Post Syndicated from Ben Peven original https://aws.amazon.com/blogs/compute/monitoring-dashboard-for-aws-parallelcluster/
This post is contributed by Nicola Venuti, Sr. HPC Solutions Architect.
AWS ParallelCluster is an AWS-supported, open source cluster management tool that makes it easy to deploy and manage High Performance Computing (HPC) clusters on AWS. While AWS ParallelCluster includes many benefits for its users, it has not provided straightforward support for monitoring your workloads. In this post, I walk you through an add-on extension that you can use to help monitor your cloud resources with AWS ParallelCluster.
Product overview
AWS ParallelCluster offers many benefits that hide the complexity of the underlying platform and processes. Some of these benefits include:
- Automatic resource scaling
- A batch scheduler
- Easy cluster management that allows you to build and rebuild your infrastructure without the need for manual actions
- Seamless migration to the cloud supporting a wide variety of operating systems.
While all of these benefits streamline processes for you, one crucial task for HPC stakeholders that customers have found challenging with AWS ParallelCluster is monitoring.
Resources in an HPC cluster like schedulers, instances, storage, and networking are important assets to monitor, especially when you pay for what you use. Organizing and displaying all these metrics becomes challenging as the scale of the infrastructure increases or changes over time which is the typical scenario in the Cloud.
Given these challenges, AWS wants to provide AWS ParallelCluster users with two additional benefits: 1/ facilitate the optimization of price performance and 2/ visualize and monitor the components of cost for their workloads.
The HPC Solution Architects team has created an AWS ParallelCluster add-on that is easy to use and customize. In this blog post, I demonstrate how Grafana – a platform for monitoring and observability – can run on AWS ParallelCluster to enable infrastructure monitoring.
AWS ParallelCluster integrated dashboard and Grafana add-on dashboards
Many customers want a tool that consolidates information coming from different AWS services and makes it easy to monitor the computing infrastructure created and managed by AWS ParallelCluster. The AWS ParallelCluster team – just like every other service team at AWS – is open and keen to listen from our customers.
This feedback helps us inform our product roadmap and build new, customer-focused features.
We recently released AWS ParallelCluster 2.10.0 based on customer feedback. Here are some key features have been released with it:
- Support for the CentOS 8 Operating System: Customers can now choose CentOS 8 as their base operating system of choice to run their clustersfor both x86 and Arm architectures.
- Support for P4d instances along with NVIDIA GPUDirect Remote Direct Memory Access (RDMA).
- FSx for Lustre enhancements (support for FSx AutoImport and HDD-based support filesystem options)
- And finally, a new CloudWatch Dashboards designed to help aggregating cluster information, metrics, and logging already available on CloudWatch.
The last of these features above, integrated CloudWatch Dashboards, are designed to help customers face the challenge of cluster monitoring mentioned above. In addition, the Grafana dashboards demonstrated later in this blog are a complementary add-on to this new, CloudWatch-based, dashboard. There are some key differences between the two, summarized in the table below.
The latter does not require any additional component or agent running on either the head or the compute nodes. It aggregates the metrics already pushed by AWS ParallelCluster on CloudWatch into a single dashboard. This translates into zero overhead for the cluster, but at the expense of less flexibility and expandability.
Instead, the Grafana-based dashboard offers additional flexibility and customizability and requires a few lightweight components installed on either the head or the compute nodes. Another key difference between the two monitoring dashboards is that the CloudWatch based one requires AWS credentials, IAM User and Roles configured and access to the AWS web-console, while the Grafana-based one has its-own built-in authentication and authorization system unrelated from the AWS account, end-users or HPC admins might not have permissions (or simply are not willing) to access the AWS Management Console in order to monitor their clusters.
| CloudWatch based dashboard | Grafana-based monitoring add-on |
| No additional component | Grafana + Prometheus |
| No overhead | Minimal overhead |
| Little to no expandability | Support full customizability |
| Requires AWS credentials and IAM configured | Custom credentials, no AWS access required |
| Custom user-interface |
Grafana add-on dashboards on GitHub
There are many components of an HPC cluster to monitor. Moreover, the cluster is built on a system that is continuously evolving: AWS ParallelCluster and AWS services in general are updated and new features are released often. Because of this, we wanted to have a monitoring solution that is developed on flexible components, that can evolve rapidly. So, we released a Grafana add-on as an open-source project onto this GitHub repository.
Releasing it as an open-source project allows us to more easily and frequently release new updates and enhancements. It also enables users to customize and extend its functionalities by adding new dashboards, or extending the dashboards functionalities (like GPU monitoring or track EC2 Spot Instance interruptions).
At the moment, this new solution is composed of the following open-source components:
- Grafana is an open-source platform for monitoring and observing. Grafana allows you to query, visualize, alert, and understand your metrics. It also helps you create, explore, and share dashboards fostering a data-driven culture.
- Prometheus is an open source project for systems and service monitoring from the Cloud Native Computing Foundation. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true.
- The Prometheus Pushgateway is an open source tool that allows ephemeral and batch jobs to expose their metrics to Prometheus.
- NGINX is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server.
- Prometheus-Slurm-Exporter is a Prometheus collector and exporter for metrics extracted from the Slurm resource scheduling system.
- Node_exporter is a Prometheus exporter for hardware and OS metrics exposed by *NIX kernels, written in Go with pluggable metric collectors.
Note: while almost all components are under the Apache2 license, only Prometheus-Slurm-Exporter is licensed under GPLv3. You should be aware of this license and accept its terms before proceeding and installing this component.
The dashboards
I demonstrate a few different Grafana dashboards in this post. These dashboards are available for you in the AWS Samples GitHub repository. In addition, two dashboards – still under development – are proposed in beta. The first shows the cluster logs coming from Amazon CloudWatch Logs. The second one shows the costs associated to each AWS service utilized.
All these dashboards can be used as they are or customized as you need:
- AWS ParallelCluster Summary – This is the main dashboard that shows general monitoring info and metrics for the whole cluster. It includes: Slurm metrics, compute related metrics, storage performance metrics, and network usage.
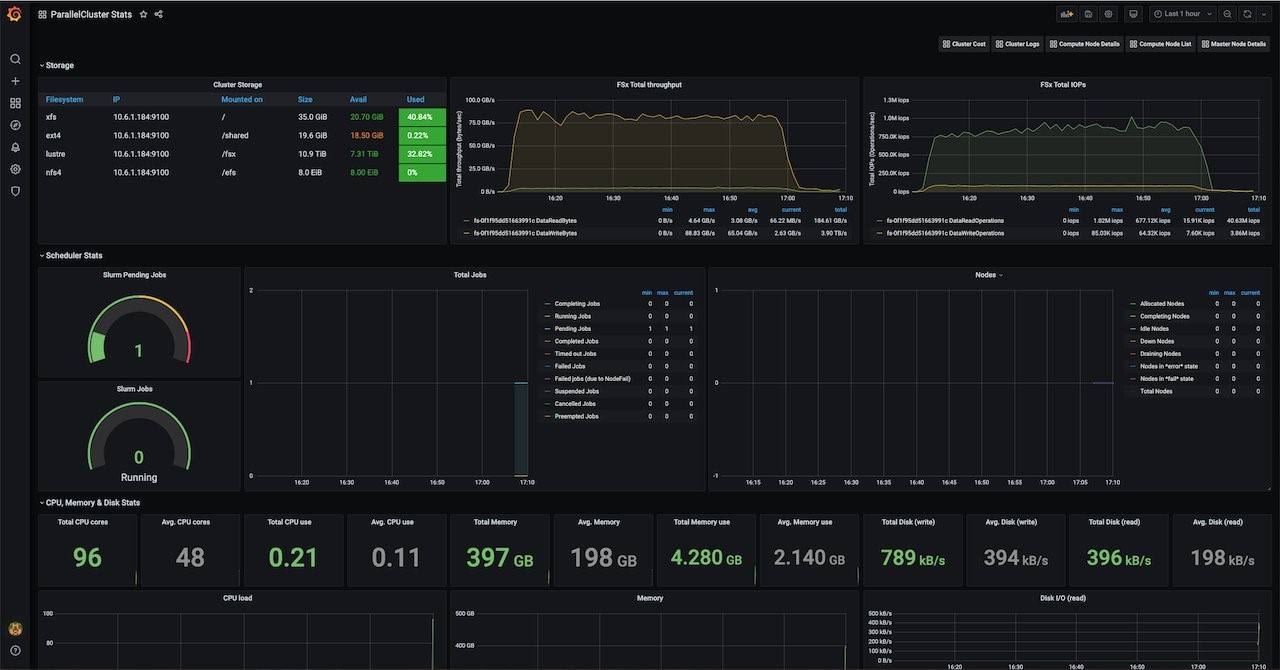
- Master Node Details – This dashboard shows detailed metrics for the head node, including CPU, memory, network, and storage utilization.

- Compute Node List – This dashboard shows the list of the available compute nodes. Each entry is a link to a more detailed dashboard: the compute node details (see the following image).

- Compute Node Details – Similar to the head node details, this dashboard shows detailed metrics for the compute nodes.
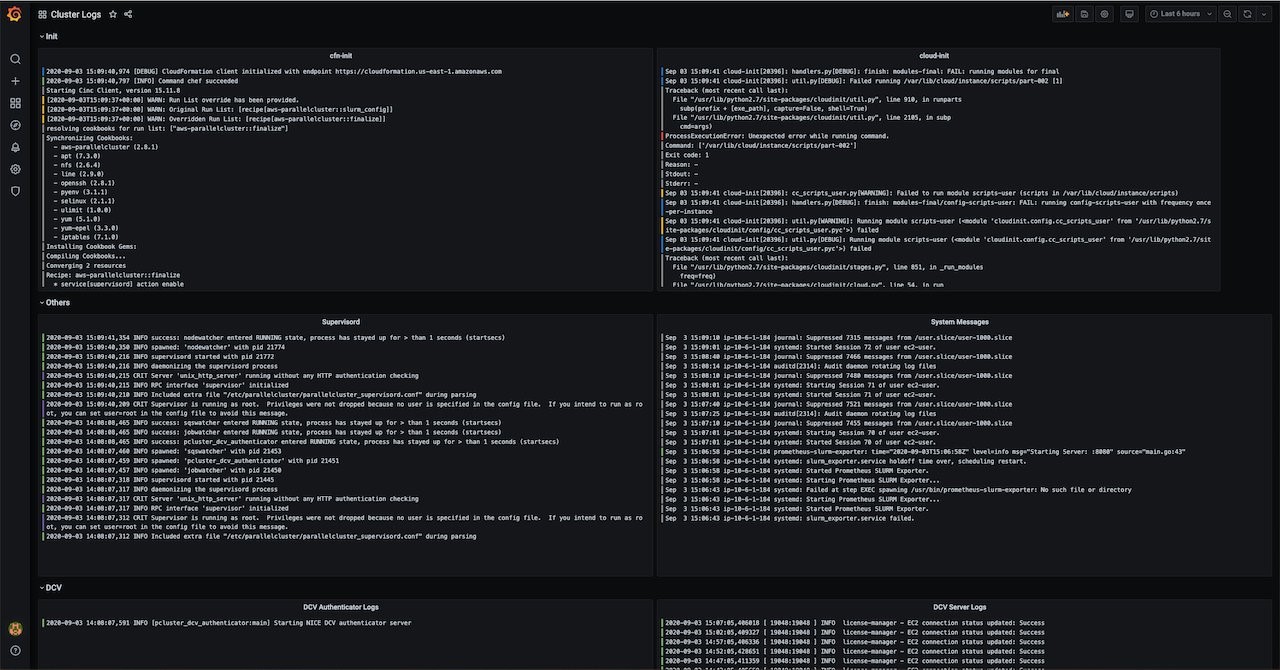
- Cluster Logs – This dashboard (still under development) shows all the logs of your HPC cluster. The logs are pushed by AWS ParallelCluster to Amazon CloudWatch Logs and are reported here.
- Cluster Costs (also under development) – This dashboard shows the cost associated to AWS Service utilized by your cluster. It includes: EC2, Amazon EBS, FSx, Amazon S3, Amazon EFS. as well as an aggregation of all the costs of every single component.

How to deploy it
You can simply use the post-install script that you can find in this GitHub repo as it is, or customize it as you need. For instance, you might want to change your Grafana password to something more secure and meaningful for you, or you might want to customize some dashboards by adding additional components to monitor.
The proposed post-install script takes care of installing and configuring everything for you. Although a few additional parameters are needed in the AWS ParallelCluster configuration file: the post-install argument, additional IAM policies, custom security group, and a tag. You can find an AWS ParallelCluster template here.
Please note that, at the moment, the post install script has only been tested using Amazon Linux 2.
Add the following parameters to your AWS ParallelCluster configuration file, and then build up your cluster:
Make sure that port 80 and port 443 of your head node are accessible from the internet or from your network. You can achieve this by creating the appropriate security group via AWS Management Console or via Command Line Interface (AWS CLI), see the following example:
There is more information on how to create your security groups here.
Finally, set the additional_sg parameter in the [VPC] section of your AWS ParallelCluster configuration file.
After your cluster is created, you can open a web-browser and connect to https://your_public_ip. You should see a landing page with links to the Prometheus database service and the Grafana dashboards.
Size your compute and head nodes
We looked into resource utilization of the components required for building this monitoring solution. In particular, the Prometheus node exporter installed in the compute nodes uses a small (almost negligible) number of CPU cycles, memory, and network.
Depending on the size of your cluster the components installed on the head node (see the list in the chapter “Solution components” of this blog) it might require additional CPU, memory and network capabilities. In particular, if you expect to run a large-scale cluster (hundreds of instances) because of the higher volume of network traffic due to the compute nodes continuously pushing metrics into the head node, we recommend you use an instance type bigger than what you planned.
We cannot advise you exactly how to size your head node because there are many factors that can influence resource utilization. The best recommendation we could give you is to use the Grafana dashboard itself to monitor the CPU, memory, disk, and most importantly, network utilization, and then resize your head node (or other components) accordingly.
Conclusions
This monitoring solution for AWS ParallelCluster is an add-on for your HPC Cluster on AWS and a complement to new features recently released in AWS ParallelCluster 2.10. This blog aimed to provide you with instructions and basic tooling that can be customized based on your needs and that can be adapted quickly as the underlying AWS services evolve.
We are open to hear from you, receive feedback, issues, and pull requests to extend its functionalities.