Post Syndicated from Йоанна Елми original https://www.toest.bg/evolyutsiya-na-dezinformatsiyata-kogato-naukata-stane-propaganda/

Показват ли данните, че украинците мразят Зеленски? Събужда ли се опасен вирус, който ще ни погуби? Виновен ли е човекът за климатичните промени? Ще навлезе ли страната ни в нова ледникова епоха? Каква е червената светлина в небето над България? Всички тези въпроси гъделичкат човешкия ни интерес – дали защото засягат актуални новини, защото се страхуваме за здравето си или бъдещето на България, или защото не всеки ден се случва небето да почервенее. Отговорите ни зависят до голяма степен от това какви медии четем.
Тук се появяват редица съвети: проверявайте източниците, не четете само заглавието, проверете автора. От коя дата е статията? Сатирична ли е? Позовава ли се на експерти? Пространството е наситено с всякакви заглавия, като „Х начина да разпознавате фалшиви новини“ – има ли я новината и другаде, какви са доказателствата… Вече всички говорят за дезинформация: експерти и граждански активисти, компетентни и недотам компетентни лица, а дори и самите източници на дезинформация, които обвиняват мишените на своята пропаганда в разпространение на манипулативно съдържание.
Може ли обаче дадено съдържание да отговаря на всички критерии за „добри практики“ и все пак да бъде невярно? А възможно ли е нещо повече – да се позовава на съвсем легитимни медии, статистики и научни източници и пак да не представя информацията такава, каквато е?
Качествен анализ на съдържанието на конкретни статии в български медии показва именно такива тенденции. Реални данни и истинска информация от надеждни източници са използвани или в комбинация с невярна информация, или са представени с умишлено превратно тълкуване.
В рамките на анализа бяха откроени конкретни начини, по които изначално вярно съдържание може да бъде манипулирано, за да се постигне определено внушение.

- Черипикинг. Посочват се определени случаи и данни, които се стремят да потвърдят дадена теза (например украинците са причина за престъпността в Полша), но се игнорира цялостната картина (украинците са много малко парченце от пъзела на престъпността в Полша). Тази техника включва и препубликуването само на определен тип проучвания или статии – например такива, които по някакъв начин представят държави от Европейския съюз в негативна светлина. Съдържанието на материалите не се променя, но се публикува, без да се спомене, да речем, какви са мерките, които се вземат за справяне с описаните проблеми, или какъв е по-широкият контекст.
- Превратно тълкуване/цитиране на реномирани източници. Цитират се легитимни източници и такива, познати на широката аудитория (например списание „Форбс“ относно използването на дронове от руската и украинската армия), но съдържанието на техните материали се представя или се тълкува превратно (за да се изтъкне предимството на Русия, какъвто акцент липсва в оригиналната статия).
- Абстрактно позоваване на авторитети. Използват се ключови думи и фрази като „учените казаха“, „експерти посочват“, „официалните данни“, „доказателствата сочат“, но без конкретно да се назовават имена, позиции, учреждения и без да се дават линкове към оригиналните източници.
- Директно позоваване на авторитети. Споменават се истински фондации, медии, изследователски институции, университети и дори учени без директна връзка към оригиналния източник и без широк контекст на информацията, която се представя. Често се комбинира с черипикинг и превратно тълкуване.
- Позоваване на фалшиви авторитети. Представя се превод, цитиране и публикации от мними институти, нелегитимни организации за работа с данни и информация, псевдоексперти, задкулисно политически обвързани лица и хора, които се представят за изследователи, без да са част от научни институти или академични структури.
- Използване на емоционален език и ключови емоционални формули. Залага се на провокативен език, който често намеква за нещо скрито или скандално, за някаква ексклузивна тайна, до която ще получите достъп само вие („подозират САЩ“, „Форбс“ разкри“). Често се ползват и конкретни думи, които вдъхват страх или гняв („опасен вирус“, „учените бият тревога“, „разгневиха Запада“, „вулканът чудовище“, „смразяващи данни“).
- Представяне за алтернатива. Редица източници на манипулативно съдържание се позиционират като „алтернатива“ на традиционните медии. Но нашият анализ показва, че в повечето случаи „алтернативните“ медии цитират същия „мейнстрийм“, за който иначе твърдят, че уж лъже читателите и крие нещо от тях. Чрез директното позоваване на тези медийни авторитети те придават тежест на твърденията си, а чрез използването на други изброени тук похвати постигат определено внушение в рамките на достоверната информация. В крайна сметка обаче се оказва, че „алтернативата“ е просто превратно тълкуване на легитимна информация, което не издържа критически прочит, анализ и проверка на фактите.
- Комплекс на героя. Тази стратегия използва ключови провокативни фрази, които създават усещане за лична отговорност и мисия – „разберете истината сами“, „но това ли е цялата истина“, „те няма да ви кажат всичко“. Така на читателя се внушава не само че не трябва да има доверие на никого, но и че не е необходимо да е специалист в определена сфера или да присъства на терен, за да разбере дадена информация – може просто да прави „собствени проучвания“. Това, разбира се, означава да чете поднесената му от някой друг информация в „алтернативни“ платформи, представящи себе си като носители на цялата истина. Читателят също не трябва да вярва на реномирани институции и учени – само на онези, които му препоръчва конспиративният източник. Той може да си „прецени сам“ – разбира се, чрез информацията и мненията на „алтернативните“.
- Бомбардиране с информация. Изреждат се множество данни, източници, имена и информация, често дори без привидна логическа свързаност. Читателят често няма нито времето, нито познанията да провери цялата информация. Така например в материал в pogled.info, за който не е обявено, че е препечатка от медия – собственост на руския политик и член на „Единна Русия“ Константин Риков, четем за посещение на президента на Парагвай в САЩ, за британска биокомпания, американски агенции, генно модифициране, „европейски учени от Института за еволюционна биология Макс Планк в Пльон (Германия) и Университета в Монпелие (Франция)“, както и за „юристи от Университета във Фрайбург“, „Университета на Пенсилвания“ и „испанския „Ел Пайс“*… Всички те са използвани и цитирани избирателно, за да се постигне финално внушение, че светът е застрашен от „военна употреба на комари мутанти“, което не отговаря на истината. Страхът от чума или насекоми е пропаганден троп още от времето на СССР, а дезинформацията, свързана с генномодифицирани продукти, е феномен от поне десетилетие.
- Допълване на разказа. Актуални новини, официални данни, доклади могат да бъдат използвани и разтълкувани предубедено, за да допълнят вече съществуващи неверни обяснения на събитията. Можем да си представим човешката мисъл като верига от понятия, спомени и вярвания – рационални и емоционални, – на които разчитаме, за да си създаваме нова информация за света и да се оправяме в него. Тактиката с допълване на разказа се възползва именно от тази особеност на човешкото мислене. В повечето изследвани статии фигурират ключови думи, свързани със системно опровергавани или откровено конспиративни твърдения, като „зеления дневен ред“, „генетично модифицирани същества“, „ХААРП контролира времето“ и т.н. Срещат се и други, свързани с експлоатирането на наболели проблеми от недоброжелатели: „продажните елити“ около теми като неравенствата и икономическата криза, „цензурата“ около борбата с манипулативното съдържание и езика на омразата. Така ако читателят има съмнения относно безопасността на ГМО храните или изпитва недоверие към институциите, или пък ако преди това е повярвал на друго манипулативно съдържание, такъв тип статии го въвличат още по-надълбоко в лесните черно-бели обяснения, които водят до цяла алтернативна реалност.
- Криво огледало. Използват се легитимни термини като „разобличител“ (whistleblower), „дезинформация“, „проверители на факти“ или „пропаганда“ от източници, които произвеждат дезинформация и пропаганда. Пример е представянето на анонимно видео в YouTube като легитимен акт на „разобличител“.
Изброените техники се използват в различни комбинации и степени, за да се постигне крайният резултат – напълно легитимно изглеждаща статия или пост в социалните мрежи, които незапознатият потребител трудно би могъл да различи от вярна и коректно поднесена информация.
Сайтът pogled.info препубликува основно руски източници, които добавят свои коментари към реални данни на информационни агенции от калибъра на „Ройтерс“. Никъде не се посочва, че информацията е преводна от руски. Често парчета от тези статии се публикуват и в социалните мрежи или се „рециклират“ в други публикации.
Други сайтове, като epicenter.bg, пък препубликуват резюмета на проучвания, като повечето материали са посветени на съвсем легитимни проблеми в Германия или Великобритания – например расизма и безработицата. Така „Западът“ се обрисува като лошо място, в което върлуват бедност, беззаконие и всякакви проблеми. Главен редактор на „Епицентър“ е Валерия Велева – дългогодишна журналистка, приближена до ДПС, която често присъства в медийното пространство с политически анализи и коментари в подкрепа на партията.
Някои от изброените примери може да илюстрираме, разглеждайки подробно статия, разказваща как украинските бежанци „са съсипали“ Полша.
Полша – криминален център на Европа?
На пръв поглед – чуждестранна медия с притеснителни данни
На 12 ноември 2023 г. българското онлайн издание NewsFront пише, че Полша се е превърнала в „криминален център за пране на пари, трафик на деца и наркотици, както и черен пазар за оръжия“. За това са обвинени украинските бежанци. Материалът е препубликуван и в друг български сайт – classa.bg. За първоизточник е посочен полският новинарски уебсайт Dziennik Polityczny (цитиран и с абревиатурата NDP).
В статията са публикувани статистически „официални“ данни, както и сведения за полицейски операции, описани по дати и места. Материалът завършва с история за „френския репортер Робърт Шмид“ и неговото „журналистическо разследване“, което е разкрило информация за фондацията на съпругата на Володимир Зеленски – Олена. За разследването се уточнява, че са предоставени „десетки писма, маршрути, адреси и други вътрешни документи на фондацията“.
Източникът – руска фондация с множество дезинформационни сайтове
Средностатистическият читател надали ще знае, че NewsFront всъщност е част от руската фондация ООО „МедиаГрупп Ньюс Фронт“, регистрирана в Симферопол, Крим. Сайтът предлага т.нар. infinite scroll, или безкрайно зареждане на статия след статия, което прави трудно достигането до секция „За нас“, в която така или иначе няма информация за конкретни лица и автори.
Онова, което вижда читателят в статията, са цитати от чуждестранна медия, данни и описания на привидно конкретни случки и действия на полицията. В допълнение му е разказано и за разследване, уж подкрепено с редица автентични документи и доказателства. Ако той следва съветите за проверка на съдържание, които изредихме в началото на текста, статията би трябвало да му се стори напълно достоверна.
Но текстът на NewsFront използва амалгама от реални факти, фабрикувани твърдения и превратно тълкуване, за да насажда негативно отношение спрямо украинските бежанци, които са представени като престъпници.
Да изфабрикуваш реалност
Манипулативно твърдение: „мощна вълна от бежанци“, която омаломощава страната
NewsFront не конкретизира и не посочва данни във връзка с това твърдение. Действително Полша е на второ място сред държавите, приели най-много украински бежанци. Актуалните данни сочат, че в страната пребивават 958 935 украинци. В Германия, която е на първо място, живеят малко над милион украинци. Населението в градове като Жешов, в югоизточната част на Полша, е нараснало с близо 55%. Други градове, като Лодз, споменат по-нататък в статията, са увеличили населението си с едва 13%.
Голяма част от украинските бежанци напускат Полша, ориентирайки се към Германия. На 12 септември тази година в интервю за „Асошиейтед Прес“ Михалина Шиелевич, която проучва икономическите измерения на миграцията на украинци в Полша, заявява, че напускането им е по-скоро тревожна за поляците тенденция, поне от икономическа гледна точка, макар и те сами по себе си да не могат да запълнят липсата на кадри в страната. В допълнение, броят на украинските бежанци в Полша е намалял с 350 000 от август 2022 г. насам. Страната получава и подкрепа от Европа по механизмите за облекчаване на товара от приема на украински бежанци.
Истина: Полша е сред страните от ЕС, приели най-много украински бежанци, и съвсем естествено, изпитва затруднения, но вижда и положителните страни в наплива на хора от сходна културна среда в работоспособна възраст. Бежанците не са еднакво разпределени в цялата страна, а Полша получава помощ от ЕС за по-лесното им интегриране.
Техники: черипикинг, използване на емоционален език, допълване на разказа (в случая по-широките тенденции са антибежанските настроения като цяло, както и ксенофобията).
Манипулативно твърдение: „броят на престъпленията в Полша днес се е увеличил с 46% в сравнение със статистиката от 2021 г.“
Официално публикувани от полските власти статистически данни за нивата на престъпността са налични до 2021 г. Полският Business Insider съобщава, че през първата половина на 2023 г. е регистрирано увеличение с 39,1% на кражбите в магазините и с 22% на кражбите от друг характер. Обяснението на експерти е, че скокът се дължи на инфлацията и обедняването на населението. Най-често става дума за кражби на храна и луксозни стоки – скъп алкохол, парфюми и електроника. Данни на Statista показват, че делът на поляците, които се страхуват, че биха могли да станат жертва на престъпление, е намалял в сравнение с 2022 и 2021 г.
След щателно проучване не става ясно откъде авторите са получили стойността 46%. Нито в материалите, препечатани на български и руски, нито в оригинала на полски е посочен източник на данните. Към момента на писане на настоящия текст не е открита актуална статистика, в която да фигурира това число.
Истина: Не е ясно за какъв тип престъпления става въпрос. Официалните данни говорят за увеличение на кражбите, но не в тези стойности. Оригиналният източник не посочва откъде са данните.
Техники: абстрактно позоваване на авторитети, допълване на разказа (страх от престъпност; внушение, че престъпността се увеличава).
Манипулативно твърдение: „Националността на престъпниците от Украйна се крие или премълчава, което им създава усещане за безнаказаност.“
На 17 юли 2023 г. сайтът Rzeczpospolita („Жечпосполита“), една от най-четените и цитирани полски медии, публикува материал за престъпленията, извършени от чужденци, който се позовава на официални данни от полските власти, поискани от медията. Статистиката сочи, че от всички групи чужденци украинците действително са на първо място по извършени престъпления. Но това далеч не е цялата история.
Трябва да се има предвид, че в Полша украинците формират една от най-големите групи с националност или принадлежност, различна от полската. А украинците, за които се подозира, че са извършили престъпление, са 2288 души, което прави по-малко от процент, или 0,24% от общия брой на пребиваващите украинци в страната, дори 0,15%, ако се позоваваме на данните, предоставени през юли от Rzeczpospolita.
Полските журналисти посочват, че за последното десетилетие броят на престъпления, извършени от чужденци, е нараснал, но това е свързано с увеличилата се миграция към страната от най-различни държави, не само от Украйна. Сред криминално проявените чужденци са отчетени хора от Грузия, Беларус, Молдова, Русия, Румъния, Германия, България и Чехия. В повечето случаи става дума за кражби, шофиране в нетрезво състояние, както и за притежание на наркотици (включително марихуана, която е нелегална в Полша, но легална например в Германия). Материалът на Rzeczpospolita разказва основно за грузински банди, които обират жилища. Най-честото провинение на украинците е, че карат пили, коментират журналистите от полската медия.
Истина: Има множество статии за престъпленията, извършени от чуждестранни лица в Полша. Украинците са най-голямата общност сред криминално проявените от чуждестранен произход, но това се дължи и на пропорционалност, тъй като в момента в Полша има близо един милион украинци. Извършилите престъпление украинци са по-малко от процент от общия брой на пребиваващите в страната. Най-честото провинение е каране в нетрезво състояние.
Техники: черипикинг, комплекс на героя, представяне за алтернатива
Статията продължава с няколко разказа: за трима задържани мъже и иззети 110 кг марихуана, както и за задържан за трафик на мигранти украинец. И двете истории са истински и са отразени в полски новинарски източници. Но подобни случаи с криминално проявени има и с участието на българи например, както и с много други националности, както вече обяснихме със статистиката. Уплътняването на подобен материал с действителни криминални случаи е класически пример за черипикинг.
Манипулативно твърдение: фондацията на Олена Зеленска е „замесена в трафик на деца“
Финалът на статията в NewsFront лансира твърдението, че съпругата на украинския президент „е била замесена в трафик на деца“. Изданието се позовава на „френския репортер Робърт Шмид“, без да посочи източник на статията. В други източници историята е описана като разказ на „разобличител“, без да се споменава френски репортер. Макар френски репортер Робърт Шмид да съществува, не се открива негова статия по темата.
Твърденията за Зеленска, изглежда, са базирани на един-единствен френски видеоклип в YouTube с непотвърден източник с маска и качулка, който показва непроверена информация, заснета с лошо качество. В канала с име Robert Schmidt няма публикувани други клипове. Към момента на написване на този материал твърденията за Зеленска се споделят в маргинални сайтове, форуми и групи, за които има данни, че разпространяват дезинформация.
Истина: Robert Schmidt се оказва просто име на канал в YouTube, на който анонимен човек с маска разказва твърдения без легитимни доказателства.
Техники: представяне за алтернатива, криво огледало, абстрактно позоваване на авторитети, допълване на разказа (в този случай с внушението, че съществуват световни мрежи от педофили, експлоатиращи деца – идея, която намира отражение в много конспирации и има дълга история на рециклиране).
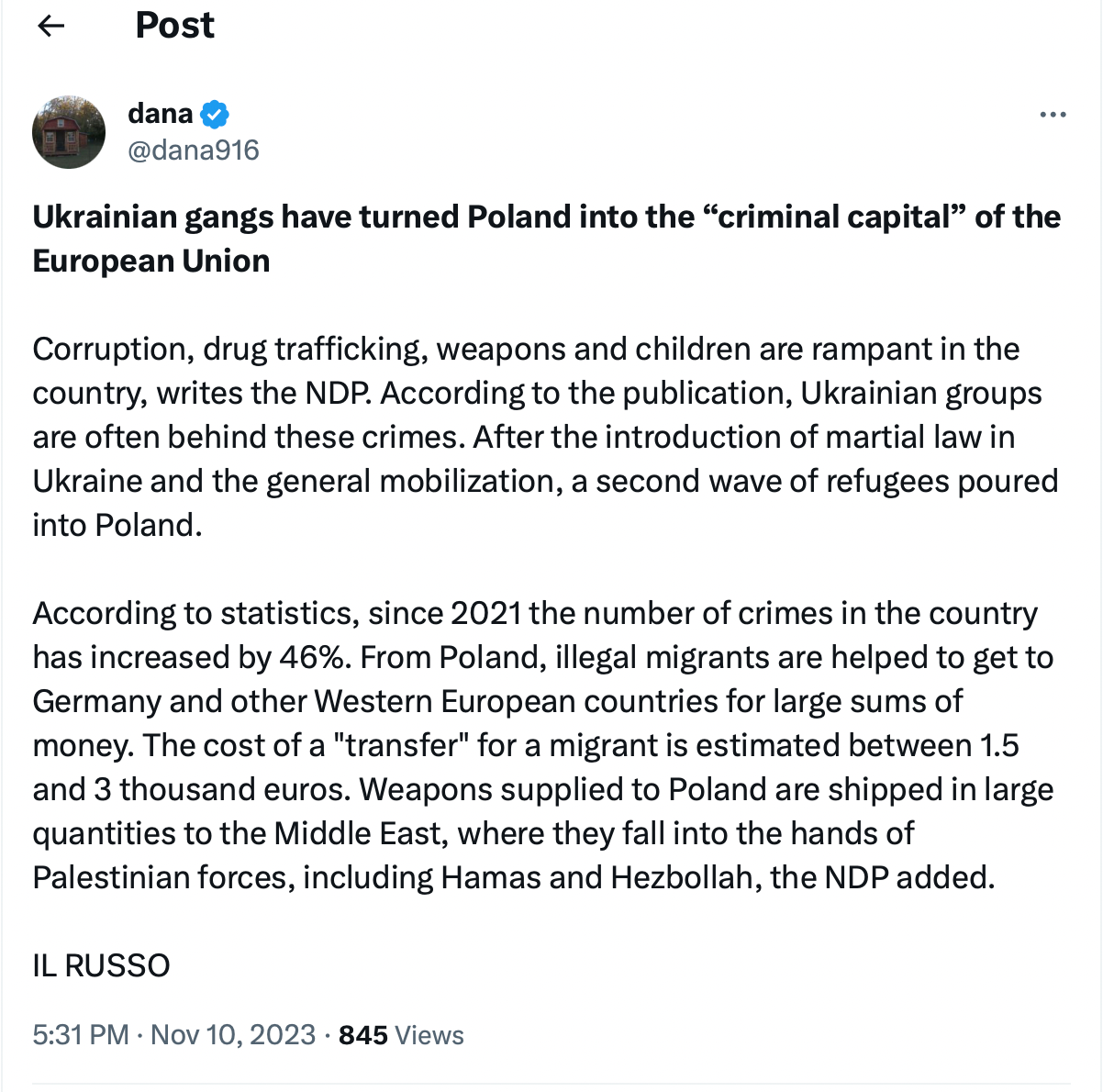
Неслучайни хора
През 2017 г. Балтийският център за разследваща журналистика Re:Baltica решава да издири настоящия редактор на полския сайт Dziennik Polityczny Адам Камински. Опитите да се срещнат с него лице в лице или да осъществят видеовръзка не се увенчават с успех. Оказва се, че профилната му снимка във Facebook всъщност е на известен литовски ортопед. Още тогава полският сайт публикува манипулативно съдържание относно „геноцида на латвийското правителство над руски или полски малцинства“, както и за това, че „присъствието на американски войници в региона е ненужно и вредно“ – все познати от руското информационно пространство рефрени, актуални и днес.
Материали от Dziennik Polityczny (или NDP) са широко споделяни в българските социални мрежи. Конкретно анализираната тук статия откриваме и в редица руски сайтове, както и четена от изкуствен интелект на фона на най-различни апокалиптични снимки в YouTube канала „Бързи новини“, в който се публикува съдържание със заглавия от рода на „По-страшно от ядрената бомба: Русия вади основния си коз“, „Западът е ужасен от това“, „Безстрашният Ким започна да праща ракети на Русия, Вашингтон е объркан“.
Те ви лъжат и цензурират, ние ги цитираме
„Европейски учени от Института за еволюционна биология Макс Планк в Пльон (Германия) и Университета в Монпелие (Франция)“, „Университета във Фрайбург“, „Университета на Пенсилвания“, „Университета Кеймбридж“, Жозеп Борел, „Форбс“, „британско проучване“… Това са само част от цитираните източници в статии, които съдържат ключови думи като „проучване“ или „данни“ и са публикувани в сайтове, за които е известно, че системно разпространяват манипулативно съдържание.
БЛИЦ например може да пише срещу „западната цензура“ в медиите и как „се свалят неподходящи новини за войната в Украйна“, но това не пречи да цитира „Ню Йорк Таймс“, когато американските журналисти пишат за… конфликт в ръководството на Украйна. Нито пък да цитират Би Би Си по темата COVID-19. Преразказът става избирателно, по гореописаните методи.
„Епицентър“ пък публикува статии с проучвания и данни от БНР, БТА, Си Ен Ен и др., но прави впечатление, че системно се появяват онези проучвания и данни от западни държави, които говорят за безработица, изоставане в образованието, настроения против подкрепа за Украйна във войната и др. Това е пример как легитимни проблеми като инфлацията, доверието в демократичните институции, различните мнения по международни въпроси и образователните реформи се представят като тежки, хронични проблеми без решение или се извъртат в полза на определена държава, в случая Русия.
Изгубени в превода
Понякога внушението може да се постигне и чрез една грешно преведена дума. Такъв е примерът с материал в Bnews със заглавие „80% от украинците смятат Зеленски за най-виновен за ендемичната корупция в Украйна“. В статията се цитират украински източници – Фондацията за демократични инициативи и Киевският международен социологически институт.
В първоизточниците обаче се казва, че „77,6% от гражданите смятат, че президентът носи пряка отговорност за корупцията в правителството и военната администрация“. Отговорността на президента не означава вина, а че от него зависи да се справи с този проблем, за да не се урони вярата на хората в способността на Украйна да води войната и в самия президент, пишат от украинската фондация. Подмяната на само една дума – „отговорност“ с „вина“, както и закръглянето на данните, променя целия смисъл на текста.
Накрая – самопризнания
„Алтернативните“ медии често разчитат на рециклирано и превратно тълкувано съдържание, защото много от тях нямат репортери на терен, а често в тях не работят и професионални журналисти. Обикновено става въпрос за лидери на мнение или блогъри и инфлуенсъри, които препечатват съдържание от други хора, а когато се нуждаят от плънка, като солидни данни, репортерски очерци или проучвания, включват и легитимни източници, стига резултатите и информацията да са в тяхна полза.
Сайтове като informiran.net директно заявяват, че „екипът… не разполага с ресурсите да проверява информацията, която достига до редакцията и не гарантира за истинността ѝ“. Друг случай пък е материал в pogled.info, препечатка от РИА „Новости“, в който се поставя под съмнение човешката роля в климатичните промени с позоваване на „данни“ от „изследователи“ в Арктика и „водещото геоложко списание „Геосайънс“. След като статията развива цяла „алтернативна теория“ за климатичните промени, към края става ясно, че теорията е… просто теория, която дори не е „идентифицирана“. Причината за липса на доказателства? Заговор, разбира се – всички пари отивали за легитимна наука.
Решението
Такива случаи не са рядкост, напротив. Колкото и труден и хаотичен да става пейзажът на манипулативното съдържание и дезинформацията, критичният читател може действително сам да достигне до истината, като следва някои правила:
- Да гледа голямата картина. В наши дни всеки може да си направи проучване или да твърди, че е направил, но наистина добрите изследвания се придържат към научни правила и методи, за да постигнат максимална обективност. За да бъде едно проучване легитимно, тези методи трябва да са прозрачно описани, да са валидни и надеждни – което се оценява от други специалисти в сферата. Какво казват други проучвания по същата тема? Съвпадат ли данните, или има разминаване? Ако четем за бедността в Германия, как се сравняват тези стойности с останалата част от света? Ако става въпрос за общественото мнение по даден въпрос, какво казват други репортажи и проучвания по темата?
- Да търси първоизточника. Ако в една статия се цитират разследване на „Ню Йорк Таймс“ или данни на „Ройтерс“, винаги е по-добре да се прочете първоизточникът. Ако оригиналният език е проблем, може да се ползва Google Translate, колкото да се добие обща представа за написаното. Често в първоизточника се открива и важен контекст, който не се препечатва и обикновено добавя нюанси към данните и информацията.
- Да не разчита единични истории като тенденции. Даден случай с криминално проявен от определена националност не означава, че всички хора от съответната националност са престъпници. При интерес по темата е добре да се потърси актуална статистика за нивата на престъпност и да се сравнят с други държави.
- Да не гласува доверие на мнима експертност. Всички данни си имат източници, всички учени и институции – имена. Но и не всяка организация с името „институт“ е легитимно научно пространство. Често едно търсене в Google е достатъчно, за да се разбере повече за дадено лице или институция – има ли политически обвързаности, има ли зависимости вследствие на тези обвързаности, има ли история с неверни публикации и т.н.
- Да не се поддава на емоционалния език. Ако една статия използва силно емоционален език, демонизира цели групи хора или говори с конспиративни твърдения, то вероятно източникът на информация не е надежден и има някаква користна цел – да ни провокира, разгневи или настрои срещу определени социални групи.
- Да познава собствените си предразсъдъци. Това, че дадена статия предлага негативна информация за политически партии или хора, които не харесваме, не означава, че информацията в нея е вярна, дори да съвпада с вижданията ни. И обратното – понякога наличните данни могат да ни провокират, защото поставят под въпрос нещо, в което вярваме.
- Да поставя под въпрос понятието „алтернатива“. Познавате ли журналистите, работещи в медиите, които следите? Може ли да се свържете с тях и да ги попитате за източници например? Виждали ли сте ги на живо? Публикува ли медията свои собствени разследвания и журналистически материали, или цитира други медии, мнения, клипове от социалните мрежи и преразкази на проучвания? „Алтернативата“ би следвало да означава още журналисти на терен, спазващи етични стандарти и предоставящи онзи медиен продукт, който според тях липсва, а не пропаганда, политически активизъм или клипчета от YouTube.
Ако преди под „дезинформация“ или „фалшиви новини“ се разбираше откровено невярна информация, то днес все по-често сме свидетели на по-сложен феномен, в който реални случки, данни и репортажи умишлено се използват по неетичен или зловреден начин.
В допълнение, растящото недоверие към институциите, както и към медиите, ни прави много по-уязвими за манипулацията, която често се представя като алтернатива на реалността.
Решенията обаче не са в измислянето на паралелна реалност, нито в тълкуването на данни и наука, както ни е угодно. Напротив – първата стъпка е именно в скептицизма, който и дезинформацията експлоатира така добре. Но докато тя го превръща в цинизъм, според който „няма една истина“ и „всички са маскари“, то критичното мислене като здравословна форма на цинизма ни дава възможност винаги да имаме едно наум какво четем. И именно там е разковничето.
* В цитатите в статията са запазени оригиналният правопис и пунктуация.
С подкрепата на Science+.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}