Post Syndicated from Valdiney Gomes original https://aws.amazon.com/blogs/big-data/migrate-amazon-redshift-from-dc2-to-ra3-to-accommodate-increasing-data-volumes-and-analytics-demands/
This is a guest post by Valdiney Gomes, Hélio Leal, Flávia Lima, and Fernando Saga from Dafiti.
As businesses strive to make informed decisions, the amount of data being generated and required for analysis is growing exponentially. This trend is no exception for Dafiti, an ecommerce company that recognizes the importance of using data to drive strategic decision-making processes. With the ever-increasing volume of data available, Dafiti faces the challenge of effectively managing and extracting valuable insights from this vast pool of information to gain a competitive edge and make data-driven decisions that align with company business objectives.
Amazon Redshift is widely used for Dafiti’s data analytics, supporting approximately 100,000 daily queries from over 400 users across three countries. These queries include both extract, transform, and load (ETL) and extract, load, and transform (ELT) processes and one-time analytics. Dafiti’s data infrastructure relies heavily on ETL and ELT processes, with approximately 2,500 unique processes run daily. These processes retrieve data from around 90 different data sources, resulting in updating roughly 2,000 tables in the data warehouse and 3,000 external tables in Parquet format, accessed through Amazon Redshift Spectrum and a data lake on Amazon Simple Storage Service (Amazon S3).
The growing need for storage space to maintain data from over 90 sources and the functionality available on the new Amazon Redshift node types, including managed storage, data sharing, and zero-ETL integrations, led us to migrate from DC2 to RA3 nodes.
In this post, we share how we handled the migration process and provide further impressions of our experience.
Amazon Redshift at Dafiti
Amazon Redshift is a fully managed data warehouse service, and was adopted by Dafiti in 2017. Since then, we’ve had the opportunity to follow many innovations and have gone through three different node types. We started with 115 dc2.large nodes and with the launch of Redshift Spectrum and the migration of our cold data to the data lake, then we considerably improved our architecture and migrated to four dc2.8xlarge nodes. RA3 introduced many features, allowing us to scale and pay for computing and storage independently. This is what brought us to the current moment, where we have eight ra3.4xlarge nodes in the production environment and a single node ra3.xlplus cluster for development.
Given our scenario, where we have many data sources and a lot of new data being generated every moment, we came across a problem: the 10 TB we had available in our cluster was insufficient for our needs. Although most of our data is currently in the data lake, more storage space was needed in the data warehouse. This was solved by RA3, which scales compute and storage independently. Also, with zero-ETL, we simplified our data pipelines, ingesting tons of data in near real time from our Amazon Relational Database Service (Amazon RDS) instances, while data sharing enables a data mesh approach.
Migration process to RA3
Our first step towards migration was to understand how the new cluster should be sized; for this, AWS provides a recommendation table.
Given the configuration of our cluster, consisting of four dc2.8xlarge nodes, the recommendation was to switch to ra3.4xlarge.
At this point, one concern we had was regarding reducing the amount of vCPU and memory. With DC2, our four nodes provided a total of 128 vCPUs and 976 GiB; in RA3, even with eight nodes, these values were reduced to 96 vCPUs and 768 GiB. However, the performance was improved, with processing of workloads 40% faster in general.
AWS offers Redshift Test Drive to validate whether the configuration chosen for Amazon Redshift is ideal for your workload before migrating the production environment. At Dafiti, given the particularities of our workload, which gives us some flexibility to make changes to specific windows without affecting the business, it wasn’t necessary to use Redshift Test Drive.
We carried out the migration as follows:
- We created a new cluster with eight ra3.4xlarge nodes from the snapshot of our four-node dc2.8xlarge cluster. This process took around 10 minutes to create the new cluster with 8.75 TB of data.
- We turned off our internal ETL and ELT orchestrator, to prevent our data from being updated during the migration period.
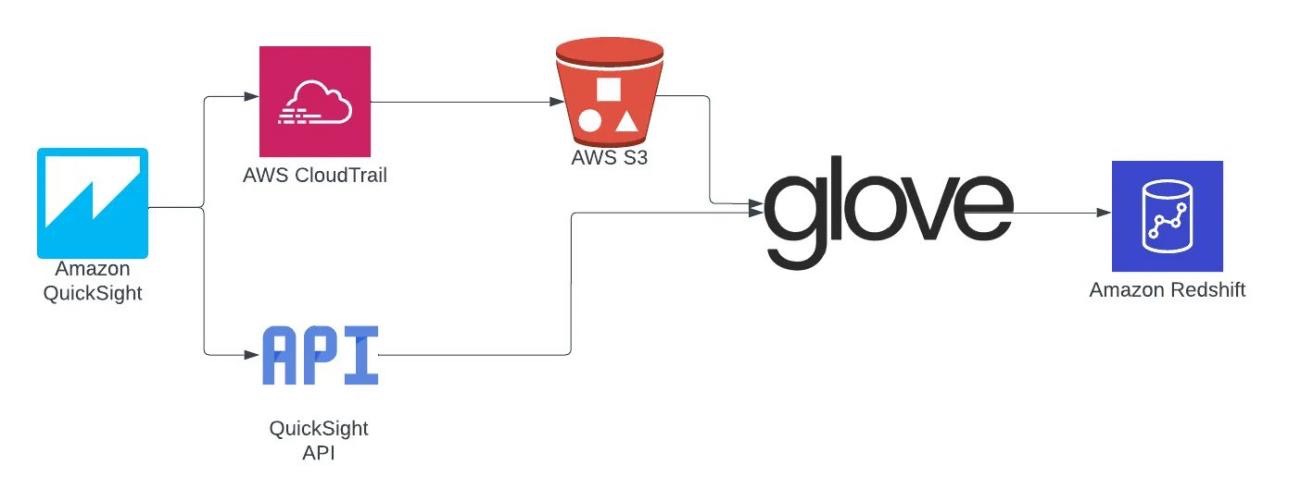
- We changed the DNS pointing to the new cluster in a transparent way for our users. At this point, only one-time queries and those made by Amazon QuickSight reached the new cluster.
- After the read query validation stage was complete and we were satisfied with the performance, we reconnected our orchestrator so that the data transformation queries could be run in the new cluster.
- We removed the DC2 cluster and completed the migration.
The following diagram illustrates the migration architecture.

During the migration, we defined some checkpoints at which a rollback would be performed if something unwanted happened. The first checkpoint was in Step 3, where the reduction in performance in user queries would lead to a rollback. The second checkpoint was in Step 4, if the ETL and ELT processes presented errors or there was a loss of performance compared to the metrics collected from the processes run in DC2. In both cases, the rollback would simply occur by changing the DNS to point to DC2 again, because it would still be possible to rebuild all processes within the defined maintenance window.
Results
The RA3 family introduced many features, allowed scaling, and enabled us to pay for compute and storage independently, which changed the game at Dafiti. Before, we had a cluster that performed as expected, but limited us in terms of storage, requiring daily maintenance to maintain control of disk space.
The RA3 nodes performed better and workloads ran 40% faster in general. It represents a significant decrease in the delivery time of our critical data analytics processes.
This improvement became even more pronounced in the days following the migration, due to the ability in Amazon Redshift to optimize caching, statistics, and apply performance recommendations. Additionally, Amazon Redshift is able to provide recommendations for optimizing our cluster based on our workload demands through Amazon Redshift Advisor recommendations, and offers automatic table optimization, which played a key role in achieving a seamless transition.
Moreover, the storage capacity leap from 10 TB to multiple PB solved Dafiti’s primary challenge of accommodating growing data volumes. This substantial increase in storage capabilities, combined with the unexpected performance enhancements, demonstrated that the migration to RA3 nodes was a successful strategic decision that addressed Dafiti’s evolving data infrastructure requirements.
Data sharing has been used since the moment of migration, to share data between the production and development environment, but the natural evolution is to enable the data mesh at Dafiti through this resource. The limitation we had was the need to activate case sensitivity, which is a prerequisite for data sharing, and which forced us to change some broken processes. But that was nothing compared to the benefits we’re seeing from migrating to RA3.
Conclusion
In this post, we discussed how Dafiti handled migrating to Redshift RA3 nodes, and the benefits of this migration.
Do you want to know more about what we’re doing in the data area at Dafiti? Check out the following resources:
- How Dafiti made Amazon QuickSight its primary data visualization tool
- AWS Summit SP 2022 – Dafiti, habilitando uma Empresa Data Driven na AWS
- Caso de sucesso: Dafiti reduz custos em 70% e otimiza tomadas de decisões com dados na nuvem da AWS
The content and opinions in this post are those of Dafiti’s authors and AWS is not responsible for the content or accuracy of this post.
About the Authors

Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America.

Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions.

Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing data from many sources to internal customers.

Fernando Saga is a data engineer at Dafiti, responsible for maintaining Dafiti’s data platform using AWS solutions.


 Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America.
Valdiney Gomes is Data Engineering Coordinator at Dafiti. He worked for many years in software engineering, migrated to data engineering, and currently leads an amazing team responsible for the data platform for Dafiti in Latin America. Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions.
Hélio Leal is a Data Engineering Specialist at Dafiti, responsible for maintaining and evolving the entire data platform at Dafiti using AWS solutions. Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing the data from many sources to internal customers.
Flávia Lima is a Data Engineer at Dafiti, responsible for sustaining the data platform and providing the data from many sources to internal customers.