Post Syndicated from Matt Bullock original http://blog.cloudflare.com/cloudflare-fonts-enhancing-website-privacy-speed/


We are thrilled to introduce Cloudflare Fonts! In the coming weeks sites that use Google Fonts will be able to effortlessly load their fonts from the site’s own domain rather than from Google. All at a click of a button. This enhances both privacy and performance. It enhances users' privacy by eliminating the need to load fonts from Google’s third-party servers. It boosts a site's performance by bringing fonts closer to end users, reducing the time spent on DNS lookups and TLS connections.
Sites that currently use Google Fonts will not need to self-host fonts or make complex code changes to benefit – Cloudflare Fonts streamlines the entire process, making it a breeze.
Fonts and privacy
When you load fonts from Google, your website initiates a data exchange with Google's servers. This means that your visitors' browsers send requests directly to Google. Consequently, Google has the potential to accumulate a range of data, including IP addresses, user agents (formatted descriptions of the browser and operating system), the referer (the page on which the Google font is to be displayed) and how often each IP makes requests to Google. While Google states that they do not use this data for targeted advertising or set cookies, any time you can prevent sharing your end user’s personal data unnecessarily is a win for privacy.
With Cloudflare Fonts, when you serve fonts directly from your own domain. This means no font requests are sent to third-party domains like Google, which some privacy regulators have found to be a problem in the past. Our pro-privacy approach means your end user’s IP address and other data are not sent to another domain. All that information stays within your control, within your domain. In addition, because Cloudflare Fonts eliminates data transmission to third-party servers like Google's, this can enhance your ability to comply with any potential data localization requirements.
Faster Google Font delivery through Cloudflare
Now that we have established that Cloudflare Fonts can improve your privacy, let's flip to the other side of the coin – how Cloudflare Fonts will improve your performance.
To do this, we first need to delve into how Google Fonts affects your website's performance. Subsequently, we'll explore how Cloudflare Fonts addresses and rectifies these performance challenges.
Google Fonts is a fantastic resource that offers website owners a range of royalty-free fonts for website usage. When you decide on the fonts you would like to incorporate, it’s super easy to integrate. You just add a snippet of HTML to your site. You then add styles to apply these fonts to various parts of your page:
<link href="https://fonts.googleapis.com/css?family=Open+Sans|Roboto+Slab" rel="stylesheet">
<style>
body {
font-family: 'Open Sans', sans-serif;
}
h1 {
font-family: 'Roboto Slab', serif;
}
</style>
But this ease of use comes with a performance penalty.
Upon loading your webpage, your visitors' browser fetches the CSS file as soon as the HTML starts to be parsed. Then, when the browser starts rendering the page and identifies the need for fonts in different text sections, it requests the required font files.
This is where the performance problem arises. Google Fonts employs a two-domain system: the CSS resides on one domain – fonts.googleapis.com – while the font files reside on another domain – fonts.gstatic.com.
This separation results in a minimum of four round trips to the third-party servers for each resource request. These round trips are DNS lookup, socket connection establishment, TLS negotiation (for HTTPS), and the final round trip for the actual resource request. Ultimately, getting a font from Google servers to a browser requires eight round trips.
Users can see this. If they are using Google Fonts they can open their network tab and filter for these Google domains.
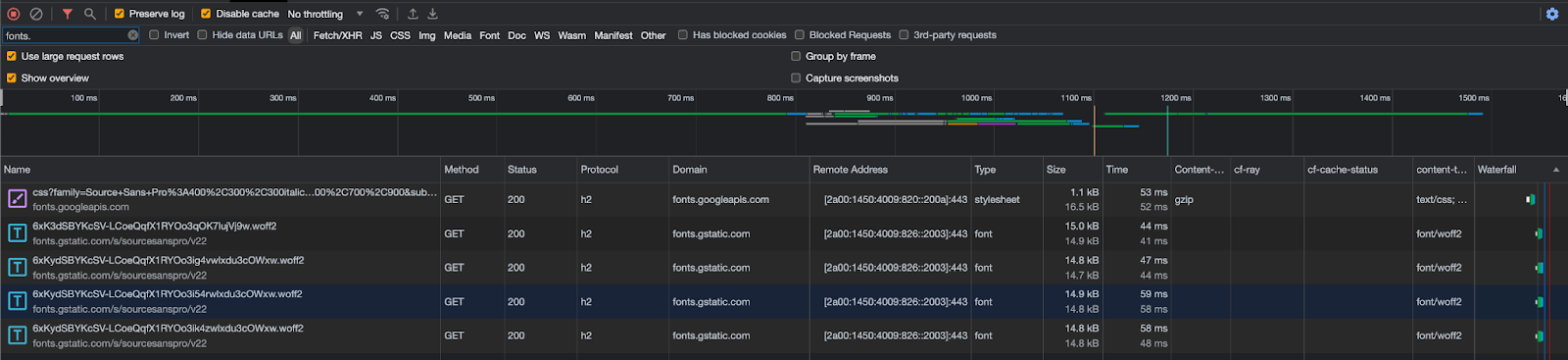
You can visually see the impact of the extra DNS request and TLS connection that these requests add to your website experience. For example on my WordPress site that natively uses Google Fonts as part of the theme adds an extra ~150ms.
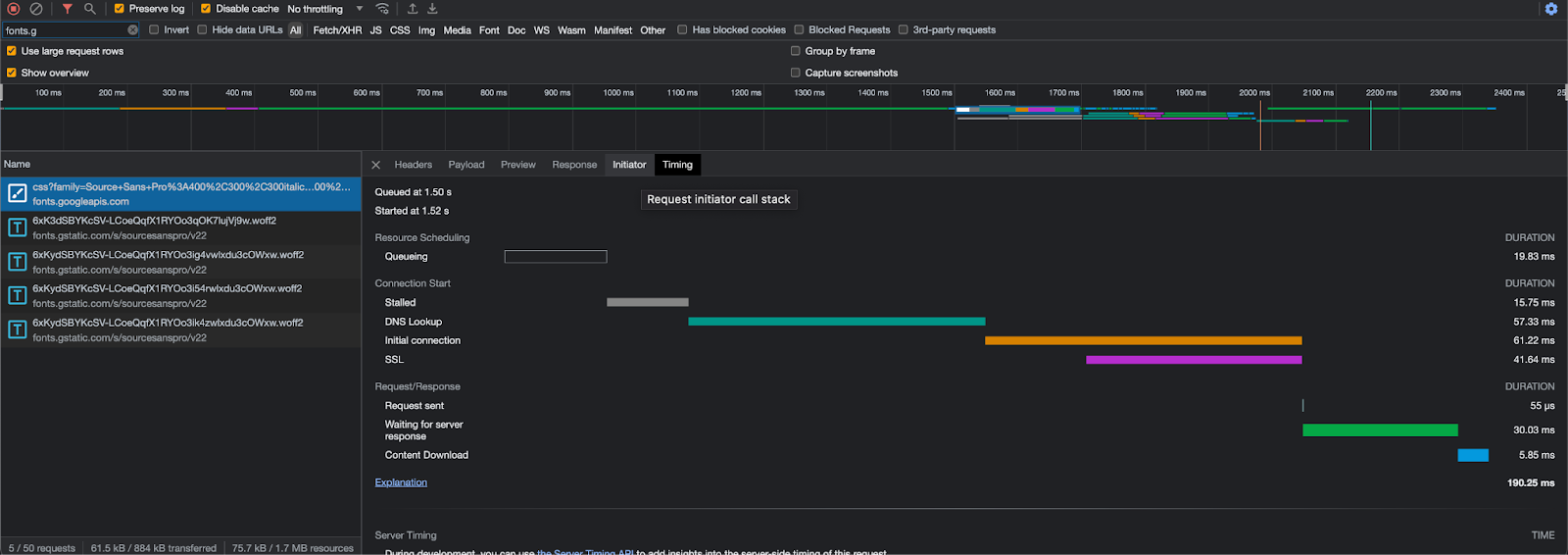
Fast fonts
Cloudflare Fonts streamlines this process, by reducing the number of round trips from eight to one. Two sets of DNS lookups, socket connections and TLS negotiations to third-parties are no longer required because there is no longer a third-party server involved in serving the CSS or the fonts. The only round trip involves serving the font files directly from the same domain where the HTML is hosted. This approach offers an additional advantage: it allows fonts to be transmitted over the same HTTP/2 or HTTP/3 connection as other page resources, benefiting from proper prioritization and preventing bandwidth contention.
The eagle-eyed amongst you might be thinking “Surely it is still two round trips – what about the CSS request?”. Well, with Cloudflare Fonts, we have also removed the need for a separate CSS request. This means there really is only one round-trip – fetching the font itself.
To achieve both the home-routing of font requests and the removal of the CSS request, we rewrite the HTML as it passes through Cloudflare’s global network. The CSS response is embedded, and font URL transformations are performed within the embedded CSS.
These transformations adjust the font URLs to align with the same domain as the HTML content. These modified responses seamlessly pass through Cloudflare's caching infrastructure, where they are automatically cached for a substantial performance boost. In the event of any cache misses, we use Fontsource and NPM to load these fonts and cache them within the Cloudflare infrastructure. This approach ensures that there's no inadvertent data exposure to Google's infrastructure, maintaining both performance and data privacy.
With Cloudflare Fonts enabled, you are able to see within your Network Tab that font files are now loaded from your own hostname from the /cf-fonts path and served from Cloudflare’s closest cache to the user, as indicated by the cf-cache-status: HIT.
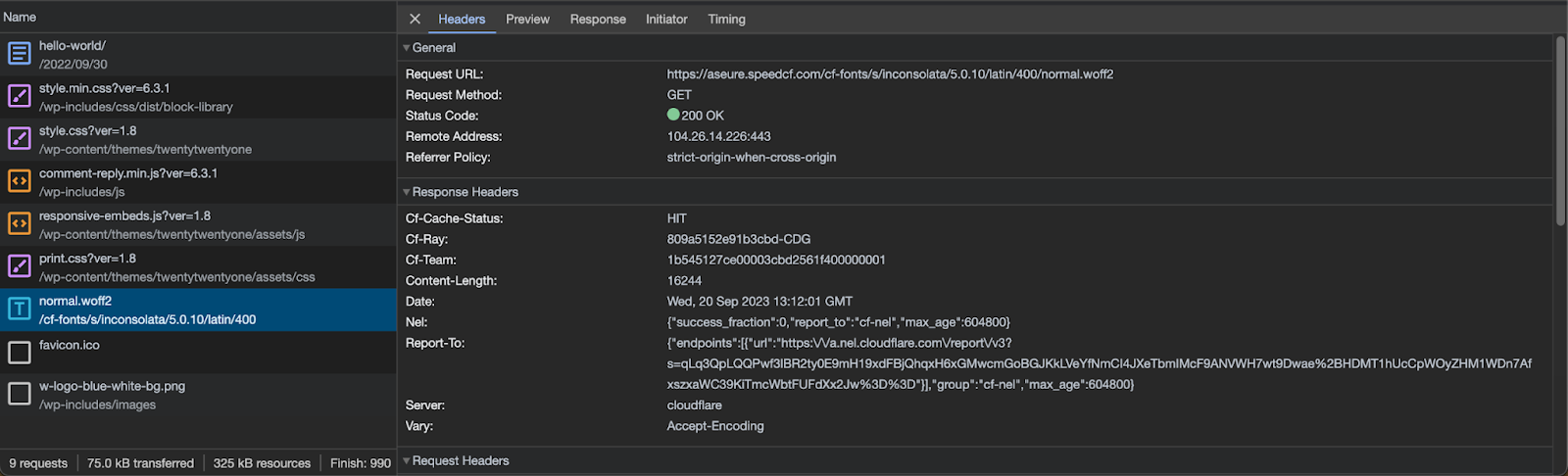
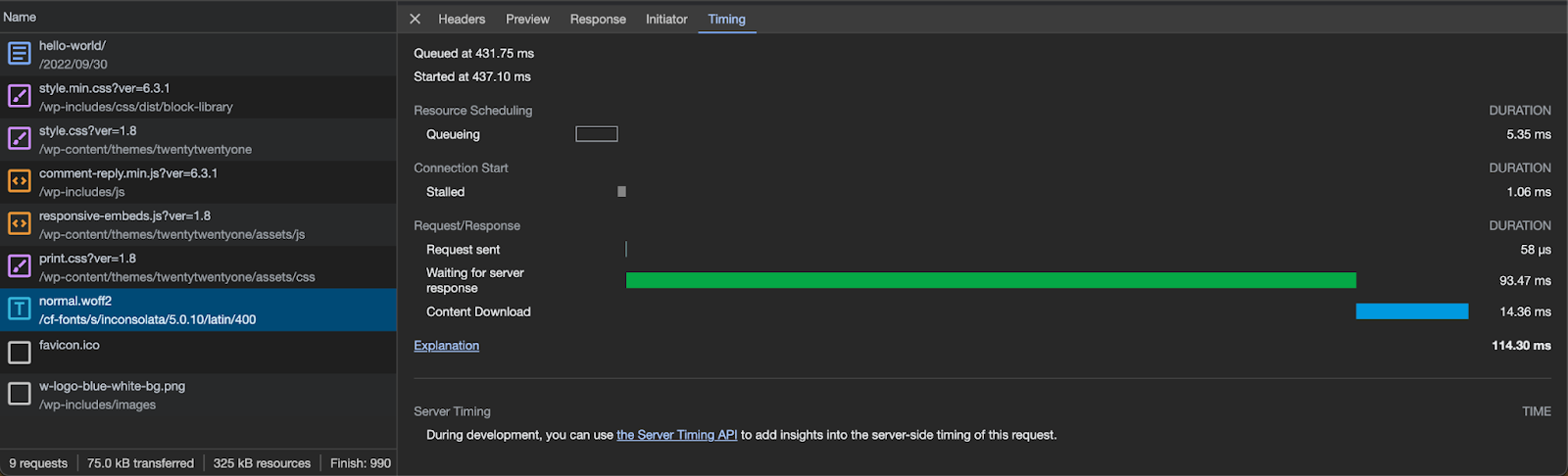
Additionally, you can notice that the timings section in the browser no longer needs an extra DNS lookup for the hostname or the setup of a TLS connection. This happens because the content is served from your hostname, and the browser has already cached the DNS response and has an open TLS connection.
Finally, you can see the real-world performance benefits of Cloudflare Fonts. We conducted synthetic Google Lighthouse tests before enabling Cloudflare Fonts on a straightforward page that displays text. First Contentful Paint (FCP), which represents the time it takes for the first content element to appear on the page, was measured at 0.9 seconds in the Google fonts tests. After enabling Cloudflare Fonts, the First Contentful Paint (FCP) was reduced to 0.3 seconds, and our overall Lighthouse performance score improved from 98 to a perfect 100 out of 100.

Making Cloudflare Fonts fast with ROFL
In order to make Cloudflare Fonts this performant, we needed to make blazing-fast HTML alterations as responses stream through Cloudflare’s network. This has been made possible by leveraging one of Cloudflare’s more recent technologies.
Earlier this year, we finished rewriting one of Cloudflare's oldest components, which played a crucial role in dynamically altering HTML content. But as described in this blog post, a new solution was required to replace the old – A memory-safe solution, able to scale to Cloudflare’s ever-increasing load.
This new module is known as ROFL (Response Overseer for FL). It now powers various Cloudflare products that need to alter HTML as it streams, such as Email Obfuscation, Rocket Loader, and HTML Minification.
ROFL was developed entirely in Rust. This decision was driven by Rust's memory safety, performance, and security. The memory-safety features of Rust are indispensable to ensure airtight protection against memory leaks while we process a staggering volume of requests, measuring in the millions per second. Rust's compiled nature allows us to finely optimize our code for specific hardware configurations, delivering impressive performance gains compared to interpreted languages.
ROFL paved the way for the development of Cloudflare Fonts. The performance of ROFL allows us to rewrite HTML on-the-fly and modify the Google Fonts links quickly, safely and efficiently. This speed helps us reduce any additional latency added by processing the HTML file and improve the performance of your website.
Unlock the power of Cloudflare Fonts today! 🚀
Cloudflare Fonts will be available to all Cloudflare customers in October. If you're using Google Fonts, you will be able to supercharge your site's privacy and speed. By enabling this feature, you can seamlessly enhance your website's performance while safeguarding your user’s privacy.