
Additionally, you can query the same materialized view from Athena SQL. The following screenshot shows the same query run on Athena and the resulting output.
Refresh a materialized view
You can refresh materialized views using two refresh types: full refresh or incremental refresh. Full refresh re-computes the entire materialized view from all base table data. Incremental refresh processes only the changes since the last refresh. Full refresh is ideal when you need consistency or after significant data changes. Incremental refresh is preferred when you need immediate updates. The following examples show both refresh types.
To use full refresh, complete the following steps:
- Insert three new records into the base table to simulate new data arriving:
- Query the materialized view to verify it still shows the old aggregated values:
- Run a full refresh of the materialized view using the following command:
- Query the materialized view again to verify the aggregated values now include the new records:
To use incremental refresh, complete the following steps:
- Enable incremental refresh by setting the Spark configuration properties:
- Insert two additional records into the base table:
- Run an incremental refresh using the
REFRESHcommand without theFULLclause. To verify if incremental refresh is enabled, refer to Appendix 2 at the end of this post. - Query the materialized view to confirm the incremental changes are reflected in the aggregated results:
In addition to using Spark SQL, you can also trigger manual refreshes through AWS Glue APIs when you need updates outside your scheduled intervals. Run the following AWS CLI command:
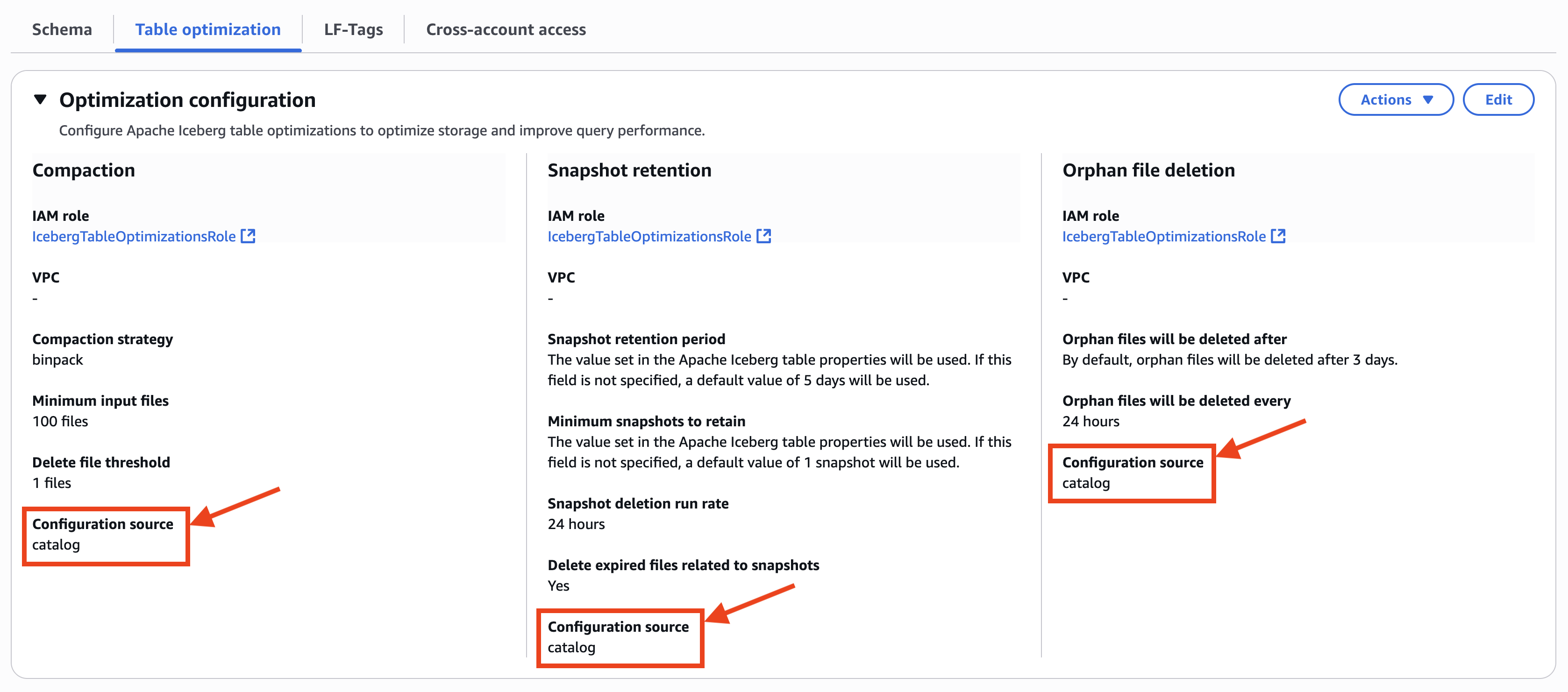
The AWS Lake Formation console displays refresh history for API-triggered updates. Open your materialized view to see the refresh type (INCREMENTAL or FULL), start and end time, status and so on:

You have learned how to use Iceberg materialized views to make your efficient data processing and queries. You created a materialized view using Spark on Amazon EMR, queried it from both Amazon EMR and Athena, and used two refresh mechanisms: full refresh and incremental refresh. Iceberg materialized views help you transform and optimize your data pipelines effortlessly.
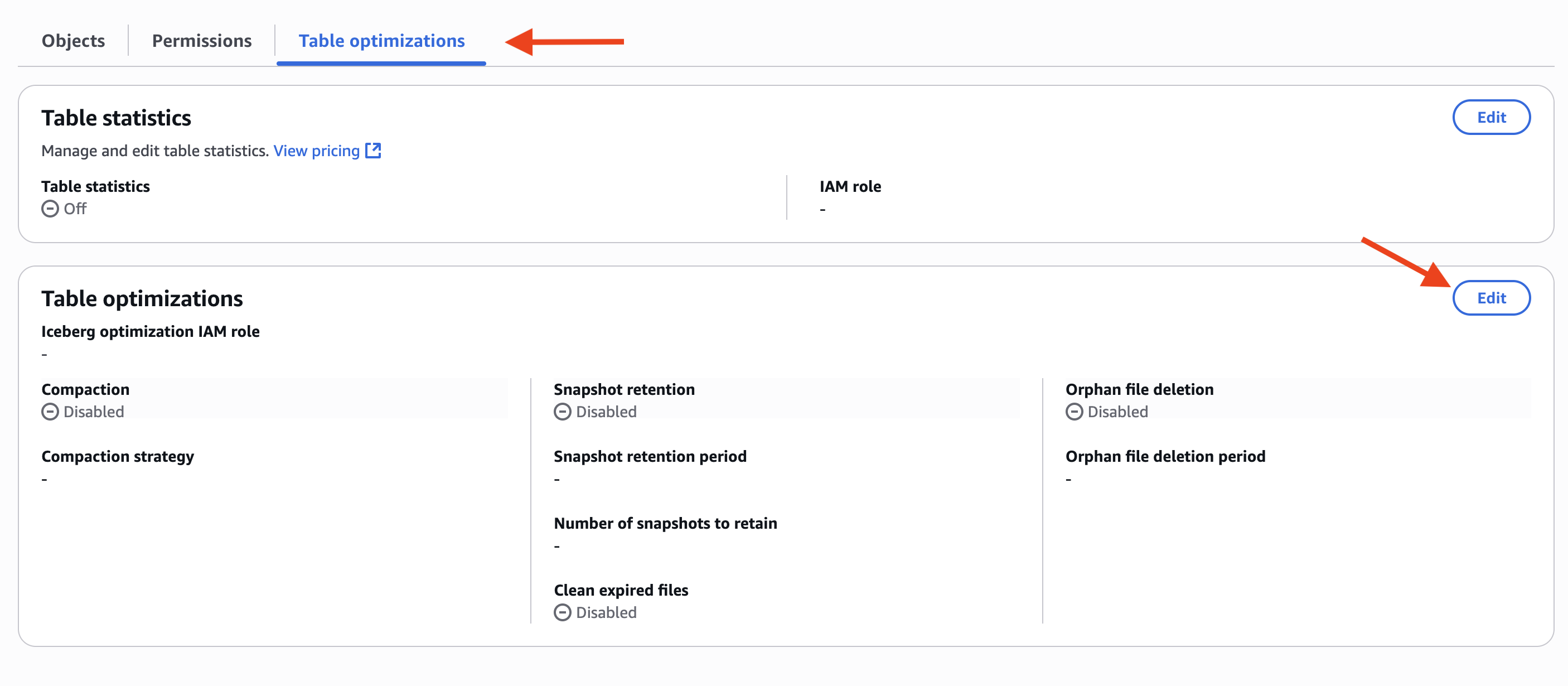
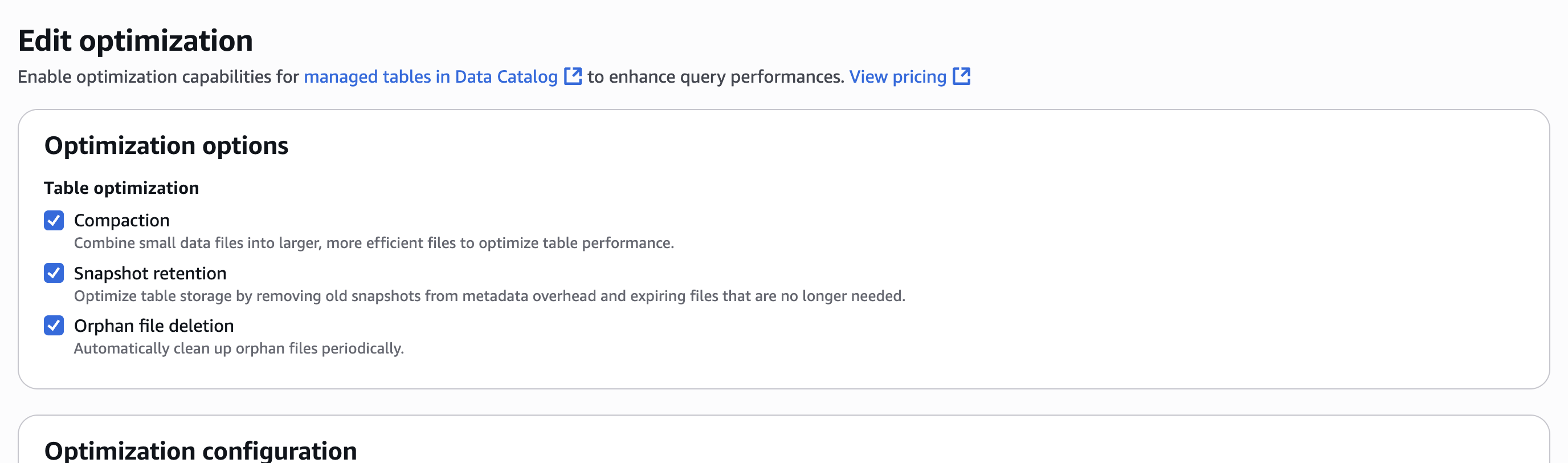
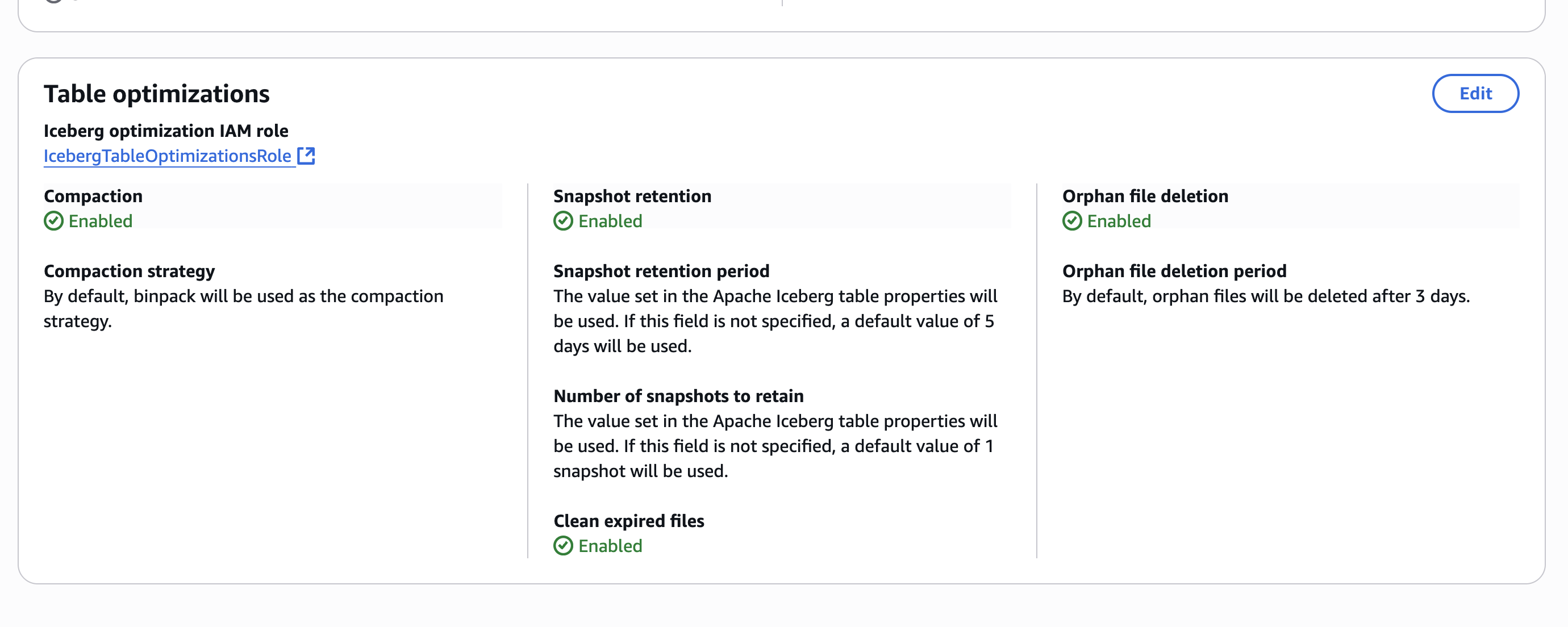
Considerations
There are important aspects to consider for optimal usage of the capability:
- We introduced new SQL syntax to manage materialized views in the AWS optimized Spark runtime engine only. These new SQL commands are available in Spark version 3.5.6 and above across Athena, Amazon EMR, and AWS Glue. Open source Spark is not supported.
- Materialized views are eventually consistent with base tables. When source tables change, the materialized views are updated through background refresh processes as defined by users in the refresh schedule at creation. During the refresh window, queries directly accessing materialized views might see outdated data. However, customers who need immediate access to the most up-to-date datasets can run a manual refresh with a simple
REFRESH MATERIALIZED VIEWSQL command.
Clean up
To avoid incurring future charges, clean up the resources you created during this walkthrough:
- Run the following commands to delete a materialized view and tables:
- For Amazon EMR, terminate the Amazon EMR cluster.
- For AWS Glue, delete the AWS Glue job.
Conclusion
This post demonstrated how Iceberg materialized views facilitate efficient data lake operations on AWS. The new materialized view capability simplifies data pipelines and improves query performance by storing pre-computed results that are automatically updated as base tables change. You can create materialized views using familiar SQL syntax, using both full and incremental refresh mechanisms to maintain data consistency. This solution alleviates the need for complex pipeline maintenance while providing seamless integration with AWS services like Athena, Amazon EMR, and AWS Glue. The automatic query rewrite functionality further optimizes performance by intelligently utilizing materialized views when applicable, making it a powerful tool for organizations looking to streamline their data transformation workflows and accelerate query performance.
Appendix 1: Spark configuration to use Amazon S3 Tables storing Apache Iceberg materialized views
As mentioned earlier in this post, materialized views are stored as Iceberg tables in Amazon S3 Tables buckets within your account. When you want to use Amazon S3 Tables as the storage location for your materialized views instead of a general Amazon S3 bucket, you must configure Spark with the Amazon S3 Tables catalog.
The difference from the standard AWS Glue Data Catalog configuration shown in the prerequisites section is the glue.id parameter format. For Amazon S3 Tables, use the format <account-id>:s3tablescatalog/<s3-tables-bucket-name> instead of just the account ID:
After you configure Spark with these settings, you can create and manage materialized views using the same SQL commands shown in this post, and the materialized views are stored in your Amazon S3 Tables bucket.
Appendix 2: Verify refreshing a materialized view with Spark SQL
Run SHOW TBLPROPERTIES in Spark SQL to check which refresh method was used:


 Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home.
Tomohiro Tanaka is a Senior Cloud Support Engineer at Amazon Web Services (AWS). He’s passionate about helping customers use Apache Iceberg for their data lakes on AWS. In his free time, he enjoys a coffee break with his colleagues and making coffee at home. Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike.
Noritaka Sekiyama is a Principal Big Data Architect with AWS Analytics services. He’s responsible for building software artifacts to help customers. In his spare time, he enjoys cycling on his road bike. Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data.
Sandeep Adwankar is a Senior Product Manager at Amazon Web Services (AWS). Based in the California Bay Area, he works with customers around the globe to translate business and technical requirements into products customers can use to improve how they manage, secure, and access data. Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.
Siddharth Padmanabhan Ramanarayanan is a Senior Software Engineer on the AWS Glue and AWS Lake Formation team, where he focuses on building scalable distributed systems for data analytics workloads. He is passionate about helping customers optimize their cloud infrastructure for performance and cost efficiency.












 Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.
Sotaro Hikita is a Solutions Architect. He supports customers in a wide range of industries, especially the financial industry, to build better solutions. He is particularly passionate about big data technologies and open source software.