Post Syndicated from Shaun Wong original https://github.blog/engineering/architecture-optimization/introducing-sub-issues-enhancing-issue-management-on-github/
Recently we launched sub-issues, a feature designed to tackle complex issue management scenarios. This blog post delves into the journey of building sub-issues, what we learned along the way, how we implemented sub-issues, and the benefits of being able to use sub-issues to build itself.
What are sub-issues?
Sub-issues are a way to break a larger issue into smaller, more manageable tasks. With this feature, you can now create hierarchical lists within a single issue, making it easier to track progress and dependencies. By providing a clear structure, sub-issues help teams stay organized and focused on their goals.
For example, I often realize that a batch of work requires multiple steps, like implementing code in different repositories. Breaking this task into discrete sub-issues makes it easier to track progress and more clearly define the work I need to do. In practice we’ve noticed this helps keep linked PRs more concise and easier to review.

A brief history
Issues have long been at the heart of project management on GitHub. From tracking bugs to planning feature development, issues provide a flexible and collaborative way for teams to organize their work. Over time, we’ve enriched this foundation with tools like labels, milestones, and task lists, all to make project management even more intuitive and powerful.
One of the key challenges we set out to solve was how to better represent and manage hierarchical tasks within issues. As projects grow in complexity, breaking down work into smaller, actionable steps becomes essential. We want to empower users to seamlessly manage these nested relationships while maintaining the simplicity and clarity GitHub is known for.
Our journey toward sub-issues began with a fundamental goal: to create a system that integrates deeply into the GitHub Issues experience, enabling users to visually and functionally organize their work without adding unnecessary complexity. Achieving this required careful design and technical innovation.
Building sub-issues
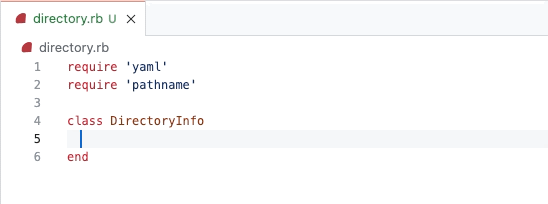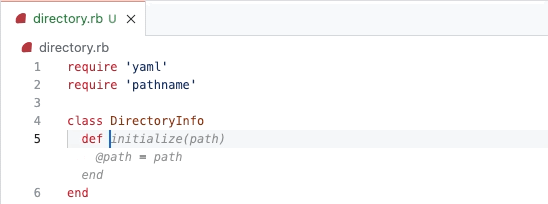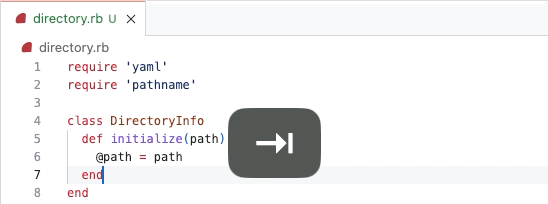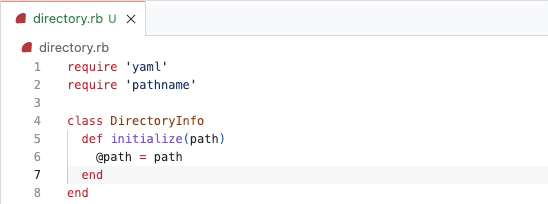
To build sub-issues, we began by designing a new hierarchical structure for tasks rather than modifying the existing task list functionality. We introduced the ability to nest tasks within tasks, creating a hierarchical structure. This required updates to our data models and rendering logic to support nested sub-issues.
From a data modeling perspective, the sub-issues table stores the relationships between parent and child issues. For example, if Issue X is a parent of Issue Y, the sub-issues table would store this link, ensuring the hierarchical relationship is maintained.
In addition, we roll up sub-issue completion information into a sub-issue list table. This allows us to performantly get progress without having to traverse through a list of sub-issues. For instance, when Issue Y is completed, the system automatically updates the progress of Issue X, eliminating the need to manually check the status of all sub-issues.
We wanted a straightforward representation of sub-issues as relationships in MySQL. This approach provided several benefits, including easier support for sub-issues in environments like GitHub Enterprise Server and GitHub Enterprise Cloud with data residency.
We exposed sub-issues through GraphQL endpoints, which let us build upon the new Issues experience and leverage newly crafted list-view components. This approach provided some benefits, including more efficient data fetching and enhanced flexibility in how issue data is queried and displayed. Overall, we could move faster because we reused existing components and leveraged new components that would be used in multiple features. This was all made possible by building sub-issues in the React ecosystem.
We also focused on providing intuitive controls for creating, editing, and managing sub-issues. To this end, we worked closely with accessibility designers and GitHub’s shared components team that built the list view that powers sub-issues.
Our goal was to make it as easy as possible for users to break down their tasks without disrupting their workflow.
Using sub-issues in practice
Dogfooding is a best practice at GitHub and it’s how we build GitHub! We used sub-issues extensively within our own teams throughout the company to manage complex projects and track progress. Having a discrete area to manage our issue hierarchy resulted in a simpler, more performant experience. Through this hands-on experience, we identified areas for improvement and ensured that the feature met our high standards.
Our teams found that sub-Issues significantly improved their ability to manage large projects. By breaking down tasks into smaller, actionable items, they maintained better visibility and control over their work. The hierarchical structure also made it easier to identify dependencies and ensure nothing fell through the cracks.
Gathering early feedback
Building sub-issues was a team effort. Feedback from our beta testers was instrumental in shaping the final product and ensuring it met the needs of our community. For example, understanding how much metadata to display in the sub-issue list was crucial. We initially started with only issue titles, but eventually added the issue number and repository name, if the issue was from another repository.
Building features at GitHub makes it really easy to improve our own features as we go. It was really cool to start breaking down the sub-issues work using sub-issues. This allowed us to experience the feature firsthand and identify any pain points or areas for improvement. For example, the has:sub-issues-progress and has:parent-issue filters evolved from early discussions around filtering syntax. This hands-on approach ensured that we delivered a polished and user-friendly product.
These lessons have been invaluable in not only improving sub-issues, but also in shaping our approach to future feature development. By involving users early and actively using our own features, we can continue to build products that truly meet the needs of our community. These practices will be important to our development process going forward, ensuring that we deliver high-quality, user-centric solutions.
Call to action
Sub-issues are designed to help you break down complex tasks into manageable pieces, providing clarity and structure to your workflows. Whether you’re tracking dependencies, managing progress, or organizing cross-repository work, sub-issues offer a powerful way to stay on top of your projects.
We’d love for you to try sub-issues and see how they can improve your workflow. Your feedback is invaluable in helping us refine and enhance this feature. Join the conversation in our community discussion to share your thoughts, experiences, and suggestions.
Thank you for being an integral part of the GitHub community. Together, we’re shaping the future of collaborative development!
The post Introducing sub-issues: Enhancing issue management on GitHub appeared first on The GitHub Blog.






 Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it
Summarization is a core workflow for AI, and so far, while it’s not always perfect, it’s been working well. If you’re interested in the prompt we’re using (or want to help us improve it!), you can find it