Post Syndicated from Zack Koppert original https://github.blog/2024-03-04-keeping-repository-maintainer-information-accurate/
Companies and their structures are always evolving. Regardless of the reason, with people and information exchanging places, it’s easy for maintainership/ownership information about a repository to become outdated or unclear. Maintainers play a crucial role in guiding and stewarding a project, and knowing who they are is essential for efficient collaboration and decision-making. This information can be stored in the CODEOWNERS file but how can we ensure that it’s up to date? Let’s delve into why this matters and how the GitHub OSPO’s tool, cleanowners, can help maintainers achieve accurate ownership information for their projects.
The importance of accurate maintainer information
In any software project, having clear ownership guidelines is crucial for effective collaboration. Maintainers are responsible for reviewing contributions, merging changes, and guiding the project’s direction. Without clear ownership information, contributors may be unsure of who to reach out to for guidance or review. Imagine that you’ve discovered a high-risk security vulnerability and nobody is responding to your pull request to fix it, let alone coordinating that everyone across the company gets the patches needed for fixing it. This ambiguity can lead to delays and confusion, unfortunately teaching teams that it’s better to maintain control than to collaborate. These are not the outcomes we are hoping for as developers, so it’s important for us to consider how we can ensure active maintainership especially of our production components.
CODEOWNERS files
Solving this problem starts with documenting maintainers. A CODEOWNERS file, residing in the root of a repository, allows maintainers to specify individuals or teams who are responsible for reviewing and maintaining specific areas of the codebase. By defining ownership at the file or directory level, CODEOWNERS provides clarity on who is responsible for reviewing changes within each part of the project.
CODEOWNERS not only streamlines the contribution process but also fosters transparency and accountability within the organization. Contributors know exactly who to contact for feedback, escalation, or approval, while maintainers can effectively distribute responsibilities and ensure that every part of the codebase has proper coverage.
Ensuring clean and accurate CODEOWNERS files with cleanowners
While CODEOWNERS is a powerful tool for managing ownership information, maintaining it manually can be tedious and easily-overlooked. To address this challenge, the GitHub OSPO developed cleanowners: a GitHub Action that automates the process of keeping CODEOWNERS files clean and up to date. If it detects that something needs to change, it will open a pull request so this problem gets addressed sooner rather than later.
Here’s how cleanowners works:
---
name: Weekly codeowners cleanup
on:
workflow_dispatch:
schedule:
- cron: '3 2 * * 6'
permissions:
issues: write
jobs:
cleanowners:
name: cleanowners
runs-on: ubuntu-latest
steps:
- name: Run cleanowners action
uses: github/cleanowners@v1
env:
GH_TOKEN: ${{ secrets.GH_TOKEN }}
ORGANIZATION: <YOUR_ORGANIZATION_GOES_HERE>
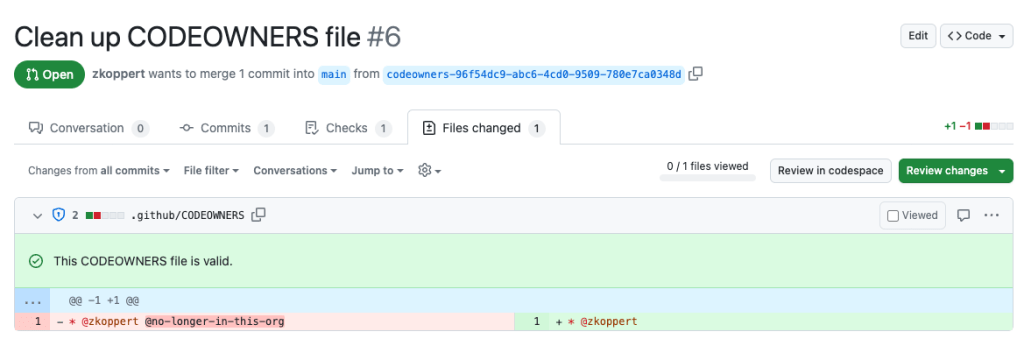
This workflow, triggered by scheduled runs, ensures that the CODEOWNERS file is cleaned automatically. By leveraging cleanowners, maintainers can rest assured that ownership information is accurate, or it will be brought to the attention of the team via an automatic pull request requesting an update to the file. Here is an example where @zkoppert and @no-longer-in-this-org used to both be maintainers, but @no-longer-in-this-org has left the company and no longer maintains this repository.
Dive in
With tools like cleanowners, the task of managing CODEOWNERS files becomes actively managed instead of ignored, allowing maintainers to focus on what matters most: building and nurturing thriving software projects. By embracing clear and accurate ownership documentation practices, software projects can continue to flourish, guided by clear ownership and collaboration principles.
Check out the repository for more information on how to configure and set up the action.
The post Keeping repository maintainer information accurate appeared first on The GitHub Blog.